In deze blogpost zullen we 6 verschillende storingsscenario's in productiedatabasesystemen analyseren, variërend van problemen met één server tot failoverplannen voor meerdere datacenters. We zullen u door de herstel- en failover-procedures voor het betreffende scenario leiden. Hopelijk geeft dit u een goed inzicht in de risico's waarmee u te maken kunt krijgen en de zaken waarmee u rekening moet houden bij het ontwerpen van uw infrastructuur.
Databaseschema beschadigd
Laten we beginnen met de installatie van één knooppunt - een databaseconfiguratie in de eenvoudigste vorm. Eenvoudig te implementeren, tegen de laagste kosten. In dit scenario voert u meerdere toepassingen uit op de enkele server waarbij elk van de databaseschema's bij de verschillende toepassing hoort. De aanpak voor het herstellen van een enkel schema is afhankelijk van verschillende factoren.
- Heb ik een back-up?
- Heb ik een back-up en hoe snel kan ik deze herstellen?
- Wat voor soort opslagengine wordt er gebruikt?
- Heb ik een PITR-compatibele (point in time recovery) back-up?
Corruptie van gegevens kan worden geïdentificeerd door mysqlcheck.
mysqlcheck -uroot -p <DATABASE>Vervang DATABASE door de naam van de database en vervang TABLE door de naam van de tabel die u wilt controleren:
mysqlcheck -uroot -p <DATABASE> <TABLE>Mysqlcheck controleert de opgegeven database en tabellen. Als een tafel de controle doorstaat, geeft mysqlcheck OK weer voor de tafel. In onderstaand voorbeeld kunnen we zien dat de tabel salarissen vereist herstel.
employees.departments OK
employees.dept_emp OK
employees.dept_manager OK
employees.employees OK
Employees.salaries
Warning : Tablespace is missing for table 'employees/salaries'
Error : Table 'employees.salaries' doesn't exist in engine
status : Operation failed
employees.titles OKVoor een installatie met één knooppunt zonder extra DR-servers, zou de primaire benadering zijn om gegevens vanaf een back-up te herstellen. Maar dit is niet het enige waar u rekening mee moet houden. Het hebben van meerdere databaseschema's onder hetzelfde exemplaar veroorzaakt een probleem wanneer u uw server moet uitschakelen om gegevens te herstellen. Een andere vraag is of u het zich kunt veroorloven om al uw databases terug te draaien naar de laatste back-up. In de meeste gevallen zou dat niet mogelijk zijn.
Hier zijn enkele uitzonderingen op. Het is mogelijk om een enkele tabel of database van de laatste back-up te herstellen wanneer herstel op een bepaald tijdstip niet nodig is. Een dergelijk proces is ingewikkelder. Als je mysqldump hebt, kun je je database eruit extraheren. Als je binaire back-ups draait met xtradbackup of mariabackup en je hebt tabel per bestand ingeschakeld, dan is het mogelijk.
Hier leest u hoe u kunt controleren of u een optie voor tabel per bestand heeft ingeschakeld.
mysql> SET GLOBAL innodb_file_per_table=1; Met innodb_file_per_table ingeschakeld, kunt u InnoDB-tabellen opslaan in een tbl_name .ibd-bestand. In tegenstelling tot de MyISAM-opslagengine, met zijn afzonderlijke tbl_name .MYD- en tbl_name .MYI-bestanden voor indexen en gegevens, slaat InnoDB de gegevens en de indexen samen op in één .ibd-bestand. Om uw opslagengine te controleren, moet u het volgende uitvoeren:
mysql> select table_name,engine from information_schema.tables where table_name='table_name' and table_schema='database_name';of rechtstreeks vanaf de console:
[example@sqldat.com ~]# mysql -u<username> -p -D<database_name> -e "show table status\G"
Enter password:
*************************** 1. row ***************************
Name: test1
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 12
Avg_row_length: 1365
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: NULL
Create_time: 2018-05-24 17:54:33
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment: Om tabellen van xtradbackup te herstellen, moet u een exportproces doorlopen. Er moet een back-up worden gemaakt voordat deze kan worden hersteld. Exporteren gebeurt in de voorbereidingsfase. Zodra een volledige back-up is gemaakt, voert u de standaard voorbereidingsprocedure uit met de extra vlag --export :
innobackupex --apply-log --export /u01/backupHiermee worden extra exportbestanden gemaakt die u later in de importfase zult gebruiken. Om een tafel naar een andere server te importeren, maakt u eerst een nieuwe tafel met dezelfde structuur als degene die op die server wordt geïmporteerd:
mysql> CREATE TABLE corrupted_table (...) ENGINE=InnoDB;verwijder de tabelruimte:
mysql> ALTER TABLE mydatabase.mytable DISCARD TABLESPACE;Kopieer vervolgens de bestanden mytable.ibd en mytable.exp naar de homepagina van de database en importeer de tablespace:
mysql> ALTER TABLE mydatabase.mytable IMPORT TABLESPACE;Om dit echter op een meer gecontroleerde manier te doen, zou de aanbeveling zijn om een databaseback-up in een andere instantie/server te herstellen en wat nodig is terug te kopiëren naar het hoofdsysteem. Om dit te doen, moet u de installatie van de mysql-instantie uitvoeren. Dit kan op dezelfde machine worden gedaan, maar vereist meer inspanning om zo te configureren dat beide instanties op dezelfde machine kunnen worden uitgevoerd. Hiervoor zijn bijvoorbeeld verschillende communicatie-instellingen nodig.
