Lelijk. Zo zien ongesorteerde gegevens eruit. We maken gegevens gemakkelijk voor het oog door ze te sorteren. En daar is SQL ORDER BY voor. Gebruik een of meer kolommen of uitdrukkingen als basis om gegevens te sorteren. Voeg vervolgens ASC of DESC toe om oplopend of aflopend te sorteren.
De SQL ORDER BY-syntaxis:
ORDER BY <order_by_expression> [ASC | DESC]
De ORDER BY-expressie kan zo eenvoudig zijn als een lijst met kolommen of expressies. Het kan ook voorwaardelijk zijn met een CASE WHEN-blok.
Het is erg flexibel.
U kunt ook via OFFSET en FETCH bladeren. Geef het aantal rijen op dat moet worden overgeslagen en het aantal rijen dat moet worden weergegeven.
Maar hier is het slechte nieuws.
Het toevoegen van ORDER BY aan uw zoekopdrachten kan deze vertragen. En sommige andere kanttekeningen kunnen ervoor zorgen dat ORDER BY "niet werkt". Je kunt ze niet zomaar gebruiken wanneer je maar wilt, omdat er sancties kunnen zijn. Dus, wat doen we?
In dit artikel gaan we in op de do's en don'ts bij het gebruik van ORDER BY. Elk item behandelt een probleem en er zal een oplossing volgen.
Klaar?
Do's in SQL ORDER BY
1. Indexeer de SQL ORDER BY kolom(men)
Indexen hebben alles te maken met snel zoeken. En als je er een hebt in de kolommen die je gebruikt in de ORDER BY-clausule, kan je zoekopdracht sneller worden.
Laten we ORDER BY gaan gebruiken in een kolom zonder index. We zullen de AdventureWorks . gebruiken voorbeelddatabase. Schakel de IX_SalesOrderDetail_ProductID . uit voordat u de onderstaande query uitvoert index in de SalesOrderDetail tafel. Druk vervolgens op Ctrl-M en voer het uit.
-- Get order details by product and sort them by ProductID
USE AdventureWorks
GO
SET STATISTICS IO ON
GO
SELECT
ProductID
,OrderQty
,UnitPrice
,LineTotal
FROM Sales.SalesOrderDetail
ORDER BY ProductID
SET STATISTICS IO OFF
GO
ANALYSE
De bovenstaande code voert de I/O-statistieken uit op het tabblad Berichten van SQL Server Management Studio. U ziet het uitvoeringsplan in een ander tabblad.
ZONDER INDEX
Laten we eerst de logische waarden uit de STATISTICS IO halen. Bekijk figuur 1.
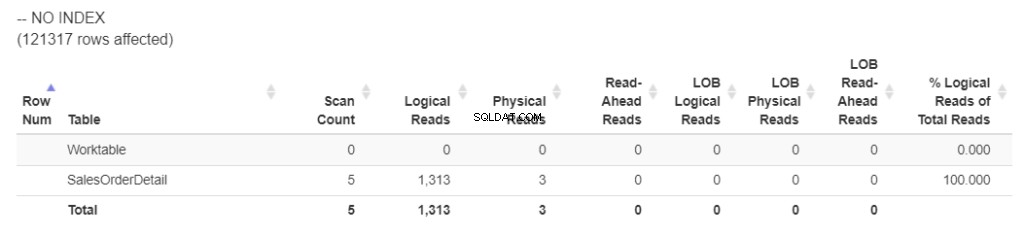
Figuur 1 . Logische leest met ORDER BY van een niet-geïndexeerde kolom. (Geformatteerd met statisticsparser.com )
Zonder de index gebruikte de query 1.313 logische reads. En die Werktafel ? Het betekent dat SQL Server TempDB . gebruikte om de sortering te verwerken.
Maar wat gebeurde er achter de schermen? Laten we het uitvoeringsplan in figuur 2 eens bekijken.
