Sinds ClusterControl 1.2.11 in 2015 werd uitgebracht, wordt MariaDB MaxScale ondersteund als load balancer voor databases. In de loop der jaren is MaxScale gegroeid en volwassener geworden en heeft het verschillende rijke functies toegevoegd. Onlangs is MariaDB MaxScale 2.2 uitgebracht en het introduceert verschillende nieuwe functies, waaronder failoverbeheer van replicatieclusters.
MariaDB MaxScale zorgt voor master/slave-implementaties met hoge beschikbaarheid, automatische failover, handmatige omschakeling en automatische re-join. Als de master faalt, kan MariaDB MaxScale automatisch de meest actuele slave tot master promoveren. Als de mislukte master wordt hersteld, kan MariaDB MaxScale deze automatisch opnieuw configureren als een slave voor de nieuwe master. Bovendien kunnen beheerders een handmatige omschakeling uitvoeren om de master op aanvraag te wijzigen.
In onze vorige blogs hebben we besproken hoe u MaxScale kunt implementeren met ClusterControl en hoe u MariaDB MaxScale op Docker kunt implementeren. Voor degenen die nog niet bekend zijn met MariaDB MaxScale, het is een geavanceerde, plug-in, databaseproxy voor MariaDB-databaseservers. Maxscale bevindt zich tussen clienttoepassingen en de databaseservers, waarbij clientquery's en serverreacties worden gerouteerd. Het bewaakt ook de servers en merkt snel veranderingen in de serverstatus of replicatietopologie op.
Hoewel Maxscale enkele kenmerken deelt van andere load balancing-technologieën zoals ProxySQL, valt deze nieuwe failover-functie (die deel uitmaakt van het monitoring- en autodetectiemechanisme) op. In deze blog gaan we het hebben over deze spannende nieuwe functie van Maxscale.
Overzicht van het MariaDB MaxScale Failover-mechanisme
Hoofddetectie
De monitor zal nu minder snel van masterserver veranderen, zelfs als een andere server meer slaves heeft dan de huidige master. De DBA kan een masterherselectie forceren door de huidige master alleen-lezen in te stellen, of door alle slaves te verwijderen als de master niet beschikbaar is.
Er kan slechts één server tegelijk de Master-statusvlag hebben, zelfs in een multimaster-opstelling. Andere servers in de multimastergroep krijgen de statusvlaggen Relay Master en Slave.
Overschakelen naar nieuwe hoofdautoselectie
Het switchover-commando kan nu worden aangeroepen met alleen de naam van de monitorinstantie als parameter. In dit geval selecteert de monitor automatisch een server voor promotie.
Detectie van replicatievertraging
De meting van de replicatievertraging leest nu gewoon de Seconds_Behind_Master -veld van de slave-statusuitgang van slaves. De slaaf berekent deze waarde door de tijdstempel in de binlog-gebeurtenis die de slaaf momenteel verwerkt te vergelijken met de eigen klok van de slaaf. Als een slave meerdere slave-aansluitingen heeft, wordt de kleinste vertraging gebruikt.
Automatische omschakeling na detectie van weinig schijfruimte
Met de recente MariaDB Server-versies kan de monitor nu de schijfruimte op de backend controleren en detecteren of de server bijna leeg is. Wanneer dit gebeurt, kan de monitor worden ingesteld om automatisch over te schakelen van een master die weinig schijfruimte heeft. Slaves kunnen ook in de onderhoudsmodus worden gezet. De schijfruimte is ook een factor waarmee rekening wordt gehouden bij het selecteren van de nieuwe master die moet worden gepromoot.
Zie switchover_on_low_disk_space en maintenance_on_low_disk_space voor meer informatie.
Replicatie-resetfunctie
De reset-replicatie monitor-opdracht verwijdert alle slave-verbindingen en binaire logboeken en stelt vervolgens replicatie in. Handig wanneer gegevens gesynchroniseerd zijn, maar gtid's niet.
Geplande afhandeling van gebeurtenissen in failover/switchover/rejoin
Servergebeurtenissen die door de gebeurtenisplannerthread zijn gestart, worden nu verwerkt tijdens clusterwijzigingsbewerkingen. Zie handle_server_events voor meer informatie.
Externe Master-ondersteuning
De monitor kan detecteren of een server in het cluster repliceert vanaf een externe master (een server die niet wordt bewaakt door de MaxScale-monitor). Als de replicerende server de clustermasterserver is, wordt aangenomen dat de cluster zelf een externe master heeft.