U kunt zowel taakherstel als installatie combineren met ClusterControl.
ClusterControl leidt u door de beschikbare back-ups op locatie of in de cloud, laat u het exacte tijdstip kiezen voor een herstel of de exacte logpositie en installeert indien nodig een nieuwe database-instantie.
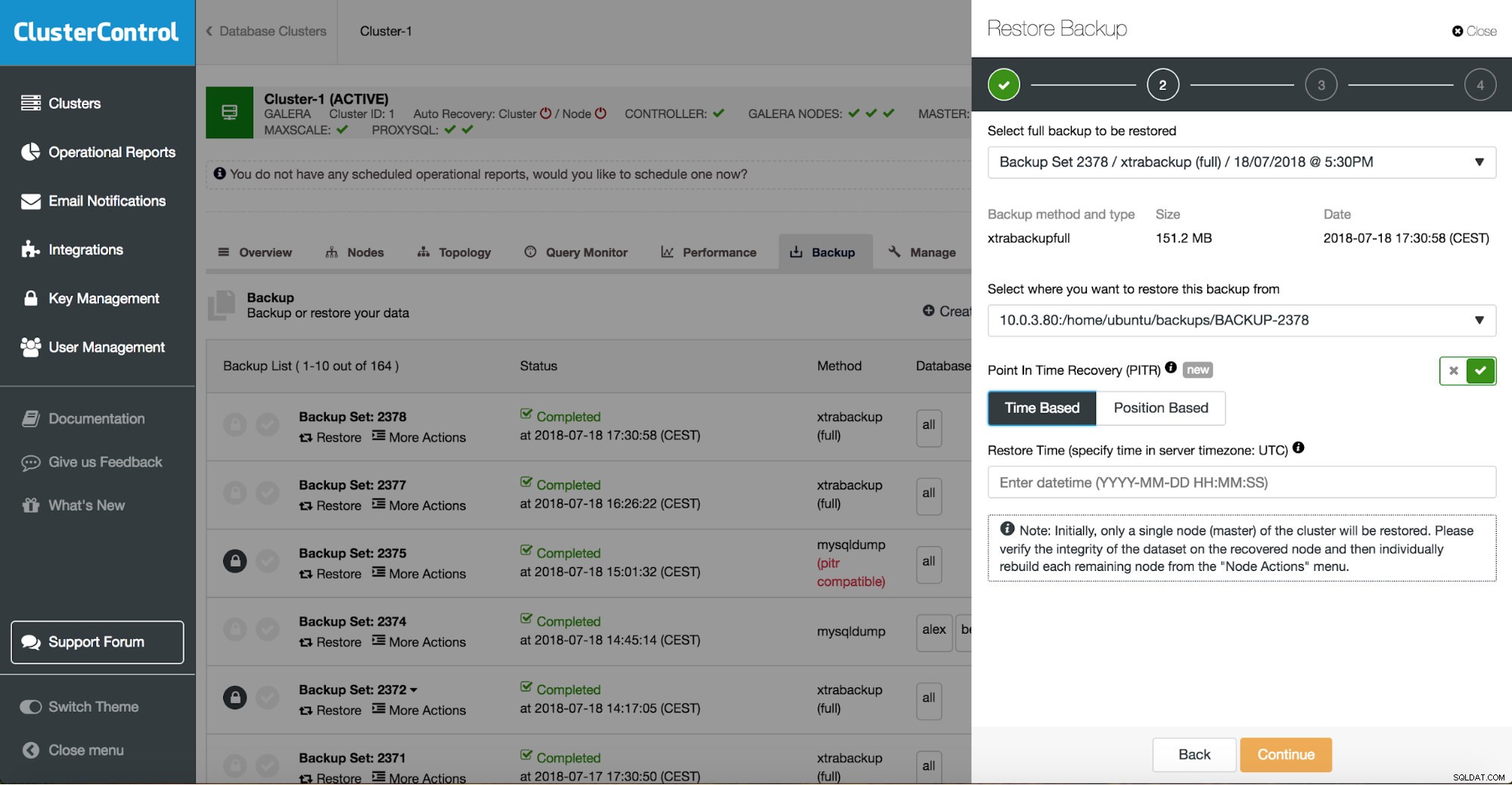 ClusterControl herstelpunt in tijd
ClusterControl herstelpunt in tijd 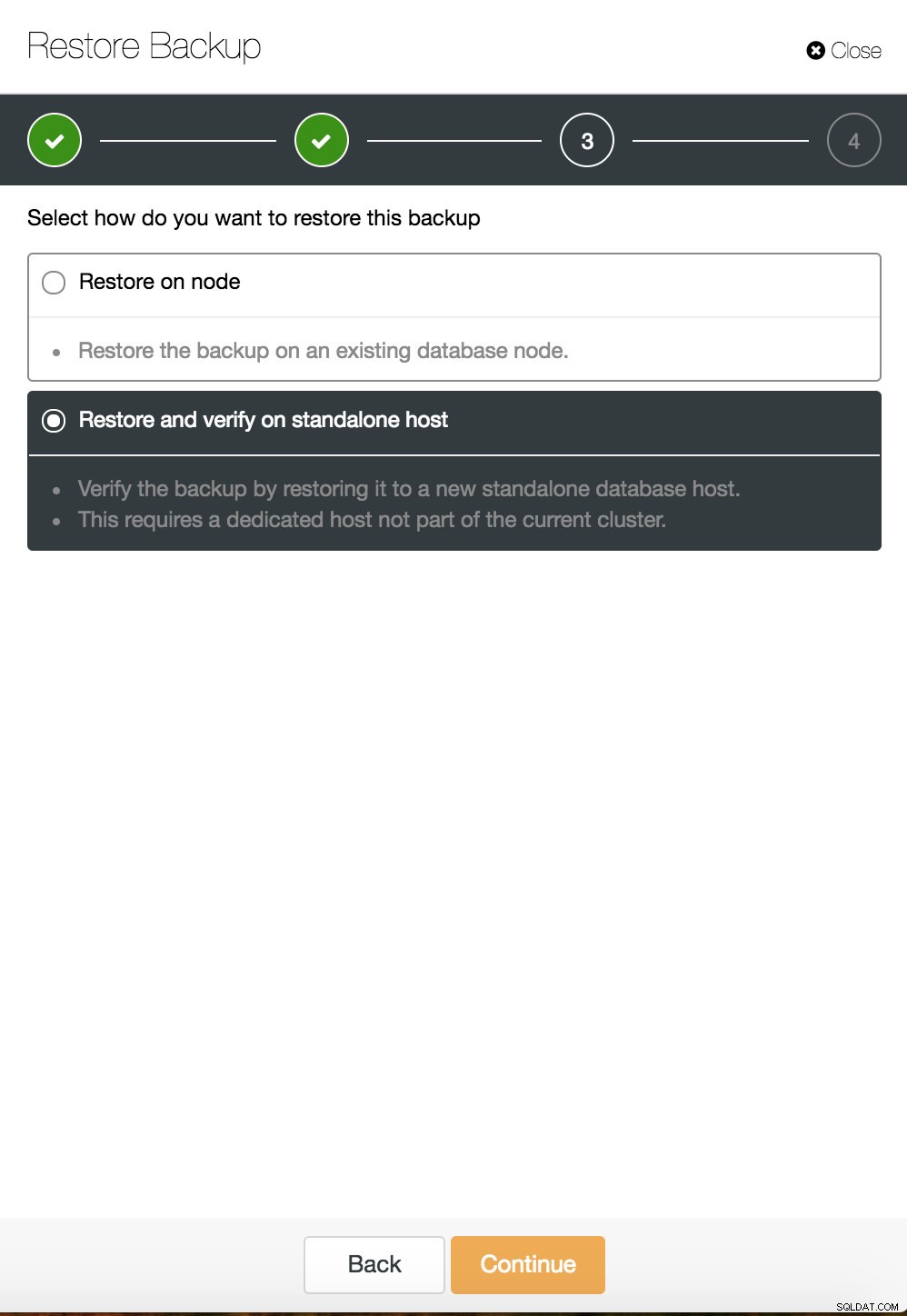 ClusterControl herstellen en verifiëren op een zelfstandige host
ClusterControl herstellen en verifiëren op een zelfstandige host 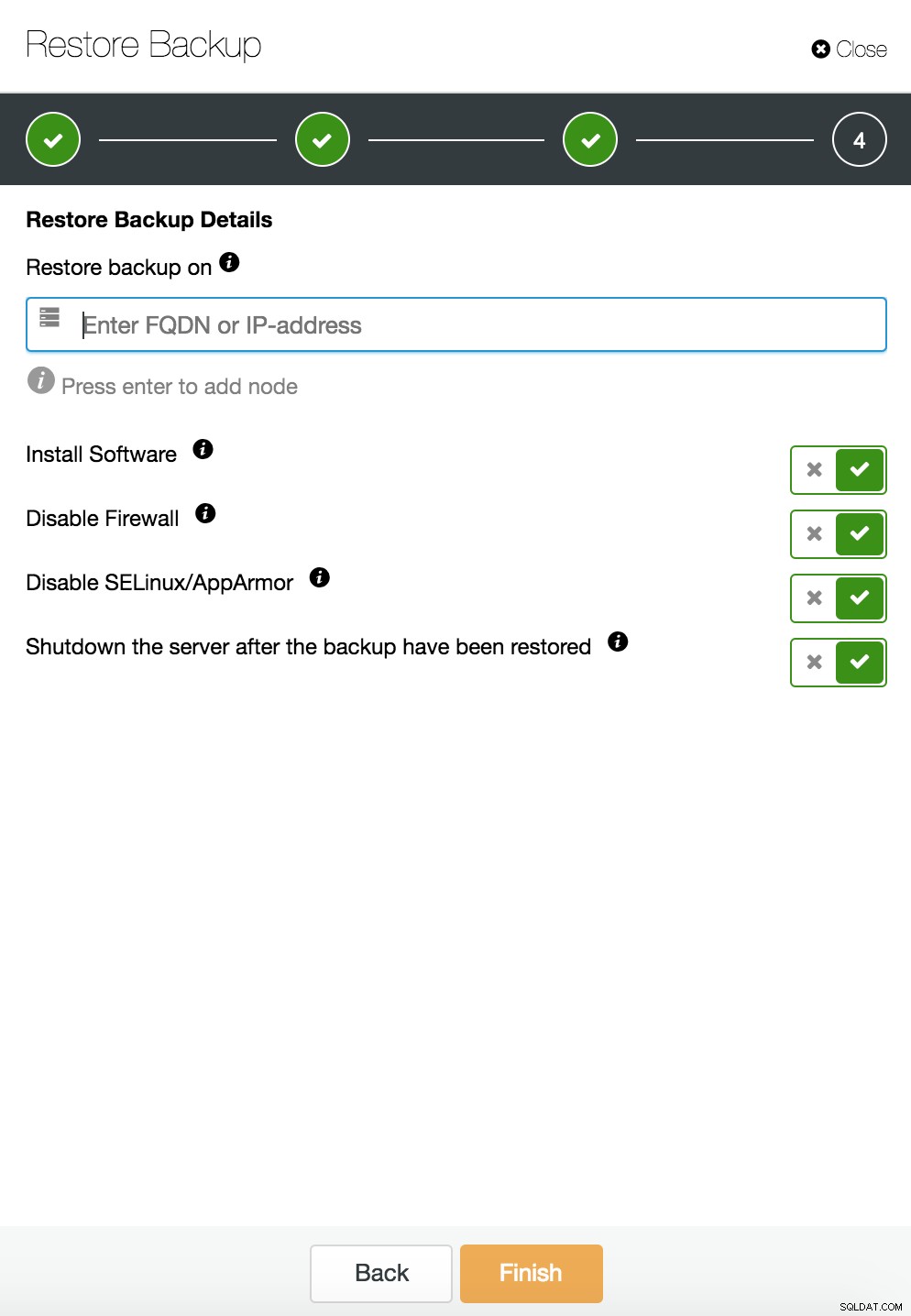 CusterControl herstel en verifieer op een zelfstandige host. Installatie opties.
CusterControl herstel en verifieer op een zelfstandige host. Installatie opties. U kunt meer informatie over gegevensherstel vinden in de blog Mijn MySQL-database is beschadigd... Wat moet ik nu doen?
Database-exemplaar beschadigd op de dedicated server
