Met vertraagde replicatie kan een replicatieslave opzettelijk ten minste een bepaalde tijd achterlopen op de master. Alvorens een gebeurtenis uit te voeren, wacht de slave, indien nodig, eerst tot de opgegeven tijd is verstreken sinds de gebeurtenis op de master is aangemaakt. Het resultaat is dat de slave de toestand van de master enige tijd terug in het verleden zal weerspiegelen. Deze functie wordt ondersteund sinds MySQL 5.6 en MariaDB 10.2.3. Het kan van pas komen in het geval van onbedoelde gegevensverwijdering en zou onderdeel moeten zijn van uw noodherstelplan.
Het probleem bij het opzetten van een vertraagde replicatieslave is hoeveel vertraging we moeten hebben. Te weinig tijd en je riskeert dat de slechte vraag je vertraagde slaaf bereikt voordat je er bij kunt komen, waardoor het punt van het hebben van de vertraagde slaaf wordt verspild. Optioneel kunt u uw vertraagde tijd zo lang laten zijn dat het uren duurt voordat uw vertraagde slave inhaalt waar de master was op het moment van de fout.
Gelukkig is met Docker procesisolatie de kracht ervan. Het uitvoeren van meerdere MySQL-instanties is best handig met Docker. Het stelt ons in staat om meerdere vertraagde slaves binnen een enkele fysieke host te hebben om onze hersteltijd te verbeteren en hardwarebronnen te besparen. Als u denkt dat een vertraging van 15 minuten te kort is, kunnen we een andere instantie hebben met 1 uur vertraging of 6 uur voor een nog oudere momentopname van onze database.
In deze blogpost gaan we met Docker meerdere MySQL-delay-slaves inzetten op één fysieke host en enkele herstelscenario's laten zien. Het volgende diagram illustreert onze uiteindelijke architectuur die we willen bouwen:
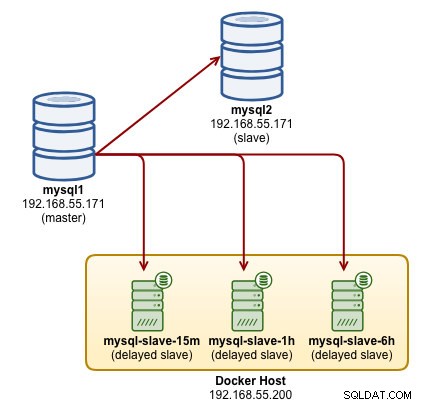
Onze architectuur bestaat uit een reeds geïmplementeerde 2-node MySQL-replicatie die draait op fysieke servers (blauw) en we zouden graag nog drie MySQL-slaves (groen) willen opzetten met het volgende gedrag:
- 15 minuten vertraging
- 1 uur vertraging
- 6 uur vertraging
Houd er rekening mee dat we 3 exemplaren van exact dezelfde gegevens op dezelfde fysieke server zullen hebben. Zorg ervoor dat onze Docker-host de benodigde opslagruimte heeft, dus wijs vooraf voldoende schijfruimte toe.
MySQL Master-voorbereiding
Log eerst in op de hoofdserver en maak de replicatiegebruiker aan:
mysql> GRANT REPLICATION SLAVE ON *.* TO example@sqldat.com'%' IDENTIFIED BY 'YlgSH6bLLy';Maak vervolgens een PITR-compatibele back-up op de master:
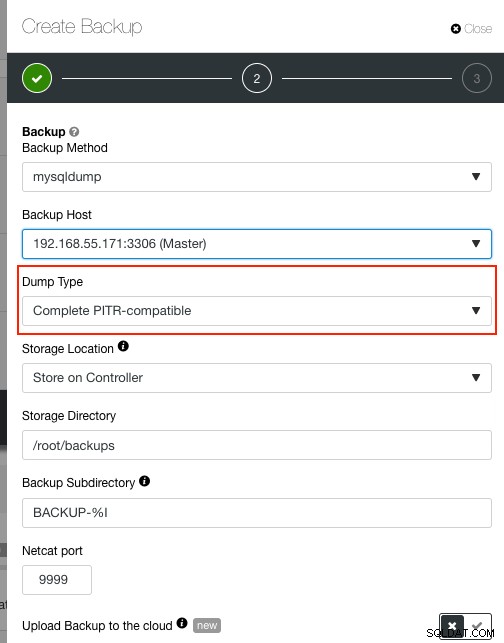
$ mysqldump -uroot -p --flush-privileges --hex-blob --opt --master-data=1 --single-transaction --skip-lock-tables --skip-lock-tables --triggers --routines --events --all-databases | gzip -6 -c > mysqldump_complete.sql.gzAls u ClusterControl gebruikt, kunt u eenvoudig een PITR-compatibele back-up maken. Ga naar Back-ups -> Back-up maken en kies "Complete PITR-compatibel" onder de vervolgkeuzelijst "Dumptype":
Breng tot slot deze back-up over naar de Docker-host:
$ scp mysqldump_complete.sql.gz example@sqldat.com:~Dit back-upbestand wordt gebruikt door de MySQL-slavecontainers tijdens het slave-bootstrapping-proces, zoals weergegeven in de volgende sectie.
