Galera Cluster, met zijn (vrijwel) synchrone replicatie, wordt veel gebruikt in veel verschillende soorten omgevingen. Het schalen door nieuwe knooppunten toe te voegen is niet moeilijk (of net zo eenvoudig een paar klikken als u ClusterControl gebruikt).
Het grootste probleem met synchrone replicatie is, nou ja, het synchrone deel dat er vaak toe leidt dat het hele cluster slechts zo snel is als het langzaamste knooppunt. Elke schrijfactie die op een cluster wordt uitgevoerd, moet naar alle knooppunten worden gerepliceerd en daarop worden gecertificeerd. Als dit proces om wat voor reden dan ook vertraagt, kan dit ernstige gevolgen hebben voor het vermogen van het cluster om schrijfbewerkingen op te vangen. Flow control treedt dan in werking, dit is om ervoor te zorgen dat de langzaamste node de belasting nog kan bijhouden. Dit maakt het nogal lastig voor sommige van de veelvoorkomende scenario's die zich voordoen in een echte wereldomgeving.
Laten we eerst eens kijken naar geografisch gedistribueerd noodherstel. Natuurlijk kunt u clusters uitvoeren via een Wide Area Network, maar de verhoogde latentie heeft een aanzienlijke impact op de prestaties van het cluster. Dit beperkt de mogelijkheid om een dergelijke opstelling te gebruiken ernstig, vooral over langere afstanden wanneer de latentie hoger is.
Een andere veel voorkomende use-case - een testomgeving voor een grote versie-upgrade. Het is geen goed idee om verschillende versies van MariaDB Galera Cluster-knooppunten in hetzelfde cluster te combineren, zelfs als dit mogelijk is. Aan de andere kant vereist migratie naar de recentere versie gedetailleerde tests. Idealiter zouden zowel lezen als schrijven zijn getest. Een manier om dat te bereiken is door een apart Galera-cluster te maken en de tests uit te voeren, maar u wilt de tests uitvoeren in een omgeving die zo dicht mogelijk bij de productie ligt. Eenmaal ingericht, kan een cluster worden gebruikt voor tests met real-world queries, maar het zou moeilijk zijn om een workload te genereren die dicht bij die van productie ligt. U kunt een deel van het productieverkeer niet naar een dergelijk testsysteem verplaatsen, omdat de gegevens niet actueel zijn.
Tot slot de migratie zelf. Nogmaals, wat we eerder zeiden, zelfs als het mogelijk is om oude en nieuwe versies van Galera-knooppunten in hetzelfde cluster te combineren, is dit niet de veiligste manier om het te doen.
Gelukkig zou de eenvoudigste oplossing voor al deze drie problemen zijn om afzonderlijke Galera-clusters te verbinden met een asynchrone replicatie. Wat maakt het zo'n goede oplossing? Welnu, het is asynchroon waardoor het de Galera-replicatie niet beïnvloedt. Er is geen flow control, dus de prestaties van het "master"-cluster worden niet beïnvloed door de prestaties van het "slave"-cluster. Zoals bij elke asynchrone replicatie kan er een vertraging optreden, maar zolang deze binnen acceptabele limieten blijft, kan het prima werken. Je moet er ook rekening mee houden dat asynchrone replicatie tegenwoordig kan worden geparalleliseerd (meerdere threads kunnen samenwerken om de bandbreedte te vergroten) en de replicatievertraging nog verder te verminderen.
In deze blogpost bespreken we wat de stappen zijn om asynchrone replicatie tussen MariaDB Galera-clusters in te zetten.
Hoe asynchrone replicatie tussen MariaDB Galera-clusters configureren?
Eerst moeten we een cluster inzetten. Voor onze doeleinden hebben we een cluster met drie knooppunten opgezet. We zullen de setup tot een minimum beperken, dus we zullen niet ingaan op de complexiteit van de applicatie- en proxylaag. Proxylaag kan erg handig zijn voor het afhandelen van taken waarvoor u asynchrone replicatie wilt implementeren - het omleiden van een subset van het alleen-lezen verkeer naar het testcluster, wat helpt bij noodherstel wanneer het "hoofd" cluster niet beschikbaar is door de verkeer naar het DR-cluster. Er zijn talloze proxy's die u kunt proberen, afhankelijk van uw voorkeur - HAProxy, MaxScale of ProxySQL - ze kunnen allemaal in dergelijke opstellingen worden gebruikt en, afhankelijk van het geval, kunnen sommige u helpen uw verkeer te beheren.
Het broncluster configureren
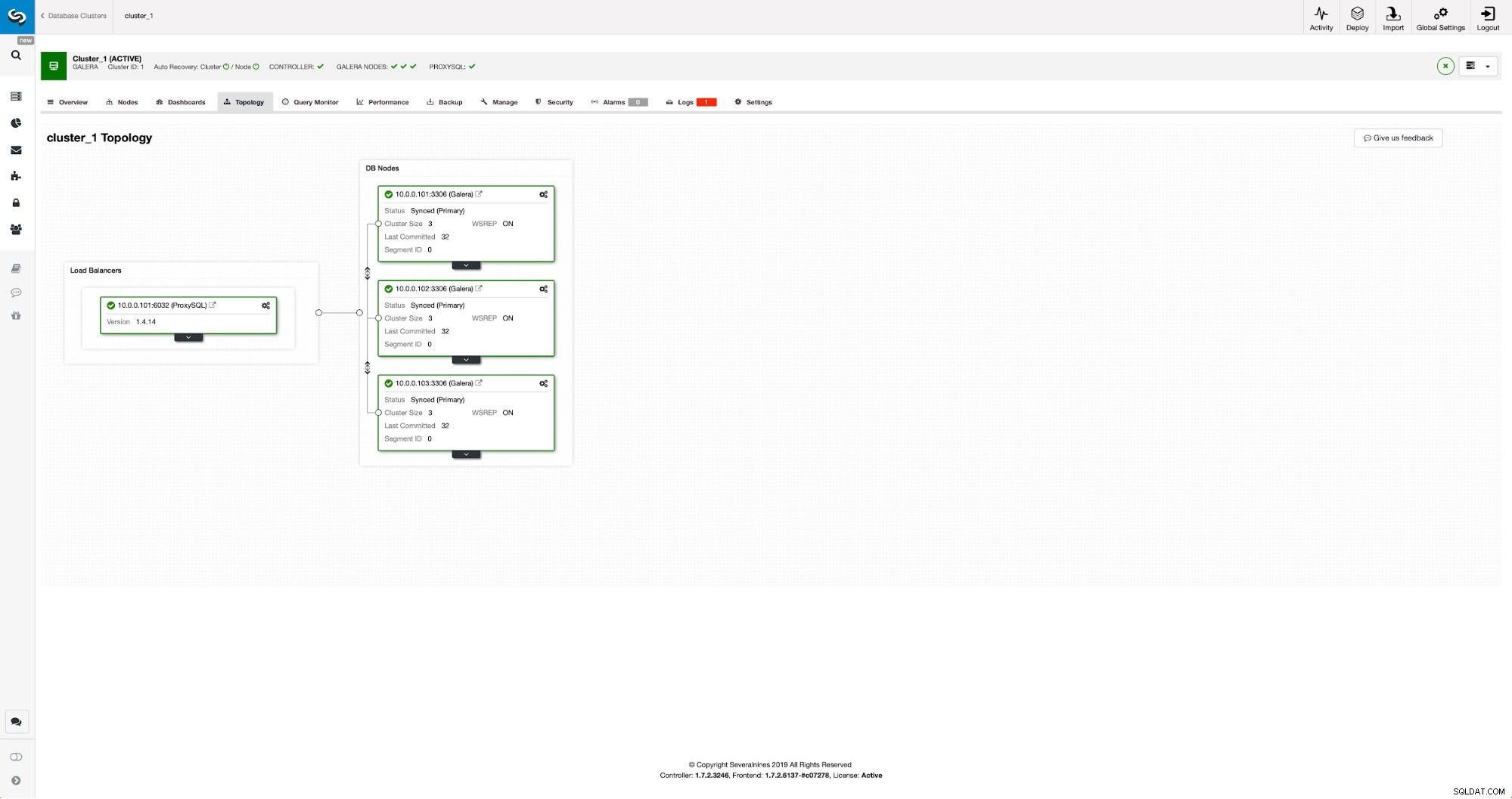
Ons cluster bestaat uit drie MariaDB 10.3-knooppunten, we hebben ook ProxySQL geïmplementeerd om de lees-schrijfsplitsing uit te voeren en het verkeer over alle knooppunten in het cluster te verdelen. Dit is geen implementatie op productieniveau, daarvoor zouden we meer ProxySQL-knooppunten en een Keepalive er bovenop moeten implementeren. Het is nog steeds genoeg voor onze doeleinden. Om asynchrone replicatie in te stellen, moeten we een binair logboek hebben ingeschakeld op ons cluster. Ten minste één knooppunt, maar het is beter om het op alle knooppunten ingeschakeld te houden voor het geval het enige knooppunt waarop binlog is ingeschakeld uitvalt - dan wilt u een ander knooppunt in het cluster actief hebben dat u kunt uitschakelen.
