Het concept van goed of slecht ontwerp is relatief. Tegelijkertijd zijn er enkele programmeerstandaarden die in de meeste gevallen de effectiviteit, onderhoudbaarheid en testbaarheid garanderen. In objectgeoriënteerde talen is dit bijvoorbeeld het gebruik van inkapseling, overerving en polymorfisme. Er is een set design patterns die in een aantal gevallen afhankelijk van de situatie een positief of negatief effect hebben op het applicatie-ontwerp. Aan de andere kant zijn er tegenstellingen, die soms leiden tot het probleemontwerp.
Dit ontwerp heeft meestal de volgende indicatoren (een of meerdere tegelijk):
- Rigiditeit (het is moeilijk om de code aan te passen, omdat een simpele wijziging op veel plaatsen van invloed is);
- Immobiliteit (het is ingewikkeld om de code op te splitsen in modules die in andere programma's kunnen worden gebruikt);
- Viscositeit (het is vrij moeilijk om de code te ontwikkelen of te testen);
- Onnodige complexiteit (er is een ongebruikte functionaliteit in de code);
- Onnodige herhaling (kopiëren/plakken);
- Slechte leesbaarheid (het is moeilijk om te begrijpen waarvoor de code is ontworpen en om deze te onderhouden);
- Kwetsbaarheid (het is gemakkelijk om functionaliteit te breken, zelfs met kleine wijzigingen).
U moet deze kenmerken kunnen begrijpen en onderscheiden om een probleemontwerp te vermijden of mogelijke gevolgen van het gebruik ervan te voorspellen. Deze indicatoren worden beschreven in het boek «Agile Principles, Patterns, And Practices in C#» van Robert Martin. Er is echter een korte beschrijving en geen codevoorbeelden in dit artikel en in andere recensieartikelen.
We gaan dit nadeel elimineren dat bij elke functie blijft hangen.
stijfheid
Zoals gezegd is een rigide code moeilijk te wijzigen, zelfs de kleinste dingen. Dit hoeft geen probleem te zijn als de code niet vaak of helemaal niet wordt gewijzigd. De code blijkt dus best goed te zijn. Als het echter nodig is om de code aan te passen en moeilijk is om dit te doen, wordt het een probleem, zelfs als het werkt.
Een van de populaire gevallen van rigiditeit is om de klassentypen expliciet te specificeren in plaats van abstracties te gebruiken (interfaces, basisklassen, enz.). Hieronder vindt u een voorbeeld van de code:
class A
{
B _b;
public A()
{
_b = new B();
}
public void Foo()
{
// Do some custom logic.
_b.DoSomething();
// Do some custom logic.
}
}
class B
{
public void DoSomething()
{
// Do something
}
} Hier hangt klasse A sterk af van klasse B. Dus als u in de toekomst een andere klasse in plaats van klasse B moet gebruiken, moet u klasse A wijzigen en opnieuw testen. Bovendien, als klasse B andere klassen beïnvloedt, wordt de situatie veel gecompliceerder.
De tijdelijke oplossing is een abstractie die de IComponent-interface moet introduceren via de constructor van klasse A. In dit geval is het niet langer afhankelijk van de specifieke klasse В en alleen van de IComponent-interface. Сlass В moet op zijn beurt de IComponent-interface implementeren.
interface IComponent
{
void DoSomething();
}
class A
{
IComponent _component;
public A(IComponent component)
{
_component = component;
}
void Foo()
{
// Do some custom logic.
_component.DoSomething();
// Do some custom logic.
}
}
class B : IComponent
{
void DoSomething()
{
// Do something
}
} Laten we een specifiek voorbeeld geven. Stel dat er een reeks klassen is die de informatie loggen - ProductManager en Consumer. Hun taak is om een product in de database op te slaan en dienovereenkomstig te bestellen. Beide klassen registreren relevante gebeurtenissen. Stel je voor dat er eerst een log in een bestand was. Hiervoor werd de klasse FileLogger gebruikt. Bovendien waren de klassen ondergebracht in verschillende modules (assemblies).