Defecten in het onderliggende platform zijn vaak de oorzaak van databasecorruptie. Uw MySQL-instantie is afhankelijk van een aantal dingen om gegevens op te slaan en op te halen:schijfsubsysteem, controllers, communicatiekanalen, stuurprogramma's en firmware. Een crash kan gevolgen hebben voor delen van uw gegevens, mysql-binaries of zelfs back-upbestanden die u op het systeem opslaat. Om verschillende applicaties te scheiden, kunt u ze op speciale servers plaatsen.
Verschillende toepassingsschema's op afzonderlijke systemen is een goed idee als u ze kunt betalen. Je zou kunnen zeggen dat dit een verspilling van middelen is, maar de kans bestaat dat de businessimpact minder wordt als er maar één uitvalt. Maar zelfs dan moet u uw database beschermen tegen gegevensverlies. Back-up op dezelfde server opslaan is geen slecht idee, zolang je een kopie ergens anders hebt. Tegenwoordig is cloudopslag een uitstekend alternatief voor back-up op tape.
Met ClusterControl kunt u een kopie van uw back-up in de cloud bewaren. Het ondersteunt uploaden naar de top 3 cloudproviders - Amazon AWS, Google Cloud en Microsoft Azure.
Wanneer u uw volledige back-up hebt teruggezet, wilt u deze mogelijk terugzetten naar een bepaald tijdstip. Point-in-time recovery zal de server up-to-date brengen naar een recenter tijdstip dan toen de volledige back-up werd gemaakt. Om dit te doen, moet u uw binaire logboeken hebben ingeschakeld. U kunt beschikbare binaire logbestanden controleren met:
mysql> SHOW BINARY LOGS;En actueel logbestand met:
SHOW MASTER STATUS;Vervolgens kunt u incrementele gegevens vastleggen door binaire logboeken door te geven aan het sql-bestand. Ontbrekende bewerkingen kunnen dan opnieuw worden uitgevoerd.
mysqlbinlog --start-position='14231131' --verbose /var/lib/mysql/binlog.000010 /var/lib/mysql/binlog.000011 /var/lib/mysql/binlog.000012 /var/lib/mysql/binlog.000013 /var/lib/mysql/binlog.000015 > binlog.outHetzelfde kan gedaan worden in ClusterControl.