Als er een failover/omschakeling plaatsvindt, wordt de nieuwe masterserver ingesteld om te repliceren vanaf de externe masterserver van het cluster. De gebruikersnaam en het wachtwoord voor de replicatie worden gedefinieerd in replication_user en replication_password. Het adres en de poort die worden gebruikt, worden weergegeven door SHOW ALL SLAVES STATUS op de oude clustermasterserver. In het geval van omschakeling stopt de oude master ook met repliceren vanaf de externe server om de topologie te behouden.
Na een failover repliceert de nieuwe master vanaf de externe master. Als de mislukte oude master weer online komt, repliceert deze ook vanaf de externe server. Om de situatie te normaliseren, moet u auto_rejoin inschakelen of handmatig een rejoin uitvoeren. Hierdoor wordt de oude master omgeleid naar de huidige clustermaster.
Hoe is failover nuttig en toepasbaar?
Failover helpt u uitvaltijd te minimaliseren, dagelijks onderhoud uit te voeren of rampzalig en ongewenst onderhoud af te handelen dat soms op ongelukkige momenten kan plaatsvinden. Met MaxScale's vermogen om clientapplicaties te isoleren van back-end databaseservers, voegt het waardevolle functionaliteit toe die downtime helpt minimaliseren.
De MaxScale-monitoringplug-in bewaakt continu de status van backend-databaseservers. De routeringsplug-in van MaxScale gebruikt deze statusinformatie vervolgens om query's altijd naar backend-databaseservers die in gebruik zijn te routeren. Het is dan in staat om query's naar de backend-databaseclusters te sturen, zelfs als sommige servers van een cluster onderhoud ondergaan of een storing ondervinden.
Dankzij de hoge configureerbaarheid van MaxScale blijven wijzigingen in de clusterconfiguratie transparant voor clienttoepassingen. Als bijvoorbeeld een nieuwe server administratief moet worden toegevoegd aan of verwijderd uit een master-slave-cluster, kunt u eenvoudig de MaxScale-configuratie toevoegen aan de serverlijst met monitor- en router-plug-ins via de maxadmin CLI-console. De clienttoepassing is zich helemaal niet bewust van deze wijziging en blijft databasequery's naar de luisterpoort van de MaxScale sturen.
Het instellen van een databaseserver in onderhoud is eenvoudig en gemakkelijk. Voer gewoon de volgende opdracht uit met maxctrl en MaxScale stopt met het verzenden van vragen naar deze server. Bijvoorbeeld,
maxctrl: set server DB_785 maintenance
OKControleer vervolgens de serverstatus als volgt,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬──────────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Maintenance, Running │ 0-43001-70 │
└────────┴───────────────┴──────┴─────────────┴──────────────────────┴────────────┘Eenmaal in de onderhoudsmodus stopt MaxScale met het routeren van nieuwe verzoeken naar de server. Voor huidige verzoeken zal MaxScale deze sessies niet beëindigen, maar eerder toestaan om de uitvoering te voltooien en geen lopende query's onderbreken in de onderhoudsmodus. Houd er ook rekening mee dat de onderhoudsmodus niet persistent is. Als MaxScale opnieuw wordt opgestart wanneer een knooppunt zich in de onderhoudsmodus bevindt, zal een nieuwe instantie van MariaDB MaxScale deze modus niet respecteren. Als er meerdere MariaDB MaxScale-instanties zijn geconfigureerd om het knooppunt te gebruiken, moet de onderhoudsmodus worden ingesteld binnen elke MariaDB MaxScale-instantie. Als echter meerdere services binnen één MariaDB MaxScale-instantie de server gebruiken, hoeft u de onderhoudsmodus slechts eenmaal op de server in te stellen zodat alle services kennis kunnen nemen van de moduswijziging.
Als u klaar bent met uw onderhoud, maakt u de server gewoon leeg met de volgende opdracht. Bijvoorbeeld,
maxctrl: clear server DB_785 maintenance
OKOm te controleren of het weer normaal is, voert u het commando list servers uit .
