In de vorige blogpost hebben we de basisprincipes van schalen behandeld - wat het is, wat de typen zijn, wat een must-have is als we willen schalen. Deze blogpost richt zich op de uitdagingen en de manieren waarop we kunnen uitbreiden.
Uitdaging van uitschalen
Het schalen van databases is om meerdere redenen niet de gemakkelijkste taak. Laten we ons een beetje concentreren op de uitdagingen die verband houden met het opschalen van uw database-infrastructuur.
Statige service
We kunnen twee verschillende soorten services onderscheiden:stateless en stateful. Stateless services zijn degenen die niet afhankelijk zijn van enige vorm van bestaande gegevens. Je kunt gewoon doorgaan, zo'n service starten en het zal gewoon werken. U hoeft zich geen zorgen te maken over de staat van de gegevens of de service. Als het goed is, werkt het naar behoren en kunt u het verkeer gemakkelijk over meerdere service-instanties verdelen door gewoon meer klonen of kopieën van bestaande VM's, containers of iets dergelijks toe te voegen. Een voorbeeld van een dergelijke service kan een webtoepassing zijn - geïmplementeerd vanuit de repo, met een correct geconfigureerde webserver, zal een dergelijke service gewoon starten en correct werken.
Het probleem met databases is dat de database alles behalve stateloos is. Gegevens moeten in de database worden ingevoegd, ze moeten worden verwerkt en bewaard. De afbeelding van de database is niets meer dan slechts een paar pakketten die over de OS-image zijn geïnstalleerd en zonder gegevens en de juiste configuratie is het nogal nutteloos. Dit draagt bij aan de complexiteit van het schalen van de database. Voor stateless services is het gewoon om ze te implementeren en enkele loadbalancers te configureren om nieuwe instanties in de werkbelasting op te nemen. Voor databases die de database implementeren, is de instantie slechts het startpunt. Verderop is gegevensbeheer - u moet de gegevens van uw bestaande database-instantie overbrengen naar de nieuwe. Dit kan een aanzienlijk deel zijn van het probleem en de tijd die nodig is voor de nieuwe instanties om het verkeer te verwerken. Pas nadat de gegevens zijn overgedragen, kunnen we de nieuwe knooppunten instellen om deel uit te maken van de bestaande replicatietopologie - de gegevens moeten in realtime worden bijgewerkt op basis van het verkeer dat andere knooppunten bereikt.
Tijd nodig om op te schalen
Het feit dat databases stateful services zijn, is een directe reden voor de tweede uitdaging waarmee we worden geconfronteerd wanneer we de database-infrastructuur willen uitbreiden. Staatloze services - u start ze gewoon en dat is alles. Het is een vrij snel proces. Voor databases moet u de gegevens overdragen. Hoe lang het duurt, hangt van meerdere factoren af. Hoe groot is de dataset? Hoe snel is de opslag? Hoe snel is het netwerk? Wat zijn de andere stappen die nodig zijn om het nieuwe knoop punt te voorzien van de nieuwe gegevens? Worden gegevens gecomprimeerd/gedecomprimeerd of versleuteld/ontsleuteld in het proces? In de echte wereld kan het enkele minuten tot meerdere uren duren om de gegevens op een nieuw knooppunt in te richten. Dit beperkt de gevallen waarin u uw databaseomgeving kunt opschalen aanzienlijk. Plotselinge, tijdelijke pieken in de belasting? Niet echt, ze zijn misschien al lang verdwenen voordat u extra databaseknooppunten kunt starten. Plotselinge en constante belastingverhoging? Ja, het is mogelijk om hiermee om te gaan door meer knooppunten toe te voegen, maar het kan zelfs uren duren om ze op te halen en ze het verkeer van bestaande databaseknooppunten te laten overnemen.
