Presto is een open-source, parallel gedistribueerde SQL-engine voor de verwerking van big data. Het is vanaf de grond af ontwikkeld door Facebook. De eerste interne release vond plaats in 2013 en was een behoorlijk revolutionaire oplossing voor hun big data-problemen.
Met de honderden geografisch gelokaliseerde servers en petabytes aan gegevens ging Facebook op zoek naar een alternatief platform voor hun Hadoop-clusters. Hun infrastructuurteam wilde de tijd die nodig was voor het uitvoeren van analysebatchtaken verminderen en de ontwikkeling van pijplijnen vereenvoudigen door gebruik te maken van programmeertaal die algemeen bekend is in de organisatie - SQL.
Volgens de Presto Foundation:“Facebook gebruikt Presto voor interactieve zoekopdrachten op verschillende interne datastores, waaronder hun 300PB datawarehouse. Meer dan 1.000 Facebook-medewerkers gebruiken Presto dagelijks om meer dan 30.000 zoekopdrachten uit te voeren die in totaal meer dan een petabyte per dag scannen.”
Hoewel Facebook een uitzonderlijke datawarehouse-omgeving heeft, zijn dezelfde uitdagingen aanwezig in veel organisaties die met big data te maken hebben.
In deze blog bekijken we hoe je een presto-basisomgeving opzet met een Docker-server uit het tar-bestand. Als gegevensbron zullen we ons concentreren op de MySQL-gegevensbron, maar dit kan elke andere populaire RDBMS zijn.
Presto gebruiken in een big data-omgeving
Laten we, voordat we beginnen, even kijken naar de belangrijkste architectuurprincipes. Presto is een alternatief voor tools die HDFS opvragen met behulp van pijplijnen van MapReduce-taken, zoals Hive. In tegenstelling tot Hive gebruikt Presto MapReduce niet. Presto wordt uitgevoerd met een speciale engine voor het uitvoeren van query's met operators op hoog niveau en verwerking in het geheugen.
In tegenstelling tot Hive kan Presto gegevens door alle fasen tegelijk streamen en tegelijkertijd gegevensblokken uitvoeren. Het is ontworpen om ad-hoc analytische query's uit te voeren op enkele of gedistribueerde heterogene gegevensbronnen. Het kan vanuit een Hadoop-platform reiken om relationele databases of andere gegevensarchieven zoals platte bestanden te doorzoeken.
Presto gebruikt standaard ANSI SQL inclusief aggregaties, joins of analytische vensterfuncties. SQL is bekend en veel gemakkelijker te gebruiken in vergelijking met MapReduce geschreven in Java.
Presto implementeren in Docker
De basisconfiguratie van Presto kan worden geïmplementeerd met een vooraf geconfigureerde Docker-image of presto-server-tarball.
De docker-server en Presto CLI-containers kunnen eenvoudig worden ingezet met:
docker run -d -p 127.0.0.1:8080:8080 --name presto starburstdata/presto
docker exec -it presto presto-cliU kunt kiezen tussen twee Presto-serverversies. Community-versie en Enterprise-versie van Starburst. Aangezien we het in een niet-productie-sandbox-omgeving gaan uitvoeren, zullen we de Apache-versie in dit artikel gebruiken.
Vereisten
Presto is volledig in Java geïmplementeerd en vereist dat JVM op uw systeem is geïnstalleerd. Het draait op zowel OpenJDK als Oracle Java. De minimale versie is Java 8u151 of Java 11.
Ga om JAVA JDK te downloaden naar https://openjdk.java.net/ of https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
U kunt uw Java-versie controleren met
$ java -version
openjdk version "1.8.0_222"
OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_222-b10)
OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.222-b10, mixed mode)Presto-installatie
Om Presto te installeren gaan we server tar en Presto CLI jar executable downloaden.
De tarball bevat een enkele directory op het hoogste niveau, presto-server-0.223, die we de installatiedirectory zullen noemen.