// Module 1 (Client)
static void Main()
{
var product = new Product("milk");
var productManager = new ProductManager();
productManager.AddProduct(product);
var consumer = new Consumer();
consumer.PurchaseProduct(product.Name);
}
// Module 2 (Business logic)
public class ProductManager
{
private readonly FileLogger _logger = new FileLogger();
public void AddProduct(Product product)
{
// Add the product to the database.
_logger.Log("The product is added.");
}
}
public class Consumer
{
private readonly FileLogger _logger = new FileLogger();
public void PurchaseProduct(string product)
{
// Purchase the product.
_logger.Log("The product is purchased.");
}
}
public class Product
{
public string Name { get; private set; }
public Product(string name)
{
Name = name;
}
}
// Module 3 (Logger implementation)
public class FileLogger
{
const string FileName = "log.txt";
public void Log(string message)
{
// Write the message to the file.
}
} Als het in eerste instantie voldoende was om alleen het bestand te gebruiken, en het vervolgens noodzakelijk wordt om in te loggen op andere repositories, zoals een database of een cloudgebaseerde service voor het verzamelen en opslaan van gegevens, dan moeten we alle klassen in de bedrijfslogica wijzigen module (Module 2) die FileLogger gebruiken. Dit kan immers lastig blijken te zijn. Om dit probleem op te lossen, kunnen we een abstracte interface introduceren om met de logger te werken, zoals hieronder getoond.
// Module 1 (Client)
static void Main()
{
var logger = new FileLogger();
var product = new Product("milk");
var productManager = new ProductManager(logger);
productManager.AddProduct(product);
var consumer = new Consumer(logger);
consumer.PurchaseProduct(product.Name);
}
// Module 2 (Business logic)
class ProductManager
{
private readonly ILogger _logger;
public ProductManager(ILogger logger)
{
_logger = logger;
}
public void AddProduct(Product product)
{
// Add the product to the database.
_logger.Log("The product is added.");
}
}
public class Consumer
{
private readonly ILogger _logger;
public Consumer(ILogger logger)
{
_logger = logger;
}
public void PurchaseProduct(string product)
{
// Purchase the product.
_logger.Log("The product is purchased.");
}
}
public class Product
{
public string Name { get; private set; }
public Product(string name)
{
Name = name;
}
}
// Module 3 (interfaces)
public interface ILogger
{
void Log(string message);
}
// Module 4 (Logger implementation)
public class FileLogger : ILogger
{
const string FileName = "log.txt";
public virtual void Log(string message)
{
// Write the message to the file.
}
} In dit geval is het voldoende om bij het wijzigen van een loggertype de clientcode (Main) te wijzigen, die de logger initialiseert en toevoegt aan de constructor van ProductManager en Consumer. Dus hebben we de klassen van bedrijfslogica afgesloten van de wijziging van het loggertype zoals vereist.
Naast directe links naar de gebruikte klassen, kunnen we starheid in andere varianten bewaken die tot problemen kunnen leiden bij het wijzigen van de code. Er kan een oneindige reeks van zijn. We zullen echter proberen een ander voorbeeld te geven. Stel dat er een code is die het gebied van een geometrisch patroon op de console weergeeft.
