Het Galera-cluster zorgt voor een sterke gegevensconsistentie, waarbij alle knooppunten in het cluster nauw met elkaar verbonden zijn. Hoewel netwerksegmentatie wordt ondersteund, zijn de replicatieprestaties nog steeds gebonden aan twee factoren:
-
De round trip time (RTT) naar het verste knooppunt in het cluster vanaf het oorspronkelijke knooppunt.
-
De grootte van een schrijfset die moet worden overgedragen en gecertificeerd voor conflict op het ontvangerknooppunt.
Hoewel er manieren zijn om de prestaties van Galera te verbeteren, is het niet mogelijk om deze twee beperkende factoren te omzeilen.
Gelukkig is Galera Cluster bovenop MySQL gebouwd, dat ook wordt geleverd met een ingebouwde replicatiefunctie (duh!). Zowel Galera-replicatie als MySQL-replicatie bestaan onafhankelijk van elkaar in dezelfde serversoftware. We kunnen deze technologieën gebruiken om samen te werken, waarbij alle replicatie binnen een datacenter op Galera zal plaatsvinden, terwijl replicatie tussen datacenters op standaard MySQL-replicatie zal plaatsvinden. De slave-site kan fungeren als een hot-standby-site, klaar om gegevens te leveren zodra de applicaties zijn omgeleid naar de back-upsite. We hebben dit besproken in een eerdere blog over MySQL-architecturen voor noodherstel.
Cluster-naar-cluster replicatie is geïntroduceerd in ClusterControl in versie 1.7.4. In deze blogpost laten we zien hoe eenvoudig het is om replicatie tussen twee Galera-clusters (PXC 8.0) in te stellen. Dan kijken we naar het meer uitdagende deel:het afhandelen van storingen op zowel knooppunt- als clusterniveau met behulp van ClusterControl; failover- en failback-bewerkingen zijn cruciaal voor het behoud van de gegevensintegriteit in het hele systeem.
Clusterimplementatie
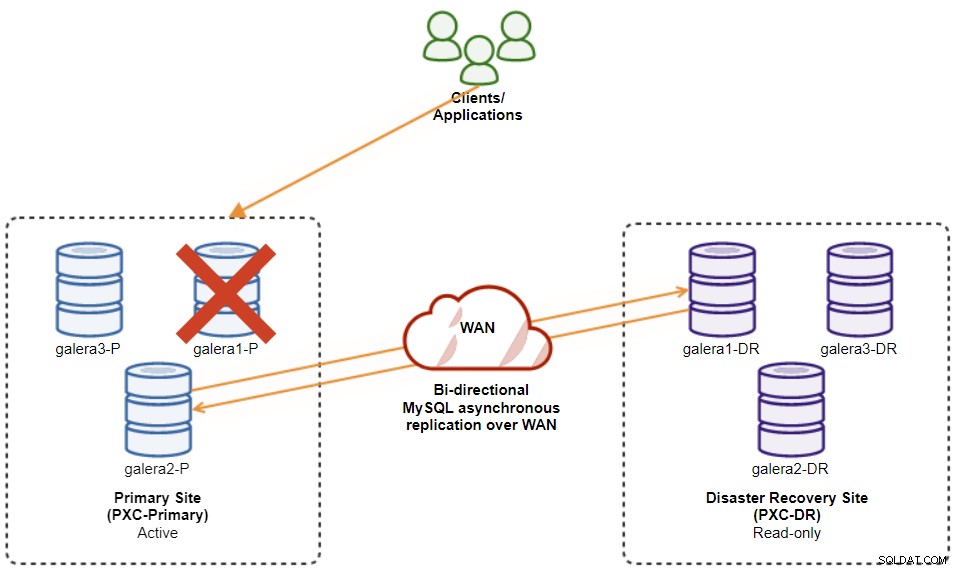
Voor ons voorbeeld hebben we minimaal twee clusters en twee sites nodig:één voor de primaire en een andere voor de secundaire. Het werkt op dezelfde manier als traditionele MySQL-master-slave-replicatie, maar op grotere schaal met drie databaseknooppunten op elke site. Met ClusterControl zou u dit bereiken door een primaire cluster te implementeren, gevolgd door de secundaire cluster op de rampherstelsite te implementeren als een replicacluster, gerepliceerd door een bidirectionele asynchrone replicatie.