Wanneer u binaire logbestanden inschakelt, moet u ervoor zorgen dat u de binaire logrotatie configureert, zodat de oude logbestanden op een bepaald moment worden verwijderd. U gebruikt het binaire logformaat ROW. Je moet er ook voor zorgen dat je GTID hebt geconfigureerd en in gebruik bent - het zal erg handig zijn wanneer je je "slave"-cluster moet reslaven of als je multi-threaded replicatie moet inschakelen. Aangezien dit een Galera-cluster is, wil je dat 'wsrep_gtid_domain_id' is geconfigureerd en 'wsrep_gtid_mode' is ingeschakeld. Die instellingen zorgen ervoor dat GTID's worden gegenereerd voor het verkeer dat uit het Galera-cluster komt. Meer informatie vindt u in de documentatie. Zodra dit allemaal is gebeurd, kunt u doorgaan met het opzetten van het tweede cluster.
Het doelcluster instellen
Aangezien er momenteel geen doelgroep is, moeten we beginnen met het inzetten ervan. We zullen deze stappen niet in detail behandelen, instructies vindt u in de documentatie. Over het algemeen bestaat het proces uit verschillende stappen:
- MariaDB-opslagplaatsen configureren
- Installeer MariaDB 10.3-pakketten
- Configureer knooppunten om een cluster te vormen
In het begin zullen we beginnen met slechts één knooppunt. Je kunt ze allemaal instellen om een cluster te vormen, maar dan moet je ze stoppen en er maar één gebruiken voor de volgende stap. Dat ene knooppunt wordt een slaaf van het oorspronkelijke cluster. We zullen mariabackup gebruiken om het te voorzien. Daarna zullen we de replicatie configureren.
Eerst moeten we een map maken waarin we de back-up zullen opslaan:
mkdir /mnt/mariabackupVervolgens voeren we de back-up uit en maken deze aan in de map die in de bovenstaande stap is voorbereid. Zorg ervoor dat u de juiste gebruiker en het juiste wachtwoord gebruikt om verbinding te maken met de database:
mariabackup --backup --user=root --password=pass --target-dir=/mnt/mariabackup/Vervolgens moeten we de back-upbestanden naar het eerste knooppunt in het tweede cluster kopiëren. Daar hebben we scp voor gebruikt, je kunt gebruiken wat je wilt - rsync, netcat, alles wat maar werkt.
scp -r /mnt/mariabackup/* 10.0.0.104:/root/mariabackup/Nadat de back-up is gekopieerd, moeten we deze voorbereiden door de logbestanden toe te passen:
mariabackup --prepare --target-dir=/root/mariabackup/
mariabackup based on MariaDB server 10.3.16-MariaDB debian-linux-gnu (x86_64)
[00] 2019-06-24 08:35:39 cd to /root/mariabackup/
[00] 2019-06-24 08:35:39 This target seems to be not prepared yet.
[00] 2019-06-24 08:35:39 mariabackup: using the following InnoDB configuration for recovery:
[00] 2019-06-24 08:35:39 innodb_data_home_dir = .
[00] 2019-06-24 08:35:39 innodb_data_file_path = ibdata1:100M:autoextend
[00] 2019-06-24 08:35:39 innodb_log_group_home_dir = .
[00] 2019-06-24 08:35:39 InnoDB: Using Linux native AIO
[00] 2019-06-24 08:35:39 Starting InnoDB instance for recovery.
[00] 2019-06-24 08:35:39 mariabackup: Using 104857600 bytes for buffer pool (set by --use-memory parameter)
2019-06-24 8:35:39 0 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins
2019-06-24 8:35:39 0 [Note] InnoDB: Uses event mutexes
2019-06-24 8:35:39 0 [Note] InnoDB: Compressed tables use zlib 1.2.8
2019-06-24 8:35:39 0 [Note] InnoDB: Number of pools: 1
2019-06-24 8:35:39 0 [Note] InnoDB: Using SSE2 crc32 instructions
2019-06-24 8:35:39 0 [Note] InnoDB: Initializing buffer pool, total size = 100M, instances = 1, chunk size = 100M
2019-06-24 8:35:39 0 [Note] InnoDB: Completed initialization of buffer pool
2019-06-24 8:35:39 0 [Note] InnoDB: page_cleaner coordinator priority: -20
2019-06-24 8:35:39 0 [Note] InnoDB: Starting crash recovery from checkpoint LSN=3448619491
2019-06-24 8:35:40 0 [Note] InnoDB: Starting final batch to recover 759 pages from redo log.
2019-06-24 8:35:40 0 [Note] InnoDB: Last binlog file '/var/lib/mysql-binlog/binlog.000003', position 865364970
[00] 2019-06-24 08:35:40 Last binlog file /var/lib/mysql-binlog/binlog.000003, position 865364970
[00] 2019-06-24 08:35:40 mariabackup: Recovered WSREP position: e79a3494-964f-11e9-8a5c-53809a3c5017:25740
[00] 2019-06-24 08:35:41 completed OK!In het geval van een fout moet u mogelijk de back-up opnieuw uitvoeren. Als alles goed is gegaan, kunnen we de oude gegevens verwijderen en vervangen door de back-upinformatie
rm -rf /var/lib/mysql/*
mariabackup --copy-back --target-dir=/root/mariabackup/
…
[01] 2019-06-24 08:37:06 Copying ./sbtest/sbtest10.frm to /var/lib/mysql/sbtest/sbtest10.frm
[01] 2019-06-24 08:37:06 ...done
[00] 2019-06-24 08:37:06 completed OK!We willen ook de juiste eigenaar van de bestanden instellen:
chown -R mysql.mysql /var/lib/mysql/We vertrouwen op GTID om de replicatie consistent te houden, dus we moeten zien wat de laatst toegepaste GTID in deze back-up was. Die informatie is te vinden in het xtrabackup_info-bestand dat deel uitmaakt van de back-up:
example@sqldat.com:~/mariabackup# cat /var/lib/mysql/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000003', position '865364970', GTID of the last change '9999-1002-23012'We zullen er ook voor moeten zorgen dat de slave-node binaire logs heeft ingeschakeld samen met 'log_slave_updates'. In het ideale geval wordt dit ingeschakeld op alle knooppunten in het tweede cluster - voor het geval dat het "slave" -knooppunt faalt en u de replicatie zou moeten instellen met een ander knooppunt in het slave-cluster.
Het laatste wat we moeten doen voordat we de replicatie kunnen instellen, is een gebruiker maken die we zullen gebruiken om de replicatie uit te voeren:
MariaDB [(none)]> CREATE USER 'repuser'@'10.0.0.104' IDENTIFIED BY 'reppass';
Query OK, 0 rows affected (0.077 sec)MariaDB [(none)]> GRANT REPLICATION SLAVE ON *.* TO 'repuser'@'10.0.0.104';
Query OK, 0 rows affected (0.012 sec)Dat is alles wat we nodig hebben. Nu kunnen we het eerste knooppunt in het tweede cluster starten, onze toekomstige slaaf:
galera_new_clusterZodra het is gestart, kunnen we MySQL CLI invoeren en configureren om een slaaf te worden, met behulp van de GITD-positie die we een paar stappen eerder hebben gevonden:
mysql -ppassMariaDB [(none)]> SET GLOBAL gtid_slave_pos = '9999-1002-23012';
Query OK, 0 rows affected (0.026 sec)Zodra dat is gebeurd, kunnen we eindelijk de replicatie instellen en starten:
MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.016 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)Op dit moment hebben we een Galera-cluster bestaande uit één knooppunt. Dat knooppunt is ook een slaaf van het oorspronkelijke cluster (met name zijn meester is knooppunt 10.0.0.101). Om lid te worden van andere knooppunten zullen we SST gebruiken, maar om het eerst te laten werken, moeten we ervoor zorgen dat de SST-configuratie correct is - houd er rekening mee dat we zojuist alle gebruikers in ons tweede cluster hebben vervangen door de inhoud van het broncluster. Wat u nu moet doen, is ervoor zorgen dat de 'wsrep_sst_auth'-configuratie van het tweede cluster overeenkomt met die van het eerste cluster. Zodra dat is gebeurd, kun je de resterende knooppunten één voor één beginnen en ze moeten zich bij het bestaande knooppunt (10.0.0.104) voegen, de gegevens over SST krijgen en het Galera-cluster vormen. Uiteindelijk zou je moeten eindigen met twee clusters, elk drie knooppunten, met een asynchrone replicatielink erover (van 10.0.0.101 tot 10.0.0.104 in ons voorbeeld). U kunt bevestigen dat de replicatie werkt door de waarde te controleren van:
MariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 106 |
+----------------------+-------+
1 row in set (0.001 sec)MariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 114 |
+----------------------+-------+
1 row in set (0.001 sec)Hoe asynchrone replicatie tussen MariaDB Galera-clusters configureren met ClusterControl?