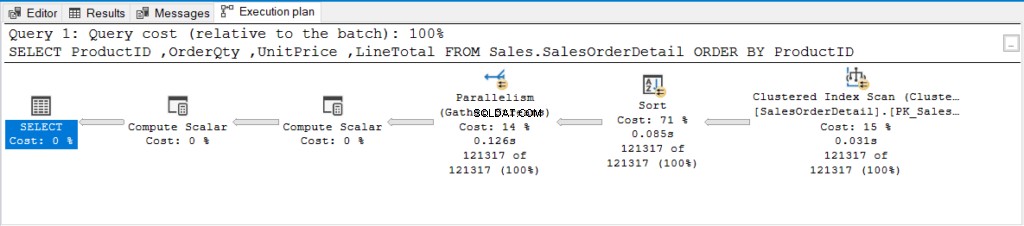
Figuur 2 . Uitvoeringsplan van een zoekopdracht met ORDER BY van een niet-geïndexeerde kolom.
Heb je die parallellisme (Gather Streams)-operator gezien? Het betekent dat SQL Server meer dan 1 processor heeft gebruikt om deze query te verwerken. De zoekopdracht was zwaar genoeg om meer CPU's te vereisen.
Dus, wat als SQL Server TempDB gebruikt? en meer verwerkers? Het is slecht voor een simpele vraag.
MET EEN INDEX
Hoe gaat het als de index opnieuw wordt ingeschakeld? Dat zoeken we uit. Herbouw de index IX_SalesOrderDetail_ProductID . Voer vervolgens de bovenstaande query opnieuw uit.
Controleer de nieuwe logische waarden in Afbeelding 3.
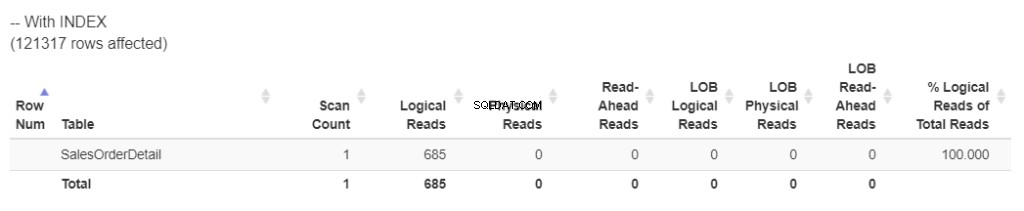
Figuur 3 . Nieuwe logische uitlezingen na het opnieuw opbouwen van de index.
Dit is veel beter. We hebben het aantal logische reads met bijna de helft teruggebracht. Dat betekent dat de index ervoor zorgde dat het minder bronnen verbruikt. En de Werktafel ? Het is weg! Het is niet nodig om TempDB te gebruiken .
En het uitvoeringsplan? Zie figuur 4.
Figuur 4 . Het nieuwe uitvoeringsplan is eenvoudiger toen de index opnieuw werd opgebouwd.
Zie je wel? Het plan is eenvoudiger. Geen extra CPU's nodig om dezelfde 121.317 rijen te sorteren.
Het komt er dus op neer:Zorg ervoor dat de kolommen die u gebruikt voor ORDER BY geïndexeerd zijn .
MAAR WAT ALS HET TOEVOEGEN VAN EEN INDEX DE SCHRIJFPRESTATIES BENVLOEDT?
Goede vraag.
Als dat het probleem is, kunt u een deel van de brontabel dumpen in een tijdelijke tabel of voor het geheugen geoptimaliseerde tabel . Indexeer vervolgens die tabel. Gebruik hetzelfde als er meer tabellen bij betrokken zijn. Beoordeel vervolgens de queryprestaties van de door u gekozen optie. De snellere optie zal de winnaar zijn.
2. Beperk de resultaten met WHERE en OFFSET/FETCH
Laten we een andere zoekopdracht gebruiken. Stel dat u productinformatie met afbeeldingen in een app moet weergeven. Afbeeldingen kunnen zoekopdrachten nog zwaarder maken. We controleren dus niet alleen logische uitlezingen, maar ook logische uitlezingen.