Het volgende diagram illustreert onze uiteindelijke architectuur:

We hebben in totaal zes databaseknooppunten, drie op de primaire site en nog een drie op de site voor noodherstel. Om de knooppuntweergave te vereenvoudigen, gebruiken we de volgende notaties:
-
Primaire site:
-
galera1-P - 192.168.11.171 (master)
-
galera2-P - 192.168.11.172
-
galera3-P - 192.168.11.173
-
-
Site voor noodherstel:
-
galera1-DR - 192.168.11.181 (slaaf)
-
galera2-DR - 192.168.11.182
-
galera3-DR - 192.168.11.183
-
Eerst, implementeer eenvoudig het eerste cluster, en we noemen het PXC-Primary. Open ClusterControl UI → Deploy → MySQL Galera en voer alle vereiste details in:
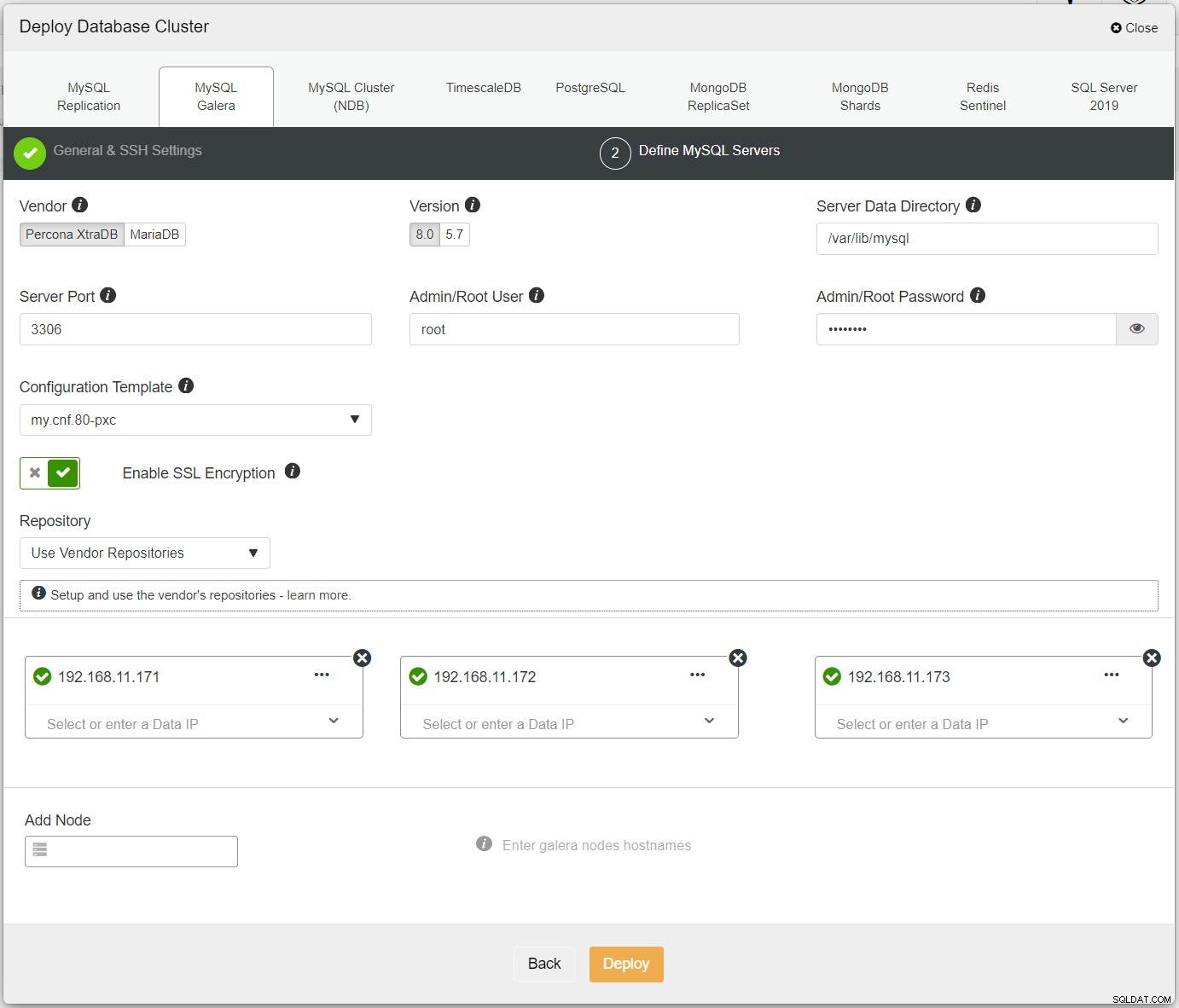
Zorg ervoor dat er naast elk opgegeven knooppunt een groen vinkje staat, wat aangeeft dat ClusterControl kan verbinding maken met de host via SSH zonder wachtwoord. Klik op Implementeren en wacht tot de implementatie is voltooid. Als u klaar bent, ziet u het volgende cluster op de clusterdashboardpagina:
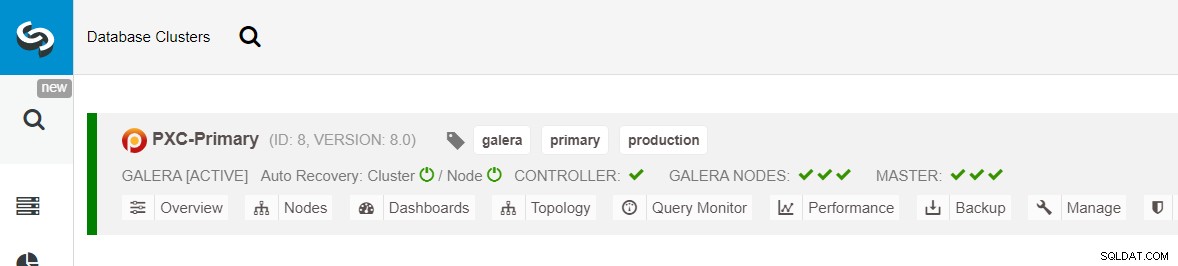
Vervolgens gebruiken we de functie ClusterControl genaamd Create Replica Cluster, toegankelijk via de vervolgkeuzelijst Clusteractie:
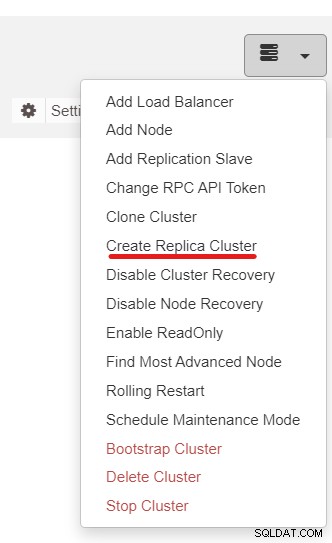
Je krijgt de volgende zijbalk-pop-up te zien:
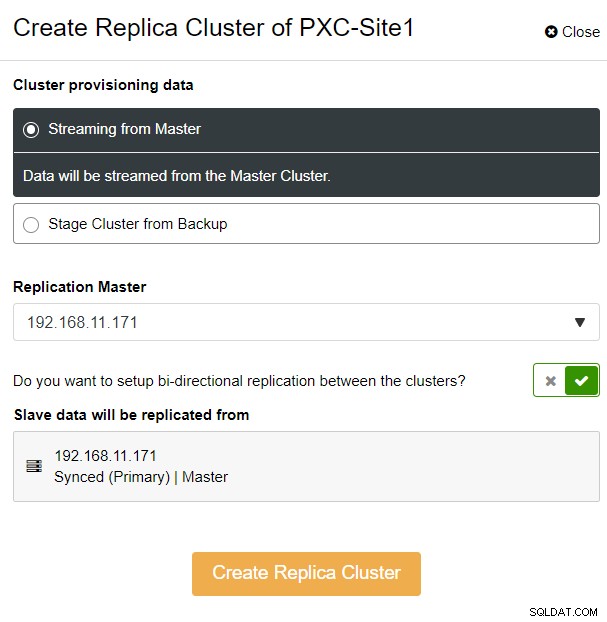
We hebben gekozen voor de optie "Streaming from Master", waarbij ClusterControl de gekozen master om het replicacluster te synchroniseren en de replicatie te configureren. Besteed aandacht aan de optie voor bidirectionele replicatie. Indien ingeschakeld, zal ClusterControl een bidirectionele replicatie tussen beide sites opzetten (circulaire replicatie). De gekozen master wordt gerepliceerd vanaf de eerste master die is gedefinieerd voor het replicacluster en vice versa. Deze setup minimaliseert de faseringstijd die nodig is bij het herstellen na een failover of failback. Klik op "Replicacluster maken", waar ClusterControl een nieuwe implementatiewizard voor het replicacluster opent, zoals hieronder weergegeven:
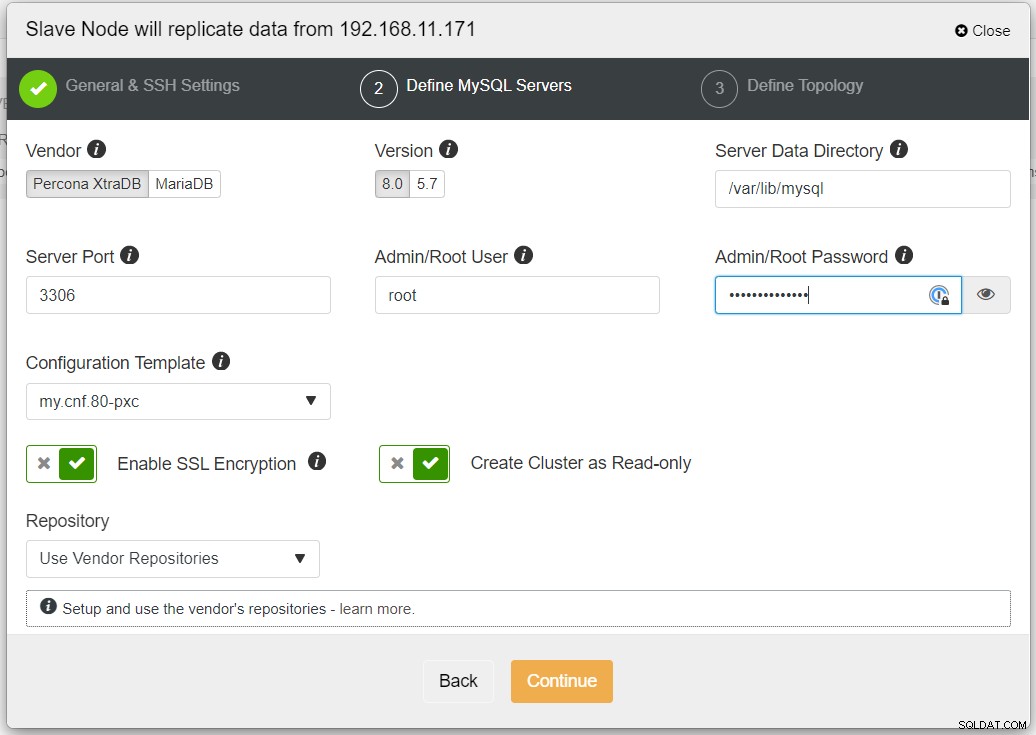
Het wordt aanbevolen om SSL-codering in te schakelen als de replicatie betrekking heeft op niet-vertrouwde netwerken zoals WAN, niet-getunnelde netwerken of internet. Zorg er ook voor dat "Cluster maken als alleen-lezen" is ingeschakeld; dit is de bescherming tegen onbedoeld schrijven en een goede indicator om gemakkelijk onderscheid te maken tussen het actieve cluster (lezen-schrijven) en het passieve cluster (alleen-lezen).
