Query's moeten in elke zwaarbelaste database worden gecached, er is gewoon geen manier voor een database om al het verkeer met redelijke prestaties te verwerken. Er zijn verschillende mechanismen waarin een querycache kan worden geïmplementeerd. Beginnend met de MySQL-querycache, die vroeger prima werkte voor voornamelijk alleen-lezen, lage gelijktijdigheidsworkloads en die geen plaats heeft in hoge gelijktijdige workloads (in de mate dat Oracle deze in MySQL 8.0 heeft verwijderd), naar externe sleutel-waardeopslag zoals Redis, memcached of CouchBase.
Het grootste probleem met het gebruik van een externe speciale gegevensopslag (aangezien we niemand zouden aanraden om MySQL-querycache te gebruiken) is dat dit nog een andere gegevensopslag is om te beheren. Het is weer een andere omgeving om te onderhouden, schaalproblemen om op te lossen, bugs om te debuggen enzovoort.
Dus waarom niet twee vliegen in één klap slaan door gebruik te maken van uw proxy? De veronderstelling hier is dat u een proxy gebruikt in uw productieomgeving, omdat het helpt om query's over instanties te verdelen en de onderliggende databasetopologie te maskeren door een eenvoudig eindpunt voor toepassingen te bieden. ProxySQL is een geweldig hulpmiddel voor deze taak, omdat het bovendien kan fungeren als een caching-laag. In deze blogpost laten we u zien hoe u query's in ProxySQL in de cache kunt opslaan met ClusterControl.
Hoe werkt Query Cache in ProxySQL?
Allereerst een beetje achtergrond. ProxySQL beheert het verkeer via queryregels en kan querycaching uitvoeren met hetzelfde mechanisme. ProxySQL slaat query's in de cache op in een geheugenstructuur. Gegevens in de cache worden verwijderd met behulp van de time-to-live (TTL)-instelling. TTL kan voor elke zoekregel afzonderlijk worden gedefinieerd, dus het is aan de gebruiker om te beslissen of er zoekregels moeten worden gedefinieerd voor elke individuele zoekopdracht, met verschillende TTL of dat ze gewoon een aantal regels moet maken die overeenkomen met de meeste van de het verkeer.
