In het commentaargedeelte van een van onze blogs vroeg een lezer naar de impact van wsrep_slave_threads op de I/O-prestaties en schaalbaarheid van Galera Cluster. Op dat moment konden we die vraag niet gemakkelijk beantwoorden en er een back-up van maken met meer gegevens, maar uiteindelijk zijn we erin geslaagd om de omgeving op te zetten en enkele tests uit te voeren.
Onze lezer wees op benchmarks die aantoonden dat het verhogen van wsrep_slave_threads geen invloed had op de prestaties van het Galera-cluster.
Om uit te leggen wat de impact van die instelling is, hebben we een klein cluster van drie nodes opgezet (m5d.xlarge). Hierdoor konden we direct aangesloten nvme SSD gebruiken voor de MySQL-gegevensdirectory. Door dit te doen, hebben we de kans geminimaliseerd dat opslag het knelpunt wordt in onze opstelling.
We hebben de InnoDB-bufferpool ingesteld op 8 GB en loggen opnieuw in twee bestanden van elk 1 GB. We hebben ook innodb_io_capacity verhoogd tot 2000 en innodb_io_capacity_max tot 10000. Dit was ook bedoeld om ervoor te zorgen dat geen van deze instellingen onze prestaties zou beïnvloeden.
Het hele probleem met dergelijke benchmarks is dat er zoveel knelpunten zijn dat je ze één voor één moet elimineren. Pas na wat configuratie-afstemming en nadat we ervoor hebben gezorgd dat de hardware geen probleem zal zijn, kan men hopen dat er wat subtielere limieten zullen verschijnen.
We hebben ~90 GB aan gegevens gegenereerd met sysbench:
sysbench /usr/share/sysbench/oltp_write_only.lua --threads=16 --events=0 --time=600 --mysql-host=172.30.4.245 --mysql-user=sbtest --mysql-password=sbtest --mysql-port=3306 --tables=28 --report-interval=1 --skip-trx=off --table-size=10000000 --db-ps-mode=disable --mysql-db=sbtest_large prepareDaarna is de benchmark uitgevoerd. We hebben twee instellingen getest:wsrep_slave_threads=1 en wsrep_slave_threads=16. De hardware was niet krachtig genoeg om te profiteren van het nog verder verhogen van deze variabele. Houd er ook rekening mee dat we geen gedetailleerde benchmarking hebben uitgevoerd om te bepalen of wsrep_slave_threads moet worden ingesteld op 16, 8 of misschien 4 voor de beste prestaties. We waren benieuwd of we een impact op het cluster kunnen laten zien. En ja, de impact was duidelijk zichtbaar. Om te beginnen enkele grafieken voor stroomregeling.
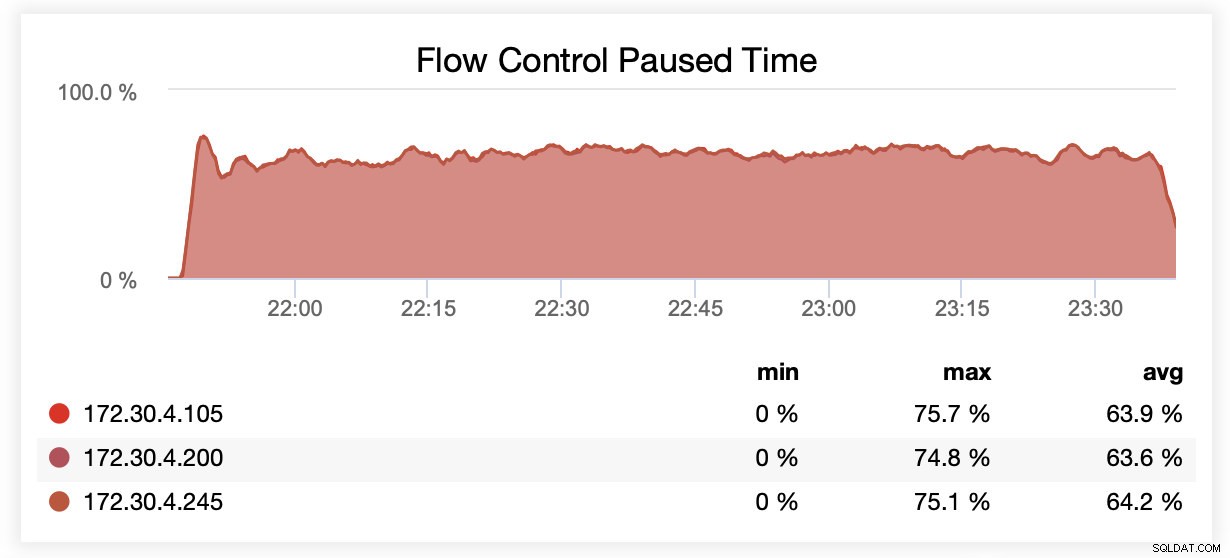
Tijdens het draaien met wsrep_slave_threads=1 werden nodes gemiddeld ~64% van de tijd gepauzeerd vanwege flow control.
