MariaDB-replicatie is een van de meest populaire oplossingen met hoge beschikbaarheid voor MariaDB en wordt veel gebruikt door topbedrijven zoals Booking.com en Google. Het is heel eenvoudig in te stellen, met enkele nadelen voor het lopende onderhoud, zoals software-upgrades, schemawijzigingen, topologiewijzigingen, failover en herstel, die altijd lastig zijn geweest. Niettemin, met de juiste toolset, zou u de topologie gemakkelijk moeten kunnen verwerken. In deze blogpost gaan we kijken naar enkele tips om MariaDB-replicatie efficiënt te monitoren met ClusterControl.
De topologieviewer gebruiken
Een replicatie-setup bestaat uit een aantal rollen. Een knooppunt in een replicatieconfiguratie kan een zijn:
- Master - De primaire schrijver/lezer.
- Back-upmaster - Een alleen-lezen slave met semi-sync-replicatie, uitsluitend voor masterredundantie.
- Tussenliggende master - Repliceren vanaf een master, terwijl andere slaves repliceren vanaf dit knooppunt.
- Binlog-server - Verzamel/bewaar alleen binlogs zonder gegevens te verstrekken.
- Slaaf - Repliceren vanaf een master, en gewoonlijk ingesteld als alleen-lezen.
- Slaaf met meerdere bronnen - Repliceren van meerdere masters.
Elke rol heeft zijn eigen verantwoordelijkheid en beperking en men moet de juiste topologie begrijpen bij het omgaan met de databaseknooppunten. Dit geldt ook voor de toepassing, waar de toepassing op elk moment alleen naar het hoofdknooppunt hoeft te schrijven. Het is dus belangrijk om een overzicht te hebben van welk knooppunt welke rol heeft, zodat we onze database niet verknoeien.
In ClusterControl kan de Topology Viewer u een overzicht geven van de replicatietopologie en zijn status, zoals weergegeven in de volgende schermafbeelding:
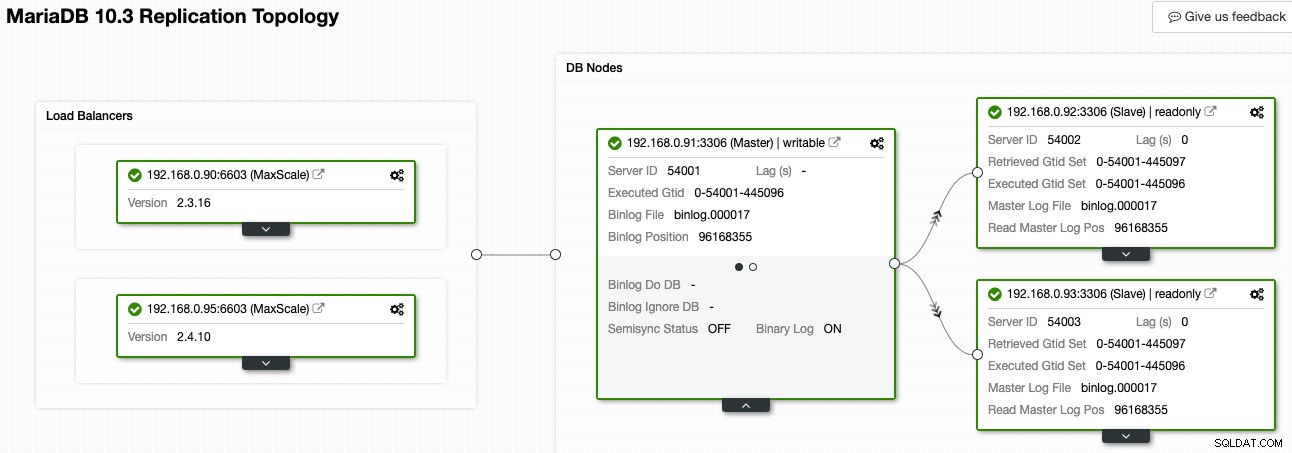
ClusterControl begrijpt MariaDB-replicatie en kan de topologie visualiseren met de juiste replicatiegegevensstroom, zoals weergegeven door de pijlen die naar de slave-knooppunten wijzen. We kunnen gemakkelijk onderscheiden welk knooppunt de master, slaves en load balancers (MaxScale) is in onze replicatie-setup. Het groene vak geeft aan dat alle belangrijke services worden uitgevoerd zoals verwacht met de toegewezen rol.