Op het moment van deze blog heeft ClusterControl niet de functionaliteit om asynchrone replicatie over meerdere clusters te configureren, we werken eraan terwijl ik dit typ. Desalniettemin kan ClusterControl een grote hulp zijn in dit proces - we laten u zien hoe u de moeizame handmatige stappen kunt versnellen met behulp van automatisering van ClusterControl.
Uit wat we eerder hebben laten zien, kunnen we concluderen dat dit de algemene stappen zijn die moeten worden genomen bij het opzetten van replicatie tussen twee Galera-clusters:
- Een nieuw Galera-cluster implementeren
- Nieuwe cluster inrichten met gegevens van de oude
- Nieuw cluster configureren (SST-configuratie, binaire logbestanden)
- Stel de replicatie in tussen het oude en het nieuwe cluster
De eerste drie punten zijn iets dat u zelfs nu gemakkelijk kunt doen met ClusterControl. We gaan je laten zien hoe je dat doet.
Een nieuw MariaDB Galera-cluster implementeren en inrichten met behulp van ClusterControl
De beginsituatie is vergelijkbaar:we hebben één cluster in gebruik. We moeten de tweede opzetten. Een van de meer recente functies van ClusterControl is een optie om een nieuw cluster te implementeren en in te richten met behulp van de gegevens uit de back-up. Dit is erg handig om testomgevingen te maken, het is ook een optie die we zullen gebruiken om ons nieuwe cluster in te richten voor de replicatie-installatie. Daarom is de eerste stap die we zullen nemen het maken van een back-up met mariabackup:
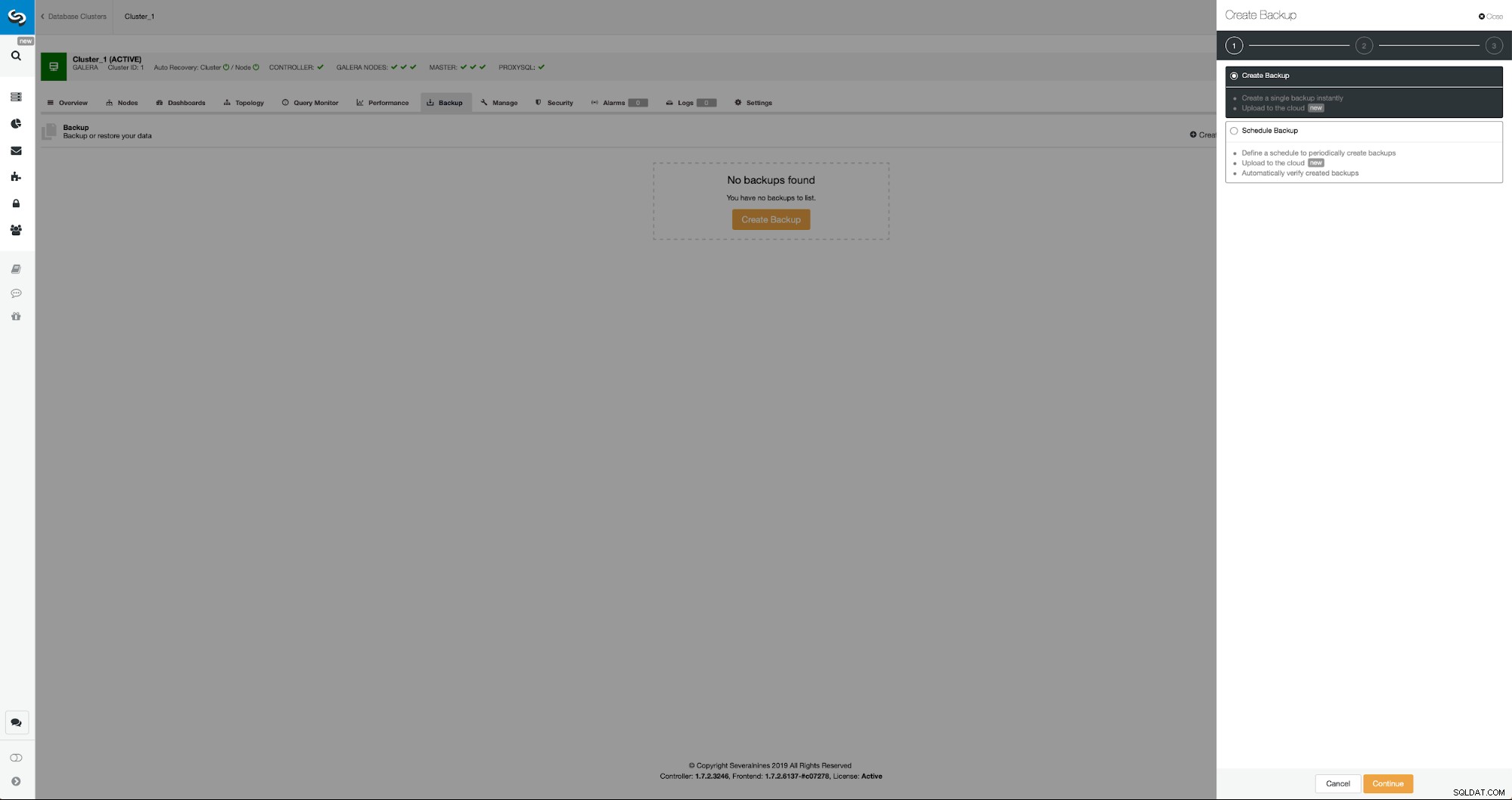
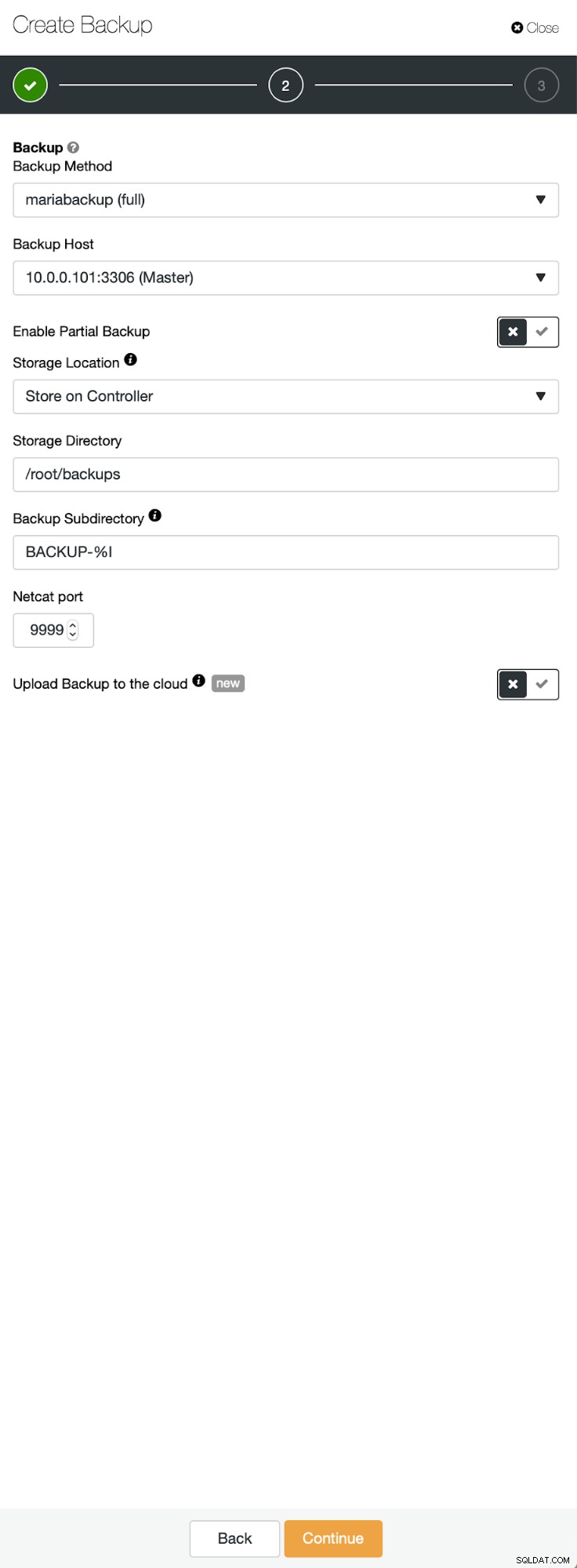
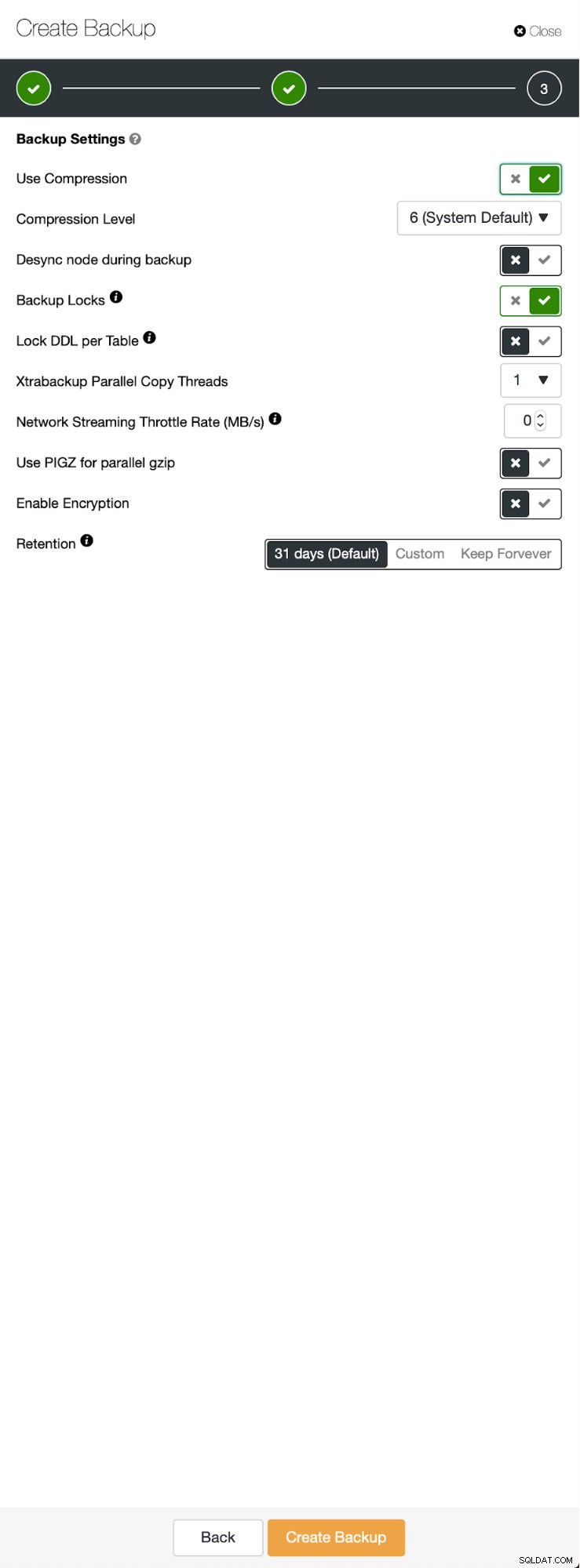
Drie stappen waarin we het knooppunt hebben gekozen om de back-up ervan af te halen. Dit knooppunt (10.0.0.101) wordt een master. Het moet binaire logboeken hebben ingeschakeld. In ons geval hebben alle knooppunten binlog ingeschakeld, maar als dat niet het geval was, is het heel eenvoudig om het vanuit de ClusterControl in te schakelen - we zullen de stappen later laten zien, wanneer we het voor het tweede cluster zullen doen.