Wanneer u alle benodigde informatie invult, moet u de volgende fase bereiken om de replicaclustertopologie te definiëren:
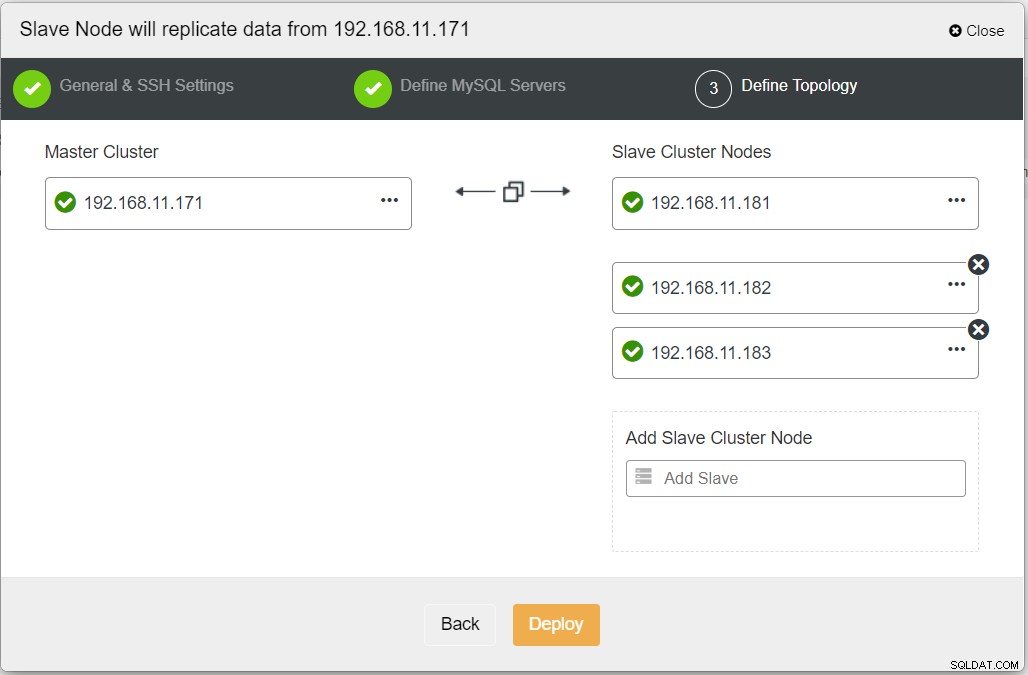
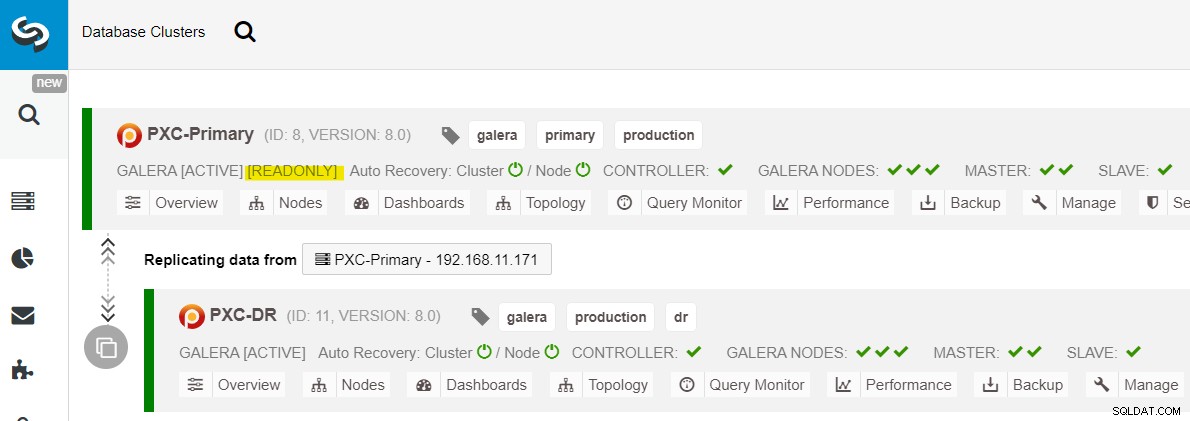
Vanaf het ClusterControl-dashboard zou u, zodra de implementatie is voltooid, de DR-site heeft een bidirectionele pijl die is verbonden met de primaire site:
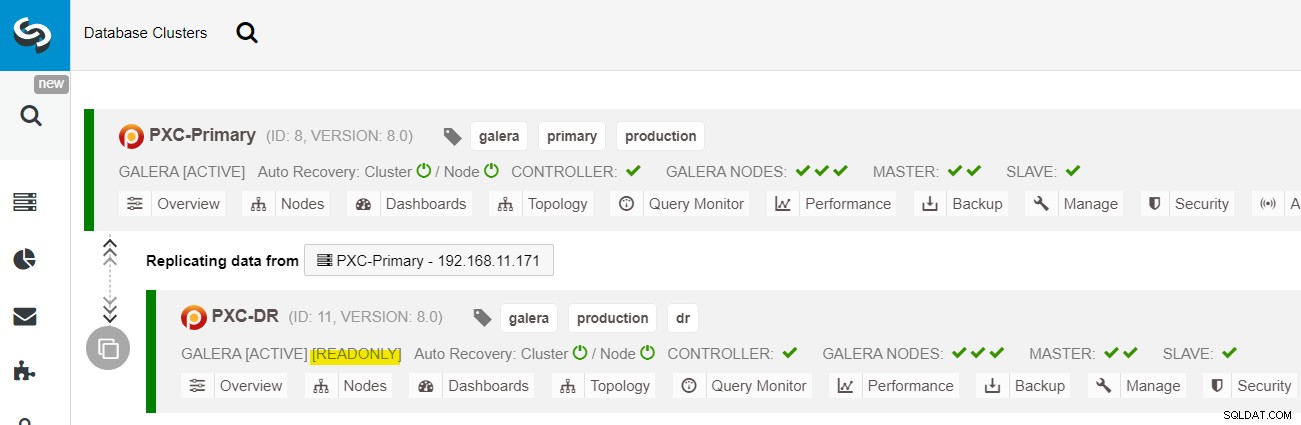
De implementatie is nu voltooid. Toepassingen mogen alleen schrijfbewerkingen naar de primaire site verzenden, aangezien dit de actieve site is en de DR-site is geconfigureerd voor alleen-lezen (gemarkeerd in geel). Leesbewerkingen kunnen naar beide sites worden verzonden, hoewel de DR-site het risico loopt achter te blijven vanwege het asynchrone replicatiekarakter. Deze opstelling maakt de primaire en noodherstelsites onafhankelijk van elkaar, losjes verbonden met asynchrone replicatie. Een van de Galera-knooppunten op de DR-site zal een slaaf zijn die repliceert vanaf een van de Galera-knooppunten (master) op de primaire site.