Bekijk de volgende schermafbeelding waar een aantal van onze knooppunten problemen hebben:
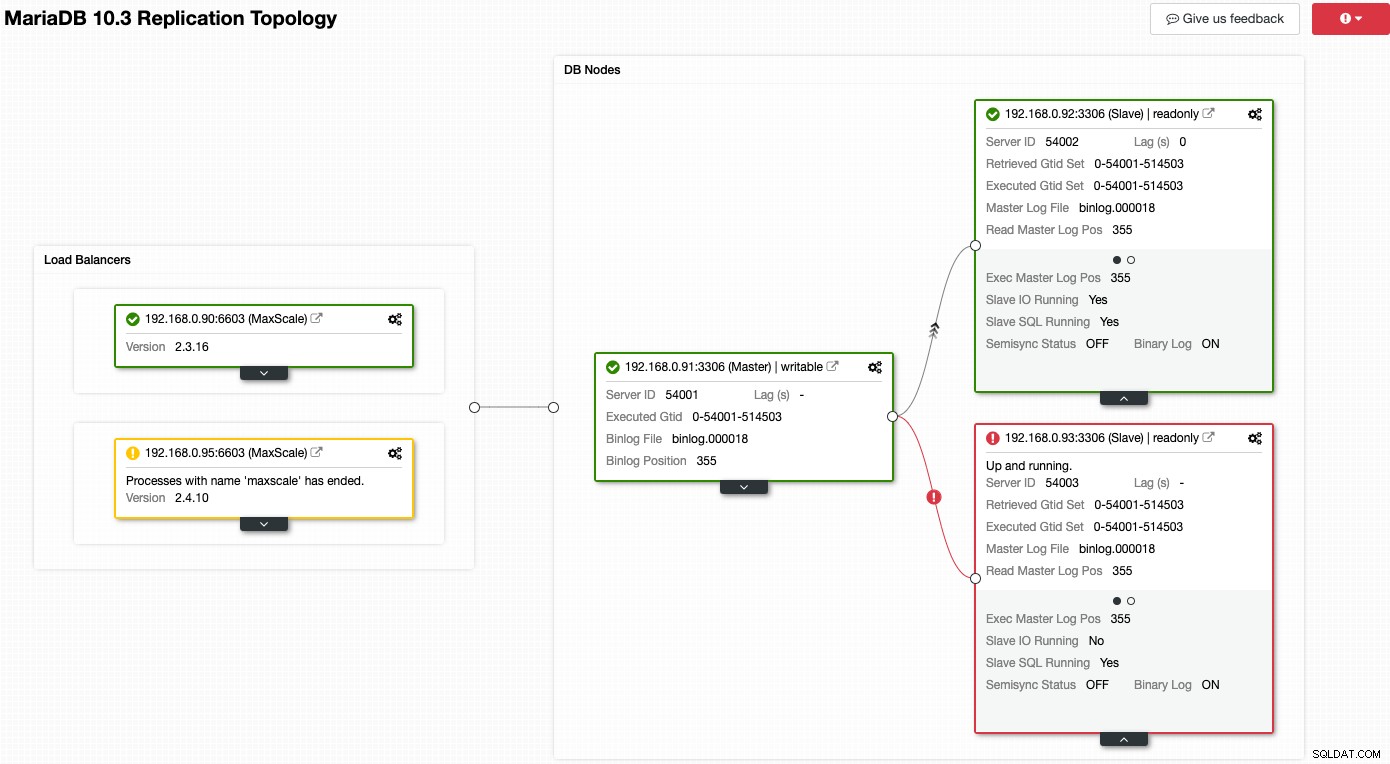
ClusterControl vertelt u direct wat er mis is met de huidige topologie. Een van de slaven (rode doos) toont "Slave IO Running" als Nee, om een verbindingsprobleem aan te geven dat moet worden gerepliceerd vanaf de master. Terwijl het gele vak aangeeft dat onze MaxScale-service niet actief is. We kunnen ook zien dat de MaxScale-versies niet identiek zijn voor beide knooppunten. U kunt ook beheertaken uitvoeren door direct op het tandwielpictogram (rechtsboven op elk vak) te klikken, wat het risico verkleint dat u een verkeerde node oppikt.