Hier is de code.
SET STATISTICS IO ON
GO
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,b.Name AS ProductSubcategory
,d.ThumbNailPhoto
,d.LargePhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
ORDER BY ProductSubcategory, ProductName, a.Color
SET STATISTICS IO OFF
GO
Dit levert 97 fietsen met foto's op. Ze zijn erg moeilijk te browsen op een mobiel apparaat.
ANALYSE
MINMAL WHERE GEBRUIKEN ZONDER OFFSET/FETCH
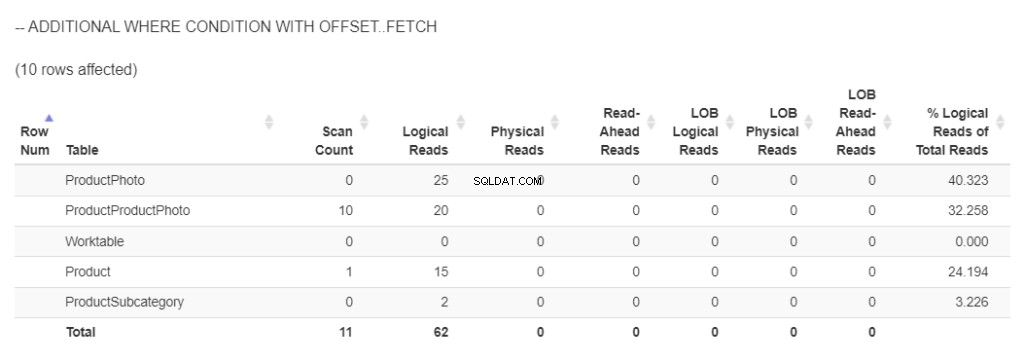
Dit is hoeveel logische leesbewerkingen er nodig zijn om 97 producten met afbeeldingen op te halen. Zie figuur 5.
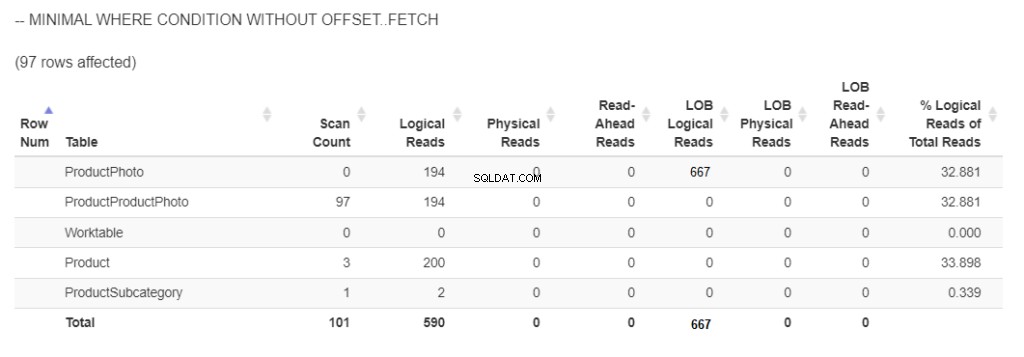
Figuur 5 . De logische lees- en lob-logische leesbewerkingen bij gebruik van ORDER BY zonder OFFSET/FETCH en met minimale WHERE-voorwaarde . (Opmerking:statistiekenparser.com liet de lob-logische uitlezingen niet zien. De schermafbeelding wordt bewerkt op basis van het resultaat in SSMS)
667 lob logische reads verschenen vanwege het ophalen van afbeeldingen in 2 kolommen. Ondertussen werden voor de rest 590 logische reads gebruikt.
Hier is het uitvoeringsplan in figuur 6, zodat we het later kunnen vergelijken met het betere plan.