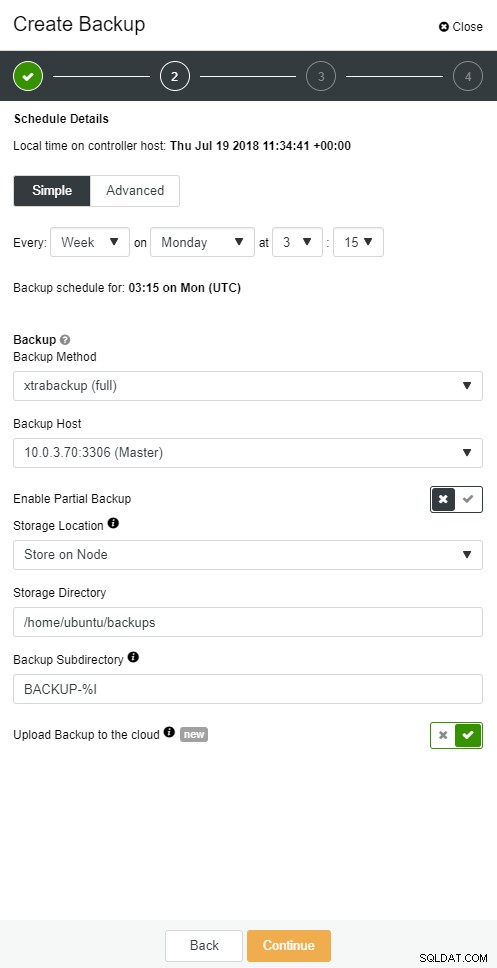 ClusterControl-cloudback-up
ClusterControl-cloudback-up 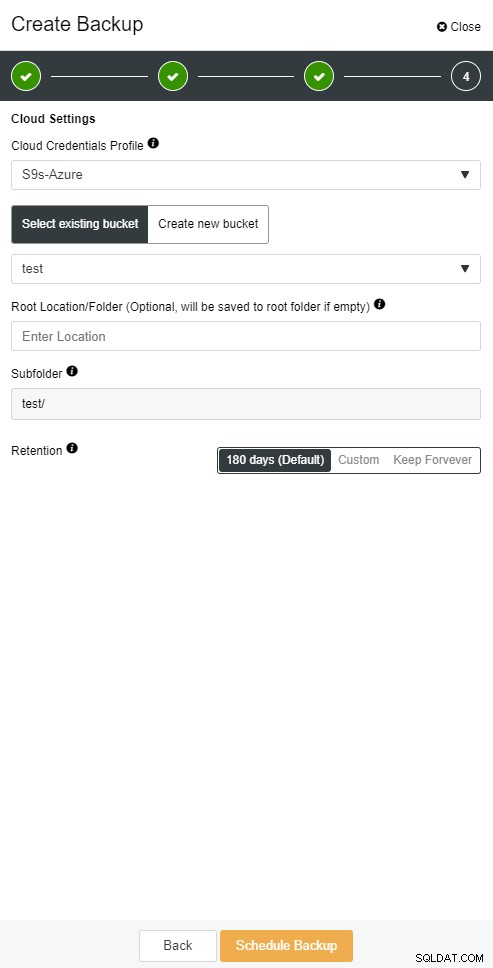 ClusterControl-cloudback-up
ClusterControl-cloudback-up Database-slave valt uit
Ok, je database draait dus op een dedicated server. Je hebt een uitgekiend back-upschema gemaakt met een combinatie van volledige en incrementele back-ups, uploadt deze naar de cloud en slaat de nieuwste back-up op lokale schijven op voor snel herstel. U heeft verschillende beleidsmaatregelen voor het bewaren van back-ups - korter voor back-ups die zijn opgeslagen op lokale schijfstuurprogramma's en uitgebreid voor uw cloudback-ups.
Het klinkt alsof je goed voorbereid bent op een rampscenario. Maar als het gaat om de hersteltijd, voldoet deze mogelijk niet aan uw zakelijke behoeften.
U hebt een snelle failover-functie nodig. Een server die actief is en binaire logboeken toepast van de master waar de schrijfbewerkingen plaatsvinden. Master/slave-replicatie begint een nieuw hoofdstuk in het failover-scenario. Het is een snelle methode om je applicatie weer tot leven te brengen als je het onder de knie hebt.
Maar er zijn weinig dingen waarmee u rekening moet houden in het failover-scenario. Een daarvan is het instellen van een vertraagde replicatieslave, zodat u kunt reageren op dikke vingercommando's die op de masterserver zijn geactiveerd. Een slave-server kan minimaal een bepaalde tijd achterlopen op de master. De standaardvertraging is 0 seconden. Gebruik de MASTER_DELAY optie voor CHANGE MASTER TO om de vertraging in te stellen op N seconden:
CHANGE MASTER TO MASTER_DELAY = N;De tweede is het inschakelen van geautomatiseerde failover. Er zijn veel geautomatiseerde failover-oplossingen op de markt. U kunt automatische failover instellen met opdrachtregelprogramma's zoals MHA, MRM, mysqlfailover of GUI Orchestrator en ClusterControl. Als het correct is ingesteld, kan het uw uitval aanzienlijk verminderen.
ClusterControl ondersteunt geautomatiseerde failover voor MySQL-, PostgreSQL- en MongoDB-replicaties, evenals multi-master clusteroplossingen Galera en NDB.