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.223/presto-server-0.223.tar.gz
$ tar -xzvf presto-server-0.223.tar.gz
$ cd presto-server-0.223/
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.223/presto-cli-0.223-executable.jar
$ mv presto-cli-0.223-executable.jar presto
$ chmod +x prestoBovendien heeft Presto een gegevensmap nodig voor het opslaan van logs, enz.
Het wordt aanbevolen om een gegevensmap te maken buiten de installatiemap.
$ mkdir -p ~/data/presto/Deze locatie is de plaats waar we beginnen met het oplossen van problemen.
Presto configureren
Voordat we onze eerste instantie starten, moeten we een aantal configuratiebestanden maken. Begin met het maken van een etc/-map in de installatiemap. Deze locatie bevat de volgende configuratiebestanden:
enz/
- Knooppunteigenschappen - omgevingsconfiguratie knooppunt
- JVM-configuratie (jvm.config) - Java Virtual Machine-configuratie
- Config Properties(config.properties) -configuratie voor de Presto-server
- Cataloguseigenschappen - configuratie voor connectoren (gegevensbronnen)
- Logeigenschappen - Configuratie van loggers
Hieronder vindt u enkele basisconfiguraties om Presto-sandbox uit te voeren. Bezoek de documentatie voor meer details.
vi etc/config.properties
Config.properties
coordinator = true
node-scheduler.include-coordinator = true