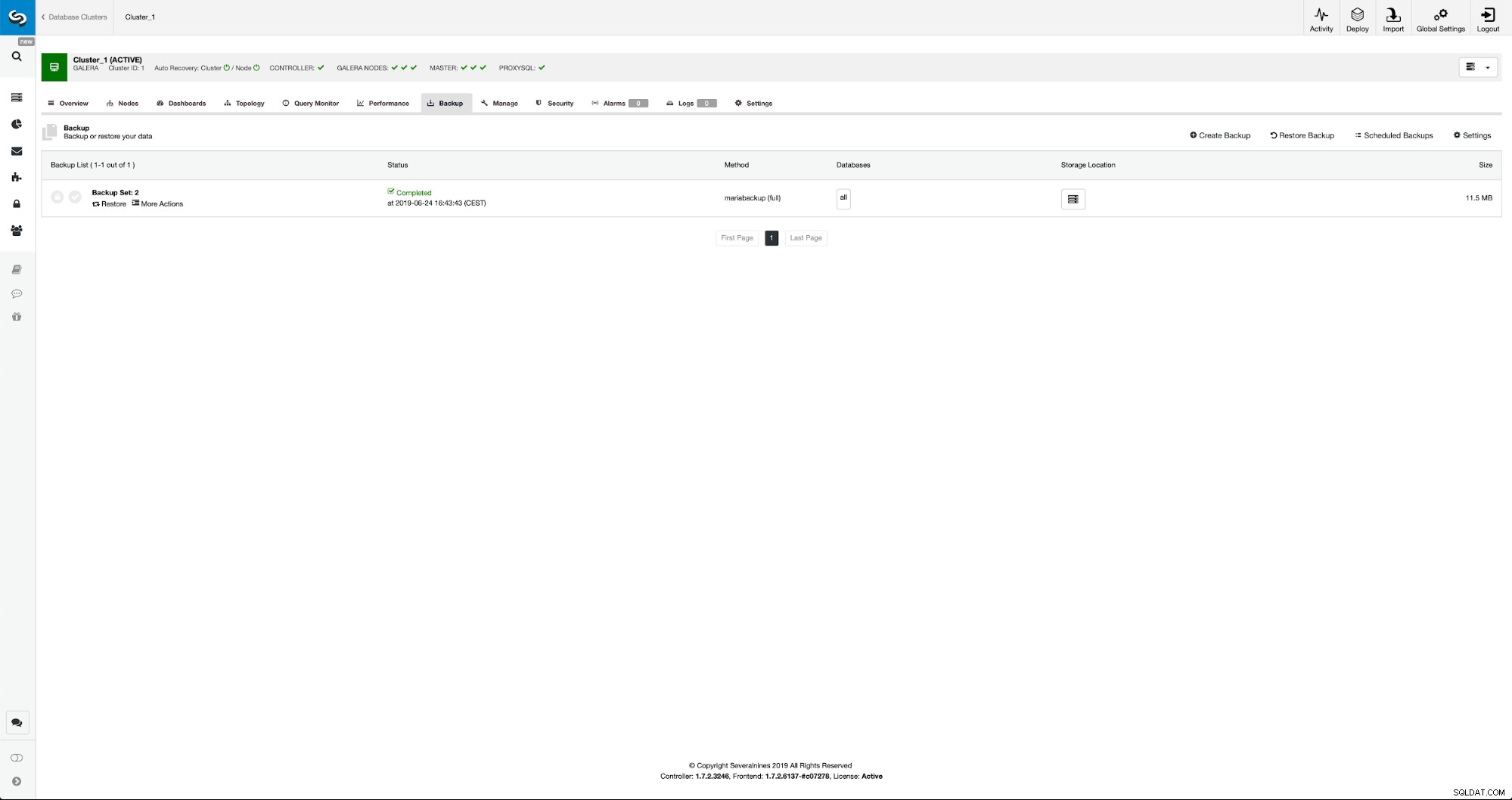
Zodra de back-up is voltooid, wordt deze zichtbaar in de lijst. We kunnen dan doorgaan en het herstellen:

Als we dat willen, zouden we zelfs de Point-In-Time Recovery kunnen doen, maar in ons geval maakt dat niet zoveel uit:zodra de replicatie is geconfigureerd, worden alle vereiste transacties uit binlogs toegepast op het nieuwe cluster.