static void Main()
{
var rectangle = new Rectangle() { W = 3, H = 5 };
var circle = new Circle() { R = 7 };
var shapes = new Shape[] { rectangle, circle };
ShapeHelper.ReportShapesSize(shapes);
}
class ShapeHelper
{
private static double GetShapeArea(Shape shape)
{
if (shape is Rectangle)
{
return ((Rectangle)shape).W * ((Rectangle)shape).H;
}
if (shape is Circle)
{
return 2 * Math.PI * ((Circle)shape).R * ((Circle)shape).R;
}
throw new InvalidOperationException("Not supported shape");
}
public static void ReportShapesSize(Shape[] shapes)
{
foreach(Shape shape in shapes)
{
if (shape is Rectangle)
{
double area = GetShapeArea(shape);
Console.WriteLine($"Rectangle's area is {area}");
}
if (shape is Circle)
{
double area = GetShapeArea(shape);
Console.WriteLine($"Circle's area is {area}");
}
}
}
}
public class Shape
{ }
public class Rectangle : Shape
{
public double W { get; set; }
public double H { get; set; }
}
public class Circle : Shape
{
public double R { get; set; }
} Zoals je kunt zien, zullen we bij het toevoegen van een nieuw patroon de methoden van de ShapeHelper-klasse moeten wijzigen. Een van de opties is om het renderalgoritme door te geven in de klassen van geometrische patronen (Rechthoek en Cirkel), zoals hieronder weergegeven. Op deze manier isoleren we de relevante logica in de corresponderende klassen, waardoor de verantwoordelijkheid van de ShapeHelper-klasse wordt verminderd voordat informatie op de console wordt weergegeven.
static void Main()
{
var rectangle = new Rectangle() { W = 3, H = 5 };
var circle = new Circle() { R = 7 };
var shapes = new Shape[]() { rectangle, circle };
ShapeHelper.ReportShapesSize(shapes);
}
class ShapeHelper
{
public static void ReportShapesSize(Shape[] shapes)
{
foreach(Shape shape in shapes)
{
shape.Report();
}
}
}
public abstract class Shape
{
public abstract void Report();
}
public class Rectangle : Shape
{
public double W { get; set; }
public double H { get; set; }
public override void Report()
{
double area = W * H;
Console.WriteLine($"Rectangle's area is {area}");
}
}
public class Circle : Shape
{
public double R { get; set; }
public override void Report()
{
double area = 2 * Math.PI * R * R;
Console.WriteLine($"Circle's area is {area}");
}
} Als gevolg hiervan hebben we de ShapeHelper-klasse gesloten voor wijzigingen die nieuwe soorten patronen toevoegen door gebruik te maken van overerving en polymorfisme.
Immobiliteit
We kunnen immobiliteit monitoren bij het splitsen van de code in herbruikbare modules. Als gevolg hiervan kan het project stoppen met ontwikkelen en concurrerend zijn.
Als voorbeeld nemen we een desktopprogramma in overweging, waarvan de hele code is geïmplementeerd in het uitvoerbare toepassingsbestand (.exe) en zo is ontworpen dat de bedrijfslogica niet in afzonderlijke modules of klassen is ingebouwd. Later kreeg de ontwikkelaar te maken met de volgende zakelijke vereisten:
- De gebruikersinterface wijzigen door er een webtoepassing van te maken;
- Om de functionaliteit van het programma te publiceren als een set webservices die beschikbaar zijn voor externe clients om in hun eigen applicaties te gebruiken.
In dit geval is het moeilijk om aan deze vereisten te voldoen, omdat de hele code zich in de uitvoerbare module bevindt.
De onderstaande afbeelding toont een voorbeeld van een onbeweeglijk ontwerp in tegenstelling tot degene die deze indicator niet heeft. Ze worden gescheiden door een stippellijn. Zoals u kunt zien, maakt de toewijzing van de code op herbruikbare modules (Logic), evenals de publicatie van de functionaliteit op het niveau van webservices, het gebruik ervan in verschillende clienttoepassingen (App) mogelijk, wat een onbetwistbaar voordeel is.
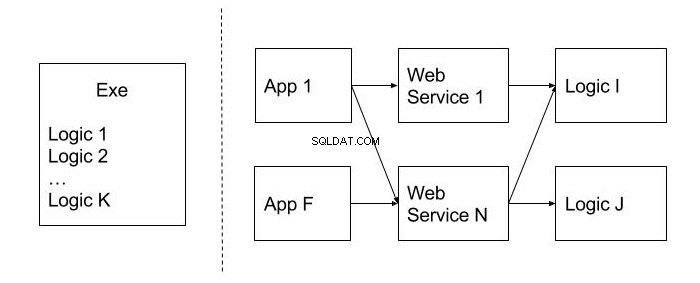
Immobiliteit kan ook een monolithisch ontwerp worden genoemd. Het is moeilijk om het op te splitsen in kleinere en bruikbare eenheden van de code. Hoe kunnen we dit probleem omzeilen? In de ontwerpfase is het beter om na te denken over hoe waarschijnlijk het is om deze of gene functie in andere systemen te gebruiken. De code die naar verwachting opnieuw zal worden gebruikt, kan het beste in afzonderlijke modules en klassen worden geplaatst.