Vertraagde implementatie van slaven
Bereid onze Docker-containerdirectory's voor. Maak 3 mappen (mysql.conf.d, datadir en sql) voor elke MySQL-container die we gaan lanceren (u kunt lus gebruiken om de onderstaande opdrachten te vereenvoudigen):
$ mkdir -p /storage/mysql-slave-15m/mysql.conf.d
$ mkdir -p /storage/mysql-slave-15m/datadir
$ mkdir -p /storage/mysql-slave-15m/sql
$ mkdir -p /storage/mysql-slave-1h/mysql.conf.d
$ mkdir -p /storage/mysql-slave-1h/datadir
$ mkdir -p /storage/mysql-slave-1h/sql
$ mkdir -p /storage/mysql-slave-6h/mysql.conf.d
$ mkdir -p /storage/mysql-slave-6h/datadir
$ mkdir -p /storage/mysql-slave-6h/sqlDe map "mysql.conf.d" slaat ons aangepaste MySQL-configuratiebestand op en wordt toegewezen aan de container onder /etc/mysql.conf.d. "datadir" is waar we willen dat Docker de MySQL-gegevensdirectory opslaat, die is toegewezen aan /var/lib/mysql van de container en de "sql" -directory slaat onze SQL-bestanden op - back-upbestanden in .sql- of .sql.gz-indeling om te stagen de slaaf voor het repliceren en ook .sql-bestanden om de replicatieconfiguratie en het opstarten te automatiseren.
15 minuten vertraagde slaaf
Bereid het MySQL-configuratiebestand voor onze 15 minuten vertraagde slaaf voor:
$ vim /storage/mysql-slave-15m/mysql.conf.d/my.cnfEn voeg de volgende regels toe:
[mysqld]
server_id=10015
binlog_format=ROW
log_bin=binlog
log_slave_updates=1
gtid_mode=ON
enforce_gtid_consistency=1
relay_log=relay-bin
expire_logs_days=7
read_only=ON** De server-id waarde die we voor deze slave hebben gebruikt is 10015.
Maak vervolgens in de directory /storage/mysql-slave-15m/sql twee SQL-bestanden, een om MASTER te RESETTEN (1reset_master.sql) en een andere om de replicatielink tot stand te brengen met de instructie CHANGE MASTER (3setup_slave.sql).
Maak een tekstbestand 1reset_master.sql en voeg de volgende regel toe:
RESET MASTER;Maak een tekstbestand 3setup_slave.sql en voeg de volgende regels toe:
CHANGE MASTER TO MASTER_HOST = '192.168.55.171', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'YlgSH6bLLy', MASTER_AUTO_POSITION = 1, MASTER_DELAY=900;
START SLAVE;MASTER_DELAY=900 is gelijk aan 15 minuten (in seconden). Kopieer vervolgens het back-upbestand van onze master (dat is overgebracht naar onze Docker-host) naar de map "sql" en hernoem het als 2mysqldump_complete.sql.gz:
$ cp ~/mysqldump_complete.tar.gz /storage/mysql-slave-15m/sql/2mysqldump_complete.tar.gzHet uiteindelijke uiterlijk van onze "sql" directory zou er ongeveer zo uit moeten zien:
$ pwd
/storage/mysql-slave-15m/sql
$ ls -1
1reset_master.sql
2mysqldump_complete.sql.gz
3setup_slave.sqlHoud er rekening mee dat we de SQL-bestandsnaam voorafgaan door een geheel getal om de uitvoeringsvolgorde te bepalen wanneer Docker de MySQL-container initialiseert.
