Met een salarisgegevensmodel kunt u eenvoudig het salaris van uw medewerkers berekenen. Hoe werkt dit model?
Het maakt niet uit of u een klein of groot bedrijf runt, u hebt een soort salarisoplossing nodig. Dan komt een payroll-applicatie goed van pas. Bovendien, hoe groter het bedrijf, hoe moeilijker het wordt om de salarisberekeningen van de werknemers te verwerken; hier wordt een payroll-applicatie een noodzaak. Om u te helpen alle gegevens te begrijpen die nodig zijn voor een dergelijke toepassing, zullen we u door een gerelateerd gegevensmodel leiden.
Laten we eens kijken hoe ons salarisgegevensmodel werkt!
Gegevensmodel
Met het maken van dit datamodel heb ik geprobeerd een model te maken dat algemeen toepasbaar is voor elk bedrijf. Natuurlijk zullen er altijd verschillen zijn in regelgeving, bedrijfsbeleid, enz. waardoor het model moet worden aangepast om aan de behoeften van een specifieke salarisadministratie te voldoen. De principes die in dit model zijn uiteengezet, zouden echter voor de meeste organisaties relevant moeten zijn.
Opgemerkt moet worden dat dit model is gemaakt met verschillende aannames:
- Salarissen zoals overeengekomen in arbeidsovereenkomst zijn per jaar.
- Nettosalarissen (d.w.z. met bepaalde bedragen ingehouden voor belastingen, enz.) worden betaald aan werknemers.
- Salarissen worden maandelijks betaald.
Het datamodel bestaat uit veertien tabellen en is onderverdeeld in twee vakgebieden:
EmployeesSalaries
Om het model beter te begrijpen, is het noodzakelijk om elk onderwerp grondig door te nemen.
Werknemers
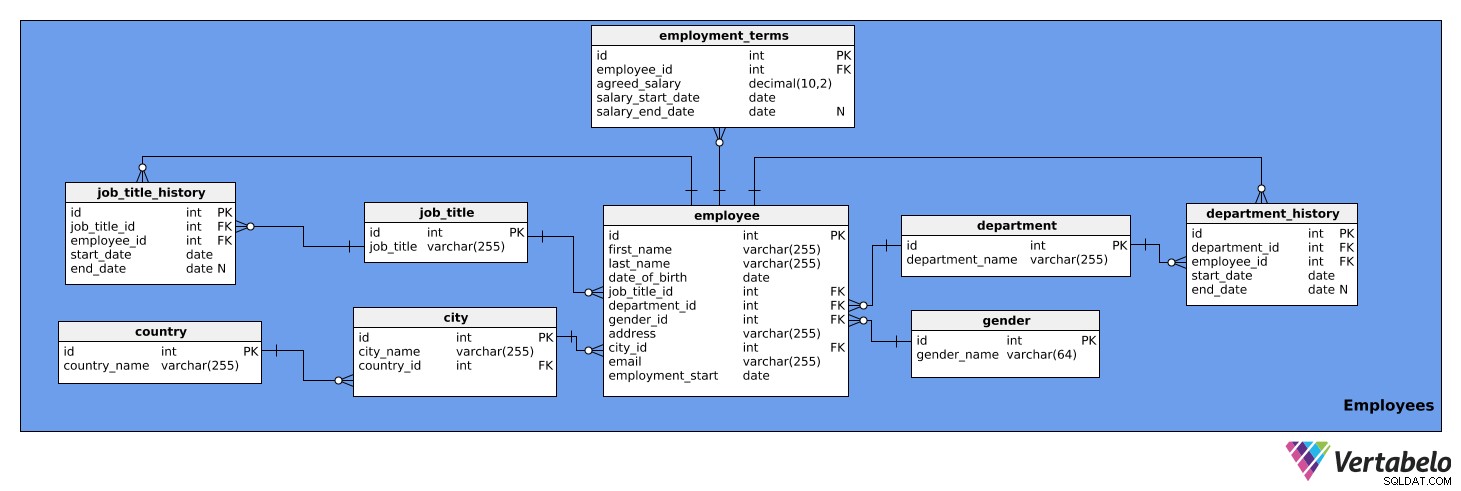
Dit onderwerpgebied bevat gedetailleerde informatie over medewerkers. Het bestaat uit negen tabellen:
employeeemployment_termsjob_titlejob_title_historydepartmentdepartment_historycitycountrygender
De eerste tabel die we bekijken is de employee tafel. Het bevat een lijst van alle medewerkers en hun relevante gegevens. De kenmerken van de tabel zijn:
id– Een unieke ID voor elke medewerker.first_name– De voornaam van de medewerker.last_name– De achternaam van de werknemer.job_title_id– Verwijst naar dejob_titletafel.department_id– Verwijst naar dedepartmenttafel.gender_id– Verwijst naar hetgendertafel.address– Het adres van de werknemer.city_id– Verwijst naar decitytafel.email– Het e-mailadres van de medewerker.employment_start– De datum waarop het dienstverband van deze persoon is begonnen.