Dan kiezen we voor de optie om een cluster te maken van de back-up. Dit opent een ander dialoogvenster:
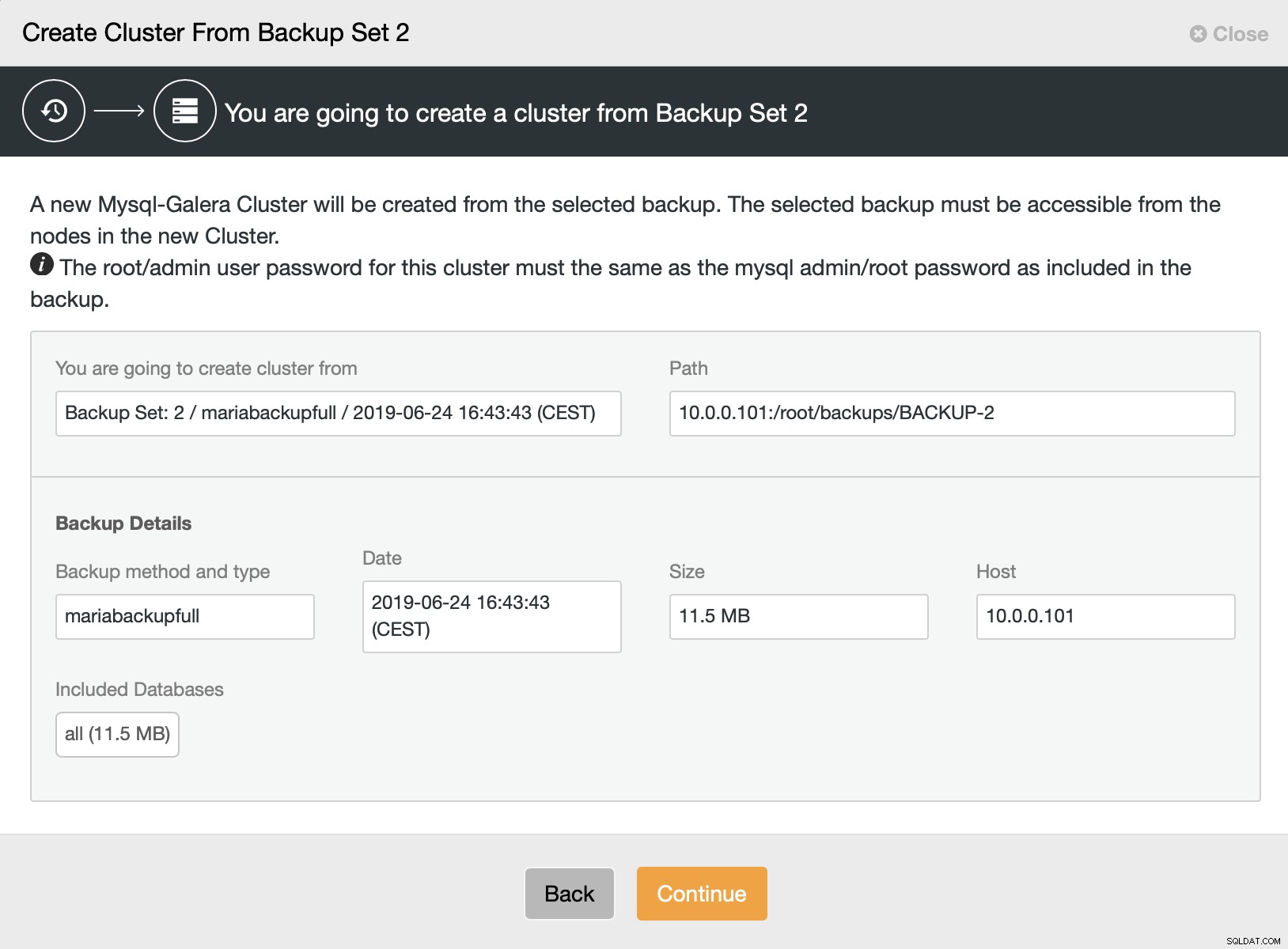
Het is een bevestiging welke back-up zal worden gebruikt, van welke host de back-up is genomen, welke methode is gebruikt om deze te maken en enkele metadata om te controleren of de back-up er goed uitziet.
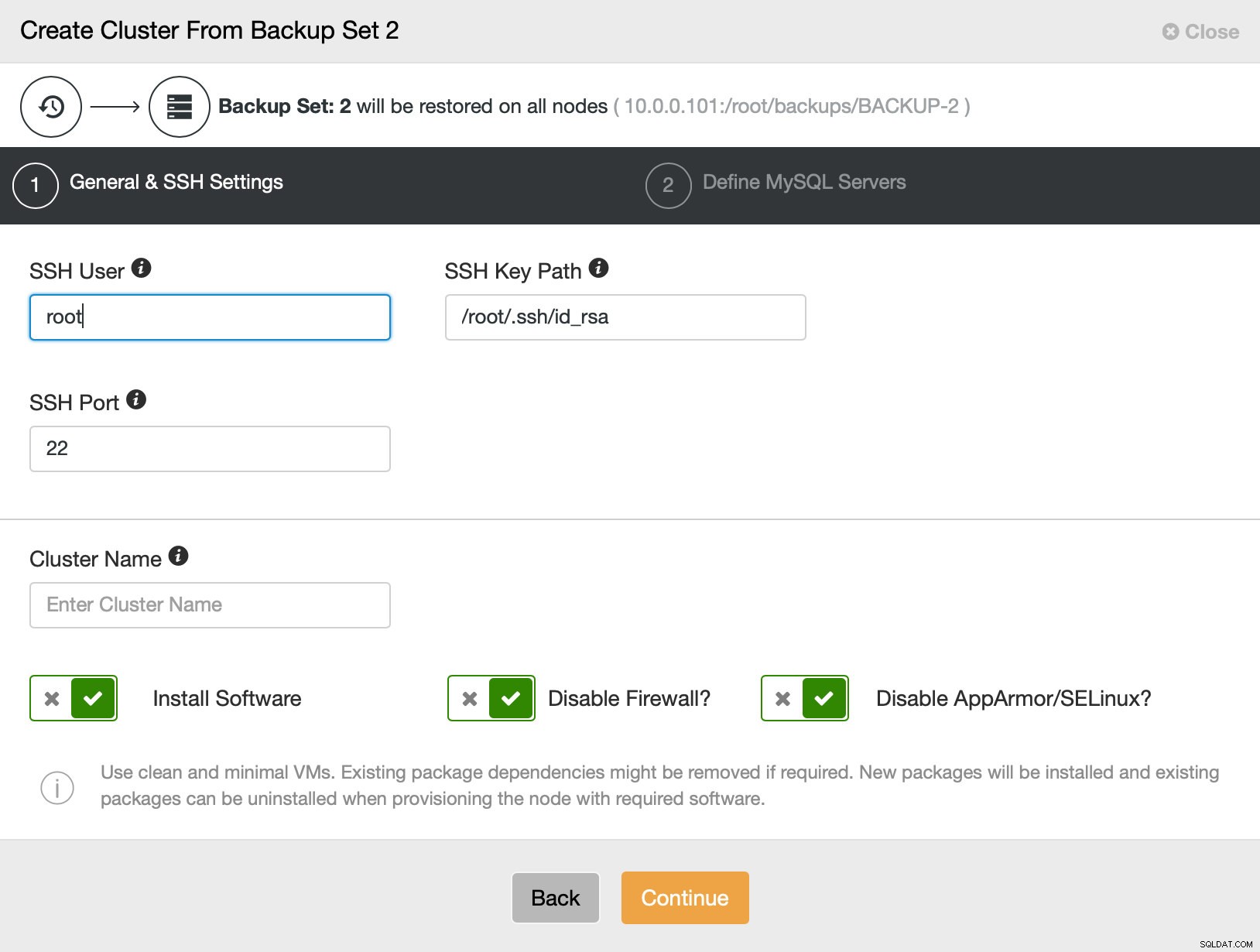
Dan gaan we in principe naar de reguliere implementatiewizard waarin we SSH-connectiviteit moeten definiëren tussen de ClusterControl-host en de knooppunten om het cluster op te implementeren (de vereiste voor ClusterControl) en, in de tweede stap, leverancier, versie, wachtwoord en knooppunten om te implementeren op:
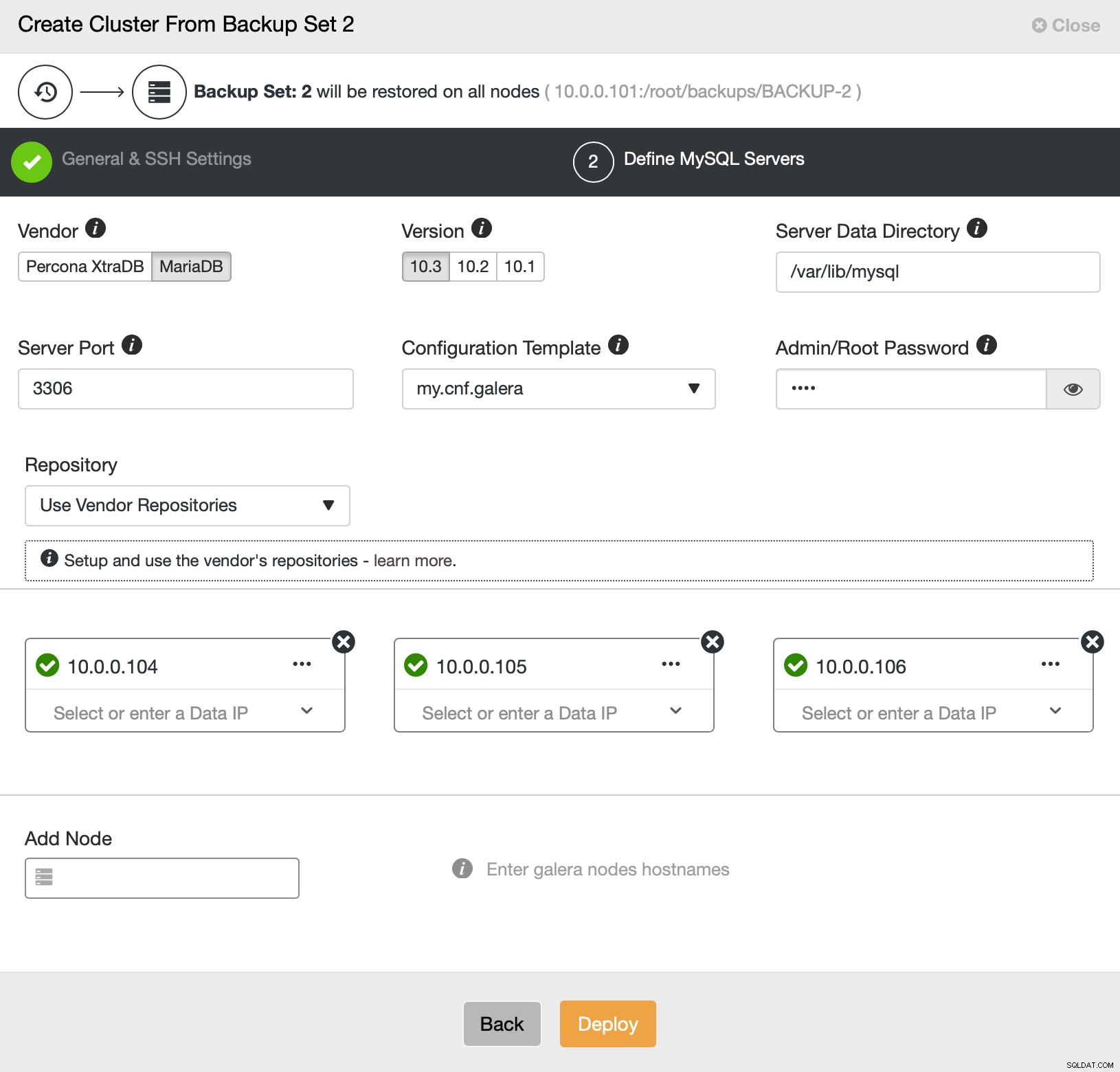
Dat heeft alles te maken met implementatie en provisioning. ClusterControl zal het nieuwe cluster opzetten en het voorzien van de gegevens van het oude.