We hebben nu een systeem waarbij een clusterstoring op de primaire site geen invloed heeft op de back-upsite. Wat de prestaties betreft, heeft de WAN-latentie geen invloed op updates op het actieve cluster. Deze worden asynchroon naar de back-upsite verzonden.
Als kanttekening is het ook mogelijk om een speciale slave-instantie als replicatierelay te gebruiken in plaats van een van de Galera-knooppunten als slave te gebruiken.
Galera Node Failover-procedure
In het geval dat de huidige master (galera1-P) faalt en de resterende nodes in de primaire site nog steeds actief zijn, moet de slave op de noodherstelsite (galera1-DR) worden doorgestuurd naar alle beschikbare masters op de primaire site, zoals weergegeven in het volgende diagram:
Van de ClusterControl-clusterlijst kunt u zien dat de clusterstatus verslechterd is , en als u over het uitroeptekenpictogram rolt, ziet u de fout voor dat specifieke knooppunt (galera1-P):
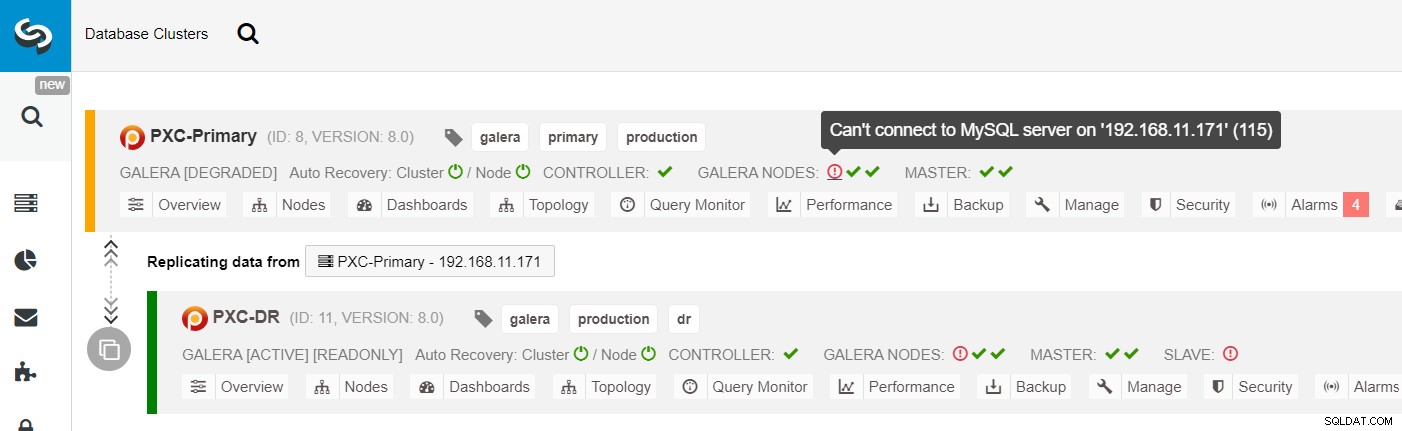
Met ClusterControl kunt u eenvoudig naar PXC-DR cluster → Nodes → kies galera1-DR → Node Actions → Rebuild Replication Slave, en u krijgt het volgende configuratiedialoogvenster te zien:
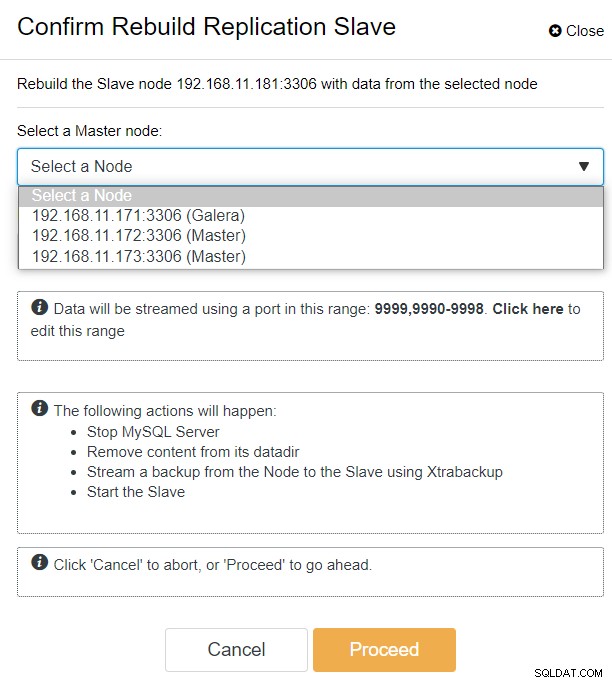
We kunnen alle Galera-knooppunten zien op de primaire site (192.168.11.17x ) uit de vervolgkeuzelijst. Kies het secundaire knooppunt, 192.168.11.172 (galera2-P), en klik op Doorgaan. ClusterControl configureert vervolgens de replicatietopologie zoals het hoort en stelt bidirectionele replicatie in van galera2-P naar galera1-DR. U kunt dit bevestigen vanaf de clusterdashboardpagina (geel gemarkeerd):
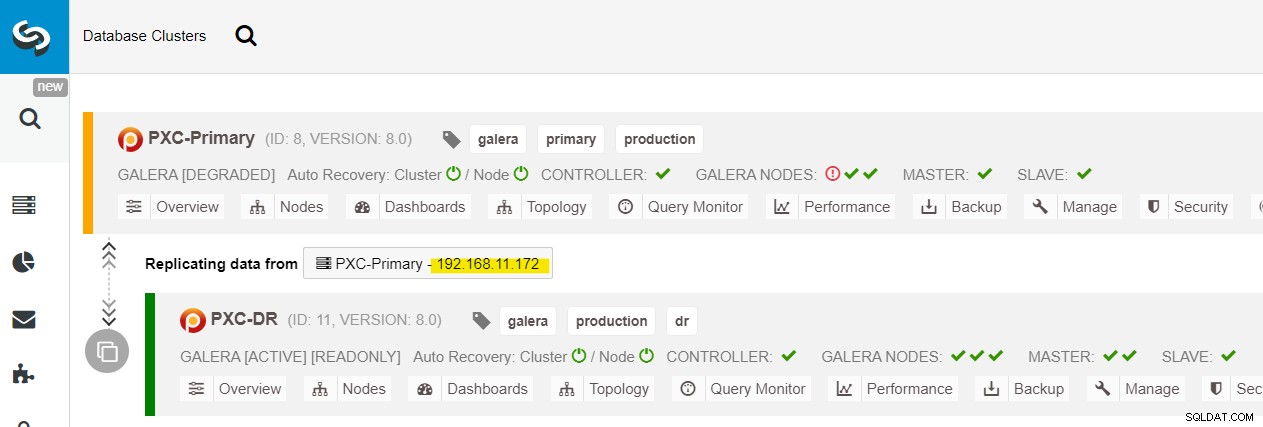