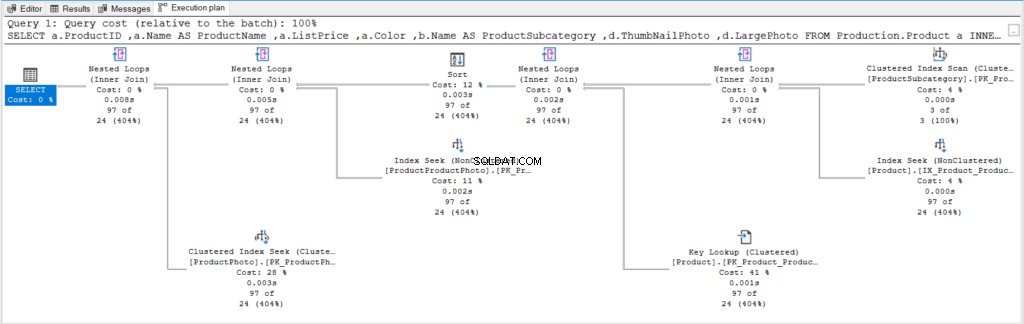
Figuur 6 . Uitvoeringsplan met ORDER BY zonder OFFSET/FETCH en met minimale WHERE-voorwaarde.
Er valt niet veel anders te zeggen totdat we het andere uitvoeringsplan zien.
AANVULLENDE WHERE CONDITION EN OFFSET/FETCH IN VOLGORDE BY GEBRUIKEN
Laten we nu de query aanpassen om ervoor te zorgen dat er minimale gegevens worden geretourneerd. Dit is wat we gaan doen:
- Voeg een voorwaarde toe aan de productsubcategorie. In de bellende app kunnen we ons voorstellen dat je de gebruiker ook de subcategorie laat kiezen.
- Verwijder vervolgens de productsubcategorie in de SELECT-lijst met kolommen en de ORDER BY-lijst met kolommen.
- Voeg ten slotte OFFSET/FETCH toe in ORDER BY. Slechts 10 producten worden geretourneerd en weergegeven in de bellende app.
Hier is de bewerkte code.
DECLARE @pageNumber TINYINT = 1
DECLARE @noOfRows TINYINT = 10 -- each page will display 10 products at a time
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,d.ThumbNailPhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
AND a.ProductSubcategoryID = 2 -- Road Bikes
ORDER BY ProductName, a.Color
OFFSET (@pageNumber-1)*@noOfRows ROWS FETCH NEXT @noOfRows ROWS ONLY
Deze code zal verder verbeteren als u er een opgeslagen procedure van maakt. Het heeft ook parameters zoals paginanummer en aantal rijen. Het paginanummer geeft aan welke pagina de gebruiker momenteel bekijkt. Verbeter dit verder door het aantal rijen flexibel te maken, afhankelijk van de schermresolutie. Maar dat is een ander verhaal.
Laten we nu eens kijken naar de logische waarden in Afbeelding 7.
Figuur 7 . Minder logische reads na vereenvoudiging van de query. OFFSET/FETCH wordt ook gebruikt in ORDER BY.
Vergelijk vervolgens figuur 7 met figuur 5. De logische uitlezingen van de lob zijn verdwenen. Bovendien hebben de logische uitlezingen een opmerkelijke afname, aangezien de resultatenset ook is verlaagd van 97 naar 10.
Maar wat deed SQL Server achter de schermen? Bekijk het uitvoeringsplan in figuur 8.