Viscositeit
Er zijn twee soorten:
- Ontwikkelingsviscositeit
- Omgevingsviscositeit
We kunnen de ontwikkelingsviscositeit zien terwijl we proberen het geselecteerde toepassingsontwerp te volgen. Dit kan gebeuren wanneer een programmeur aan te veel eisen moet voldoen terwijl er een eenvoudigere manier van ontwikkelen is. Bovendien kan de ontwikkelingsviscositeit worden gezien wanneer het proces van assemblage, implementatie en testen niet effectief is.
Als een eenvoudig voorbeeld kunnen we het werk beschouwen met constanten die moeten worden geplaatst (By Design) in een afzonderlijke module (Module 1) om te worden gebruikt door andere componenten (Module 2 en Module 3).
// Module 1 (Constants)
static class Constants
{
public const decimal MaxSalary = 100M;
public const int MaxNumberOfProducts = 100;
}
// Finance Module
#using Module1
static class FinanceHelper
{
public static bool ApproveSalary(decimal salary)
{
return salary <= Constants.MaxSalary;
}
}
// Marketing Module
#using Module1
class ProductManager
{
public void MakeOrder()
{
int productsNumber = 0;
while(productsNumber++ <= Constants.MaxNumberOfProducts)
{
// Purchase some product
}
}
} Als het assemblageproces om welke reden dan ook veel tijd in beslag neemt, zal het voor ontwikkelaars moeilijk zijn om te wachten tot het klaar is. Bovendien moet worden opgemerkt dat de constante module gemengde entiteiten bevat die tot verschillende delen van de bedrijfslogica behoren (financiële en marketingmodules). De constante module kan dus vrij vaak worden gewijzigd om redenen die onafhankelijk zijn van elkaar, wat kan leiden tot extra problemen zoals synchronisatie van de wijzigingen.
Dit alles vertraagt het ontwikkelingsproces en kan programmeurs belasten. De varianten van het minder viskeuze ontwerp zouden zijn om ofwel afzonderlijke constante-modules te maken - één voor de overeenkomstige module van bedrijfslogica - of om constanten naar de juiste plaats door te geven zonder er een aparte module voor te nemen.
Een voorbeeld van de omgevingsviscositeit kan de ontwikkeling en het testen van de toepassing op de virtuele client-machine op afstand zijn. Soms wordt deze workflow ondraaglijk vanwege een trage internetverbinding, zodat de ontwikkelaar de integratietest van de geschreven code systematisch kan negeren, wat uiteindelijk kan leiden tot bugs aan de clientzijde bij het gebruik van deze functie.
Onnodige complexiteit
In dit geval heeft het ontwerp eigenlijk ongebruikte functionaliteit. Dit feit kan de ondersteuning en het onderhoud van het programma bemoeilijken en de ontwikkel- en testtijd verlengen. Denk bijvoorbeeld aan het programma dat bepaalde gegevens uit de database moet lezen. Om dit te doen, is de DataManager-component gemaakt, die in een andere component wordt gebruikt.
class DataManager
{
object[] GetData()
{
// Retrieve and return data
}
} Als de ontwikkelaar een nieuwe methode toevoegt aan DataManager om gegevens in de database te schrijven (WriteData), die in de toekomst waarschijnlijk niet zal worden gebruikt, dan wordt het ook een onnodige complexiteit.