Replicatievertraging
Dit is het belangrijkste als u vertrouwt op consistentie van gegevensreplicatie. Replicatievertraging treedt op wanneer de slaven de updates op de master niet kunnen bijhouden. Niet-toegepaste wijzigingen stapelen zich op in de relaislogboeken van de slaven en de versie van de database op de slaven verschilt steeds meer van de master.
In ClusterControl vindt u het histogram van de replicatievertraging onder Overzicht -> Replicatievertraging, waar ClusterControl constant de Seconds_Behind_Master-waarde van de uitvoer "SHOW SLAVE STATUS" samplet:
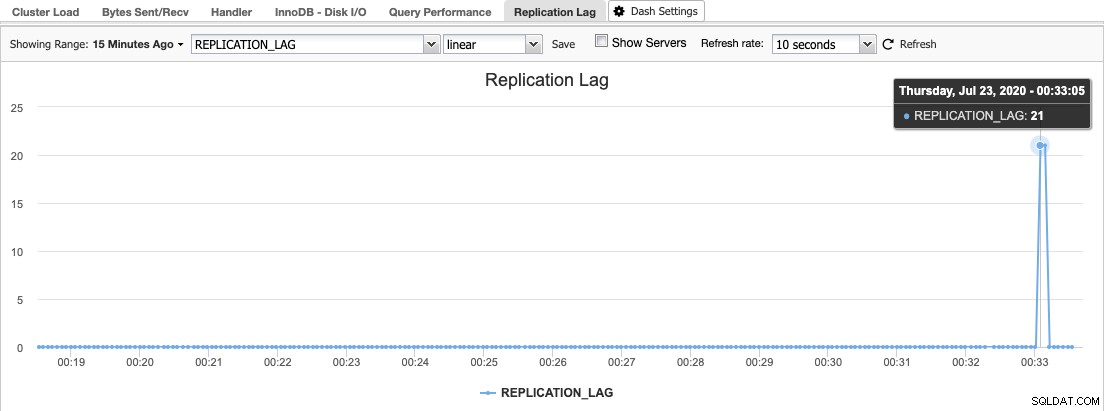
Replicatievertraging treedt op wanneer ofwel de I/O-thread of de SQL-thread niet kan omgaan met de eisen die eraan worden gesteld. Als de I/O-thread lijdt, betekent dit dat de netwerkverbinding tussen de master en zijn slaves traag is of problemen heeft. U kunt overwegen het slave_compressed_protocol in te schakelen om netwerkverkeer te comprimeren of dit aan uw netwerkbeheerder te rapporteren.
Als het de SQL-thread is, is het probleem waarschijnlijk te wijten aan slecht geoptimaliseerde query's die er te lang over doen om de slave toe te passen. Er kunnen langlopende transacties zijn of te veel I/O-activiteit. Het hebben van geen primaire sleutel op de slave-tabellen bij gebruik van het ROW- of MIXED-replicatieformaat is ook een veelvoorkomende oorzaak van vertraging in deze thread. Controleer of de master- en slave-versies van tabellen een primaire sleutel hebben.
Meer tips en trucs worden behandeld in deze blogpost, Hoe replicatievertraging in multi-cloudimplementaties te verminderen.
Binaire/relay loggrootte
Het is belangrijk om de schijfgrootte van de binaire en relay-logboeken te controleren, omdat deze een aanzienlijke hoeveelheid opslagruimte op elk knooppunt in een replicatiecluster kan gebruiken. Gewoonlijk stelt men de systeemvariabele expire_logs_days zo in dat binaire logbestanden automatisch verlopen na een bepaald aantal dagen, bijvoorbeeld expire_logs_days=7. De grootte van binaire logboeken is volledig afhankelijk van het aantal gemaakte binaire gebeurtenissen (inkomende schrijfacties) en we weten niet hoeveel schijfruimte het zou verbruiken voordat de logboeken door MariaDB verlopen zijn. Houd er rekening mee dat als u log_slave_updates op de slaves inschakelt, de grootte van de logboeken bijna verdubbeld zal worden vanwege het bestaan van zowel binaire als relaislogboeken op dezelfde server.