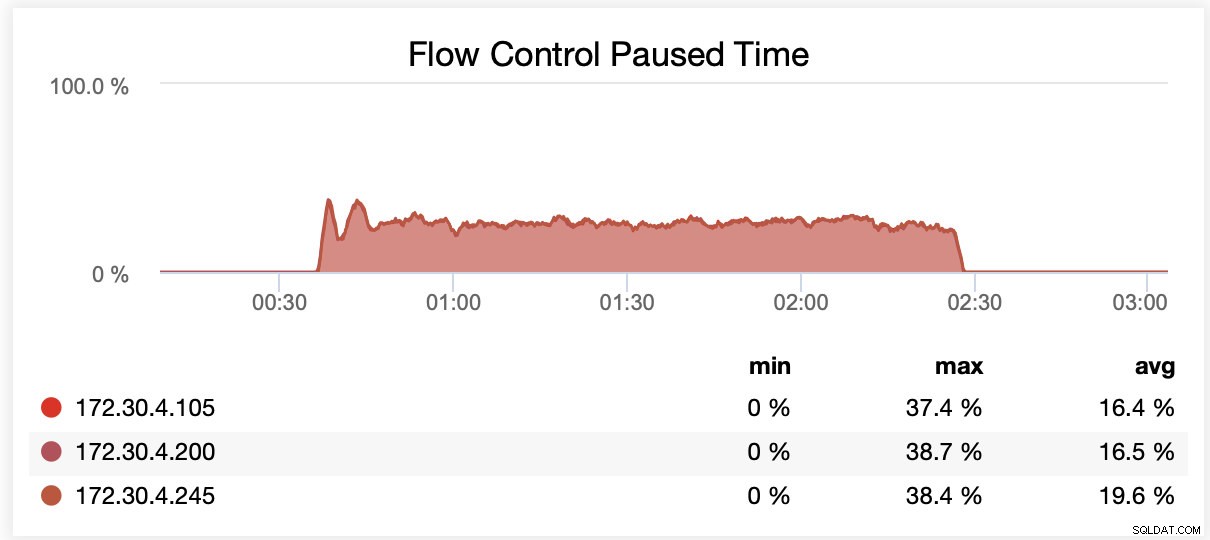
Tijdens het draaien met wsrep_slave_threads=16 werden nodes gemiddeld in ongeveer 20% van de gevallen gepauzeerd vanwege flow control.
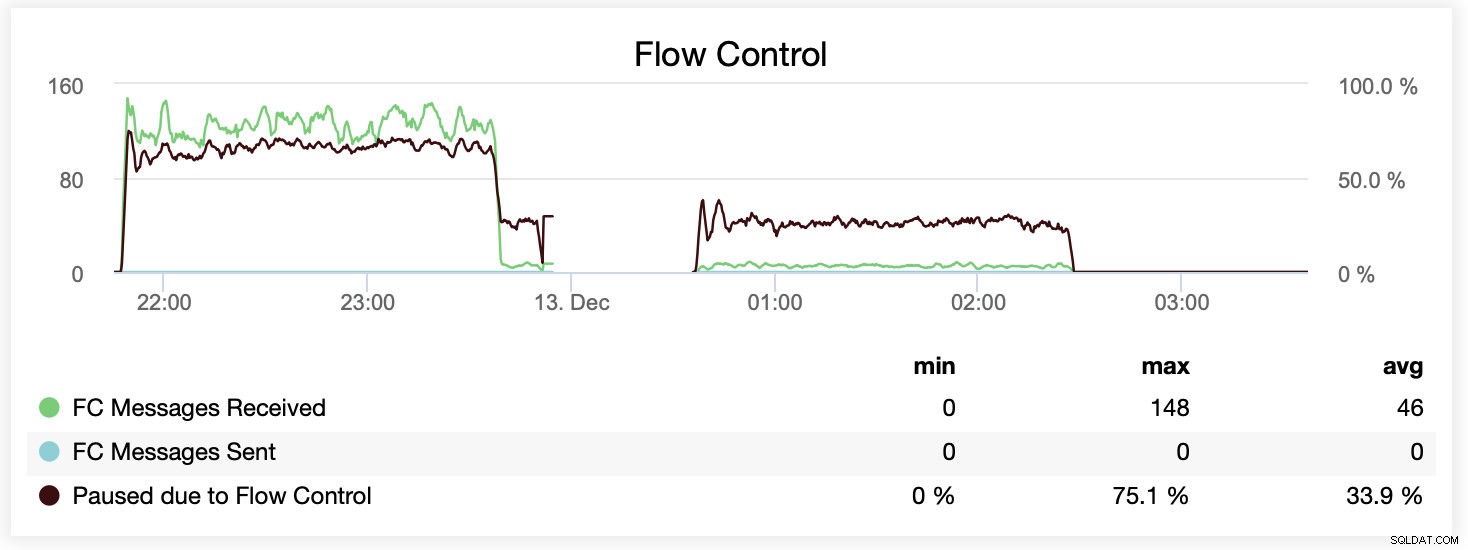
U kunt het verschil ook op één enkele grafiek vergelijken. De drop aan het einde van het eerste deel is de eerste poging om te draaien met wsrep_slave_threads=16. Servers hadden onvoldoende schijfruimte voor binaire logbestanden en we moesten die benchmark op een later tijdstip opnieuw uitvoeren.