http-server.http.port = 8080
query.max-memory = 5GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = https://localhost:8080
vi etc/jvm.config
-server
-Xmx8G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
vi etc/log.properties
com.facebook.presto = INFOvi etc/node.properties
node.environment = production
node.id = ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir = /Users/bartez/data/prestoDe basisstructuur etc/ kan er als volgt uitzien:

De volgende stap is het opzetten van de MySQL-connector.
We gaan verbinding maken met een van de 3 nodes MariaDB Cluster.
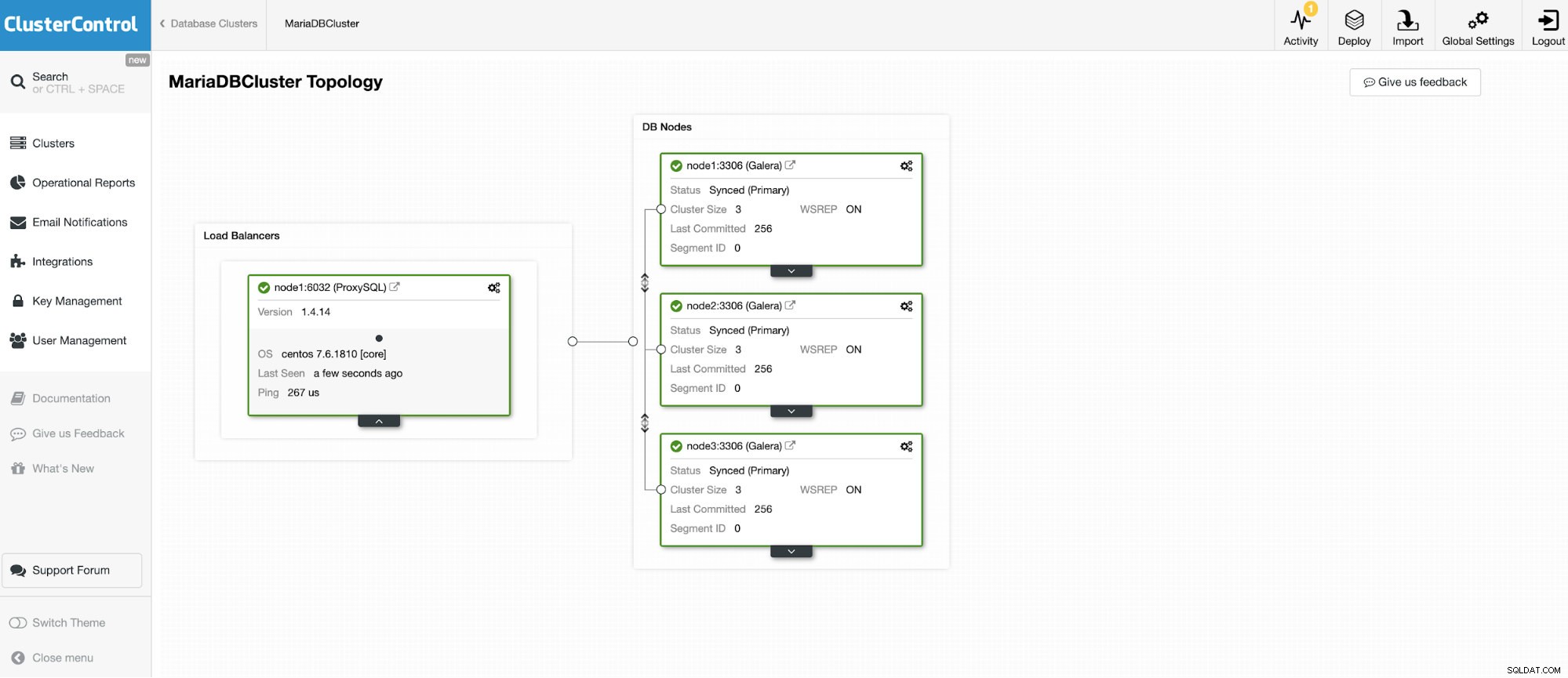
En nog een zelfstandige instantie met Oracle MySQL 5.7.
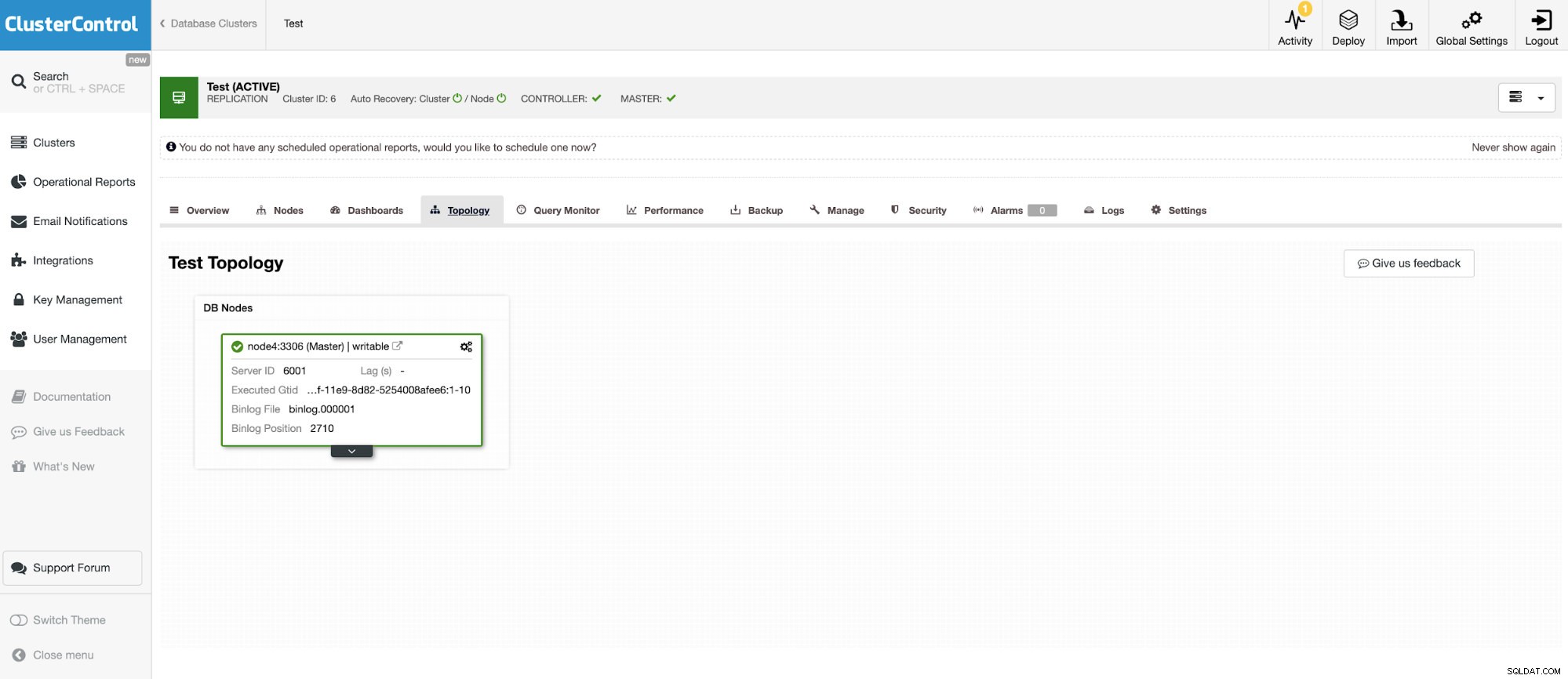
Met de MySQL-connector kunt u tabellen opvragen en maken in een externe MySQL-database. Dit kan worden gebruikt om gegevens tussen verschillende systemen, zoals MariaDB en MySQL van Oracle, samen te voegen.
Presto maakt gebruik van pluggable connectoren en de configuratie is zeer eenvoudig. Om de MySQL-connector te configureren, maakt u een bestand met cataloguseigenschappen in etc/catalog met de naam bijvoorbeeld mysql.properties, om de MySQL-connector te koppelen als de mysql-catalogus. Elk van de bestanden vertegenwoordigt een verbinding met een andere server. In dit geval hebben we twee bestanden:
vi etc/catalog/mysq.properties:
connector.name=mysql
connection-url=jdbc:mysql://node1.net:3306
connection-user=bart
connection-password=secretvi etc/catalog/mysq2.properties
connector.name=mysql
connection-url=jdbc:mysql://node4.net:3306
connection-user=bart2
connection-password=secretPresto draaien
Als alles is ingesteld, is het tijd om Presto-instantie te starten. Om presto te starten, gaat u naar de bin-map onder preso-installatie en voert u het volgende uit:
$ bin/launcher start
Started as 18363Presto-run stoppen
$ bin/launcher stopWanneer de server nu actief is, kunnen we verbinding maken met Presto met CLI en de MySQL-database opvragen.
Presto console run starten:
./presto --server localhost:8080 --catalog mysql --schema employeesNu kunnen we onze databases opvragen via CLI.
presto:mysql> select * from mysql.employees.departments;
dept_no | dept_name
---------+--------------------
d009 | Customer Service
d005 | Development
d002 | Finance
d003 | Human Resources
d001 | Marketing
d004 | Production
d006 | Quality Management
d008 | Research
d007 | Sales
(9 rows)
Query 20190730_232304_00019_uq3iu, FINISHED, 1 node
Splits: 17 total, 17 done (100,00%)
0:00 [9 rows, 0B] [81 rows/s, 0B/s]
Beide databases MariaDB-cluster en MySQL zijn gevoed met de werknemersdatabase.