U kunt ook bepaalde administratieve acties toepassen via de gebruikersinterface van ClusterControl. Zie de voorbeeldscreenshot hieronder:
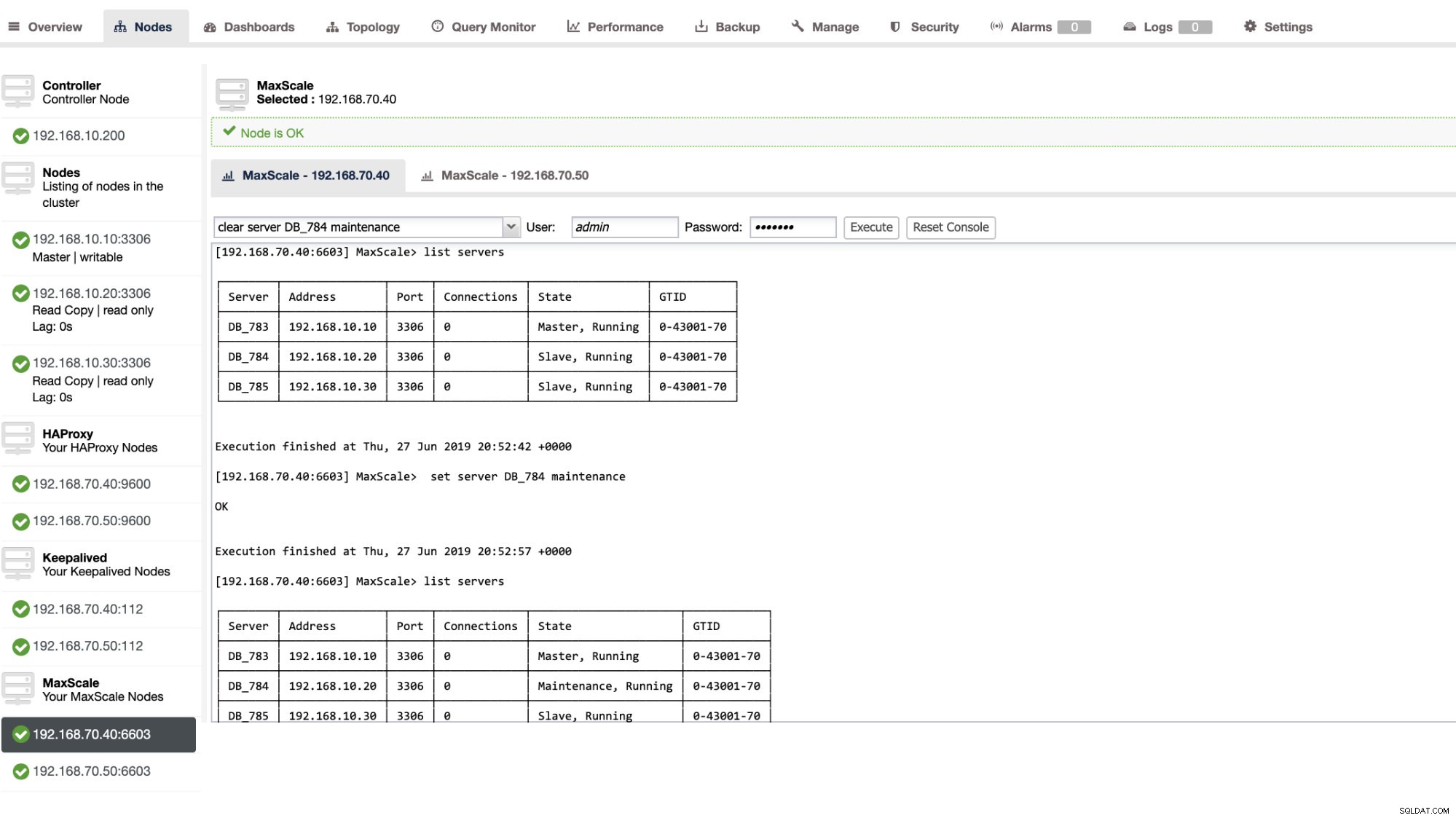
MaxScale-failover in actie
De automatische failover
MariaDB's MaxScale-failover werkt zeer efficiënt en configureert de slave overeenkomstig zoals verwacht. In deze test hebben we de volgende configuratiebestandenset die is gemaakt en beheerd door ClusterControl. Zie hieronder:
[replication_monitor]
type=monitor
servers=DB_783,DB_784,DB_785
disk_space_check_interval=1000
disk_space_threshold=/:85
detect_replication_lag=true
enforce_read_only_slaves=true
failcount=3
auto_failover=1
auto_rejoin=true
monitor_interval=300
password=725DE70F196694B277117DC825994D44
user=maxscalecc
replication_password=5349E1268CC4AF42B919A42C8E52D185
replication_user=rpl_user
module=mariadbmonHoud er rekening mee dat alleen de auto_failover en auto_rejoin zijn de variabelen die ik heb toegevoegd aangezien ClusterControl dit niet standaard zal toevoegen als je eenmaal een MaxScale load balancer hebt ingesteld (bekijk deze blog over hoe je MaxScale instelt met ClusterControl). Vergeet niet dat u MariaDB MaxScale opnieuw moet opstarten nadat u de wijzigingen in uw configuratiebestand hebt toegepast. Gewoon rennen,
systemctl restart maxscaleen je bent klaar om te gaan.