Er zijn twee configuratie-instellingen die bepalen hoe een querycache moet worden gebruikt. Ten eerste, mysql-query_cache_size_MB die een zachte limiet definieert voor de grootte van de querycache. Het is geen harde limiet, dus ProxySQL kan iets meer geheugen gebruiken, maar het is voldoende om het geheugengebruik onder controle te houden. De tweede instelling die u kunt aanpassen is mysql-query_cache_stores_empty_result . Het definieert of een lege resultatenset in de cache wordt opgeslagen of niet.
ProxySQL-querycache is ontworpen als een sleutelwaardearchief. De waarde is de resultaatset van een query en de sleutel is samengesteld uit aaneengeschakelde waarden zoals:gebruiker, schema en querytekst. Dan wordt er een hash gemaakt van die string en die hash wordt gebruikt als de sleutel.
ProxySQL instellen als een querycache met ClusterControl
Als initiële setup hebben we een replicatiecluster van één master en één slave. We hebben ook een enkele ProxySQL.
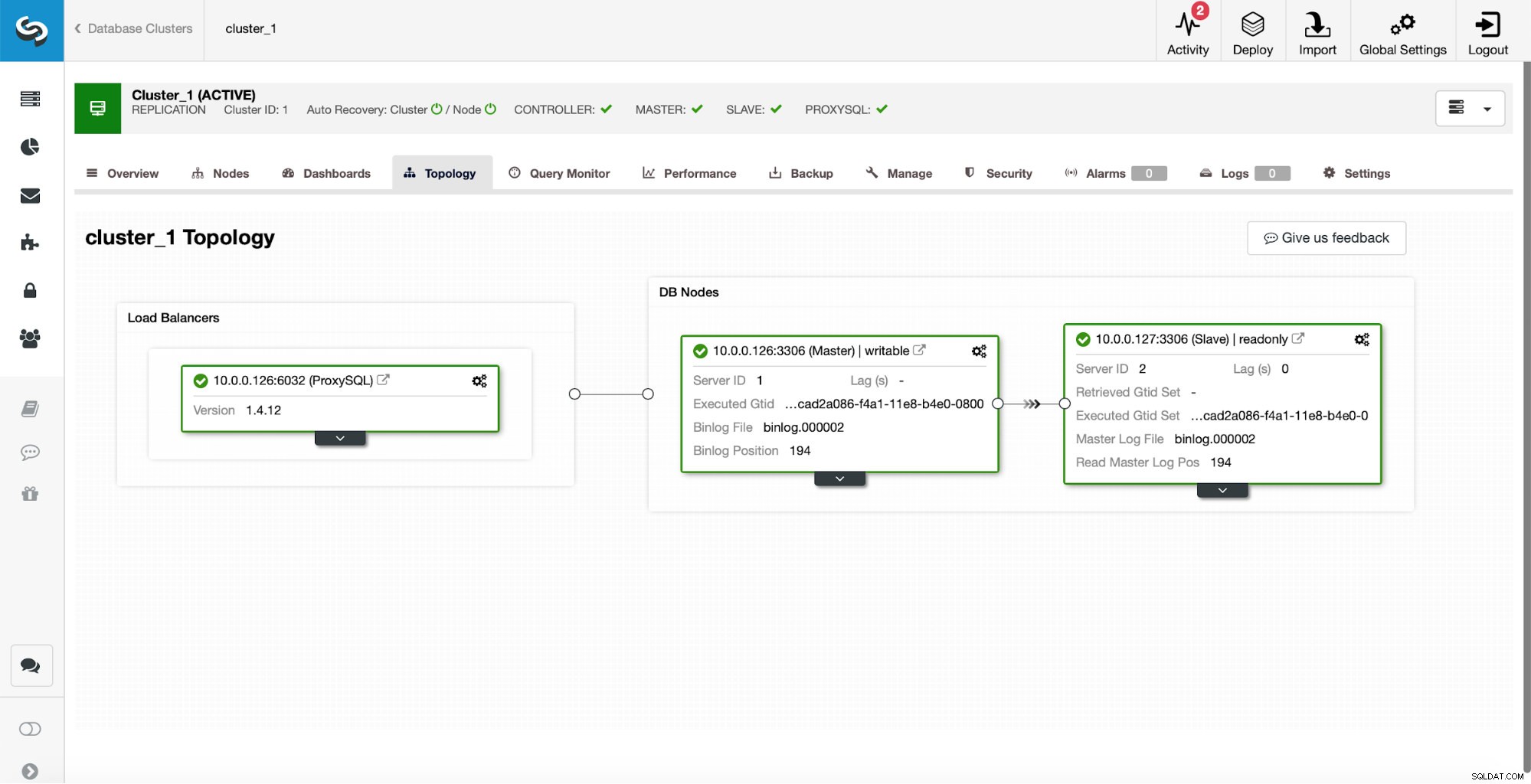
Dit is geenszins een setup van productiekwaliteit, omdat we een soort van hoge beschikbaarheid voor de proxylaag zouden moeten implementeren (bijvoorbeeld door meer dan één ProxySQL-instantie in te zetten, en dan daarbovenop te blijven leven voor zwevende virtuele IP), maar het zal meer dan genoeg zijn voor onze tests.
Eerst gaan we de ProxySQL-configuratie verifiëren om er zeker van te zijn dat de cache-instellingen van de query zijn wat we willen dat ze zijn.
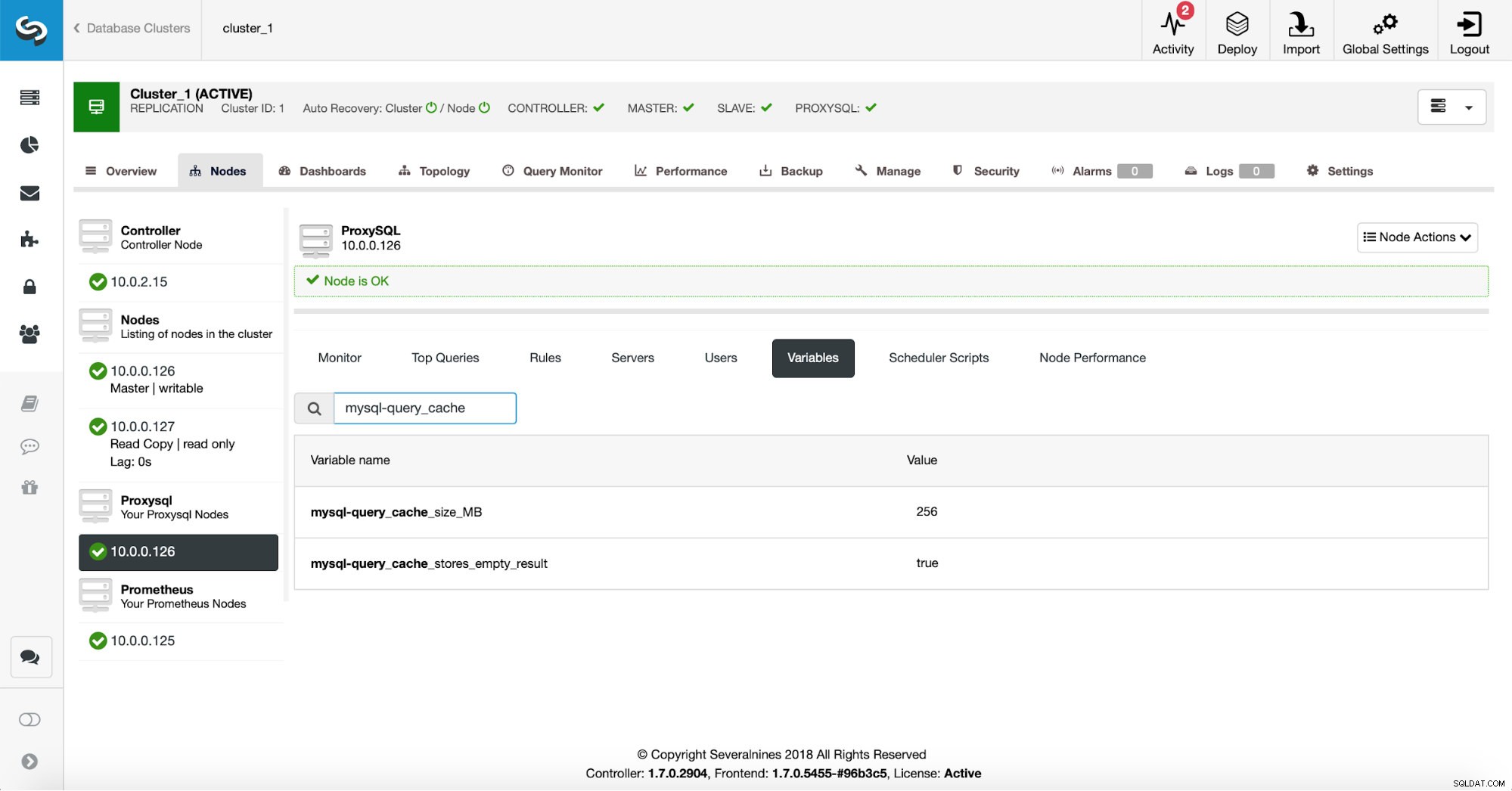
256 MB querycache zou ongeveer goed moeten zijn en we willen ook de lege resultatensets cachen - soms moet een query die geen gegevens retourneert nog steeds veel werk doen om te verifiëren dat er niets is om te retourneren.