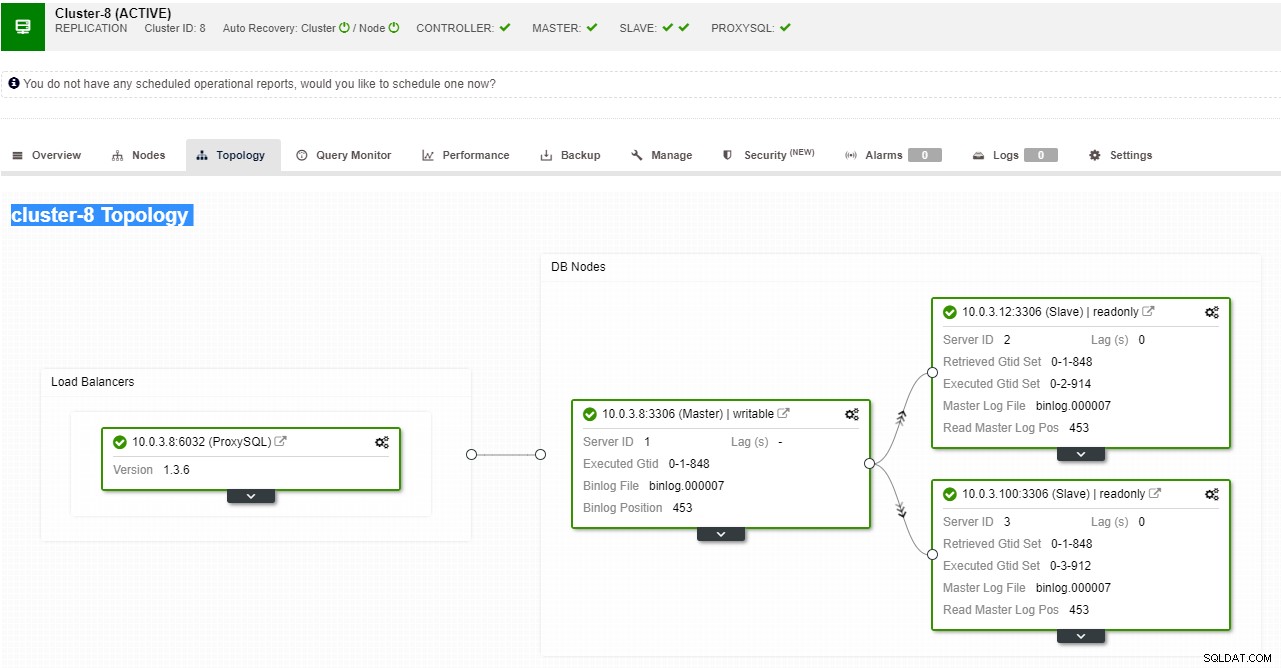 ClusterControl-weergave van replicatietopologie
ClusterControl-weergave van replicatietopologie Wanneer een slave-node crasht en de server ernstig achterloopt, wil je misschien je slave-server opnieuw opbouwen. Het proces voor het opnieuw opbouwen van een slave is vergelijkbaar met het herstellen van een back-up.
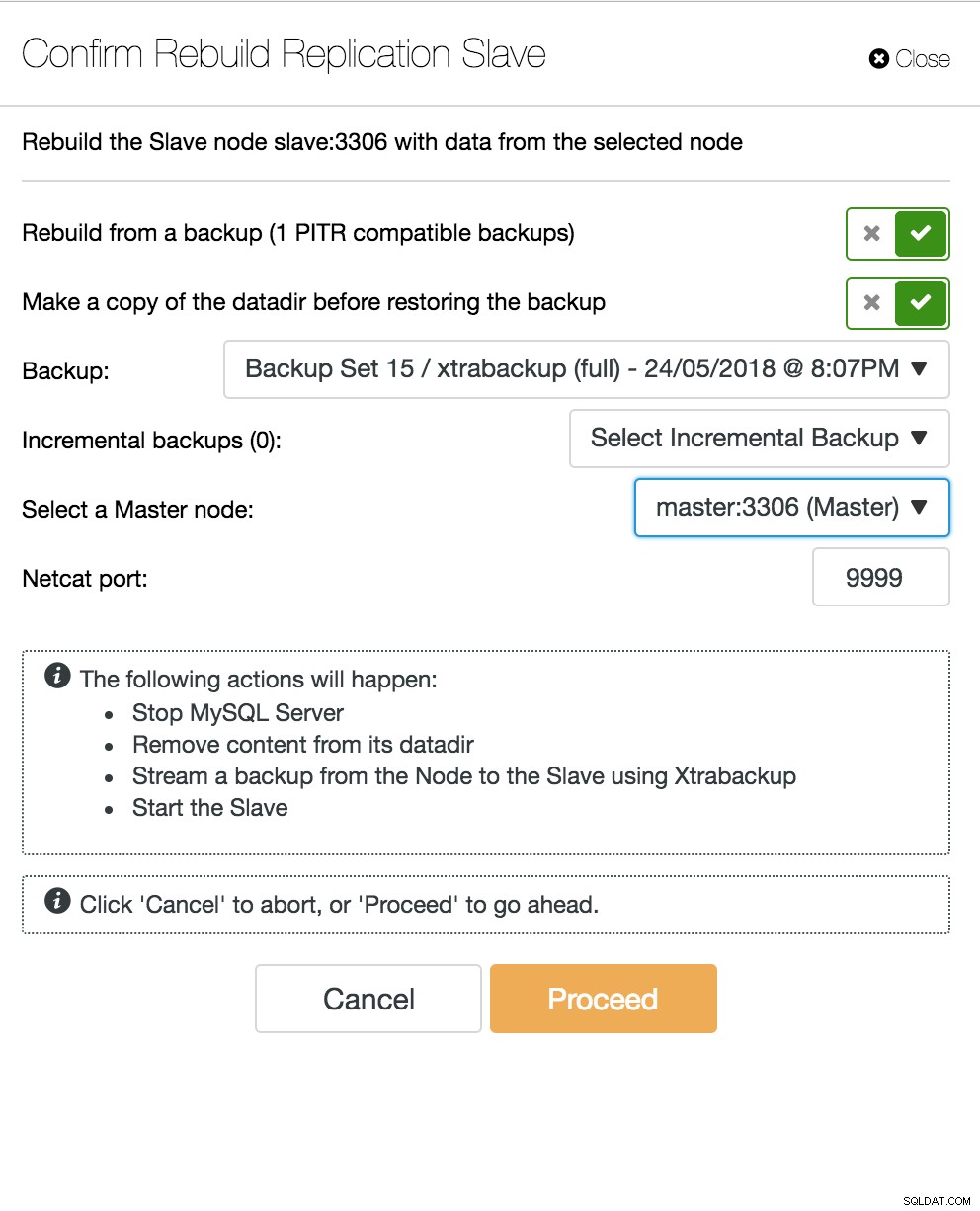 ClusterControl-slaaf opnieuw opbouwen
ClusterControl-slaaf opnieuw opbouwen Database Multi-Master Server gaat uit
Als je nu een slave-server hebt die fungeert als een DR-knooppunt en je failover-proces goed is geautomatiseerd en getest, wordt je DBA-leven comfortabeler. Dat is waar, maar er zijn nog een paar puzzels om op te lossen. Computerkracht is niet gratis, en uw bedrijfsteam kan u vragen om uw hardware beter te gebruiken. Misschien wilt u uw slave-server niet alleen als passieve server gebruiken, maar ook voor schrijfbewerkingen.
Mogelijk wilt u dan een multi-master replicatie-oplossing onderzoeken. Galera Cluster is een reguliere optie geworden voor MySQL en MariaDB met hoge beschikbaarheid. En hoewel het nu bekend staat als een geloofwaardige vervanging voor traditionele MySQL master-slave-architecturen, is het geen drop-in vervanging.
Galera-cluster heeft een gedeelde niets-architectuur. In plaats van gedeelde schijven gebruikt Galera op certificering gebaseerde replicatie met groepscommunicatie en transactiebestelling om synchrone replicatie te bereiken. Een databasecluster moet een verlies van een knoop punt kunnen overleven, hoewel dit op verschillende manieren wordt bereikt. In het geval van Galera is het kritische aspect het aantal knooppunten. Galera heeft een quorum nodig om operationeel te blijven. Een cluster met drie knooppunten kan de crash van één knooppunt overleven. Met meer nodes in uw cluster, kunt u meer mislukkingen overleven.