Voordat we verder gaan met de failover-test, moeten we eerst de status van het cluster controleren:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Ziet er geweldig uit!
Ik heb de master gedood met alleen het pure killer-commando KILL -9 $ (pidof mysqld) in mijn masterknooppunt en zie, tot geen verrassing, de monitor dit snel opmerkend en activeert de failover. Bekijk de logs als volgt:
2019-06-28 06:39:14.306 error : (mon_log_connect_error): Monitor was unable to connect to server DB_783[192.168.10.10:3306] : 'Can't connect to MySQL server on '192.168.10.10' (115)'
2019-06-28 06:39:14.329 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: master_down. [Master, Running] -> [Down]
2019-06-28 06:39:14.329 warning: (handle_auto_failover): Master has failed. If master status does not change in 2 monitor passes, failover begins.
2019-06-28 06:39:15.011 notice : (select_promotion_target): Selecting a server to promote and replace 'DB_783'. Candidates are: 'DB_784', 'DB_785'.
2019-06-28 06:39:15.011 warning: (warn_replication_settings): Slave 'DB_784' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 warning: (warn_replication_settings): Slave 'DB_785' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 notice : (select_promotion_target): Selected 'DB_784'.
2019-06-28 06:39:15.012 notice : (handle_auto_failover): Performing automatic failover to replace failed master 'DB_783'.
2019-06-28 06:39:15.017 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_784' instead of 'DB_783'.
2019-06-28 06:39:15.024 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 06:39:15.527 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_784'.
2019-06-28 06:39:15.527 notice : (handle_auto_failover): Failover 'DB_783' -> 'DB_784' performed.
2019-06-28 06:39:15.634 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 06:39:20.165 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: slave_up. [Down] -> [Slave, Running]Laten we nu eens kijken naar de gezondheid van het cluster,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Down │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Het knooppunt 192.168.10.10 dat voorheen de master was, is niet beschikbaar. Ik heb geprobeerd opnieuw op te starten en te kijken of automatisch opnieuw deelnemen zou worden geactiveerd, en zoals je opmerkte in het logboek op het moment 2019-06-28 06:39:20.165, het is zo snel geweest om de status van het knooppunt te detecteren en vervolgens de configuratie automatisch in te stellen zonder gedoe voor de DBA om het aan te zetten.
Nu, als laatste controlerend op de staat, ziet het er perfect uit zoals verwacht. Zie hieronder:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Mijn ex-Master is gerepareerd en hersteld en ik wil overstappen
Ook overstappen naar je vorige master is geen probleem. U kunt dit bedienen met maxctrl (of maxadmin in eerdere versies van MaxScale) of via ClusterControl UI (zoals eerder aangetoond).
Laten we even verwijzen naar de vorige status van de replicatieclustergezondheid eerder, en wilden de 192.168.10.10 (momenteel slave) terugzetten naar zijn masterstatus. Voordat we verder gaan, moet u mogelijk eerst de monitor identificeren die u gaat gebruiken. U kunt dit verifiëren met de volgende opdracht hieronder:
maxctrl: list monitors
┌─────────────────────┬─────────┬────────────────────────┐
│ Monitor │ State │ Servers │
├─────────────────────┼─────────┼────────────────────────┤
│ replication_monitor │ Running │ DB_783, DB_784, DB_785 │
└─────────────────────┴─────────┴────────────────────────┘Als je het eenmaal hebt, kun je de volgende opdracht hieronder uitvoeren om over te schakelen:
maxctrl: call command mariadbmon switchover replication_monitor DB_783 DB_784
OKControleer vervolgens nogmaals de status van het cluster,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Ziet er perfect uit!
Logs zullen u uitgebreid laten zien hoe het ging en de reeks acties tijdens de omschakeling. Zie de details hieronder:
2019-06-28 07:03:48.064 error : (switchover_prepare): 'DB_784' is not a valid promotion target for switchover because it is already the master.