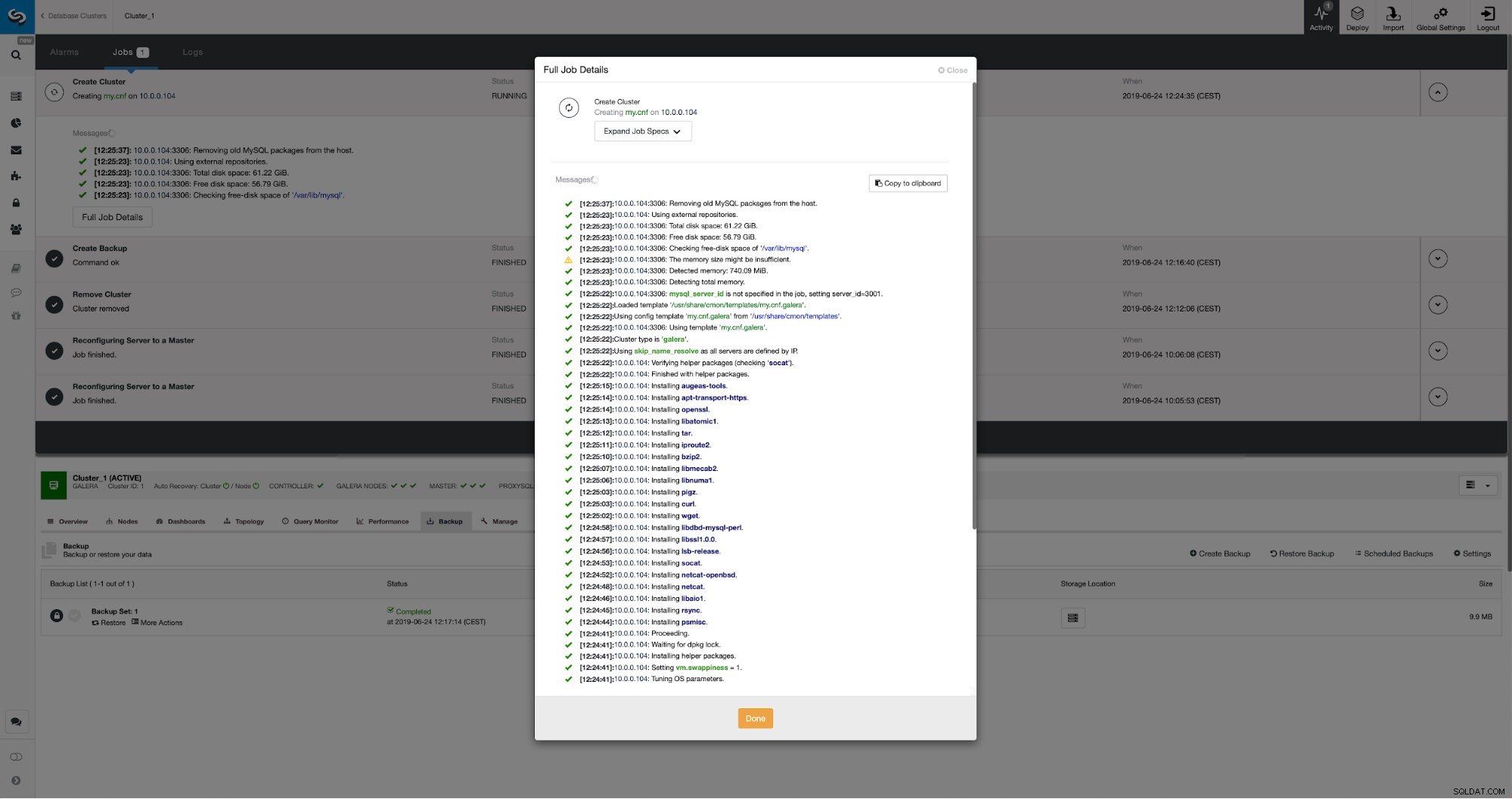
We kunnen de voortgang volgen op het tabblad Activiteiten. Eenmaal voltooid, zal het tweede cluster verschijnen op de clusterlijst in ClusterControl.
Herconfiguratie van het nieuwe cluster met behulp van ClusterControl
Nu moeten we het cluster opnieuw configureren - we zullen binaire logboeken inschakelen. In het handmatige proces moesten we wijzigingen aanbrengen in de wsrep_sst_auth-configuratie en ook configuratie-items in de secties [mysqldump] en [xtrabackup] van de configuratie. Die instellingen zijn te vinden in het bestand secrets-backup.cnf. Deze keer is het niet nodig omdat ClusterControl nieuwe wachtwoorden voor het cluster heeft gegenereerd en de bestanden correct heeft geconfigureerd. Wat echter belangrijk is om in gedachten te houden, is dat als u het wachtwoord van de 'backupuser'@'127.0.0.1'-gebruiker in het oorspronkelijke cluster wijzigt, u ook configuratiewijzigingen moet aanbrengen in het tweede cluster om dat weer te geven als wijzigingen in het eerste cluster zal repliceren naar het tweede cluster.