Op dit moment wordt het primaire cluster (PXC-Primary) nog steeds gebruikt als het actieve cluster voor deze topologie. Het zou geen invloed moeten hebben op de uptime van de databaseservice van het primaire cluster.
Galera-clusterfailoverprocedure
Als het primaire cluster uitvalt, crasht of simpelweg de verbinding verliest vanuit het oogpunt van de applicatie, kan de applicatie vrijwel onmiddellijk naar de DR-site worden geleid. De SysAdmin hoeft alleen alleen-lezen op alle Galera-knooppunten op de rampherstelsite uit te schakelen door de volgende instructie te gebruiken:
mysql> SET GLOBAL read_only = 0; -- repeat on galera1-DR, galera2-DR, galera3-DRVoor ClusterControl-gebruikers kunt u ClusterControl UI → Nodes → kies het DB-knooppunt → Node-acties → Alleen-lezen uitschakelen. ClusterControl CLI is ook beschikbaar door de volgende opdrachten uit te voeren op het ClusterControl-knooppunt:
$ s9s node --nodes="192.168.11.181" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.182" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.183" --cluster-id=11 --set-read-writeDe failover naar de DR-site is nu voltooid en de toepassingen kunnen beginnen met het verzenden van schrijfbewerkingen naar het PXC-DR-cluster. In de gebruikersinterface van ClusterControl zou u zoiets als dit moeten zien:
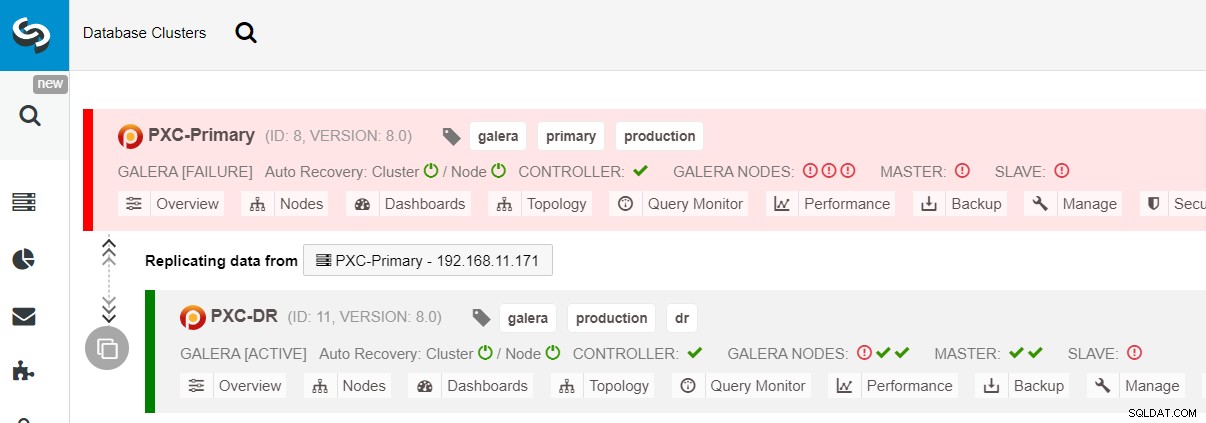
Het volgende diagram toont onze architectuur nadat de toepassing mislukte naar de DR-site :
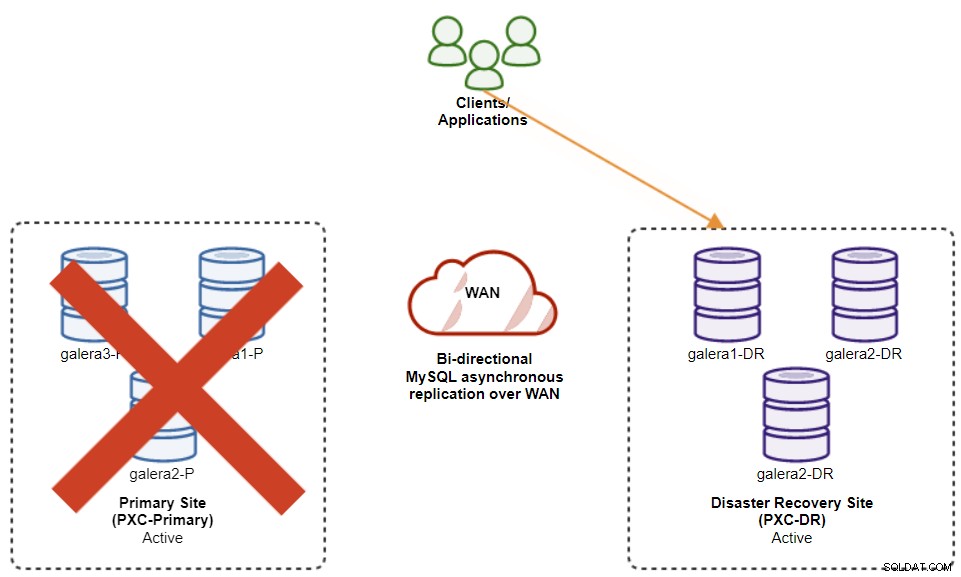
Ervan uitgaande dat de primaire site nog steeds niet beschikbaar is, is er op dit moment geen replicatie tussen sites totdat de primaire site weer beschikbaar is.
