TimescaleDB is een open-source database die is uitgevonden om SQL schaalbaar te maken voor tijdreeksgegevens. Het is een relatief nieuw databasesysteem. TimescaleDB is twee jaar geleden op de markt geïntroduceerd en bereikte versie 1.0 in september 2018. Desalniettemin is het ontwikkeld bovenop een volwassen RDBMS-systeem.
TimescaleDB is verpakt als een PostgreSQL-extensie. Alle code is gelicentieerd onder de Apache-2 open-sourcelicentie, met uitzondering van sommige broncode die verband houdt met de time-series enterprise-functies die zijn gelicentieerd onder de Timescale License (TSL).
Als een tijdreeksdatabase biedt het automatische partitionering over datum- en sleutelwaarden. De native SQL-ondersteuning van TimescaleDB maakt het een goede optie voor diegenen die van plan zijn tijdreeksgegevens op te slaan en al over gedegen kennis van SQL-taal beschikken.
Als u op zoek bent naar een tijdreeksdatabase die uitgebreide SQL, HA, een solide back-upoplossing, replicatie en andere zakelijke functies kan gebruiken, kan deze blog u op het juiste pad brengen.
Wanneer TimescaleDB gebruiken
Voordat we beginnen met de functies van TimescaleDB, laten we eens kijken waar het past. TimescaleDB is ontworpen om het beste van zowel relationeel als NoSQL te bieden, met de focus op tijdreeksen. Maar wat zijn tijdreeksgegevens?
Tijdreeksgegevens vormen de kern van het internet der dingen, monitoringsystemen en vele andere oplossingen die zijn gericht op frequent veranderende gegevens. Zoals de naam "tijdreeksen" suggereert, hebben we het over gegevens die met de tijd veranderen. De mogelijkheden voor een dergelijk type DBMS zijn eindeloos. U kunt het gebruiken in verschillende industriële IoT-gebruikssituaties in de productie-, mijnbouw-, olie- en gassector, detailhandel, gezondheidszorg, dev ops-monitoring of financiële informatiesector. Het kan ook uitstekend passen in machine learning-pijplijnen of als bron voor bedrijfsactiviteiten en intelligentie.
Het lijdt geen twijfel dat de vraag naar IoT en soortgelijke oplossingen zal groeien. Dat gezegd hebbende, kunnen we ook verwachten dat gegevens op veel verschillende manieren moeten worden geanalyseerd en verwerkt. Tijdreeksgegevens worden meestal alleen toegevoegd - het is vrij onwaarschijnlijk dat u oude gegevens bijwerkt. Meestal verwijdert u bepaalde rijen niet, aan de andere kant wilt u misschien een soort aggregatie van de gegevens in de loop van de tijd. We willen niet alleen opslaan hoe onze gegevens met de tijd veranderen, maar ook analyseren en ervan leren.
Het probleem met nieuwe typen databasesystemen is dat ze meestal hun eigen zoektaal gebruiken. Gebruikers hebben tijd nodig om een nieuwe taal te leren. Het grootste verschil tussen TimescaleDB en andere populaire tijdreeksdatabases is de ondersteuning voor SQL. TimescaleDB ondersteunt het volledige scala aan SQL-functionaliteit, inclusief op tijd gebaseerde aggregaten, joins, subquery's, vensterfuncties en secundaire indexen. Bovendien, als uw applicatie al gebruik maakt van PostgreSQL, zijn er geen wijzigingen nodig in de klantcode.
Basisbeginselen van architectuur
TimescaleDB is geïmplementeerd als een uitbreiding op PostgreSQL, wat betekent dat een tijdschaaldatabase wordt uitgevoerd binnen een algemene PostgreSQL-instantie. Dankzij het uitbreidingsmodel kan de database profiteren van veel van de kenmerken van PostgreSQL, zoals betrouwbaarheid, beveiliging en connectiviteit met een breed scala aan tools van derden. Tegelijkertijd maakt TimescaleDB gebruik van de hoge mate van aanpassing die beschikbaar is voor extensies door hooks toe te voegen diep in de queryplanner, het gegevensmodel en de uitvoeringsengine van PostgreSQL.
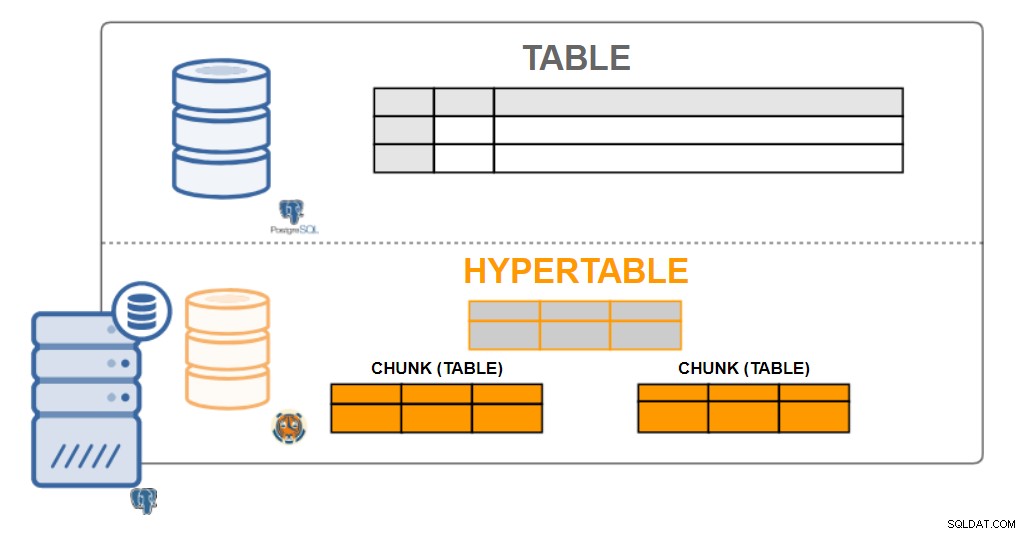 TimescaleDB-architectuur
TimescaleDB-architectuur Hypertafels
Vanuit gebruikersperspectief zien TimescaleDB-gegevens eruit als enkelvoudige tabellen, hypertabellen genoemd. Hypertabellen zijn een concept of een impliciete weergave van veel afzonderlijke tabellen die de gegevens bevatten die chunks worden genoemd. De gegevens van de hypertabel kunnen een of twee dimensies zijn. Het kan worden geaggregeerd door een tijdsinterval en door een (optionele) "partitiesleutel"-waarde.