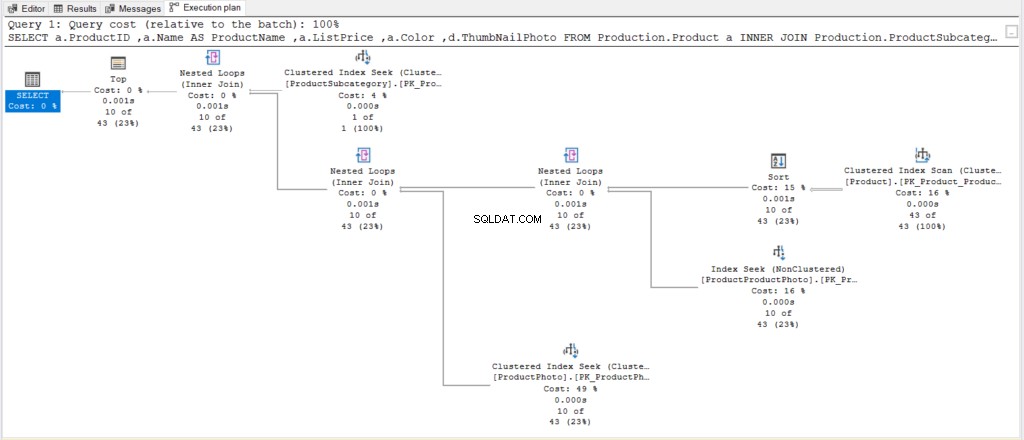
Figuur 8 . Een eenvoudiger uitvoeringsplan na vereenvoudiging van de zoekopdracht en het toevoegen van OFFSET/FETCH in ORDER BY.
Vergelijk vervolgens figuur 8 met figuur 6. Zonder elke operator te onderzoeken, kunnen we zien dat dit nieuwe plan eenvoudiger is dan het vorige.
De les? Vereenvoudig uw zoekopdracht. Gebruik waar mogelijk OFFSET/FETCH.
Don'ts in SQL ORDER BY
We zijn klaar met wat we moeten doen bij het gebruik van ORDER BY. Laten we ons deze keer concentreren op wat we moeten vermijden.
3. Gebruik ORDER BY niet bij het sorteren op de geclusterde indexsleutel
Omdat het nutteloos is.
Laten we het met een voorbeeld laten zien.
SET STATISTICS IO ON
GO
-- Using ORDER BY with BusinessEntityID - the primary key
SELECT TOP 100 * FROM Person.Person
ORDER BY BusinessEntityID;
-- Without using ORDER BY at all
SELECT TOP 100 * FROM Person.Person;
SET STATISTICS IO OFF
GO
Laten we dan eens kijken naar de logische uitlezingen van beide SELECT-instructies in Afbeelding 9.
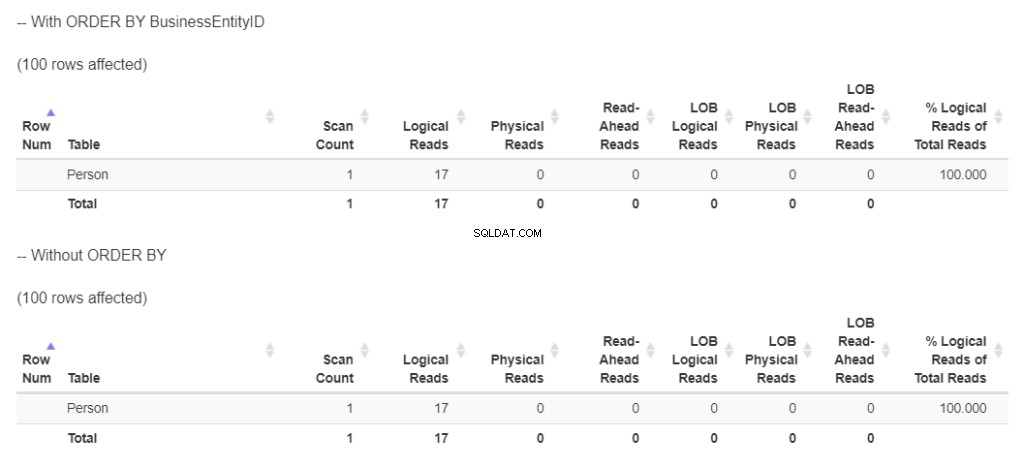
Figuur 9 . 2-query's in de tabel Persoon tonen dezelfde logische uitlezingen. De ene is met ORDER BY, de andere zonder.
Beide hebben 17 logische uitlezingen. Dit is logisch omdat dezelfde 100 rijen worden geretourneerd. Maar hebben ze hetzelfde plan? Bekijk figuur 10.