Failback-procedure Galera-cluster
Nadat de primaire site is geopend, is het belangrijk op te merken dat het primaire cluster moet worden ingesteld op alleen-lezen, zodat we weten dat het actieve cluster het cluster is op de site voor noodherstel. Ga vanuit ClusterControl naar het vervolgkeuzemenu van het cluster en kies "Alleen-lezen inschakelen", waarmee alleen-lezen op alle knooppunten in het primaire cluster wordt ingeschakeld en de huidige topologie als volgt wordt samengevat:
Zorg ervoor dat alles groen is voordat u de clusterfailback-procedure start (groen betekent dat alle knooppunten actief zijn en met elkaar zijn gesynchroniseerd). Als er bijvoorbeeld een node in degraderende status is, loopt de replicerende node nog steeds achter, of waren slechts enkele van de nodes in het primaire cluster bereikbaar, wacht dan tot het cluster volledig is hersteld, ofwel door te wachten op de automatische herstelprocedures van ClusterControl om te voltooien, of handmatige interventie.
Op dit moment is het actieve cluster nog steeds het cluster van de DR en fungeert het primaire cluster als een secundair cluster. Het volgende diagram illustreert de huidige architectuur:
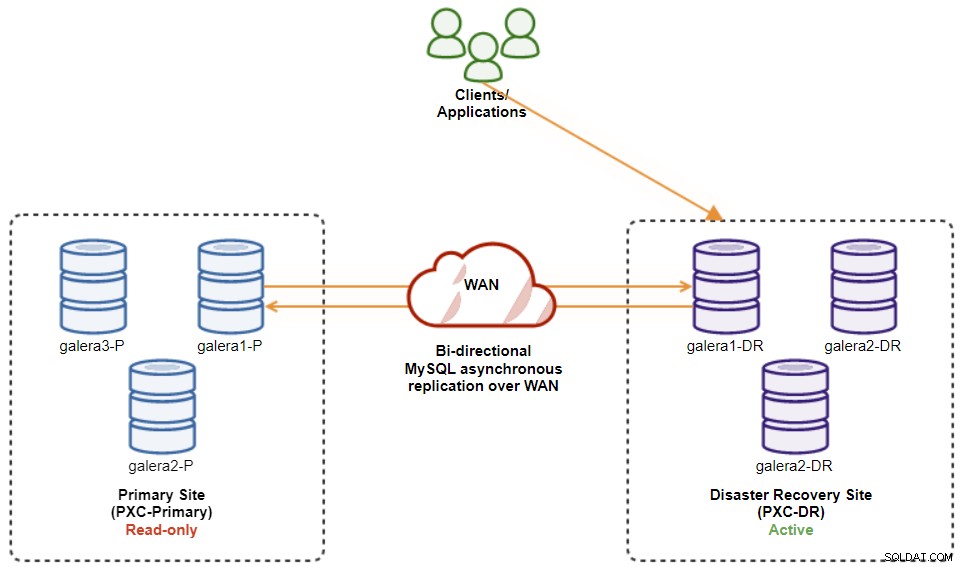
De veiligste manier om naar de primaire site te failbacken is om alleen-lezen in te stellen op het cluster van de DR, gevolgd door het uitschakelen van alleen-lezen op de primaire site. Ga naar ClusterControl UI → PXC-DR (vervolgkeuzemenu) → Alleen-lezen inschakelen. Hierdoor wordt een taak geactiveerd om alleen-lezen in te stellen op alle knoop punten op het cluster van de DR. Ga dan naar ClusterControl UI → PXC-Primary → Nodes en schakel alleen-lezen uit op alle databasenodes in het primaire cluster.