Extra belasting veroorzaakt door het opschalingsproces
Het is erg belangrijk om in gedachten te houden dat de tijd die nodig is om op te schalen slechts één kant van het probleem is. De andere kant is de belasting die wordt veroorzaakt door het schaalproces. Zoals we eerder vermeldden, moet je de hele dataset overzetten naar nieuw toegevoegde nodes. Dit is niet iets dat u kunt negeren, het kan tenslotte een proces van uren duren om de gegevens van de schijf te lezen, over het netwerk te verzenden en op een nieuwe locatie op te slaan. Als de donor, het knooppunt waarvan u de gegevens leest, overbelast is, moet u zich afvragen hoe het zich zal gedragen als het wordt gedwongen om extra zware I/O-activiteiten uit te voeren? Kan uw cluster een extra werklast op zich nemen als het al onder zware druk staat en dun verspreid is? Het antwoord is misschien niet gemakkelijk te krijgen, omdat de belasting van de knooppunten in verschillende vormen kan komen. CPU-gebonden belasting is het beste scenario, aangezien de I/O-activiteit laag moet zijn en extra schijfbewerkingen beheersbaar zijn. I/O-gebonden belasting daarentegen kan de gegevensoverdracht aanzienlijk vertragen, wat ernstige gevolgen heeft voor het schaalbaarheidsvermogen van het cluster.
Schrijfschaal
Het uitschaalproces dat we eerder noemden, is vrijwel beperkt tot het schalen van leesbewerkingen. Het is van het grootste belang om te begrijpen dat het schrijven van schalen een heel ander verhaal is. U kunt uitlezingen schalen door simpelweg meer knooppunten toe te voegen en de uitlezingen over meer backend-knooppunten te verspreiden. Schrijven is niet zo eenvoudig te schalen. Om te beginnen kun je schrijfbewerkingen niet zomaar uitschalen. Elk knooppunt dat de hele dataset bevat, moet natuurlijk alle schrijfbewerkingen die ergens in het cluster worden uitgevoerd afhandelen, omdat het alleen door alle wijzigingen aan de dataset toe te passen consistentie kan behouden. Dus als je erover nadenkt, ongeacht hoe je je cluster ontwerpt en welke technologie je ook gebruikt, elk lid van het cluster moet elke schrijfactie uitvoeren. Of het nu een replica is, waarbij alle schrijfbewerkingen van de master of het knooppunt worden gerepliceerd in een multi-mastercluster zoals Galera of InnoDB Cluster, waarbij alle wijzigingen in de dataset worden uitgevoerd op alle andere knooppunten van het cluster, het resultaat is hetzelfde. Schrijfbewerkingen worden niet uitgeschaald door simpelweg meer knooppunten aan het cluster toe te voegen.
Hoe kunnen we de database uitschalen?
We weten dus met wat voor uitdagingen we te maken hebben. Wat zijn de opties die we hebben? Hoe kunnen we de database uitschalen?
Door replica's toe te voegen
Eerst en vooral zullen we uitschalen door simpelweg meer knooppunten toe te voegen. Natuurlijk, het zal tijd kosten en zeker, het is niet een proces waarvan je kunt verwachten dat het onmiddellijk zal plaatsvinden. Natuurlijk kun je dergelijke schrijfopdrachten niet uitschalen. Aan de andere kant is het meest typische probleem waarmee u te maken krijgt de CPU-belasting die wordt veroorzaakt door SELECT-query's en, zoals we hebben besproken, kunnen reads eenvoudig worden geschaald door gewoon meer knooppunten aan het cluster toe te voegen. Meer knooppunten om van te lezen, betekent dat de belasting op elk van hen wordt verminderd. Wanneer je aan het begin staat van je reis naar de levenscyclus van je applicatie, ga er dan maar vanuit dat dit is waar je mee te maken krijgt. CPU-belasting, geen efficiënte query's. Het is zeer onwaarschijnlijk dat u schrijfbewerkingen moet uitschalen tot ver in de levenscyclus, wanneer uw toepassing al volwassen is en u te maken krijgt met het aantal klanten.
Door te sharden
Het toevoegen van nodes lost het schrijfprobleem niet op, dat hebben we vastgesteld. Wat u in plaats daarvan moet doen, is sharding - het splitsen van de gegevensset over het cluster. In dit geval bevat elk knooppunt slechts een deel van de gegevens, niet alles. Hierdoor kunnen we eindelijk beginnen met het schalen van schrijfacties. Laten we zeggen dat we vier knooppunten hebben, die elk de helft van de dataset bevatten.