De volgende stap is het maken van queryregels die overeenkomen met de query's die u in de cache wilt opslaan. Er zijn twee manieren om dat te doen in ClusterControl.
Handmatig Queryregels toevoegen
De eerste manier vereist wat meer handmatige acties. Met ClusterControl kunt u eenvoudig elke gewenste queryregel maken, inclusief queryregels die de cache uitvoeren. Laten we eerst eens kijken naar de lijst met regels:
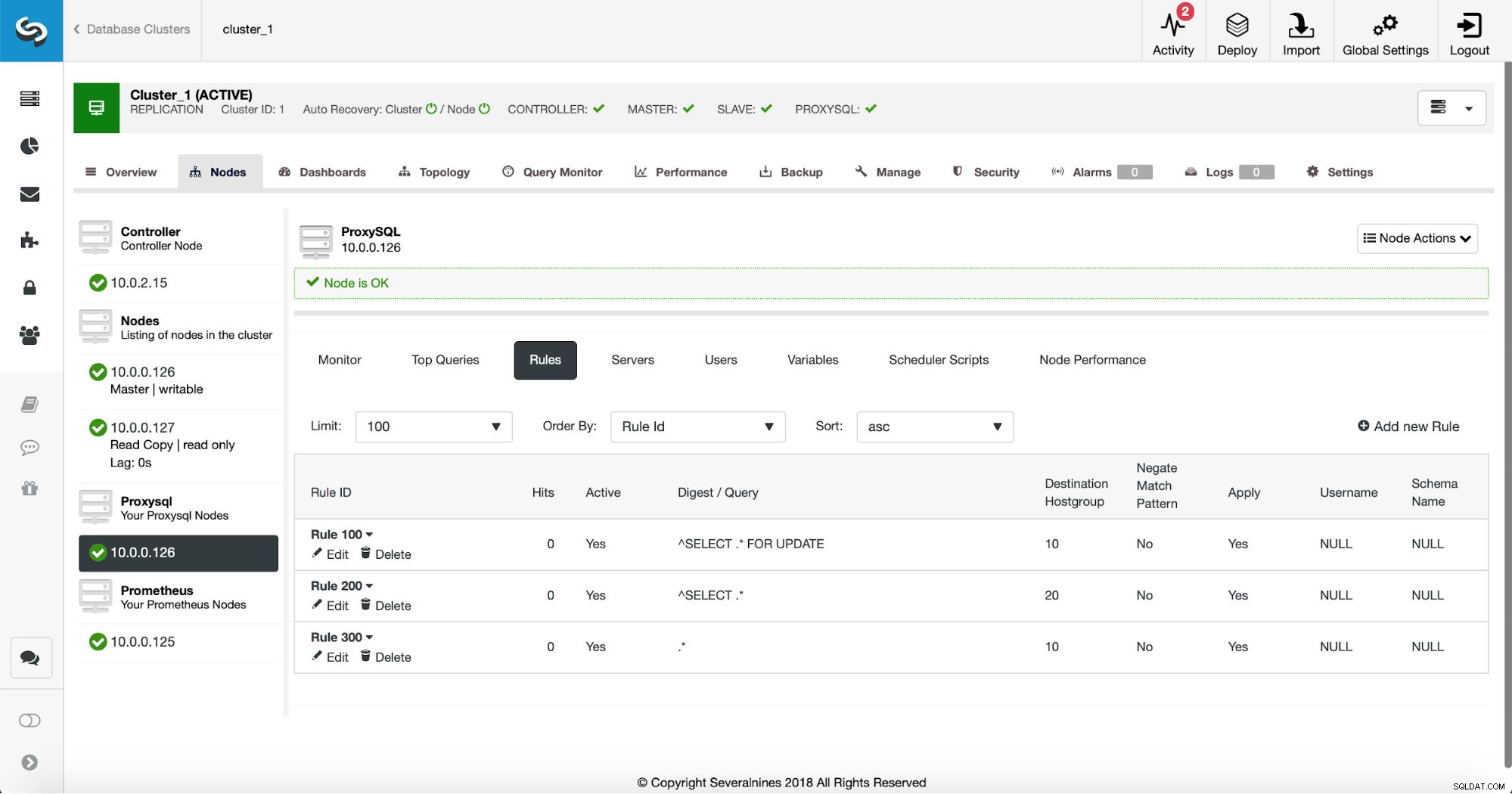
Op dit moment hebben we een set queryregels om de lees-/schrijfsplitsing uit te voeren. De eerste regel heeft een ID van 100. Onze nieuwe queryregel moet eerder worden verwerkt, dus we zullen een lagere regel-ID gebruiken. Laten we een queryregel maken die het cachen van query's zal doen die vergelijkbaar zijn met deze:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY c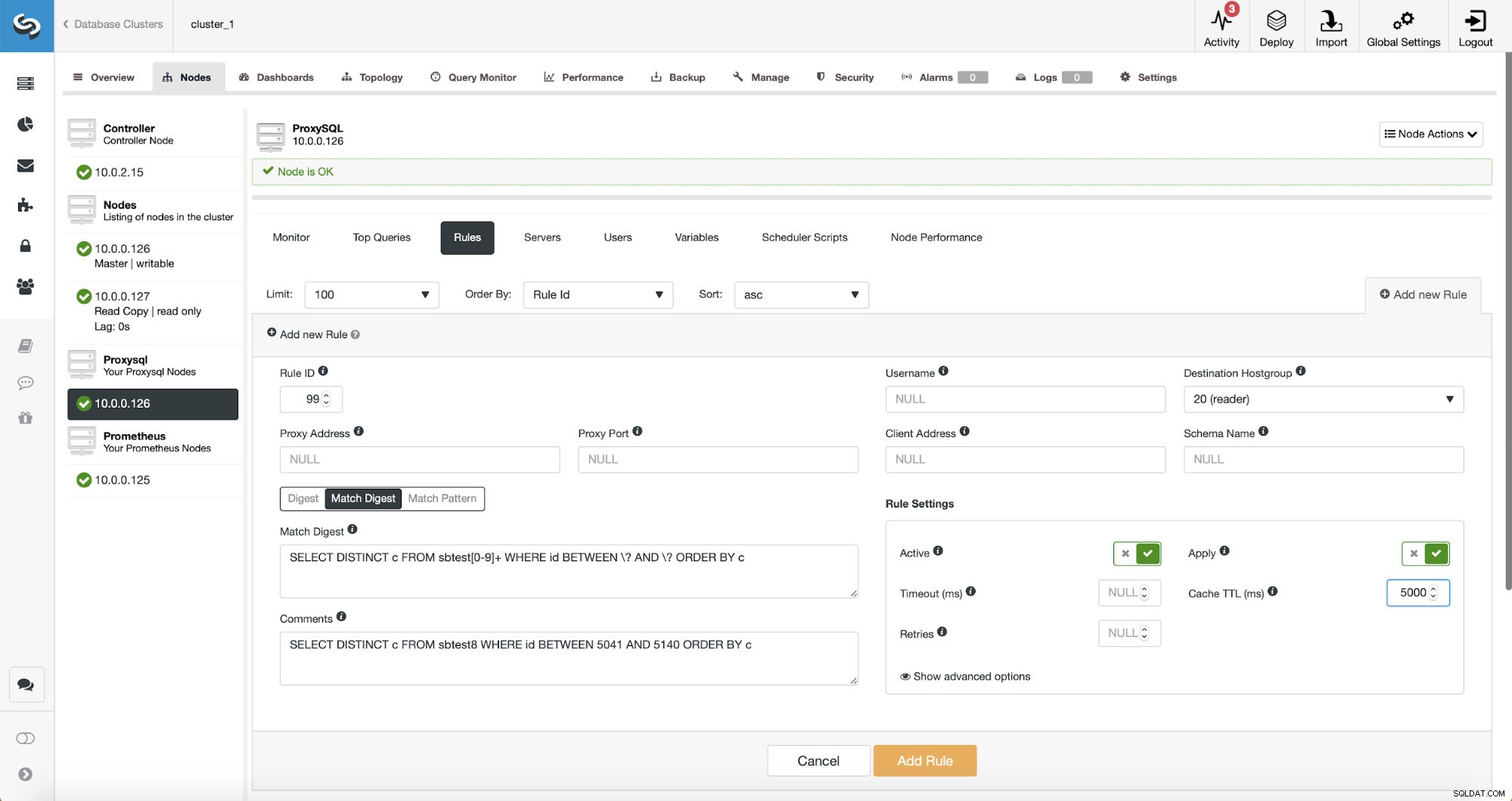
Er zijn drie manieren om de zoekopdracht te matchen:Digest, Match Digest en Match Pattern. Laten we het hier wat over hen hebben. Eerst Match Digest. We kunnen hier een reguliere expressie instellen die overeenkomt met een gegeneraliseerde queryreeks die een bepaald type query vertegenwoordigt. Bijvoorbeeld voor onze vraag:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY cDe algemene weergave is:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN ? AND ? ORDER BY cZoals u kunt zien, heeft het de argumenten van de WHERE-component verwijderd, daarom worden alle query's van dit type weergegeven als een enkele tekenreeks. Deze optie is best leuk om te gebruiken omdat het overeenkomt met het hele querytype en, wat nog belangrijker is, het is ontdaan van alle spaties. Dit maakt het zoveel gemakkelijker om een reguliere expressie te schrijven, omdat je geen rekening hoeft te houden met rare regeleinden, spaties aan het begin of einde van de tekenreeks enzovoort.