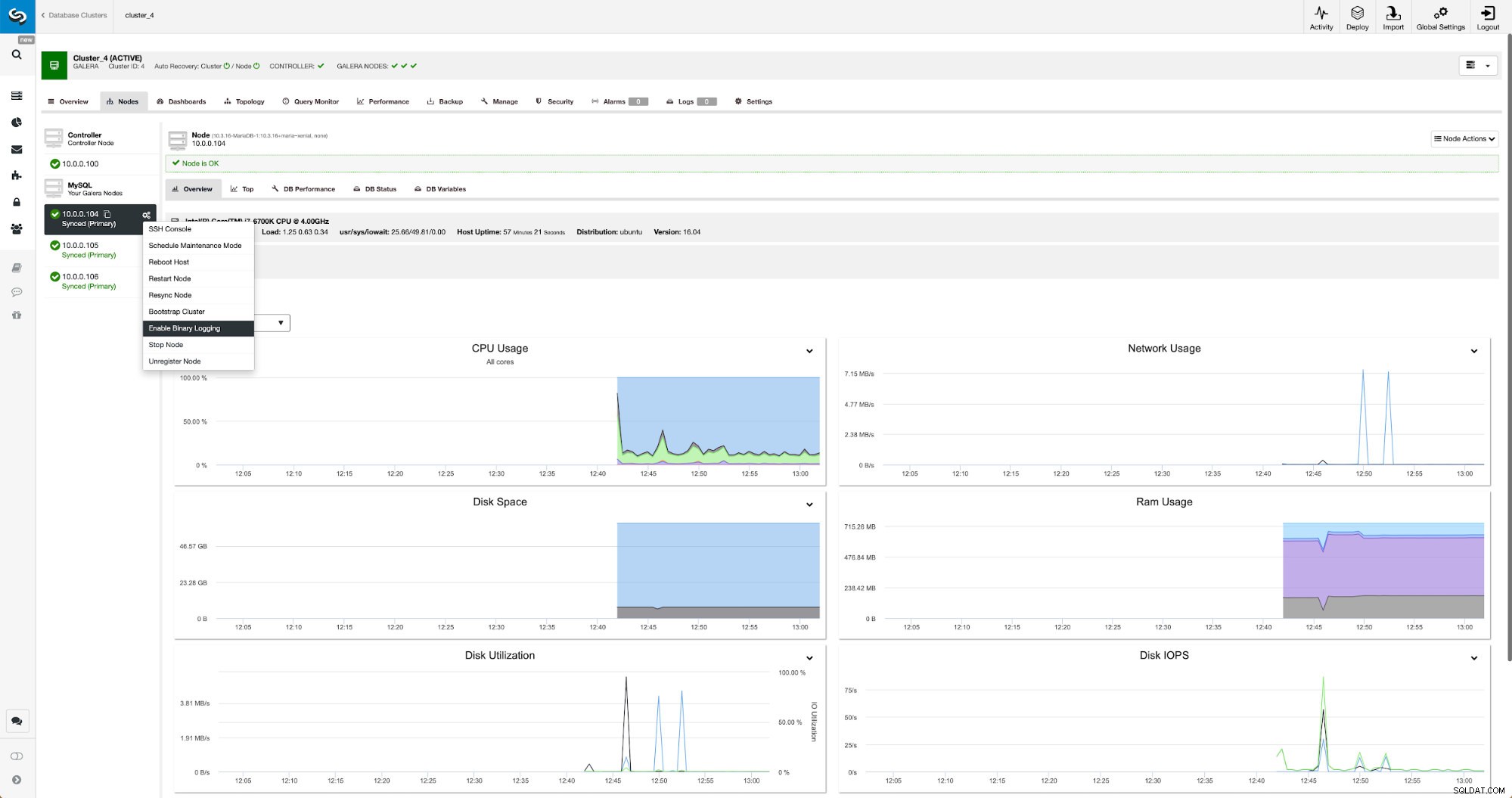
Binaire logboeken kunnen worden ingeschakeld vanuit de sectie Knooppunten. U moet knooppunt voor knooppunt kiezen en de taak "Binaire logboekregistratie inschakelen" uitvoeren. U krijgt een dialoogvenster te zien:
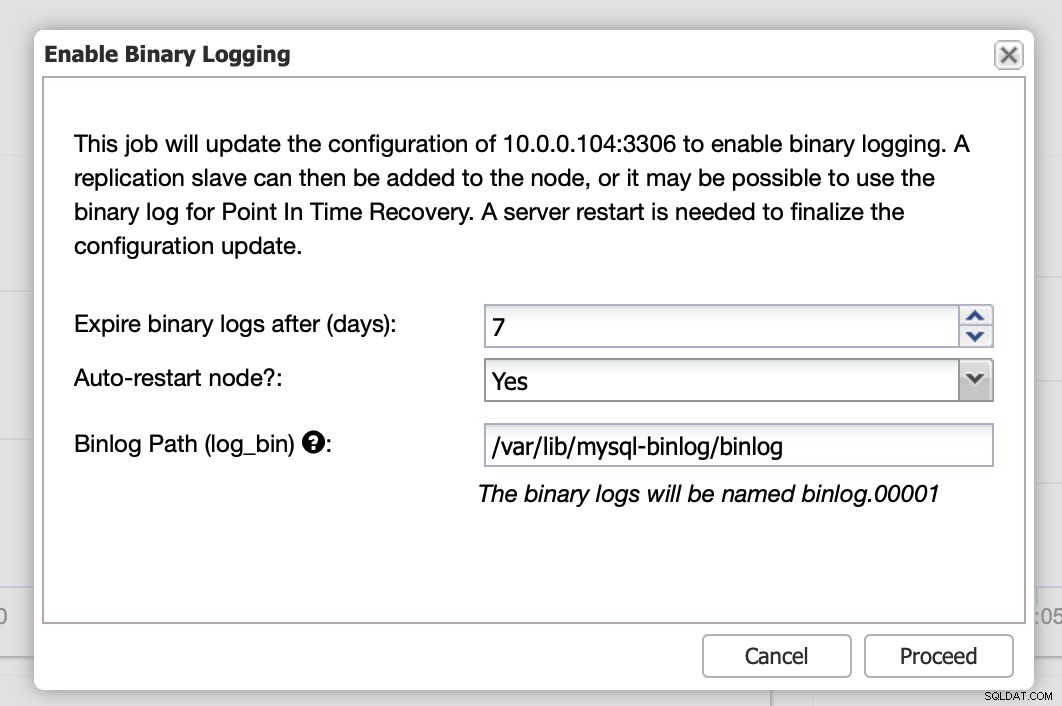
Hier kunt u definiëren hoe lang u de logboeken wilt bewaren, waar ze moeten worden opgeslagen en of ClusterControl het knooppunt opnieuw moet opstarten om wijzigingen toe te passen - binaire logboekconfiguratie is niet dynamisch en MariaDB moet opnieuw worden gestart om die wijzigingen toe te passen.
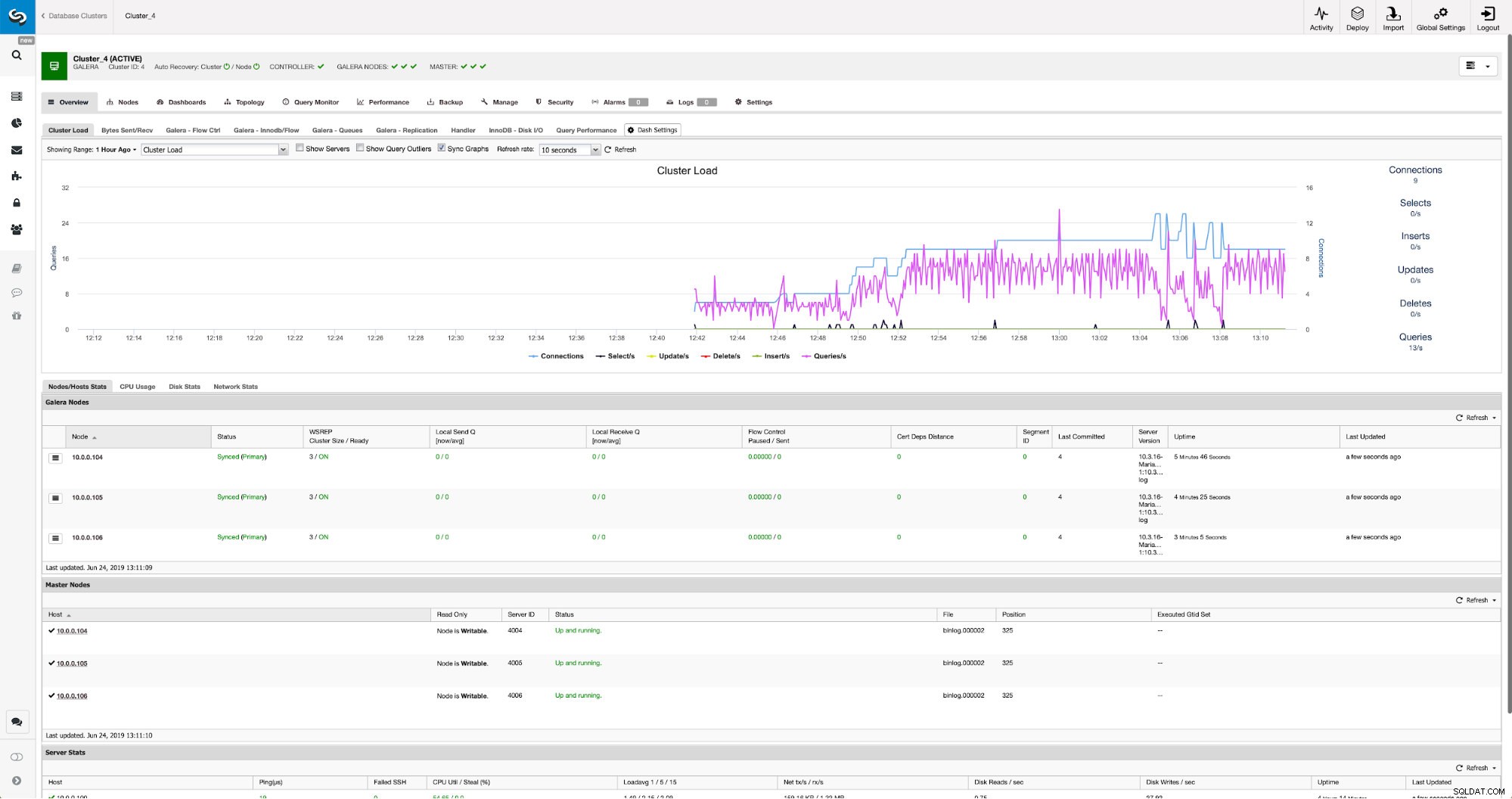
Wanneer de wijzigingen zijn voltooid, ziet u alle knooppunten gemarkeerd als "master", wat betekent dat voor die knooppunten binaire logbestanden zijn ingeschakeld en als master kunnen fungeren.