Het herstelproces is geautomatiseerd, zodat u geen failover-bewerkingen hoeft uit te voeren. Het is echter een goede gewoonte om knooppunten te doden en te kijken hoe snel je ze terug kunt brengen. Om deze bewerking efficiënter te maken, kunt u de grootte van de galera-cache wijzigen. Als de grootte van de galera-cache niet goed is gepland, moet uw volgende opstartknooppunt een volledige back-up maken in plaats van alleen de ontbrekende schrijfsets in de cache.
Het failover-scenario is eenvoudig als het starten van de instance. Op basis van de gegevens in de galera-cache, voert het opstartknooppunt SST (herstel vanaf volledige back-up) of IST uit (past ontbrekende schrijfsets toe). Dit is echter vaak gekoppeld aan menselijk ingrijpen. Als u het volledige failoverproces wilt automatiseren, kunt u de autorecovery-functionaliteit van ClusterControl gebruiken (knooppunt- en clusterniveau).
 ClusterControl-cluster automatisch herstellen
ClusterControl-cluster automatisch herstellen Schat de grootte van de galera-cache:
MariaDB [(none)]> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;Om failover consistenter te maken, moet u gcache.recover=yes inschakelen in mycnf. Deze optie zal de galera-cache bij herstart doen herleven. Dit betekent dat het knooppunt kan fungeren als DONOR en ontbrekende schrijfsets kan bedienen (waardoor IST wordt vergemakkelijkt in plaats van SST te gebruiken).