Digest is in feite een hash die ProxySQL berekent via het Match Digest-formulier.
Ten slotte komt Match Pattern overeen met de volledige tekst van de zoekopdracht, zoals deze door de klant is verzonden. In ons geval zal de vraag de vorm hebben van:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY cWe gaan Match Digest gebruiken omdat we willen dat al die zoekopdrachten onder de queryregel vallen. Als we alleen die specifieke zoekopdracht in de cache willen opslaan, is het een goede optie om Match Pattern te gebruiken.
De reguliere expressie die we gebruiken is:
SELECT DISTINCT c FROM sbtest[0-9]+ WHERE id BETWEEN \? AND \? ORDER BY cWe matchen letterlijk de exacte gegeneraliseerde queryreeks met één uitzondering - we weten dat deze query meerdere tabellen heeft bereikt, daarom hebben we een reguliere expressie toegevoegd om ze allemaal te matchen.
Zodra dit is gebeurd, kunnen we zien of de queryregel van kracht is of niet.
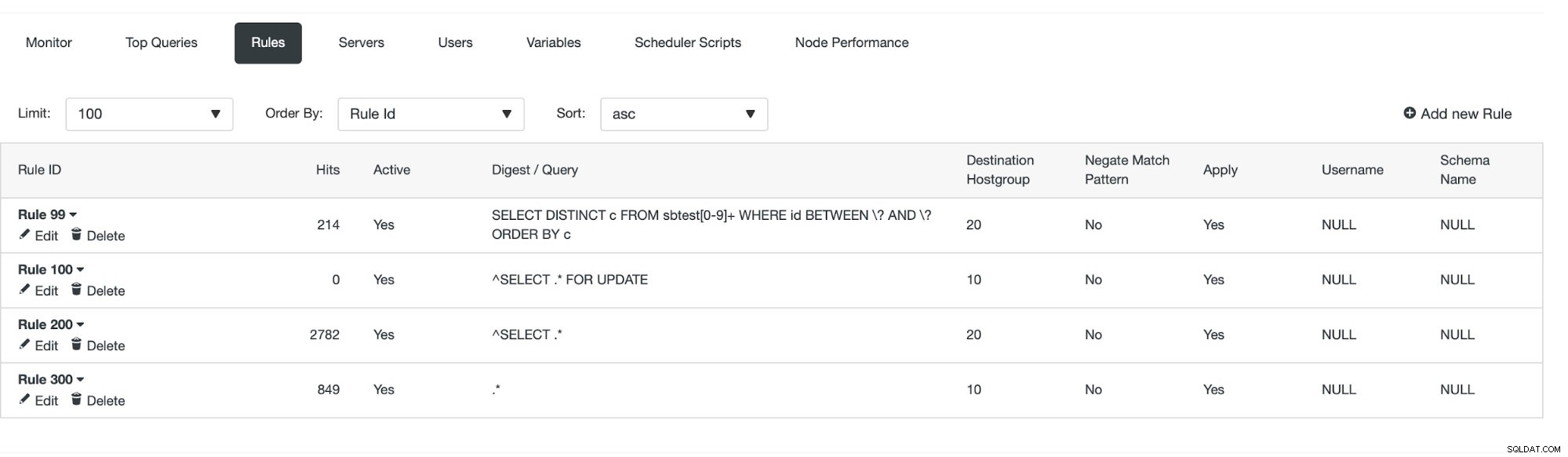
We kunnen zien dat 'Hits' toenemen, wat betekent dat onze queryregel wordt gebruikt. Vervolgens bekijken we een andere manier om een queryregel te maken.