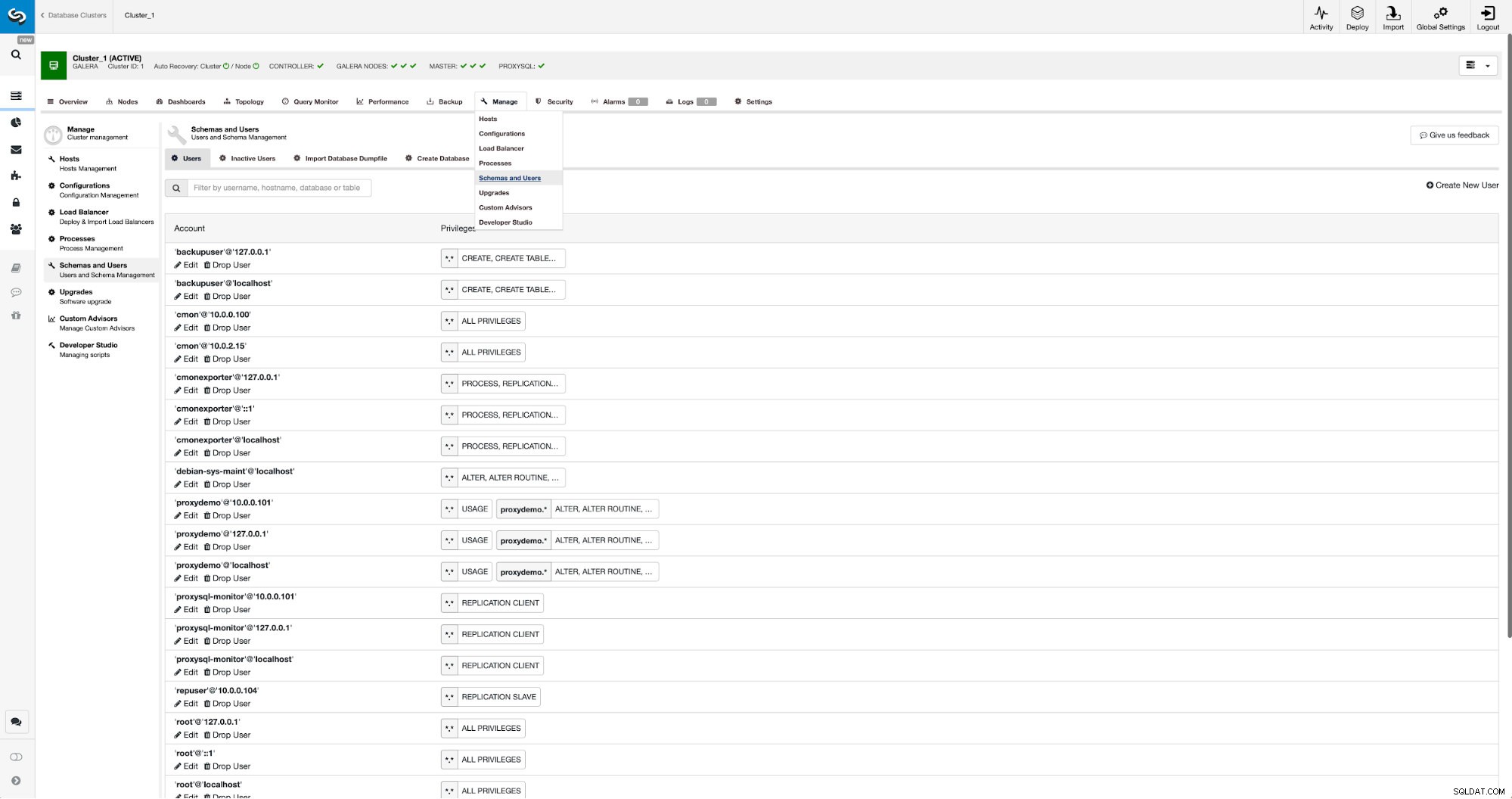
Als we nog geen replicatiegebruiker hebben gemaakt, moeten we dat doen. In het eerste cluster moeten we naar Beheren -> Schema's en gebruikers:
Aan de rechterkant hebben we een optie om een nieuwe gebruiker aan te maken:
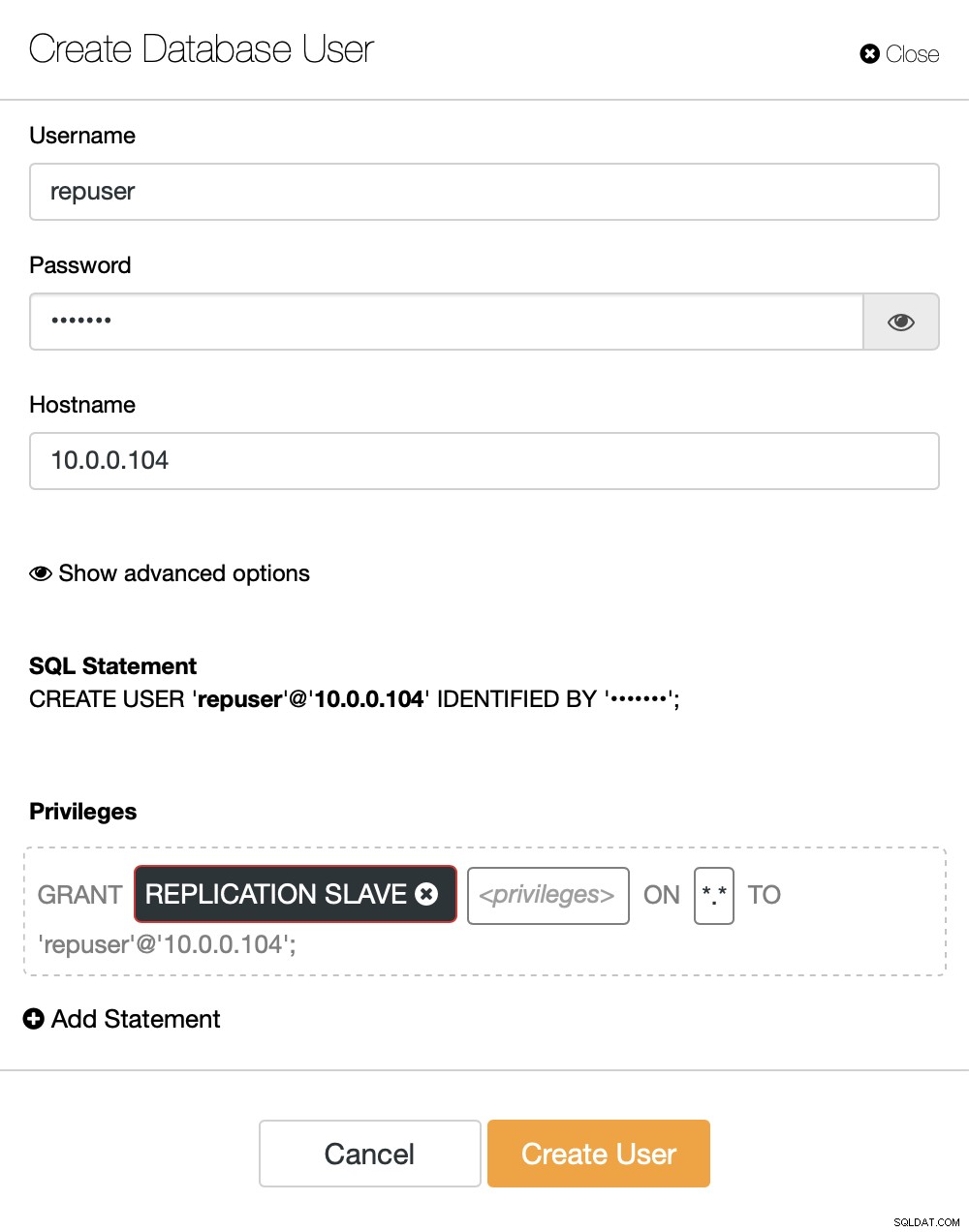
Hiermee is de configuratie voltooid die nodig is om de replicatie in te stellen.
Replicatie tussen clusters instellen met ClusterControl
Zoals we al zeiden, werken we aan het automatiseren van dit onderdeel. Momenteel moet het handmatig worden gedaan. Zoals je je misschien herinnert, hebben we de GITD-positie van onze back-up nodig en voeren we vervolgens een paar opdrachten uit met MySQL CLI. GTID-gegevens zijn beschikbaar in de back-up. ClusterControl maakt een back-up met xbstream/mbstream en comprimeert deze daarna. Onze back-up wordt opgeslagen op de ClusterControl-host waar we geen toegang hebben tot mbstream binary. U kunt proberen het te installeren of u kunt het back-upbestand kopiëren naar de locatie waar zo'n binair bestand beschikbaar is:
scp /root/backups/BACKUP-2/ backup-full-2019-06-24_144329.xbstream.gz 10.0.0.104:/root/mariabackup/Zodra dat is gebeurd, willen we op 10.0.0.104 de inhoud van het xtrabackup_info-bestand controleren:
cd /root/mariabackup
zcat backup-full-2019-06-24_144329.xbstream.gz | mbstream -x
example@sqldat.com:~/mariabackup# cat /root/mariabackup/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000007', position '379', GTID of the last change '9999-1002-846116'Ten slotte configureren we de replicatie en starten we deze:
MariaDB [(none)]> SET GLOBAL gtid_slave_pos ='9999-1002-846116';
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)Dit is het - we hebben zojuist asynchrone replicatie geconfigureerd tussen twee MariaDB Galera-clusters met behulp van ClusterControl. Zoals u had kunnen zien, heeft ClusterControl de meeste stappen kunnen automatiseren die we moesten nemen om deze omgeving in te stellen.