Hoe vertaalde zich dit in prestatietermen? Het verschil is zichtbaar, hoewel zeker niet zo spectaculair.
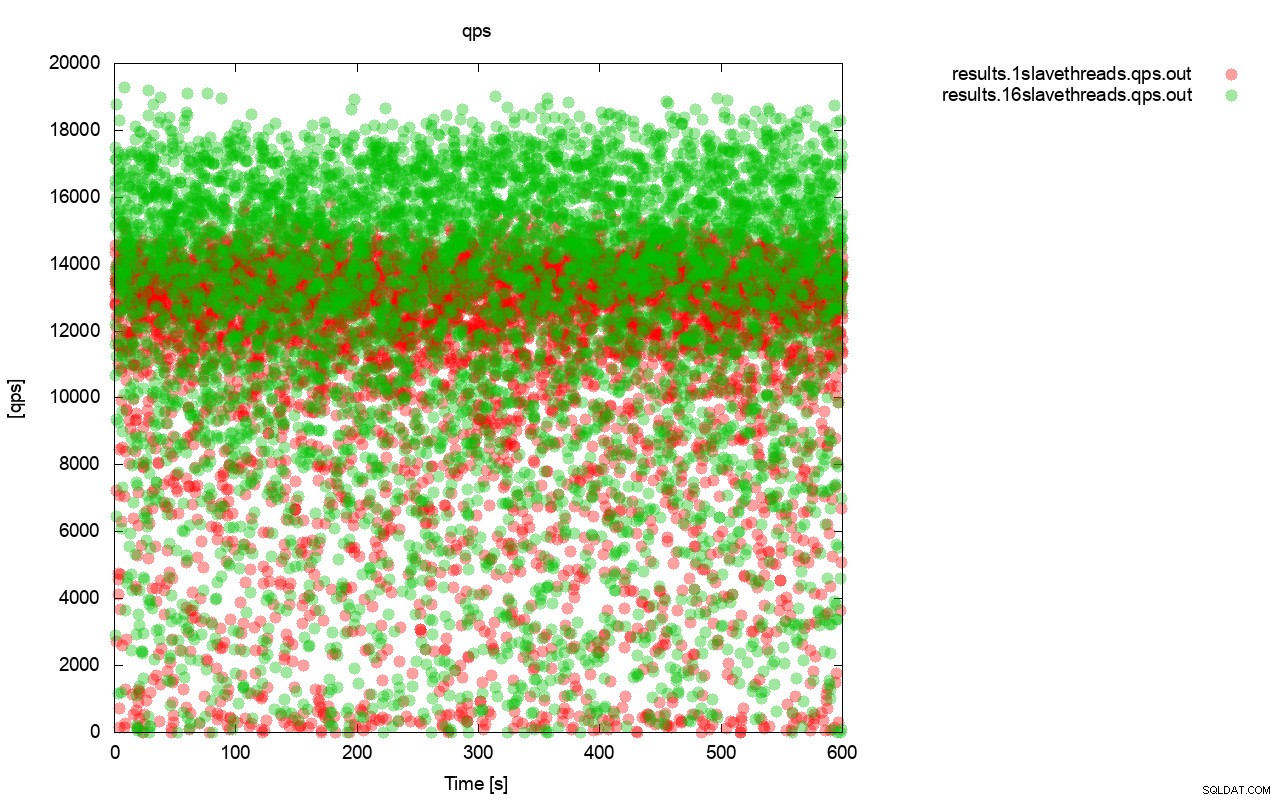
Ten eerste de grafiek van de zoekopdracht per seconde. Allereerst kun je merken dat in beide gevallen de resultaten overal zijn. Dit heeft vooral te maken met de onstabiele prestaties van de I/O-opslag en de willekeurig in werking tredende stroomregeling. Je kunt nog steeds zien dat de prestaties van het "rode" resultaat (wsrep_slave_threads=1) behoorlijk lager zijn dan het "groene" resultaat ( wsrep_slave_threads=16).