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 2,
members = 2/3 (joined/total),
act_id = 12810,
last_appl. = 0,
protocols = 0/7/3 (gcs/repl/appl),
group UUID = 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Trying to continue unpaused monitor
2018-07-20 8:59:44 139657311033088 [Note] WSREP: New cluster view: global state: 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69:12810, view# 3: Primary, number of nodes: 3, my index: 1, protocol version 3Proxy SQL-knooppunt valt uit
Als je een virtuele IP-configuratie hebt, hoef je alleen maar je applicatie naar het virtuele IP-adres te verwijzen en alles zou correct moeten zijn qua verbinding. Het is niet voldoende om uw database-instances over meerdere datacenters te hebben, u hebt nog steeds uw applicaties nodig om er toegang toe te krijgen. Stel dat u het aantal leesreplica's hebt uitgeschaald, wilt u misschien ook virtuele IP's voor elk van die leesreplica's implementeren vanwege onderhouds- of beschikbaarheidsredenen. Het kan een omslachtige pool van virtuele IP's worden die u moet beheren. Als een van die leesreplica's crasht, moet u het virtuele IP-adres opnieuw toewijzen aan de andere host, anders zal uw toepassing verbinding maken met een host die niet beschikbaar is of in het ergste geval een achterblijvende server met verouderde gegevens.
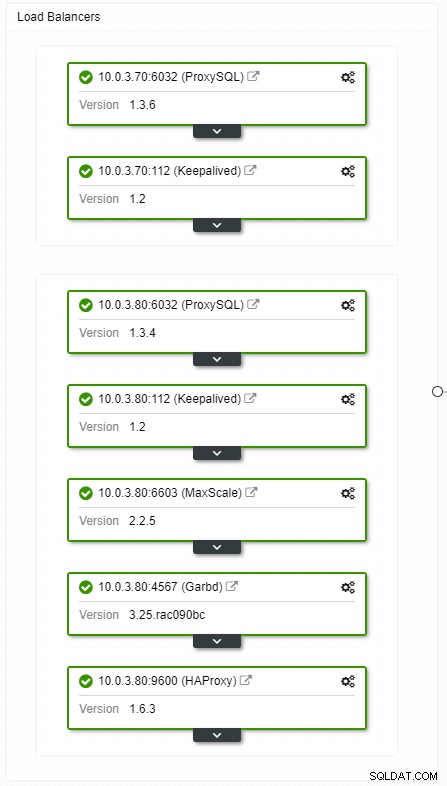 ClusterControl HA load balancers topologieweergave
ClusterControl HA load balancers topologieweergave Crashes komen niet vaak voor, maar waarschijnlijker dan het uitvallen van servers. Als om wat voor reden dan ook een slave uitvalt, zal zoiets als ProxySQL al het verkeer naar de master omleiden, met het risico deze te overbelasten. Wanneer de slaaf herstelt, wordt het verkeer ernaar teruggestuurd. Gewoonlijk duurt zo'n uitvaltijd niet langer dan een paar minuten, dus de algehele ernst is gemiddeld, ook al is de kans ook gemiddeld.
Om uw load balancer-componenten redundant te hebben, kunt u keepalive gebruiken.
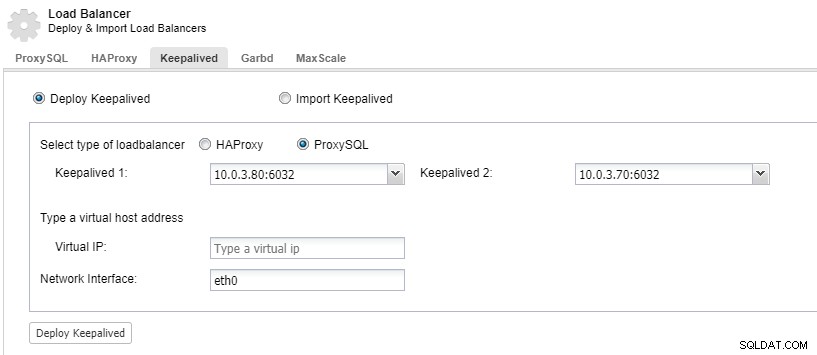 ClusterControl:Keepalive implementeren voor ProxySQL-load balancer
ClusterControl:Keepalive implementeren voor ProxySQL-load balancer Datacenter valt uit
Het grootste probleem met replicatie is dat er geen meerderheidsmechanisme is om een datacenterstoring te detecteren en een nieuwe master te bedienen. Een van de voornemens is om Orchestrator/Raft te gebruiken. Orchestrator is een topologiesupervisor die failovers kan beheren. Bij gebruik in combinatie met Raft wordt Orchestrator quorumbewust. Een van de Orchestrator-instanties wordt gekozen als leider en voert hersteltaken uit. De verbinding tussen de orchestrator-node correleert niet met de transactiedatabase-commits en is schaars.
Orchestrator/Raft kan extra instances gebruiken die monitoring van de topologie uitvoeren. In het geval van netwerkpartitionering zullen de gepartitioneerde Orchestrator-instanties geen actie ondernemen. Het deel van het Orchestrator-cluster dat het quorum heeft, kiest een nieuwe master en brengt de nodige topologiewijzigingen aan.
ClusterControl wordt gebruikt voor beheer, schaling en, het belangrijkste, knooppuntherstel - Orchestrator zou failovers afhandelen, maar als een slave zou crashen, zorgt ClusterControl ervoor dat deze wordt hersteld. Orchestrator en ClusterControl zouden zich in dezelfde beschikbaarheidszone bevinden, gescheiden van de MySQL-knooppunten, om ervoor te zorgen dat hun activiteit niet wordt beïnvloed door netwerksplitsingen tussen beschikbaarheidszones in het datacenter.