Vrijwel alle gebruikersinteracties met TimescaleDB zijn met hypertables. Tabellen maken, indexen, tabellen wijzigen, gegevens selecteren, gegevens invoegen ... moeten allemaal op de hypertabel worden uitgevoerd.
TimescaleDB voert deze uitgebreide partitionering uit zowel op implementaties met één knooppunt als op geclusterde implementaties (in ontwikkeling). Hoewel partitionering traditioneel alleen wordt gebruikt voor het uitschalen over meerdere machines, stelt het ons ook in staat om op te schalen naar hoge schrijfsnelheden (en verbeterde parallelle query's), zelfs op afzonderlijke machines.
Ondersteuning voor relationele gegevens
Als relationele database biedt het volledige ondersteuning voor SQL. TimescaleDB ondersteunt flexibele datamodellen die kunnen worden geoptimaliseerd voor verschillende gebruiksscenario's. Dit maakt Timescale enigszins anders dan de meeste andere tijdreeksdatabases. Het DBMS is geoptimaliseerd voor snelle opname en complexe zoekopdrachten, gebaseerd op PostgreSQL en indien nodig hebben we toegang tot robuuste tijdreeksverwerking.
Installatie
TimescaleDB ondersteunt, net als PostgreSQL, veel verschillende manieren van installatie, waaronder installatie op Ubuntu, Debian, RHEL/Centos, Windows of cloudplatforms.
Een van de handigste manieren om met TimescaleDB te spelen is een docker-image.
De onderstaande opdracht haalt een Docker-image uit Docker Hub als deze nog niet is geïnstalleerd en voert deze vervolgens uit.
docker run -d --name timescaledb -p 5432:5432 -e POSTGRES_PASSWORD=severalnines timescale/timescaledbEerste gebruik
Aangezien onze instantie actief is, is het tijd om onze eerste timescaledb-database te maken. Zoals je hieronder kunt zien, maken we verbinding via de standaard PostgreSQL-console, dus als je PostgreSQL-clienttools (bijv. psql) lokaal hebt geïnstalleerd, kun je die gebruiken om toegang te krijgen tot de TimescaleDB-dockerinstantie.
psql -U postgres -h localhost
CREATE DATABASE severalnines;
\c severalnines
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;Dagelijkse operaties
Vanuit het oogpunt van zowel gebruik als beheer, ziet TimescaleDB er gewoon uit en voelt het aan als PostgreSQL, en kan als zodanig worden beheerd en opgevraagd.
De belangrijkste punten voor de dagelijkse werkzaamheden zijn:
- Bestaat naast andere TimescaleDB's en PostgreSQL-databases op een PostgreSQL-server.
- Gebruikt SQL als interfacetaal.
- Gebruikt algemene PostgreSQL-connectoren voor tools van derden voor back-ups, console enz.
TimescaleDB-instellingen
De kant-en-klare instellingen van PostgreSQL zijn doorgaans te conservatief voor moderne servers en TimescaleDB. U moet ervoor zorgen dat uw postgresql.conf-instellingen zijn afgestemd, hetzij door timescaledb-tune te gebruiken, hetzij door dit handmatig te doen.
$ timescaledb-tuneHet script zal u vragen om de wijzigingen te bevestigen. Deze wijzigingen worden vervolgens naar uw postgresql.conf geschreven en worden van kracht bij het opnieuw opstarten.
Laten we nu eens kijken naar enkele basisbewerkingen uit de TimescaleDB-zelfstudie die u een idee kunnen geven van hoe u met het nieuwe databasesysteem kunt werken.
Om een hypertabel te maken, begin je met een gewone SQL-tabel en converteer je deze vervolgens naar een hypertabel via de functie create_hypertable.
-- Create extension timescaledb
CREATE EXTENSION timescaledb;
Create a regular table
CREATE TABLE conditions (
time TIMESTAMPTZ NOT NULL,
location TEXT NOT NULL,
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL
);Het converteren naar hypertabel is eenvoudig als:
SELECT create_hypertable('conditions', 'time');Het invoegen van gegevens in de hypertabel gebeurt via normale SQL-commando's:
INSERT INTO conditions(time, location, temperature, humidity)
VALUES (NOW(), 'office', 70.0, 50.0);Gegevens selecteren is oude goede SQL.
SELECT * FROM conditions ORDER BY time DESC LIMIT 10;Zoals we hieronder kunnen zien, kunnen we een groep maken op, sorteren op en functies. Daarnaast bevat TimescaleDB functies voor tijdreeksanalyse die niet aanwezig zijn in vanilla PostgreSQL.
SELECT time_bucket('15 minutes', time) AS fifteen_min,
location, COUNT(*),
MAX(temperature) AS max_temp,
MAX(humidity) AS max_hum
FROM conditions
WHERE time > NOW() - interval '3 hours'
GROUP BY fifteen_min, location
ORDER BY fifteen_min DESC, max_temp DESC;