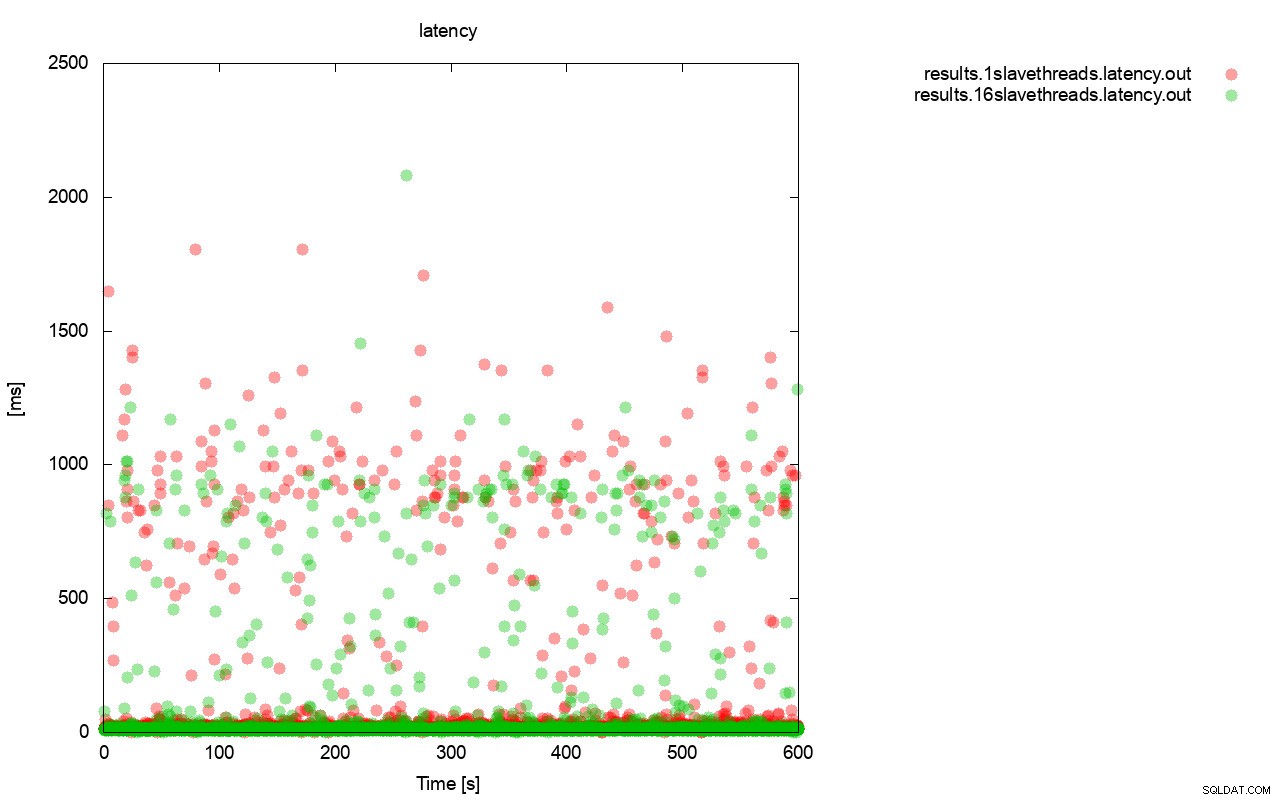
Vrij gelijkaardig beeld is wanneer we kijken naar de latentie. Met wsrep_slave_thread=1 kun je meer (en doorgaans diepere) stallingen voor de run zien.