Een ander voorbeeld is een interface voor alle doeleinden. We gaan bijvoorbeeld een interface overwegen met de single Process-methode die een object van het stringtype accepteert.
interface IProcessor
{
void Process(string message);
} Als het de taak was om een bepaald type bericht met een goed gedefinieerde structuur te verwerken, zou het gemakkelijker zijn om een strikt getypte interface te maken, in plaats van ontwikkelaars deze string elke keer te laten deserialiseren in een bepaald berichttype.
Overmatig gebruik van ontwerppatronen in gevallen waar dit helemaal niet nodig is, kan ook leiden tot viscositeitsontwerp.
Waarom zou u uw tijd verspillen aan het schrijven van een mogelijk ongebruikte code? Soms moet QA deze code testen, omdat deze daadwerkelijk is gepubliceerd en open staat voor gebruik door externe clients. Dit stelt ook de releasetijd uit. Het opnemen van een functie voor de toekomst is alleen de moeite waard als het mogelijke voordeel de kosten voor ontwikkeling en testen overtreft.
Onnodige herhaling
Misschien hebben de meeste ontwikkelaars te maken gehad of zullen ze deze functie tegenkomen, die erin bestaat meerdere keren dezelfde logica of de code te kopiëren. De grootste bedreiging is de kwetsbaarheid van deze code tijdens het wijzigen ervan - door iets op de ene plek te repareren, vergeet je dit misschien op een andere plek te doen. Bovendien kost het meer tijd om wijzigingen aan te brengen in vergelijking met de situatie wanneer de code deze functie niet bevat.
Onnodige herhaling kan te wijten zijn aan de nalatigheid van ontwikkelaars, maar ook aan de rigiditeit/fragiliteit van het ontwerp wanneer het veel moeilijker en riskanter is om de code niet te herhalen in plaats van dit te doen. Herhaalbaarheid is in ieder geval geen goed idee en het is noodzakelijk om de code voortdurend te verbeteren, waarbij herbruikbare onderdelen worden doorgegeven aan algemene methoden en klassen.
Slechte leesbaarheid
U kunt deze functie controleren wanneer het moeilijk is om een code te lezen en te begrijpen waarvoor deze is gemaakt. De redenen voor slechte leesbaarheid kunnen het niet-naleven van de vereisten voor de uitvoering van de code (syntaxis, variabelen, klassen), een gecompliceerde implementatielogica, enz. zijn.
Hieronder vindt u het voorbeeld van de moeilijk leesbare code, die de methode implementeert met de Booleaanse variabele.
void Process_true_false(string trueorfalsevalue)
{
if (trueorfalsevalue.ToString().Length == 4)
{
// That means trueorfalsevalue is probably "true". Do something here.
}
else if (trueorfalsevalue.ToString().Length == 5)
{
// That means trueorfalsevalue is probably "false". Do something here.
}
else
{
throw new Exception("not true of false. that's not nice. return.")
}
} Hier kunnen we verschillende problemen schetsen. Ten eerste voldoen namen van methoden en variabelen niet aan algemeen aanvaarde conventies. Ten tweede is de implementatie van de methode niet de beste.
Misschien is het de moeite waard om een Booleaanse waarde te nemen in plaats van een string. Het is echter beter om deze aan het begin van de methode naar een Booleaanse waarde te converteren, in plaats van de methode voor het bepalen van de lengte van de tekenreeks te gebruiken.
Ten derde komt de tekst van de uitzondering niet overeen met de officiële stijl. Bij het lezen van dergelijke teksten kan het gevoel zijn dat de code door een amateur is gemaakt (toch kan er een punt zijn). De methode kan als volgt worden herschreven als er een Booleaanse waarde voor nodig is:
public void Process(bool value)
{
if (value)
{
// Do something.
}
else
{
// Do something.
}
} Hier is nog een voorbeeld van refactoring als je nog steeds een string moet nemen:
public void Process(string value)
{
bool bValue = false;
if (!bool.TryParse(value, out bValue))
{
throw new ArgumentException($"The {value} is not boolean");
}
if (bValue)
{
// Do something.
}
else
{
// Do something.