Voor ClusterControl kunnen we een drempelwaarde voor het gebruik van schijfruimte instellen onder ClusterControl -> Instellingen -> Drempels om een waarschuwing en kritieke meldingen te krijgen, zoals hieronder:
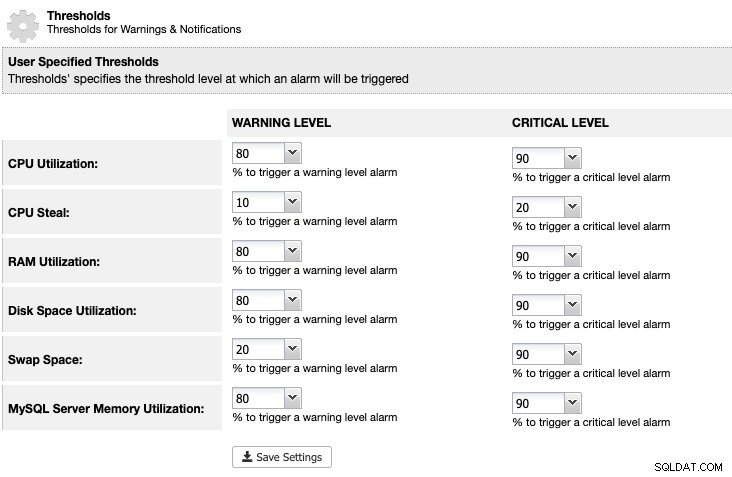
ClusterControl bewaakt alle schijfruimte met betrekking tot MariaDB-services, zoals de locatie van MariaDB-gegevens directory, de directory met binaire logboeken en ook de rootpartitie. Als u de drempel hebt bereikt, kunt u overwegen de binaire logboeken handmatig op te schonen met de opdracht PURGE BINARY LOGS, zoals uitgelegd en besproken in dit artikel.
Bewakingsdashboards inschakelen
ClusterControl biedt twee bewakingsopties om de databaseknooppunten te samplen:agentloos of agentgebaseerd. De standaard is agentless waarbij bemonstering plaatsvindt via SSH in een pull-only-mechanisme. Voor monitoring op basis van agenten moet een Prometheus-server worden uitgevoerd en moeten alle bewaakte knooppunten worden geconfigureerd met ten minste drie exportprogramma's:
- Procesexporter (poort 9011)
- Knooppunt-/systeemstatistieken-exporter (poort 9100)
- MySQL/MariaDB-exporteur (poort 9104)
Om het agent-based monitoring dashboard in te schakelen, moet men naar ClusterControl -> Dashboards -> Agent Based Monitoring inschakelen. Eenmaal ingeschakeld, ziet u een set dashboards die zijn geconfigureerd voor onze MariaDB-replicatie, wat ons een veel beter inzicht geeft in onze replicatie-instellingen. De volgende schermafbeelding laat zien wat u zou zien voor het hoofdknooppunt:
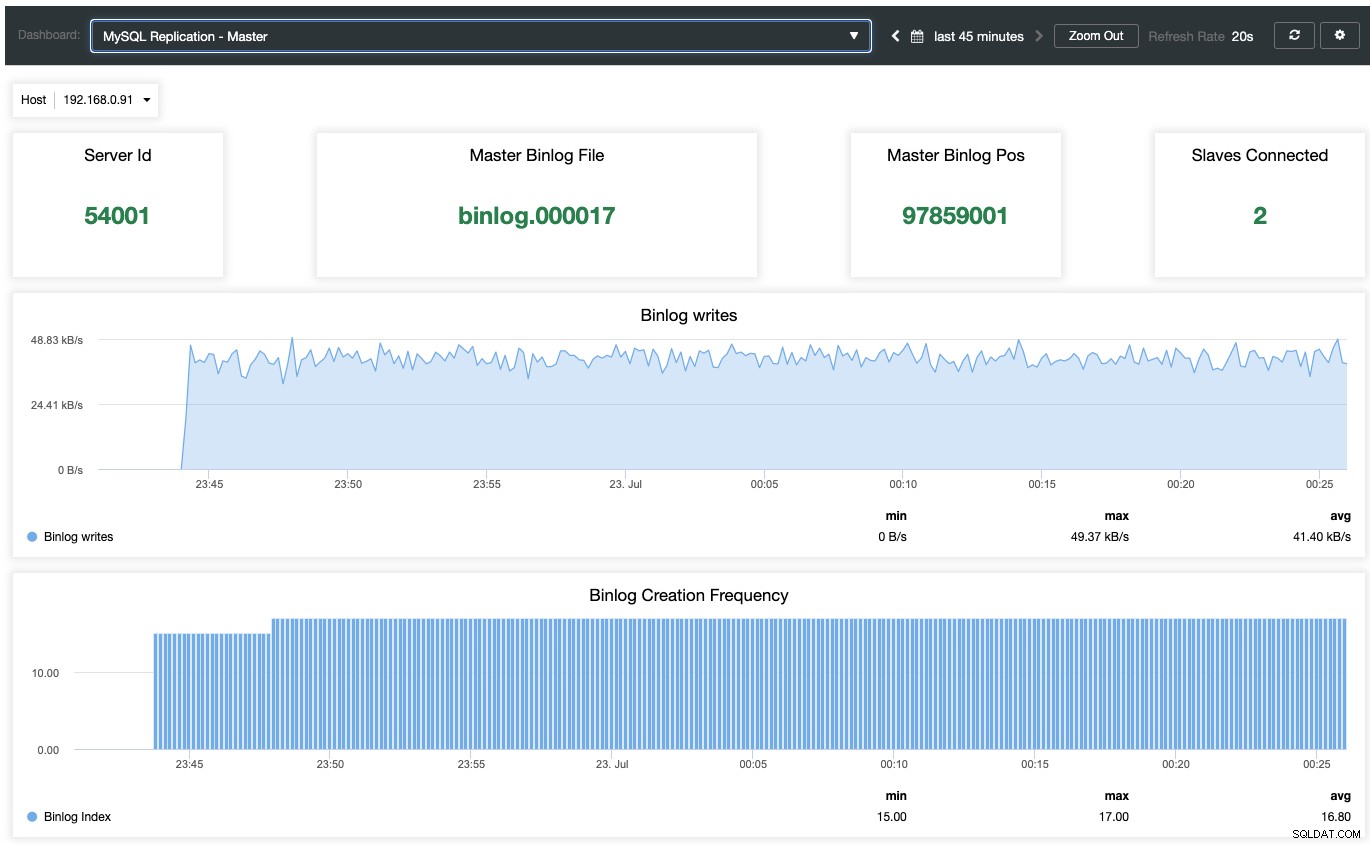
Naast MariaDB standaard monitoringdashboards zoals algemeen, caches en InnoDB-statistieken, zal worden gepresenteerd met een replicatiedashboard. Voor het masterknooppunt kunnen we veel nuttige informatie krijgen over de status van de master, de schrijfdoorvoer en de aanmaakfrequentie van binlog.