Zodra alles op zijn plaats is, voert u de MySQL-container uit voor onze 15 minuten vertraagde slaaf:
$ docker run -d \
--name mysql-slave-15m \
-e MYSQL_ROOT_PASSWORD=password \
--mount type=bind,source=/storage/mysql-slave-15m/datadir,target=/var/lib/mysql \
--mount type=bind,source=/storage/mysql-slave-15m/mysql.conf.d,target=/etc/mysql/mysql.conf.d \
--mount type=bind,source=/storage/mysql-slave-15m/sql,target=/docker-entrypoint-initdb.d \
mysql:5.7** De MYSQL_ROOT_PASSWORD-waarde moet hetzelfde zijn als het MySQL-rootwachtwoord op de master.
We zijn op zoek naar de volgende regels om te controleren of MySQL correct werkt en als slave is verbonden met onze master (192.168.55.171):
$ docker logs -f mysql-slave-15m
...
2018-12-04T04:05:24.890244Z 0 [Note] mysqld: ready for connections.
Version: '5.7.24-log' socket: '/var/run/mysqld/mysqld.sock' port: 3306 MySQL Community Server (GPL)
2018-12-04T04:05:25.010032Z 2 [Note] Slave I/O thread for channel '': connected to master 'example@sqldat.com:3306',replication started in log 'FIRST' at position 4U kunt dan de replicatiestatus verifiëren met de volgende verklaring:
$ docker exec -it mysql-slave-15m mysql -uroot -p -e 'show slave status\G'
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
SQL_Delay: 900
Auto_Position: 1
...Op dit moment repliceert onze 15 minuten vertraagde slave-container correct en onze architectuur ziet er ongeveer zo uit:
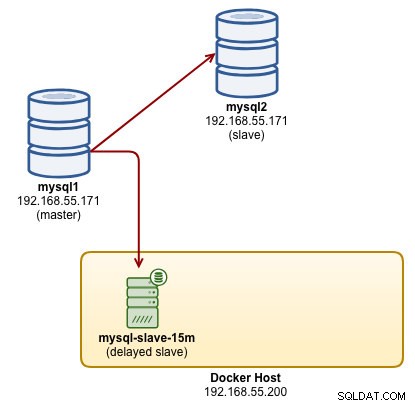
1 uur vertraagde slaaf
Bereid het MySQL-configuratiebestand voor onze 1-uur vertraagde slaaf voor:
$ vim /storage/mysql-slave-1h/mysql.conf.d/my.cnfEn voeg de volgende regels toe:
[mysqld]
server_id=10060
binlog_format=ROW
log_bin=binlog
log_slave_updates=1
gtid_mode=ON
enforce_gtid_consistency=1
relay_log=relay-bin
expire_logs_days=7
read_only=ON** De server-id waarde die we voor deze slave hebben gebruikt is 10060.
Maak vervolgens in de directory /storage/mysql-slave-1h/sql twee SQL-bestanden, één om MASTER te RESETTEN (1reset_master.sql) en een andere om de replicatielink tot stand te brengen met behulp van de CHANGE MASTER-instructie (3setup_slave.sql).
Maak een tekstbestand 1reset_master.sql en voeg de volgende regel toe:
RESET MASTER;Maak een tekstbestand 3setup_slave.sql en voeg de volgende regels toe:
CHANGE MASTER TO MASTER_HOST = '192.168.55.171', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'YlgSH6bLLy', MASTER_AUTO_POSITION = 1, MASTER_DELAY=3600;
START SLAVE;MASTER_DELAY=3600 is gelijk aan 1 uur (in seconden). Kopieer vervolgens het back-upbestand van onze master (dat is overgebracht naar onze Docker-host) naar de map "sql" en hernoem het als 2mysqldump_complete.sql.gz:
$ cp ~/mysqldump_complete.tar.gz /storage/mysql-slave-1h/sql/2mysqldump_complete.tar.gzHet uiteindelijke uiterlijk van onze "sql" directory zou er ongeveer zo uit moeten zien:
$ pwd
/storage/mysql-slave-1h/sql
$ ls -1
1reset_master.sql
2mysqldump_complete.sql.gz
3setup_slave.sqlHoud er rekening mee dat we de SQL-bestandsnaam voorafgaan door een geheel getal om de uitvoeringsvolgorde te bepalen wanneer Docker de MySQL-container initialiseert.