U kunt de bovenstaande procedures ook vereenvoudigen met ClusterControl CLI. U kunt ook de volgende opdrachten uitvoeren op de ClusterControl-host:
$ s9s cluster --cluster-id=11 --set-read-only # enable cluster-wide read-only
$ s9s node --nodes="192.168.11.171" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.172" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.173" --cluster-id=8 --set-read-writeAls je klaar bent, is de replicatierichting teruggegaan naar de oorspronkelijke configuratie, waarbij PXC-Primary het actieve cluster is en PXC-DR het standby-cluster. Het volgende diagram illustreert de uiteindelijke architectuur na de clusterfailback-bewerking:
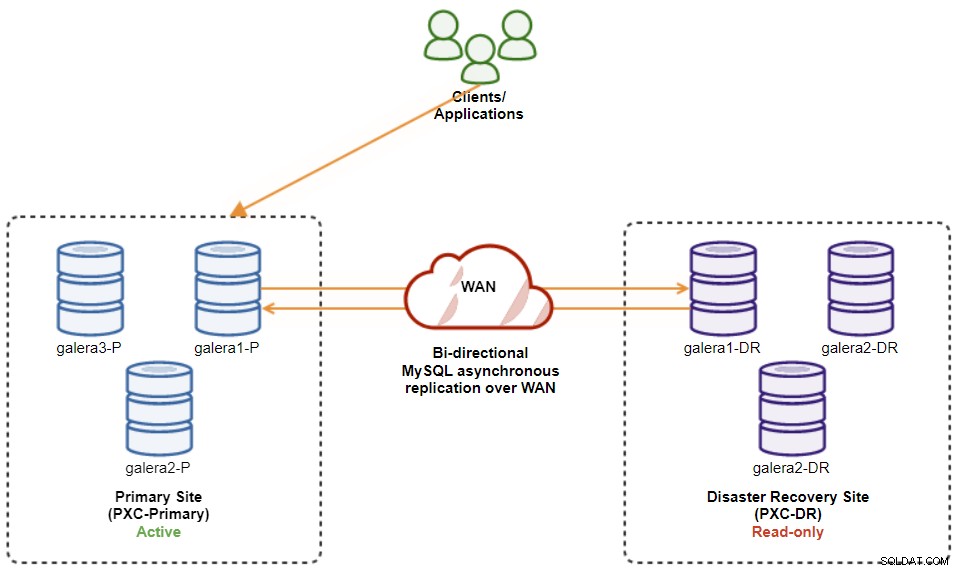
Op dit moment is het veilig om de applicaties om te leiden naar de primaire site.
Voordelen van cluster-naar-cluster asynchrone replicatie
Cluster-naar-cluster met asynchrone replicatie heeft een aantal voordelen:
-
Minimale uitvaltijd tijdens een database-failover-bewerking. In principe kunt u het schrijven vrijwel onmiddellijk omleiden naar de slave-site, alleen als u de schrijfbewerkingen kunt beveiligen om de hoofdsite niet te bereiken (omdat deze schrijfbewerkingen niet worden gerepliceerd en waarschijnlijk worden overschreven wanneer opnieuw wordt gesynchroniseerd vanaf de DR-site).
-
Geen invloed van de prestaties op de primaire site omdat deze onafhankelijk is van de back-up (DR)-site. Replicatie van master naar slave wordt asynchroon uitgevoerd. De mastersite genereert binaire logboeken, de slave-site repliceert de gebeurtenissen en past de gebeurtenissen op een later tijdstip toe.
-
Disaster recovery-sites kunnen voor andere doeleinden worden gebruikt, bijvoorbeeld databaseback-up, binaire logback-up en rapportage, of zware analytische vragen (OLAP). Beide sites kunnen tegelijkertijd worden gebruikt, behalve de replicatievertraging en alleen-lezen bewerkingen aan de slave-kant.
-
Het DR-cluster kan mogelijk worden uitgevoerd op kleinere instanties in een openbare cloudomgeving, zolang ze het kunnen bijhouden met het primaire cluster. U kunt de instanties indien nodig upgraden. In bepaalde scenario's kan het u wat kosten besparen.
-
Je hebt maar één extra site nodig voor Disaster Recovery vergeleken met de active-active Galera multi-site replicatie setup, die vereist ten minste drie actieve sites om correct te werken.
Nadelen van cluster-naar-cluster asynchrone replicatie
Er zijn ook nadelen aan deze opstelling, afhankelijk van of u bidirectionele of unidirectionele replicatie gebruikt:
-
Er is een kans dat er gegevens ontbreken tijdens de failover als de slaaf achterblijft, aangezien replicatie asynchroon is. Dit kan worden verbeterd met semi-synchrone en multi-threaded slave-replicatie, hoewel er nog een reeks uitdagingen wacht (netwerkoverhead, replicatiegat, enz.).
-
In unidirectionele replicatie, ondanks dat de failover-procedures vrij eenvoudig zijn, kunnen de failback-procedures lastig zijn en vatbaar voor menselijke fout. Het vereist enige expertise om de master/slave-rol terug te schakelen naar de primaire site. Het wordt aanbevolen om de procedures gedocumenteerd te houden, de failover/failback-bewerking regelmatig te oefenen en nauwkeurige rapportage- en monitoringtools te gebruiken.
-
Het kan behoorlijk duur zijn, omdat u een vergelijkbaar aantal knooppunten moet instellen op de site voor noodherstel . Dit is niet zwart-wit, aangezien de kostenverantwoording meestal voortkomt uit de vereisten van uw bedrijf. Met enige planning is het mogelijk om het gebruik van databasebronnen op beide sites te maximaliseren, ongeacht de databaserollen.
Afronden
Het instellen van asynchrone replicatie voor uw MySQL Galera-clusters kan een relatief eenvoudig proces zijn, zolang u maar begrijpt hoe u fouten op zowel knooppunt- als clusterniveau op de juiste manier kunt afhandelen. Uiteindelijk zijn failover- en failback-operaties van cruciaal belang om de gegevensintegriteit te waarborgen.
Voor meer tips over het ontwerpen van uw Galera-clusters met failover- en failback-strategieën in gedachten, bekijk dit bericht over MySQL-architecturen voor noodherstel. Als u hulp zoekt bij het automatiseren van deze bewerkingen, evalueer dan ClusterControl 30 dagen gratis en volg de stappen in dit bericht.
Vergeet ons niet te volgen op Twitter of LinkedIn en u te abonneren op onze nieuwsbrief, blijf op de hoogte van het laatste nieuws en best practices voor het beheer van uw open-source database-infrastructuren.