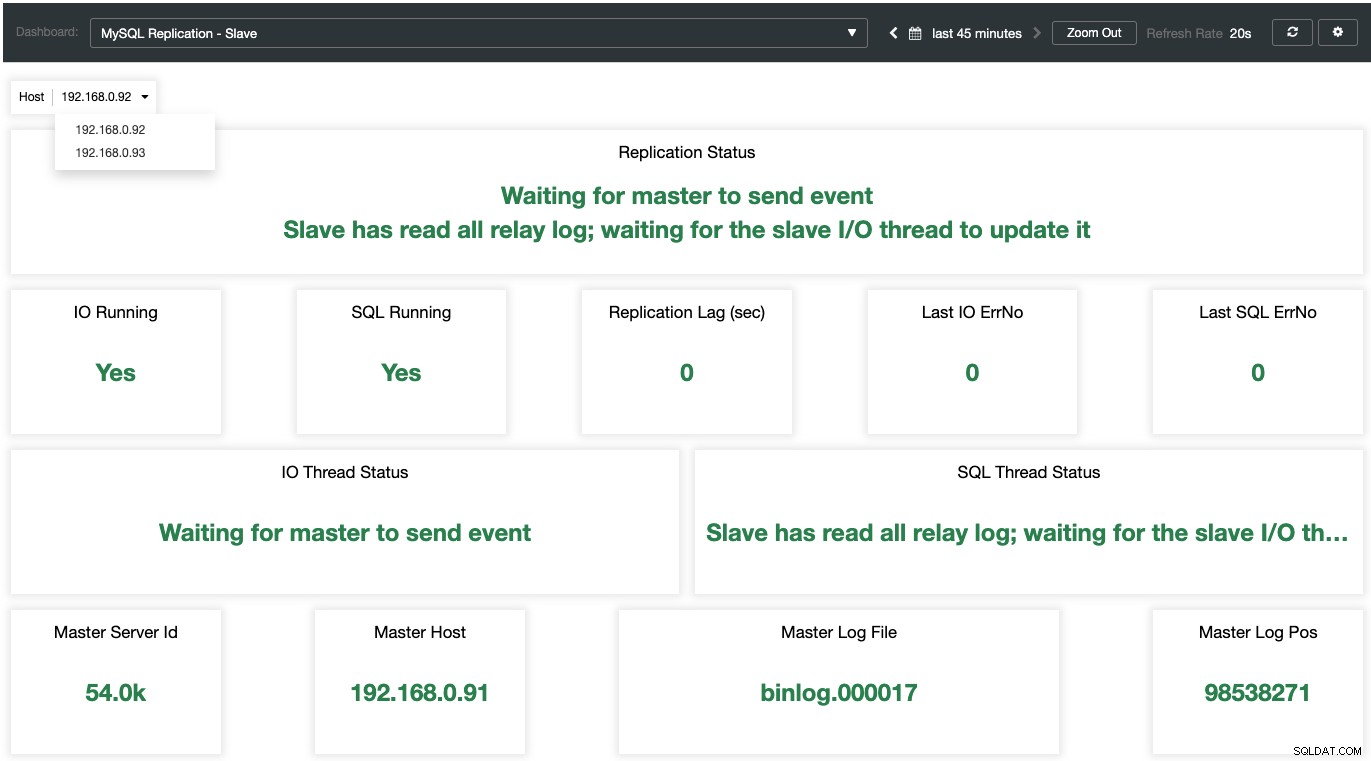
Terwijl voor de slaven alle belangrijke toestanden worden gesampled en samengevat als de volgende schermafbeelding. als alles groen is, ben je in goede handen:
Het MariaDB-foutlogboek begrijpen
MariaDB legt de belangrijke gebeurtenissen vast in het foutenlogboek, wat handig is om te begrijpen wat er met de server aan de hand was, vooral voor, tijdens en na een topologiewijziging. ClusterControl biedt een gecentraliseerde weergave van foutenlogboeken onder ClusterControl -> Logboeken -> Systeemlogboeken door ze uit elk databaseknooppunt te halen. U klikt op "Refresh Logs" om een taak te activeren om de nieuwste logs van de server te halen.