Zodra alles op zijn plaats is, voert u de MySQL-container uit voor onze 1 uur vertraagde slaaf:
$ docker run -d \
--name mysql-slave-1h \
-e MYSQL_ROOT_PASSWORD=password \
--mount type=bind,source=/storage/mysql-slave-1h/datadir,target=/var/lib/mysql \
--mount type=bind,source=/storage/mysql-slave-1h/mysql.conf.d,target=/etc/mysql/mysql.conf.d \
--mount type=bind,source=/storage/mysql-slave-1h/sql,target=/docker-entrypoint-initdb.d \
mysql:5.7** De MYSQL_ROOT_PASSWORD-waarde moet hetzelfde zijn als het MySQL-rootwachtwoord op de master.
We zijn op zoek naar de volgende regels om te controleren of MySQL correct werkt en als slave is verbonden met onze master (192.168.55.171):
$ docker logs -f mysql-slave-1h
...
2018-12-04T04:05:24.890244Z 0 [Note] mysqld: ready for connections.
Version: '5.7.24-log' socket: '/var/run/mysqld/mysqld.sock' port: 3306 MySQL Community Server (GPL)
2018-12-04T04:05:25.010032Z 2 [Note] Slave I/O thread for channel '': connected to master 'example@sqldat.com:3306',replication started in log 'FIRST' at position 4U kunt dan de replicatiestatus verifiëren met de volgende verklaring:
$ docker exec -it mysql-slave-1h mysql -uroot -p -e 'show slave status\G'
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
SQL_Delay: 3600
Auto_Position: 1
...Op dit moment repliceren onze MySQL-slavecontainers van 15 minuten en 1 uur met vertraging van de master en onze architectuur ziet er ongeveer zo uit:
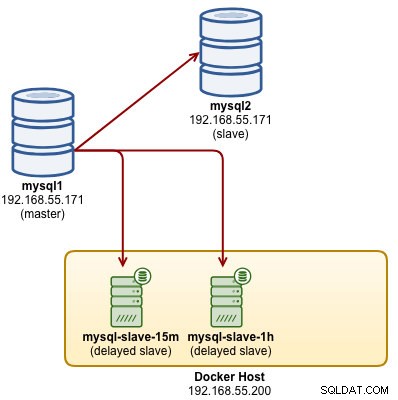
6 uur vertraagde slaaf
Bereid het MySQL-configuratiebestand voor onze 6 uur vertraagde slaaf voor:
$ vim /storage/mysql-slave-15m/mysql.conf.d/my.cnfEn voeg de volgende regels toe:
[mysqld]
server_id=10006
binlog_format=ROW
log_bin=binlog
log_slave_updates=1
gtid_mode=ON
enforce_gtid_consistency=1
relay_log=relay-bin
expire_logs_days=7
read_only=ON** De server-id waarde die we voor deze slave hebben gebruikt is 10006.
Maak vervolgens in de directory /storage/mysql-slave-6h/sql twee SQL-bestanden, een om MASTER te RESETTEN (1reset_master.sql) en een andere om de replicatielink tot stand te brengen met de instructie CHANGE MASTER (3setup_slave.sql).
Maak een tekstbestand 1reset_master.sql en voeg de volgende regel toe:
RESET MASTER;Maak een tekstbestand 3setup_slave.sql en voeg de volgende regels toe:
CHANGE MASTER TO MASTER_HOST = '192.168.55.171', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'YlgSH6bLLy', MASTER_AUTO_POSITION = 1, MASTER_DELAY=21600;
START SLAVE;MASTER_DELAY=21600 is gelijk aan 6 uur (in seconden). Kopieer vervolgens het back-upbestand van onze master (dat is overgebracht naar onze Docker-host) naar de map "sql" en hernoem het als 2mysqldump_complete.sql.gz:
$ cp ~/mysqldump_complete.tar.gz /storage/mysql-slave-6h/sql/2mysqldump_complete.tar.gzHet uiteindelijke uiterlijk van onze "sql" directory zou er ongeveer zo uit moeten zien:
$ pwd
/storage/mysql-slave-6h/sql
$ ls -1
1reset_master.sql
2mysqldump_complete.sql.gz
3setup_slave.sqlHoud er rekening mee dat we de SQL-bestandsnaam voorafgaan door een geheel getal om de uitvoeringsvolgorde te bepalen wanneer Docker de MySQL-container initialiseert.
Zodra alles op zijn plaats is, voert u de MySQL-container uit voor onze 6 uur vertraagde slaaf:
$ docker run -d \
--name mysql-slave-6h \
-e MYSQL_ROOT_PASSWORD=password \
--mount type=bind,source=/storage/mysql-slave-6h/datadir,target=/var/lib/mysql \
--mount type=bind,source=/storage/mysql-slave-6h/mysql.conf.d,target=/etc/mysql/mysql.conf.d \
--mount type=bind,source=/storage/mysql-slave-6h/sql,target=/docker-entrypoint-initdb.d \
mysql:5.7** De MYSQL_ROOT_PASSWORD-waarde moet hetzelfde zijn als het MySQL-rootwachtwoord op de master.