ClusterControl gebruiken om queryregels te maken
ProxySQL heeft een handige functionaliteit voor het verzamelen van statistieken van de query's die het heeft gerouteerd. U kunt gegevens bijhouden zoals de uitvoeringstijd, hoe vaak een bepaalde query is uitgevoerd, enzovoort. Deze gegevens zijn ook aanwezig in ClusterControl:
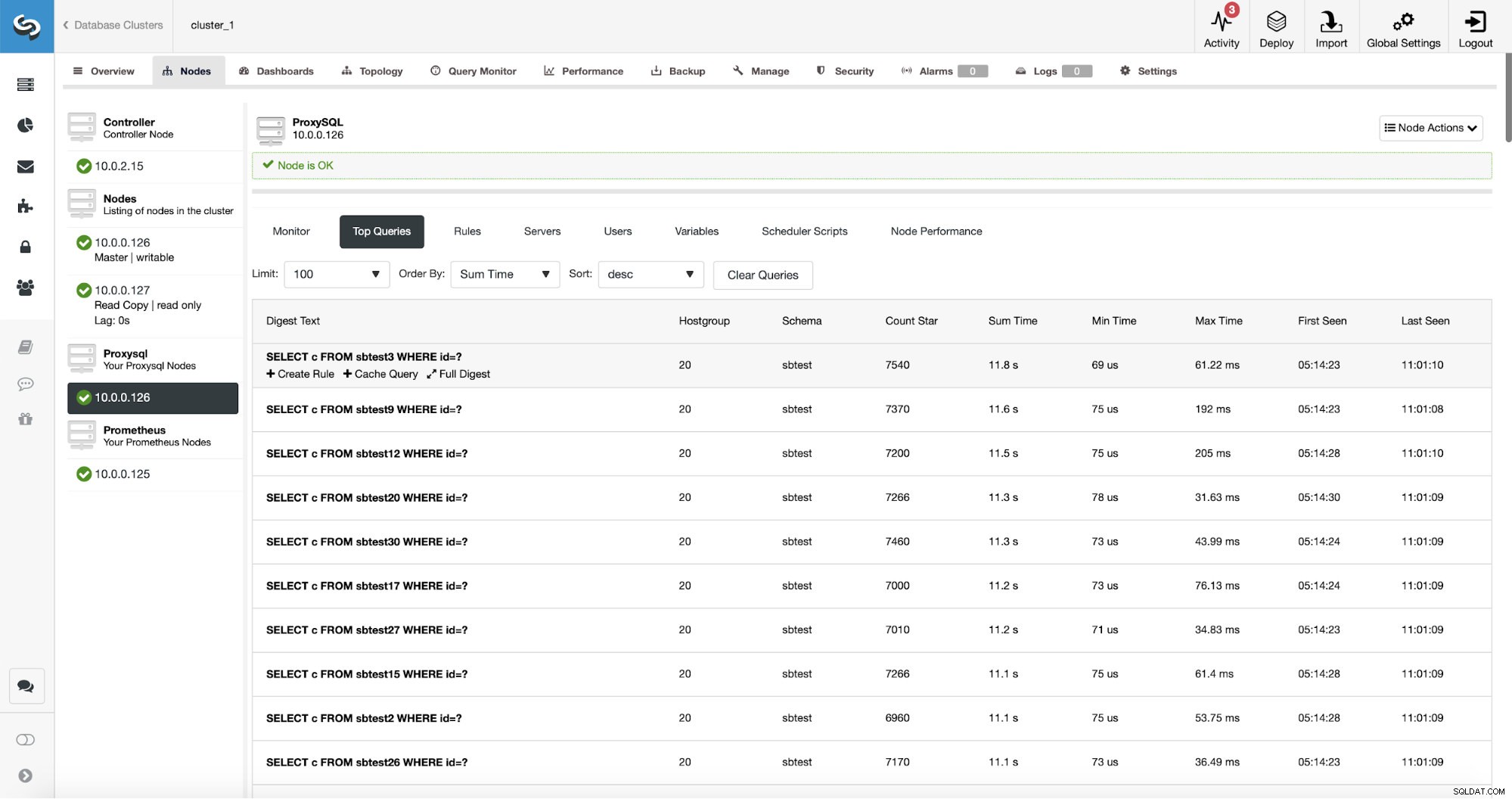
Wat nog beter is, als u naar een bepaald querytype wijst, kunt u een daaraan