}
} Het wordt aanbevolen om refactoring uit te voeren met de moeilijk leesbare code, bijvoorbeeld wanneer onderhoud en klonen tot meerdere bugs leiden.
Breekbaarheid
De kwetsbaarheid van een programma betekent dat het gemakkelijk kan worden gecrasht wanneer het wordt gewijzigd. Er zijn twee soorten crashes:compilatiefouten en runtime-fouten. De eerste kunnen een achterkant van stijfheid zijn. De laatste zijn het gevaarlijkst omdat ze aan de kant van de klant voorkomen. Ze zijn dus een indicator van de kwetsbaarheid.
De indicator is ongetwijfeld relatief. Iemand repareert de code zeer zorgvuldig en de kans op crash is vrij klein, terwijl anderen dit gehaast en onzorgvuldig doen. Toch kan een andere code met dezelfde gebruikers een ander aantal fouten veroorzaken. Waarschijnlijk kunnen we zeggen dat hoe moeilijker het is om de code te begrijpen en te vertrouwen op de uitvoeringstijd van het programma, in plaats van op de compilatiefase, hoe kwetsbaarder de code is.
Bovendien crasht de functionaliteit die niet wordt gewijzigd vaak. Het kan last hebben van de hoge koppeling van de logica van verschillende componenten.
Denk aan het specifieke voorbeeld. Hier bevindt de logica van gebruikersautorisatie met een bepaalde rol (gedefinieerd als de gerolde parameter) om toegang te krijgen tot een bepaalde bron (gedefinieerd als de resourceUri) zich in de statische methode.
static void Main()
{
if (Helper.Authorize(1, "/pictures"))
{
Console.WriteLine("Authorized");
}
}
class Helper
{
public static bool Authorize(int roleId, string resourceUri)
{
if (roleId == 1 || roleId == 10)
{
if (resourceUri == "/pictures")
{
return true;
}
}
if (roleId == 1 || roleId == 2 && resourceUri == "/admin")
{
return true;
}
return false;
}
} Zoals je kunt zien, is de logica ingewikkeld. Het is duidelijk dat het toevoegen van nieuwe rollen en bronnen het gemakkelijk zal breken. Als gevolg hiervan kan een bepaalde rol toegang krijgen of verliezen tot een resource. Het maken van de resourceklasse waarin de resource-ID en de lijst met ondersteunde rollen intern worden opgeslagen, zoals hieronder weergegeven, zou de kwetsbaarheid verminderen.
static void Main()
{
var picturesResource = new Resource() { Uri = "/pictures" };
picturesResource.AddRole(1);
if (picturesResource.IsAvailable(1))
{
Console.WriteLine("Authorized");
}
}
class Resource
{
private List<int> _roles = new List<int>();
public string Uri { get; set; }
public void AddRole(int roleId)
{
_roles.Add(roleId);
}
public void RemoveRole(int roleId)
{
_roles.Remove(roleId);
}
public bool IsAvailable(int roleId)
{
return _roles.Contains(roleId);
}
} In dit geval is het, om nieuwe bronnen en rollen toe te voegen, helemaal niet nodig om de logische autorisatiecode te wijzigen, dat wil zeggen, er valt eigenlijk niets te breken.
Wat kan helpen bij het opsporen van runtime-fouten? Het antwoord is handmatig, automatisch en unit testing. Hoe beter het testproces is georganiseerd, hoe waarschijnlijker het is dat de fragiele code aan de clientzijde zal voorkomen.
Breekbaarheid is vaak een keerzijde van andere kenmerken van een slecht ontwerp, zoals starheid, slechte leesbaarheid en onnodige herhaling.
Conclusie
We hebben geprobeerd de belangrijkste kenmerken van een slecht ontwerp te schetsen en te beschrijven. Sommigen van hen zijn onderling afhankelijk. U moet begrijpen dat de kwestie van het ontwerp niet altijd onvermijdelijk tot problemen leidt. Het wijst er alleen op dat ze kunnen voorkomen. Hoe minder deze identifiers worden gecontroleerd, hoe kleiner deze kans is.