We zijn op zoek naar de volgende regels om te controleren of MySQL correct werkt en als slave is verbonden met onze master (192.168.55.171):
$ docker logs -f mysql-slave-6h
...
2018-12-04T04:05:24.890244Z 0 [Note] mysqld: ready for connections.
Version: '5.7.24-log' socket: '/var/run/mysqld/mysqld.sock' port: 3306 MySQL Community Server (GPL)
2018-12-04T04:05:25.010032Z 2 [Note] Slave I/O thread for channel '': connected to master 'example@sqldat.com:3306',replication started in log 'FIRST' at position 4U kunt dan de replicatiestatus verifiëren met de volgende verklaring:
$ docker exec -it mysql-slave-6h mysql -uroot -p -e 'show slave status\G'
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
SQL_Delay: 21600
Auto_Position: 1
...Op dit moment repliceren onze 5 minuten, 1 uur en 6 uur vertraagde slave-containers correct en onze architectuur ziet er ongeveer zo uit:
Scenario voor noodherstel
Stel dat een gebruiker per ongeluk een verkeerde kolom op een grote tafel heeft laten vallen. Overweeg dat de volgende instructie op de master is uitgevoerd:
mysql> USE shop;
mysql> ALTER TABLE settings DROP COLUMN status;Als je het geluk hebt om het onmiddellijk te realiseren, kun je de 15 minuten vertraagde slave gebruiken om het moment in te halen voordat de ramp plaatsvindt en het te promoten om master te worden, of de ontbrekende gegevens exporteren en terugzetten op de master.
Ten eerste moeten we de binaire logpositie vinden voordat de ramp plaatsvond. Grijp nu de tijd() op de master:
mysql> SELECT now();
+---------------------+
| now() |
+---------------------+
| 2018-12-04 14:55:41 |
+---------------------+Haal dan het actieve binaire logbestand op de master:
mysql> SHOW MASTER STATUS;
+---------------+----------+--------------+------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| binlog.000004 | 20260658 | | | 1560665e-ed2b-11e8-93fa-000c29b7f985:1-12031,
1b235f7a-d37b-11e8-9c3e-000c29bafe8f:1-62519,
1d8dc60a-e817-11e8-82ff-000c29bafe8f:1-326575,
791748b3-d37a-11e8-b03a-000c29b7f985:1-374 |
+---------------+----------+--------------+------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+Gebruik hetzelfde datumformaat en extraheer de informatie die we willen uit het binaire logboek, binlog.000004. We schatten de starttijd voor het lezen van de binlog ongeveer 20 minuten geleden (2018-12-04 14:35:00) en filteren de uitvoer om 25 regels te tonen vóór de "drop column"-instructie:
$ mysqlbinlog --start-datetime="2018-12-04 14:35:00" --stop-datetime="2018-12-04 14:55:41" /var/lib/mysql/binlog.000004 | grep -i -B 25 "drop column"
'/*!*/;
# at 19379172
#181204 14:54:45 server id 1 end_log_pos 19379232 CRC32 0x0716e7a2 Table_map: `shop`.`settings` mapped to number 766
# at 19379232
#181204 14:54:45 server id 1 end_log_pos 19379460 CRC32 0xa6187edd Write_rows: table id 766 flags: STMT_END_F
BINLOG '
tSQGXBMBAAAAPAAAACC0JwEAAP4CAAAAAAEABnNidGVzdAAHc2J0ZXN0MgAFAwP+/gME/nj+PBCi
5xYH
tSQGXB4BAAAA5AAAAAS1JwEAAP4CAAAAAAEAAgAF/+AYwwAAysYAAHc0ODYyMjI0NjI5OC0zNDE2
OTY3MjY5OS02MDQ1NTQwOTY1Ny01MjY2MDQ0MDcwOC05NDA0NzQzOTUwMS00OTA2MTAxNzgwNC05
OTIyMzM3NzEwOS05NzIwMzc5NTA4OC0yODAzOTU2NjQ2MC0zNzY0ODg3MTYzOTswMTM0MjAwNTcw
Ni02Mjk1ODMzMzExNi00NzQ1MjMxODA1OS0zODk4MDQwMjk5MS03OTc4MTA3OTkwNQEAAADdfhim
'/*!*/;
# at 19379460
#181204 14:54:45 server id 1 end_log_pos 19379491 CRC32 0x71f00e63 Xid = 622405
COMMIT/*!*/;
# at 19379491
#181204 14:54:46 server id 1 end_log_pos 19379556 CRC32 0x62b78c9e GTID last_committed=11507 sequence_number=11508 rbr_only=no
SET @@SESSION.GTID_NEXT= '1560665e-ed2b-11e8-93fa-000c29b7f985:11508'/*!*/;
# at 19379556
#181204 14:54:46 server id 1 end_log_pos 19379672 CRC32 0xc222542a Query thread_id=3162 exec_time=1 error_code=0
SET TIMESTAMP=1543906486/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
ALTER TABLE settings DROP COLUMN statusIn de onderste paar regels van de mysqlbinlog-uitvoer zou je het foutieve commando moeten hebben dat werd uitgevoerd op positie 19379556. De positie die we moeten herstellen is een stap eerder, namelijk in positie 19379491. Dit is de binlog-positie waar we onze vertraagde slaaf te zijn.