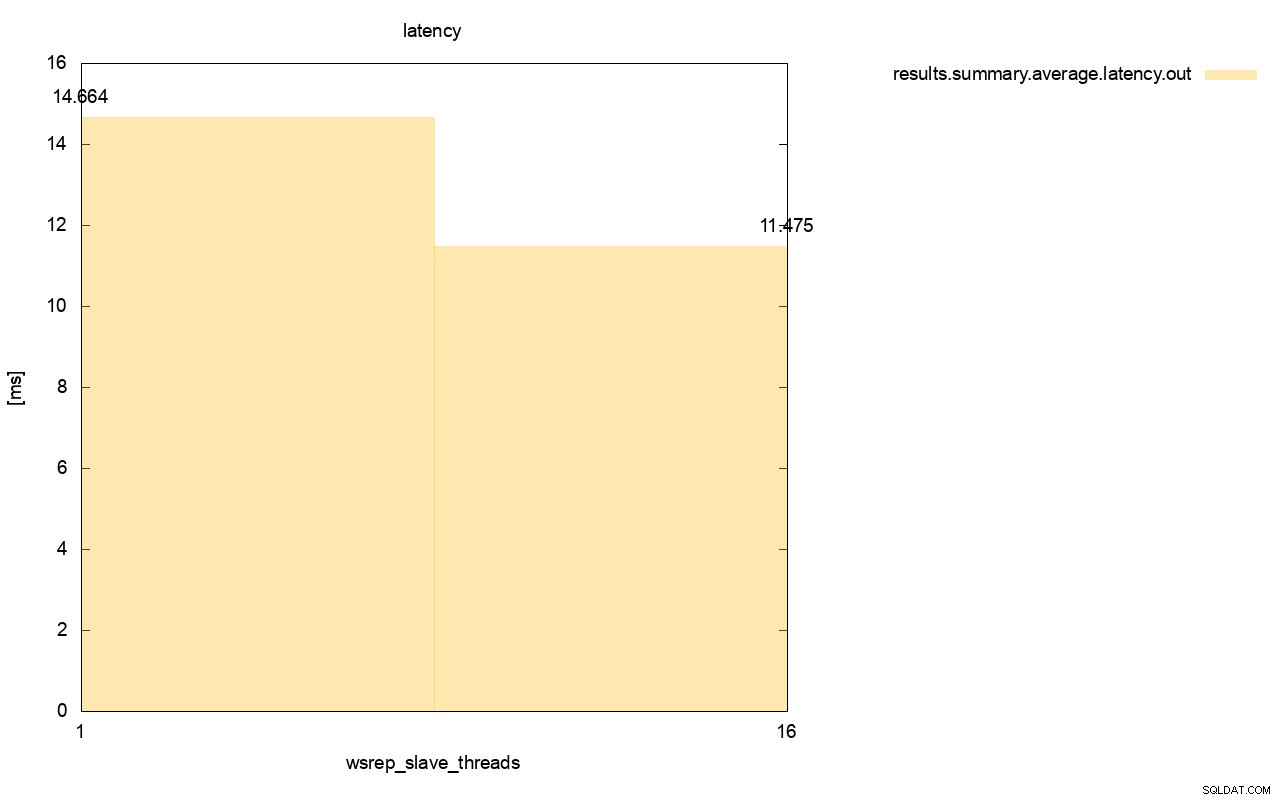
Het verschil is nog beter zichtbaar wanneer we de gemiddelde latentie over alle runs hebben berekend en je kunt zien dat de latentie van wsrep_slave_thread=1 27% hoger is dan de latentie met 16 slave-threads, wat natuurlijk niet goed is omdat we willen dat de latentie lager is , niet hoger.