wget https://github.com/datacharmer/test_db/archive/master.zip
mysql -uroot -psecret < employees.sqlDe status van de query is ook zichtbaar in de Presto-webconsole:https://localhost:8080/ui/#
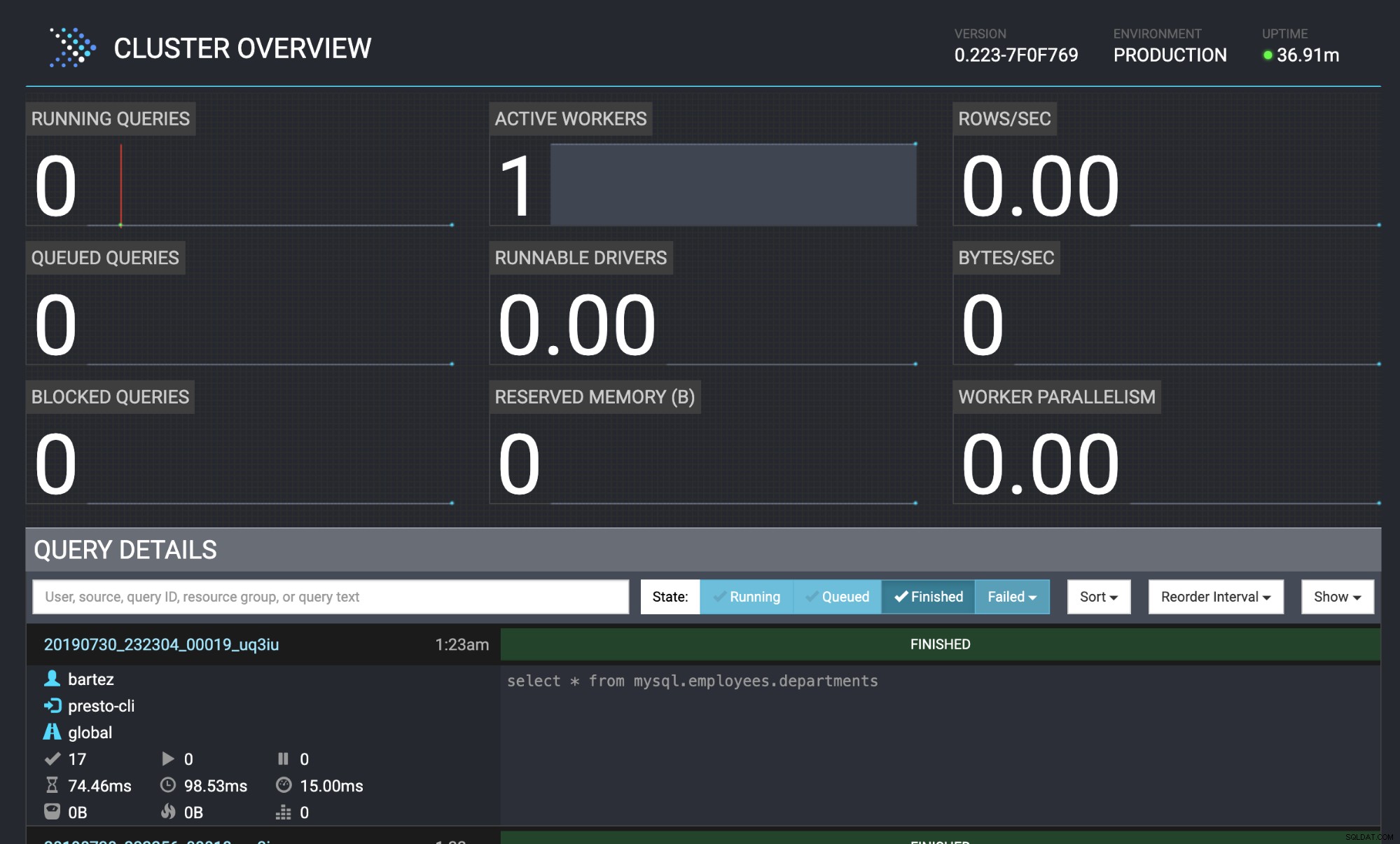 Presto-clusteroverzicht
Presto-clusteroverzicht Conclusie
Veel bekende bedrijven (zoals Airbnb, Netflix, Twitter) gebruiken Presto voor prestaties met een lage latentie. Het is zonder twijfel zeer interessante software die de noodzaak voor het uitvoeren van zware ETL-datawarehouse-processen kan elimineren. In deze blog hebben we een korte blik geworpen op de MySQL-connector, maar je kunt deze gebruiken om gegevens te analyseren van HDFS, objectstores, RDBMS (SQL Server, Oracle, PostgreSQL), Kafka, Cassandra, MongoDB en vele anderen.