Stop vervolgens op de gekozen vertraagde slave de vertraagde replicatieslave en start de slave opnieuw naar een vaste eindpositie die we hierboven hebben bedacht:
$ docker exec -it mysql-slave-15m mysql -uroot -p
mysql> STOP SLAVE;
mysql> START SLAVE UNTIL MASTER_LOG_FILE = 'binlog.000004', MASTER_LOG_POS = 19379491;Controleer de replicatiestatus en wacht tot Exec_Master_Log_Pos gelijk is aan de waarde Until_Log_Pos. Dit kan enige tijd duren. Als je eenmaal bent ingehaald, zou je het volgende moeten zien:
$ docker exec -it mysql-slave-15m mysql -uroot -p -e 'SHOW SLAVE STATUS\G'
...
Exec_Master_Log_Pos: 19379491
Relay_Log_Space: 50552186
Until_Condition: Master
Until_Log_File: binlog.000004
Until_Log_Pos: 19379491
...Controleer ten slotte of de ontbrekende gegevens waarnaar we op zoek waren aanwezig zijn (kolom "status" bestaat nog steeds):
mysql> DESCRIBE shop.settings;
+--------+------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+------------------+------+-----+---------+----------------+
| id | int(10) unsigned | NO | PRI | NULL | auto_increment |
| sid | int(10) unsigned | NO | MUL | 0 | |
| param | varchar(100) | NO | | | |
| value | varchar(255) | NO | | | |
| status | int(11) | YES | | 1 | |
+--------+------------------+------+-----+---------+----------------+Exporteer vervolgens de tabel uit onze slave-container en breng deze over naar de masterserver:
$ docker exec -it mysql-slave-1h mysqldump -uroot -ppassword --single-transaction shop settings > shop_settings.sqlLaat de problematische tabel vallen en herstel deze terug op de master:
$ mysql -uroot -p -e 'DROP TABLE shop.settings'
$ mysqldump -uroot -p -e shop < shop_setttings.sqlWe hebben onze tafel nu teruggebracht in de oorspronkelijke staat van voor de rampzalige gebeurtenis. Samenvattend kan uitgestelde replicatie voor verschillende doeleinden worden gebruikt:
- Om te beschermen tegen gebruikersfouten op de master. Een DBA kan een vertraagde slaaf terugdraaien naar de tijd net voor de ramp.
- Om te testen hoe het systeem zich gedraagt als er een vertraging is. In een toepassing kan bijvoorbeeld een vertraging worden veroorzaakt door een zware belasting van de slave. Het kan echter moeilijk zijn om dit belastingsniveau te genereren. Vertraagde replicatie kan de vertraging simuleren zonder de belasting te hoeven simuleren. Het kan ook worden gebruikt om problemen met een achterblijvende slaaf te debuggen.
- Om te zien hoe de database er in het verleden uitzag, zonder een back-up te hoeven herladen. Als de vertraging bijvoorbeeld een week is en de DBA moet zien hoe de database eruitzag voor de ontwikkeling van de afgelopen dagen, kan de vertraagde slaaf worden geïnspecteerd.
Laatste gedachten
Met Docker kan het efficiënt draaien van meerdere MySQL-instances op dezelfde fysieke host. U kunt Docker-orkestratietools zoals Docker Compose en Swarm gebruiken om de implementatie met meerdere containers te vereenvoudigen, in tegenstelling tot de stappen die in deze blogpost worden getoond.