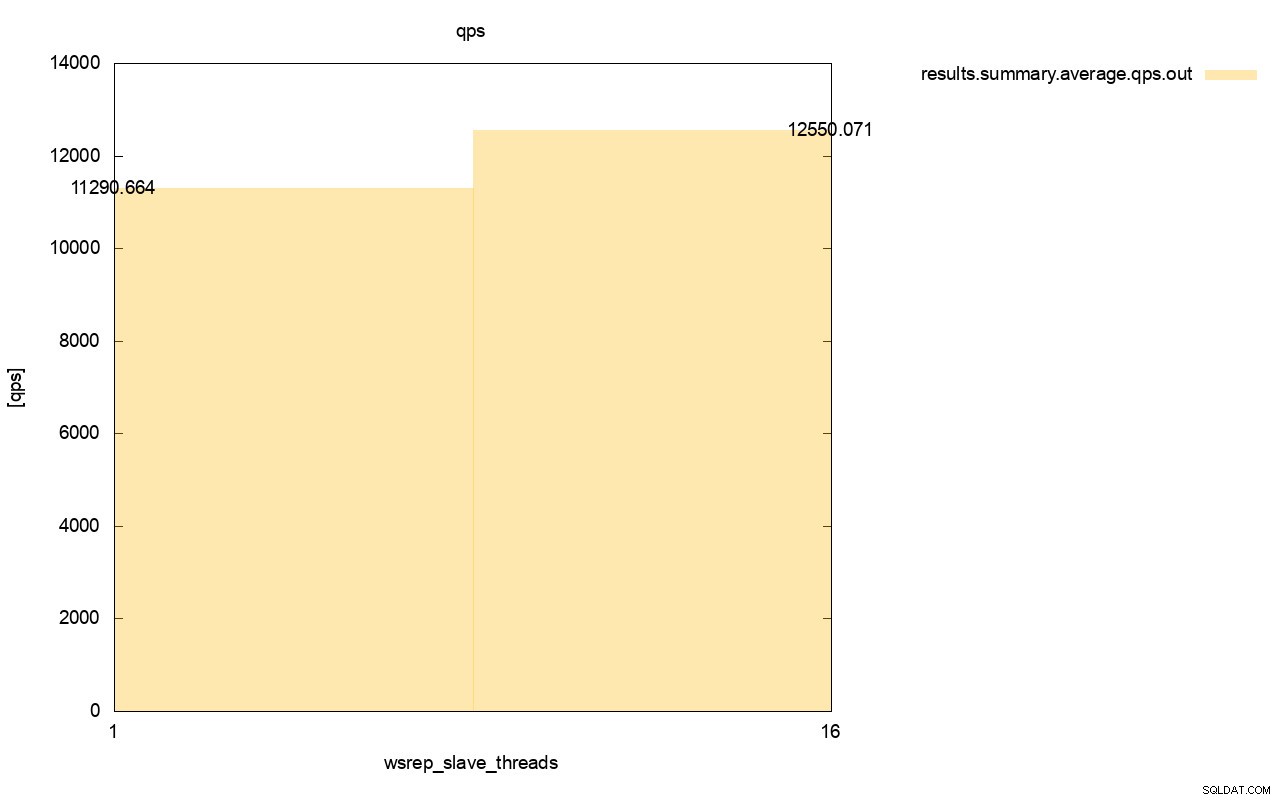
Het verschil in doorvoer is ook zichtbaar, ongeveer 11% van de verbetering toen we meer wsrep_slave_threads toevoegden.
Zoals je kunt zien, is de impact er. Het is geenszins 16x (zelfs als dat is hoe we het aantal slave-threads in Galera hebben verhoogd), maar het is zeker prominent genoeg zodat we het niet kunnen classificeren als slechts een statistische anomalie.
Houd er rekening mee dat we in ons geval vrij kleine knooppunten hebben gebruikt. Het verschil zou nog groter moeten zijn als we het hebben over grote instances die draaien op EBS-volumes met duizenden ingerichte IOPS.
Dan zouden we sysbench nog agressiever kunnen uitvoeren, met een groter aantal gelijktijdige bewerkingen. Dit zou de parallellisatie van de schrijfsets moeten verbeteren, waardoor de winst van multithreading nog verder wordt verbeterd. Snellere hardware betekent ook dat Galera die 16 threads op een efficiëntere manier kan gebruiken.
Bij het uitvoeren van dit soort tests moet je er rekening mee houden dat je je setup bijna tot het uiterste moet pushen. Single-threaded replicatie kan behoorlijk wat belasting aan en je moet veel verkeer laten lopen om het eigenlijk niet performant genoeg te maken om de taak aan te kunnen.
We hopen dat deze blogpost je meer inzicht geeft in de mogelijkheden van Galera Cluster om schrijfsets parallel toe te passen en de beperkende factoren eromheen.