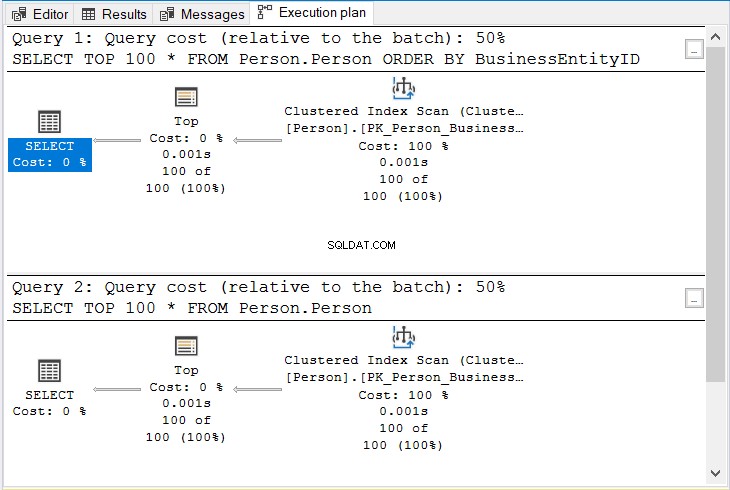
Figuur 10 . Hetzelfde plan of ORDER BY wordt gebruikt of niet bij het sorteren op de geclusterde indexsleutel.
Let op dezelfde operators en dezelfde querykosten.
Maar waarom? Bij het indexeren van een of meer kolommen in een geclusterde index, wordt de tabel fysiek gesorteerd door de geclusterde indexsleutel. Dus zelfs als u niet op die sleutel sorteert, wordt het resultaat nog steeds gesorteerd.
Onder de streep? Vergeef jezelf door in vergelijkbare gevallen de geclusterde indexsleutel niet te gebruiken met ORDER BY . Bespaar energie met minder toetsaanslagen.
4. Gebruik ORDER BY niet als een stringkolom getallen bevat
Als u sorteert op een tekenreekskolom die getallen bevat, verwacht dan geen sorteervolgorde zoals typen met reële getallen. Anders staat u een grote verrassing te wachten.
Hier is een voorbeeld.
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
ORDER BY NationalIDNumber;
Controleer de uitvoer in Afbeelding 11.
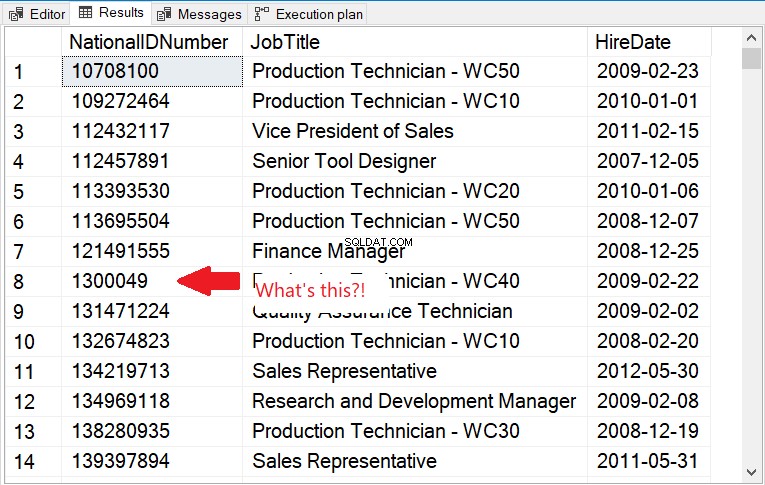
Figuur 11 . Sorteervolgorde van een tekenreekskolom die getallen bevat. De numerieke waarde wordt niet gevolgd.
In figuur 11 wordt de lexicografische sorteervolgorde gevolgd. Om dit op te lossen, gebruikt u een CAST naar een geheel getal.
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
ORDER BY CAST(NationalIDNumber AS INT)
Bekijk figuur 12 voor de vaste output.