gerelateerde queryregel maken. U kunt dit specifieke type zoekopdracht ook gemakkelijk in de cache opslaan.
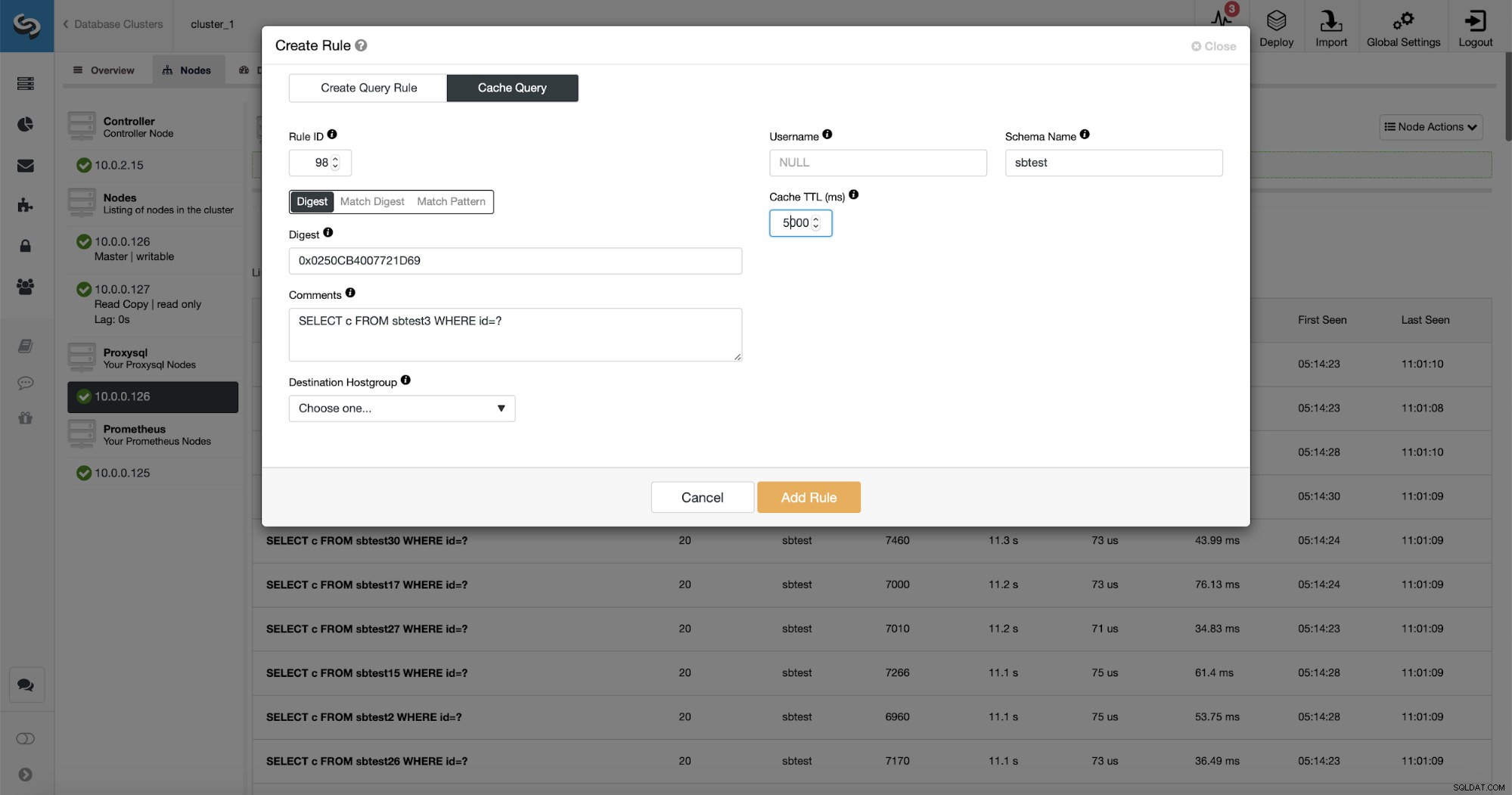
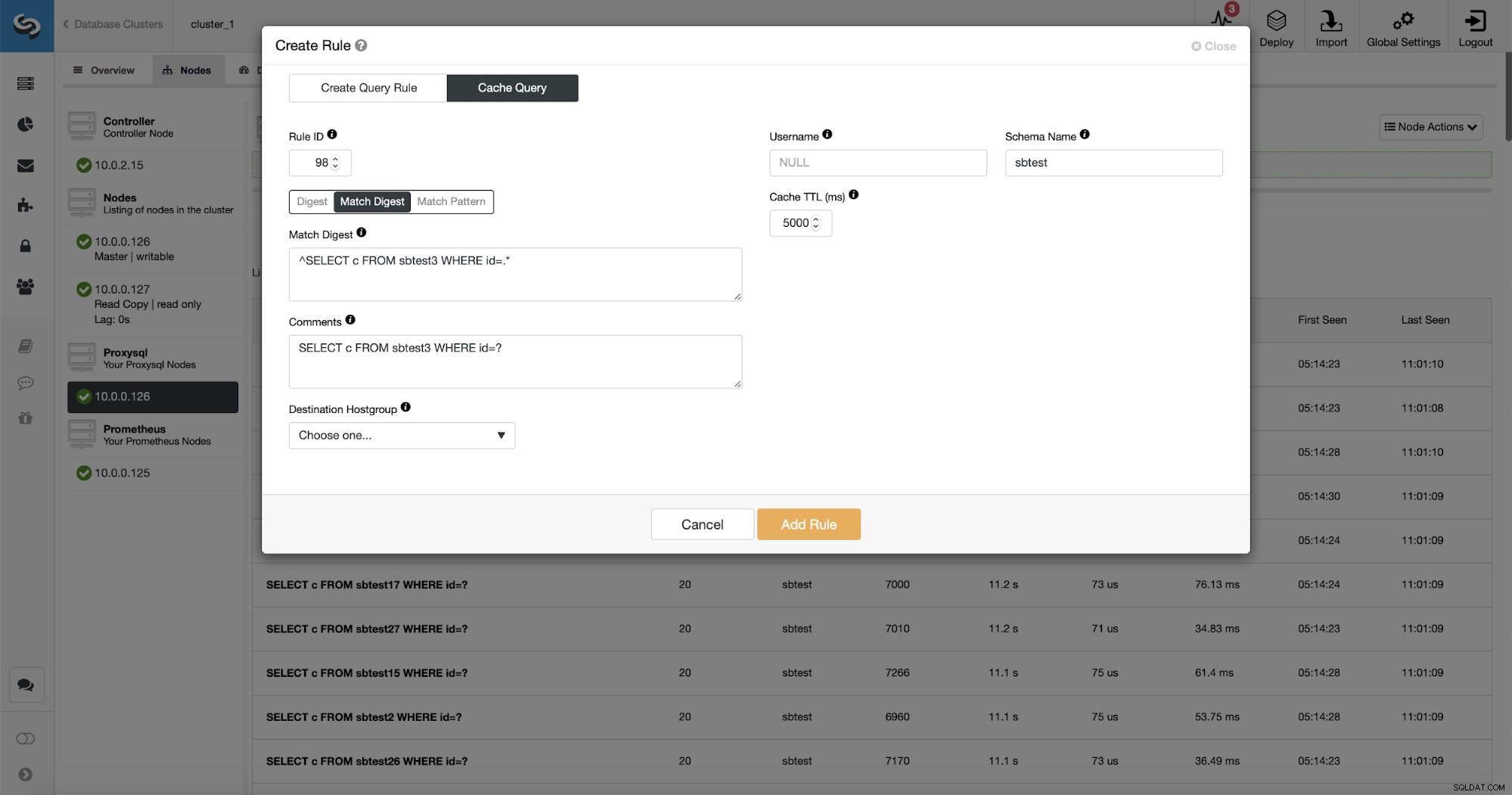
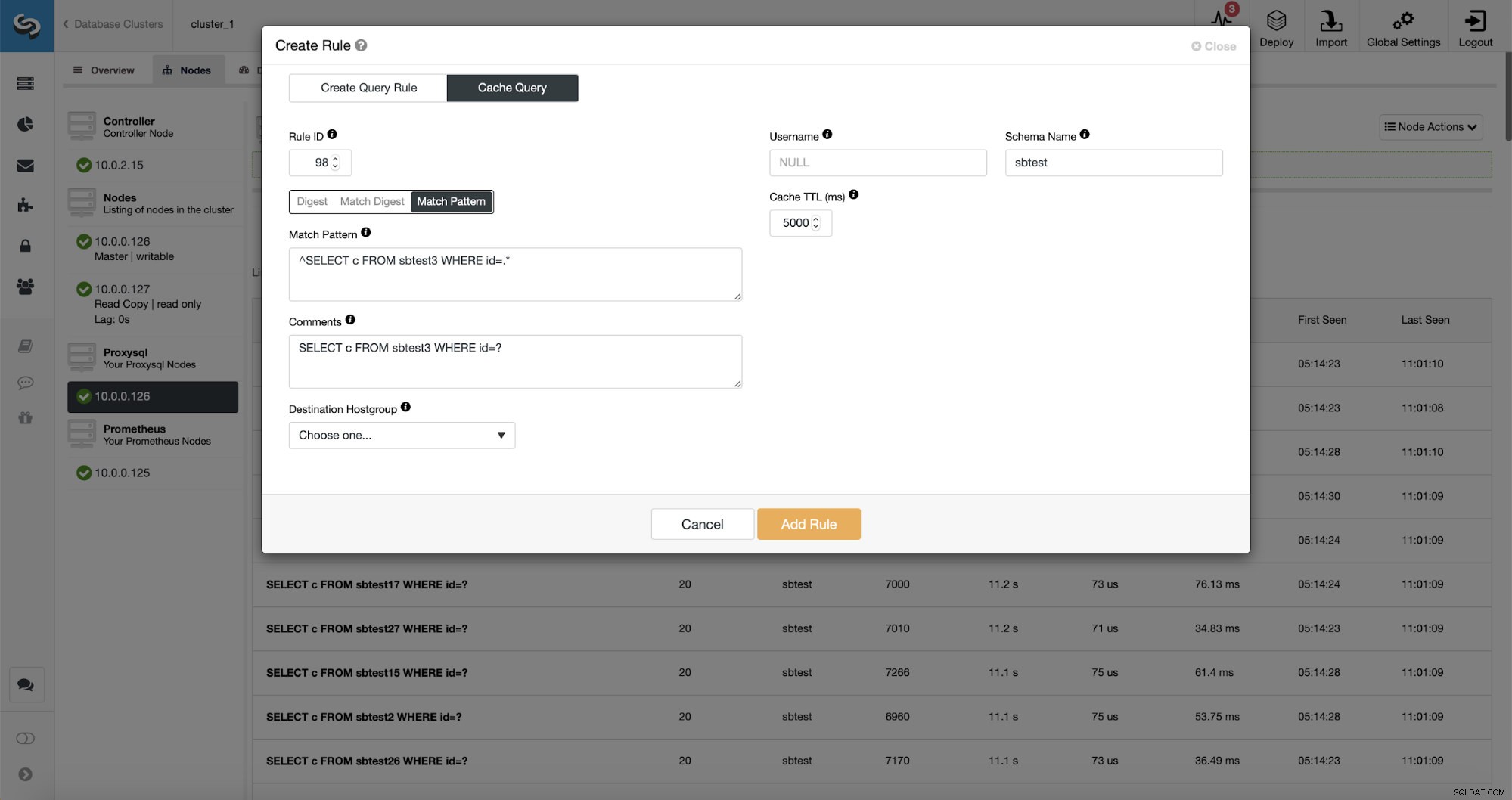
Zoals je kunt zien, zijn sommige gegevens zoals Rule IP, Cache TTL of Schema Name al gevuld. ClusterControl zal ook gegevens invullen op basis van welk matching-mechanisme u hebt besloten te gebruiken. We kunnen gemakkelijk ofwel hash gebruiken voor een bepaald type zoekopdracht of we kunnen Match Digest of Match Pattern gebruiken als we de reguliere expressie willen verfijnen (bijvoorbeeld door hetzelfde te doen als eerder en de reguliere expressie uit te breiden zodat deze overeenkomt met alle tabellen in het beste schema).
Dit is alles wat u nodig hebt om eenvoudig querycacheregels te maken in ProxySQL. Download ClusterControl om het vandaag nog te proberen.