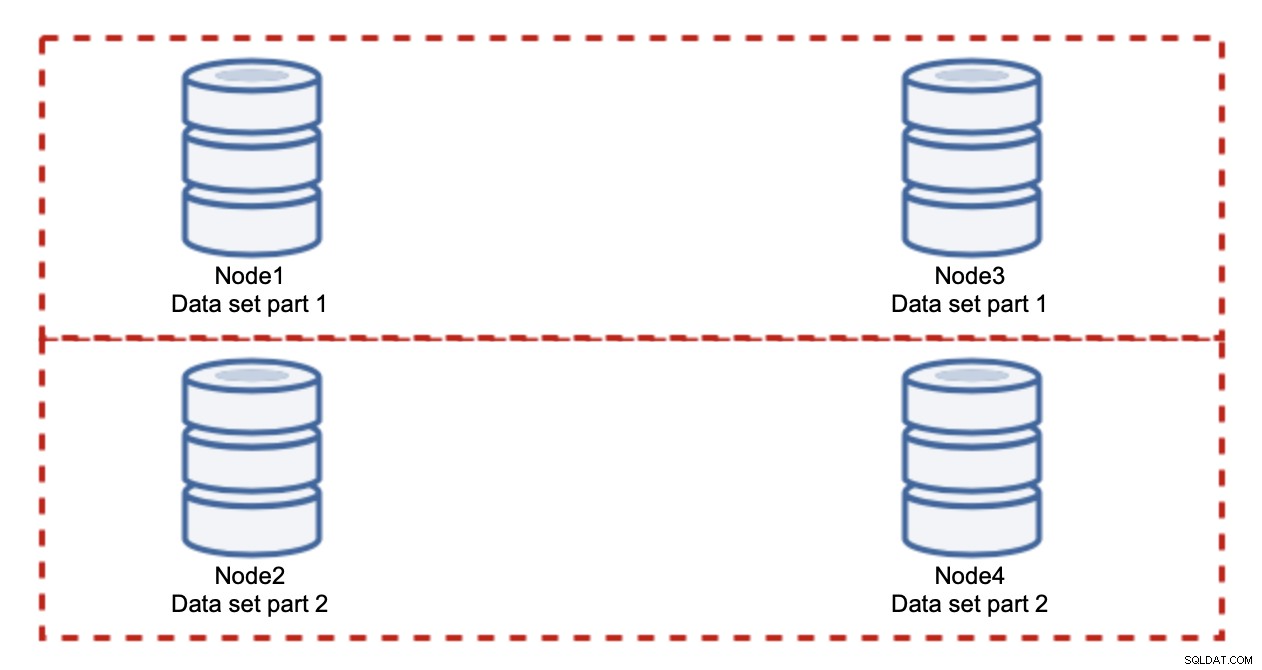
Zoals je kunt zien, is het idee eenvoudig. Als het schrijven gerelateerd is aan deel 1 van de dataset, wordt het uitgevoerd op knooppunt1 en knooppunt3. Als het gerelateerd is aan deel 2 van de dataset, wordt het uitgevoerd op node2 en node4. U kunt de databaseknooppunten zien als schijven in een RAID. Hier hebben we een voorbeeld van RAID10, twee paar spiegels, voor redundantie. In de echte implementatie kan het complexer zijn, u kunt meer dan één replica van de gegevens hebben voor een betere hoge beschikbaarheid. De essentie is dat, uitgaande van een volkomen eerlijke splitsing van de gegevens, de helft van de schrijfacties knooppunt1 en knooppunt3 raakt en de andere helft knooppunten 2 en 4. Als u de belasting nog verder wilt splitsen, kunt u het derde paar knooppunten introduceren:
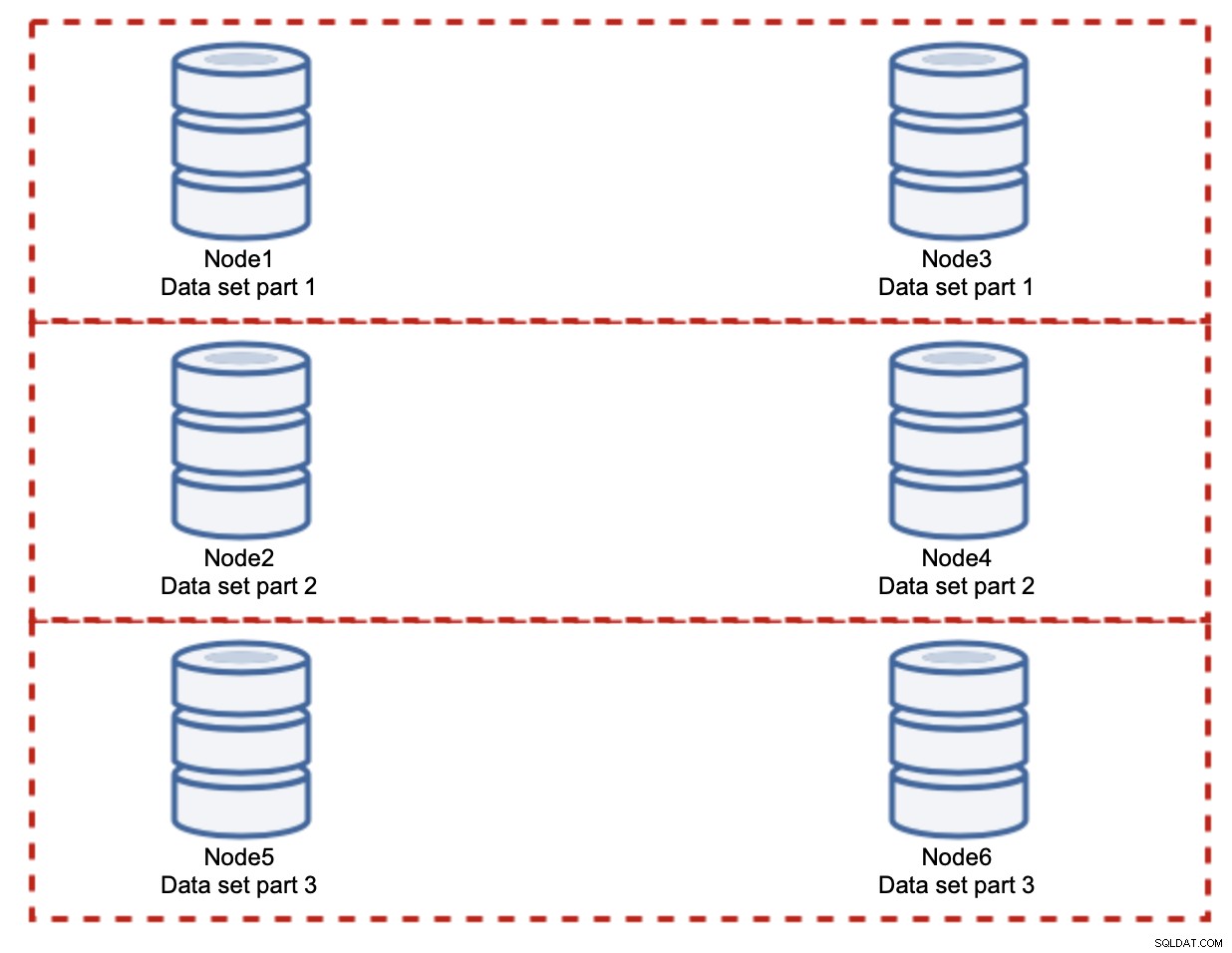
In dit geval, nogmaals, uitgaande van een volkomen eerlijke splitsing, zal elk paar verantwoordelijk zijn voor 33% van alle schrijfacties naar het cluster.
Dit vat het idee van sharding ongeveer samen. In ons voorbeeld kunnen we, door meer shards toe te voegen, de schrijfactiviteit op de databaseknooppunten verminderen tot 33% van de oorspronkelijke I/O-belasting. Zoals je je misschien kunt voorstellen, gaat dit niet zonder nadelen.
Hoe kan ik vinden op welke shard mijn gegevens zich bevinden? Details vallen buiten het bereik van deze aanroep, maar kortom, u kunt een soort functie op een bepaalde kolom implementeren (modulo of hash op de 'id'-kolom) of u kunt een afzonderlijke metadatabase bouwen waarin u de details opslaat van hoe de gegevens worden gedistribueerd.
We hopen dat je deze korte blogserie informatief vond en dat je een beter begrip hebt gekregen van de verschillende uitdagingen waarmee we worden geconfronteerd wanneer we de databaseomgeving willen uitbreiden. Als je opmerkingen of suggesties hebt over dit onderwerp, aarzel dan niet om onder dit bericht te reageren en je ervaring te delen