Verzamelde bestanden worden weergegeven in een navigatieboomstructuur en een tekstgebied met syntaxisaccentuering voor een betere leesbaarheid:
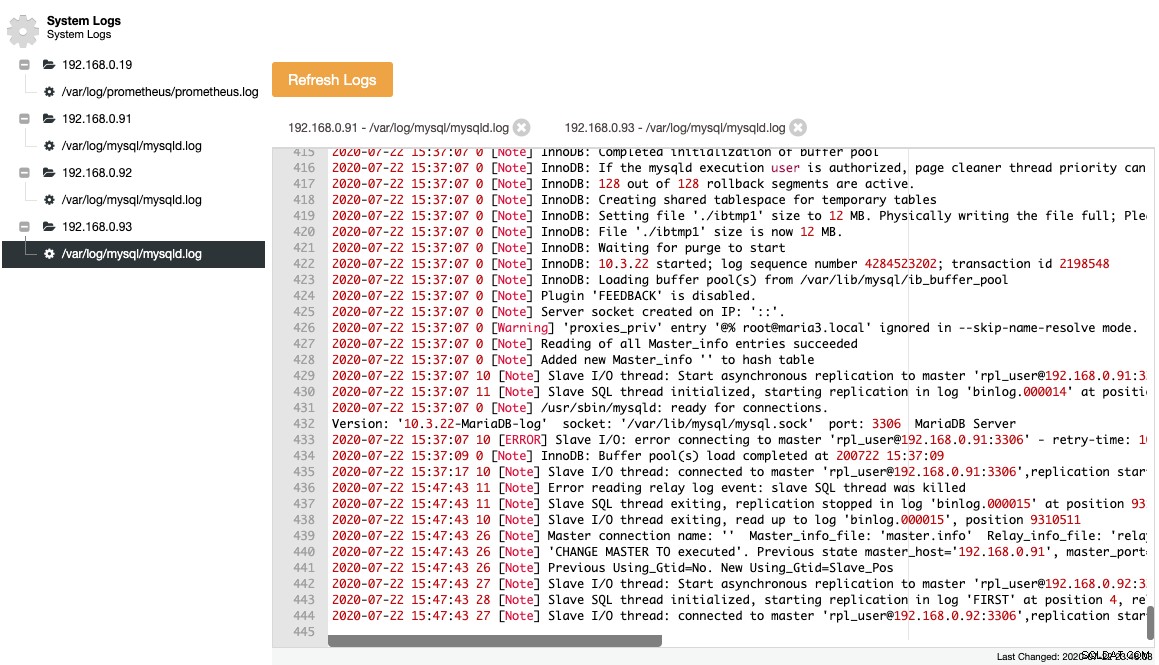
Uit de bovenstaande schermafbeelding kunnen we de volgorde van gebeurtenissen begrijpen en wat er met dit knooppunt is gebeurd tijdens een topologiewijzigingsgebeurtenis. Van de laatste 12 regels van het bovenstaande foutenlogboek had de slave een fout toen hij verbinding maakte met de master en het laatste binaire logbestand en de laatste positie werden in het log vastgelegd voordat het stopte. Vervolgens werd een nieuwere CHANGE MASTER-opdracht uitgevoerd met GTID-informatie, zoals weergegeven in de regel "Previous Using_Gtid=No. New Using_Gtid=Slave_Pos" en vervolgens wordt de replicatie hervat zoals we wilden.
MariaDB-waarschuwing en -meldingen
Monitoring is onvolledig zonder waarschuwingen en meldingen. Alle gebeurtenissen en alarmen die door ClusterControl worden gegenereerd, kunnen naar de e-mail of andere ondersteunde tools van derden worden verzonden. Voor e-mailmeldingen kan men configureren of het type gebeurtenissen onmiddellijk wordt afgeleverd, genegeerd of verwerkt (een dagelijks samengevat rapport):

Voor alle kritieke ernstgebeurtenissen wordt aanbevolen om alles op "Bezorgen" in te stellen, zodat u de meldingen zo snel mogelijk ontvangt. Stel "Digest" in op waarschuwingsgebeurtenissen, zodat u goed op de hoogte bent van de clusterstatus en -status.
U kunt uw favoriete communicatie- en berichtentools integreren met ClusterControl door de functie Meldingenbeheer te gebruiken onder ClusterControl -> Integraties -> Meldingen van derden. ClusterControl kan alarmen en gebeurtenissen naar PagerDuty, VictorOps, OpsGenie, Slack, Telegram, ServiceNow of andere door gebruikers geregistreerde webhooks sturen.
De volgende schermafbeelding laat zien dat alle kritieke gebeurtenissen naar het geconfigureerde telegramkanaal voor ons MariaDB 10.3-replicatiecluster worden gepusht:

ClusterControl ondersteunt ook chatbotintegratie, waar u rechtstreeks vanuit uw berichtentool kunt communiceren met de controllerservice via de s9s-client, zoals weergegeven in deze blogpost, Automatiseer uw database met CCBot:ClusterControl Hubot-integratie.
Conclusie
ClusterControl biedt een complete set proactieve monitoringtools voor uw databaseclusters. Gebruik ClusterControl om uw MariaDB-replicatie-instellingen te bewaken, omdat de meeste monitoringfuncties gratis beschikbaar zijn in de community-editie. Mis die niet!