2019-06-28 07:03:48.064 error : (manual_switchover): Switchover cancelled.
2019-06-28 07:04:30.700 notice : (create_start_slave): Slave connection from DB_784 to [192.168.10.10]:3306 created and started.
2019-06-28 07:04:30.700 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_783' instead of 'DB_784'.
2019-06-28 07:04:30.708 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 07:04:31.209 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_783'.
2019-06-28 07:04:31.209 notice : (manual_switchover): Switchover 'DB_784' -> 'DB_783' performed.
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_slave. [Master, Running] -> [Slave, Running]In het geval van een verkeerde omschakeling, zal het niet doorgaan en zal het dus een fout genereren zoals weergegeven in het bovenstaande logboek. Dus je bent veilig en helemaal geen enge verrassingen.
Uw MaxScale zeer beschikbaar maken
Hoewel het een beetje off-topic is met betrekking tot failover, wilde ik hier enkele waardevolle punten toevoegen met betrekking tot hoge beschikbaarheid en hoe dit verband hield met MariaDB MaxScale-failover.
Het maximaal beschikbaar maken van uw MaxScale is een belangrijk onderdeel in het geval dat uw systeem crasht, schijfcorruptie of beschadiging van virtuele machines ervaart. Deze situaties zijn onvermijdelijk en kunnen de status van uw geautomatiseerde failover-configuratie beïnvloeden wanneer deze onverwachte onderhoudscycli plaatsvinden.
Voor een omgeving van het type replicatiecluster is dit zeer nuttig en wordt het ten zeerste aanbevolen voor een specifieke MaxScale-configuratie. Het doel hiervan is dat slechts één MaxScale-instantie het cluster op een bepaald moment mag wijzigen. Als je een setup hebt met Keepalived, zijn dit waar de instances met de status MASTER. MaxScale zelf kent de staat niet, maar met maxctrl (of maxadmin in eerdere versies) kan een MaxScale-instantie in de passieve modus zetten. Vanaf versie 2.2.2 gedraagt een passieve MaxScale zich vergelijkbaar met een actieve MaxScale, met het verschil dat het geen failover, omschakeling of re-join zal uitvoeren. Zelfs handmatige versies van deze opdrachten eindigen in een fout. De verschillen in passieve/actieve modus kunnen in de toekomst worden uitgebreid, dus blijf op de hoogte van dergelijke wijzigingen in MaxScale. Om dit te doen, doet u het volgende:
maxctrl: alter maxscale passive true
OKU kunt dit achteraf verifiëren door de onderstaande opdracht uit te voeren:
[example@sqldat.com vagrant]# maxctrl -u admin -p mariadb -h 127.0.0.1:8989 show maxscale|grep 'passive'
│ │ "passive": true, │Als je wilt zien hoe je een hoge beschikbaarheid kunt instellen met Keepalive, bekijk dan dit bericht van MariaDB.
VIP-behandeling
Bovendien, aangezien MaxScale zelf geen ingebouwde VIP-afhandeling heeft, kunt u Keepalive gebruiken om dat voor u af te handelen. U kunt gewoon het virtual_ipaddress gebruiken dat is toegewezen aan het MASTER-statusknooppunt. Dit komt waarschijnlijk met virtueel IP-beheer, net zoals MHA doet met de variabele master_failover_script. Zoals eerder vermeld, bekijk deze Keepalived met MaxScale setup-blogpost van MariaDB.
Conclusie
MariaDB MaxScale is rijk aan functies en heeft veel mogelijkheden, niet alleen beperkt tot het zijn van een proxy en load balancer, maar het biedt ook het failover-mechanisme waarnaar grote organisaties op zoek zijn. Het is bijna one-size-fits-all software, maar komt natuurlijk met beperkingen die een bepaalde applicatie nodig kan hebben in tegenstelling tot andere load balancers zoals ProxySQL.
ClusterControl biedt ook een auto-failover en master-autodetectiemechanisme, plus cluster- en nodeherstel met de mogelijkheid om Maxscale en andere load balancing-technologieën in te zetten.
Elk van deze tools heeft zijn verschillende kenmerken en functionaliteit, maar MariaDB MaxScale wordt goed ondersteund binnen ClusterControl en kan samen met Keepalived, HAProxy worden ingezet om u te helpen uw dagelijkse routinetaak te versnellen.