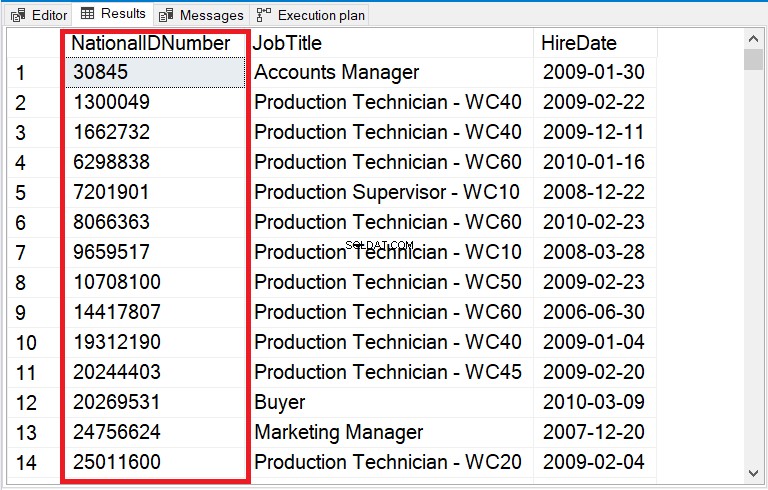
Figuur 12 . CAST naar INT repareerde de sortering van een stringkolom die getallen bevat.
Dus, iin plaats van ORDER BY
5. Gebruik SELECT INTO #TempTable niet met ORDER BY
Uw gewenste sorteervolgorde wordt niet gegarandeerd in de tijdelijke doeltabel. Zie de officiële documentatie .
Laten we een aangepaste code van het vorige voorbeeld nemen.
SELECT
NationalIDNumber
,JobTitle
,HireDate
INTO #temp
FROM HumanResources.Employee
ORDER BY CAST(NationalIDNumber AS INT);
SELECT * FROM #temp;
Het enige verschil met het vorige voorbeeld is de INTO-clausule. De output zal hetzelfde zijn als in figuur 11. We zijn terug in vierkant 1, zelfs als we de kolom naar INT CAST.
U moet een tijdelijke tabel maken met CREATE TABLE. Maar voeg een extra identiteitskolom toe en maak er een primaire sleutel van. INSERT dan in de tijdelijke tabel.
Hier is de vaste code.
CREATE TABLE #temp2
(
id INT IDENTITY(1,1) NOT NULL PRIMARY KEY,
NationalIDNumber NVARCHAR(15) NOT NULL,
JobTitle NVARCHAR(50) NOT NULL,
HireDate DATE NOT NULL
)
GO
INSERT INTO #temp2
(NationalIDNumber, JobTitle, HireDate)
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM HumanResources.Employee
ORDER BY CAST(NationalIDNumber AS INT);
SELECT
NationalIDNumber
,JobTitle
,HireDate
FROM #Temp2;
En de output zal hetzelfde zijn als in figuur 12. Het werkt!
Afhaalmaaltijden bij het gebruik van SQL ORDER BY
We hebben de veelvoorkomende valkuilen behandeld bij het gebruik van SQL ORDER BY. Hier is een samenvatting:
Do's :
- Indexeer de ORDER BY-kolommen,
- Beperk de resultaten met WHERE en OFFSET/FETCH,
Niet doen :
- Gebruik ORDER BY niet bij het sorteren op de geclusterde indexsleutel,
- Gebruik ORDER BY niet als een tekenreekskolom getallen bevat. CAST in plaats daarvan eerst de tekenreekskolom naar INT.
- Gebruik SELECT INTO #TempTable niet met ORDER BY. Maak in plaats daarvan eerst de tijdelijke tabel met een extra identiteitskolom.
Wat zijn jouw tips en trucs bij het gebruik van ORDER BY? Laat het ons weten in het gedeelte Opmerkingen hieronder. En als je dit bericht leuk vindt, deel het dan op je favoriete sociale mediaplatforms.