Merk op dat de kolommen job_title_id en department_id zijn overbodig, omdat de informatie over huidige functietitels en afdelingen toegankelijk is via de job_title_history en department_history tafels. We zullen deze twee kolommen echter in deze tabel behouden voor snellere toegang tot de informatie.
Het volgende is de employment_terms tafel. Het slaat gegevens op over het salaris van elke werknemer, zoals overeengekomen in de arbeidsovereenkomst, en hoe dit in de loop van de tijd is veranderd. De kenmerken van de tabel zijn:
id– Een unieke ID voor elke set arbeidsvoorwaarden.employee_id– Verwijst naar deemployeetafel.agreed_salary– Het salaris vermeld in de arbeidsovereenkomst.salary_start_date– De startdatum van het overeengekomen salaris.salary_end_date– De einddatum van het overeengekomen salaris. Dit kan NULL zijn omdat een salaris mogelijk geen geplande wijziging heeft.
De job_title tabel is een lijst van de functietitels die aan verschillende werknemers van het bedrijf kunnen worden toegewezen, b.v. analist, chauffeur, secretaresse, directeur, etc. De tabel heeft de volgende attributen:
id– Een unieke ID voor elke functietitel.job_title– De naam van de functietitel. Dit is de alternatieve sleutel.
We hebben ook een tabel nodig om de functiegeschiedenis van elke werknemer op te slaan. We hebben dit nodig omdat medewerkers binnen het bedrijf kunnen worden bevorderd, gedegradeerd of opnieuw kunnen worden toegewezen. De job_title_history tabel zal deze informatie beheren en zal bestaan uit de volgende attributen:
id– Een unieke ID voor de historische vermelding van de functietitel.job_title_id– Verwijst naar dejob_titletafel.employee_id– Verwijst naar deemployeetafel.start_date– De datum waarop de werknemer die functietitel voor het eerst bekleedde.end_date– Wanneer de werknemer die functietitel niet meer heeft. Dit kan NULL zijn omdat de werknemer momenteel die functietitel heeft.
De combinatie van job_title_id , employee_id , en start_date is de alternatieve sleutel voor de bovenstaande tabel. Een werknemer kan op een bepaalde datum slechts één functietitel toegewezen krijgen.
De volgende tabel is de department tafel. Dit geeft een lijst van alle afdelingen van het bedrijf, zoals IT, Boekhouding, Juridisch, enz. Het bevat twee kenmerken:
id– Een unieke ID voor elke afdeling.department_name– De naam van elke afdeling. Dit is de alternatieve sleutel.
Ook kunnen medewerkers van afdeling veranderen binnen het bedrijf. Daarom hebben we een department_history tafel. In deze tabel wordt het volgende opgeslagen:
id– Een unieke ID voor de historische invoer van die afdeling.department_id– Verwijst naar dedepartmenttafel.employee_id– Verwijst naar deemployeetafel.start_date– De datum waarop een medewerker op een afdeling is gaan werken.end_date- De datum waarop een werknemer stopte met werken op die afdeling. Dit kan NULL zijn omdat de werknemer daar nog steeds kan werken.
De combinatie van department_id , employee_id , en start_date is de alternatieve sleutel. Een medewerker kan maar op één afdeling tegelijk werken.
De volgende tabel waar we het over zullen hebben is de city tafel. Dit is een lijst van alle relevante steden. Het heeft de volgende kenmerken:
id– Een unieke ID voor elke stad.city_name– De naam van de stad.country_id– Verwijst naar hetcountrytafel.
Het country tabel is de volgende in ons model. Het is gewoon een lijst met landen en bevat de volgende informatie:
id– Een unieke ID voor elk land.country_name- De naam van het land. Dit is de alternatieve sleutel.
De laatste tabel in dit onderwerpgebied is het gender tafel. Deze tabel geeft een overzicht van alle geslachten. Het bevat de volgende attributen:
id– Een unieke ID voor elk geslacht.gender_name– De naam van het geslacht.
Laten we nu het tweede onderwerpgebied analyseren.
Salarissen
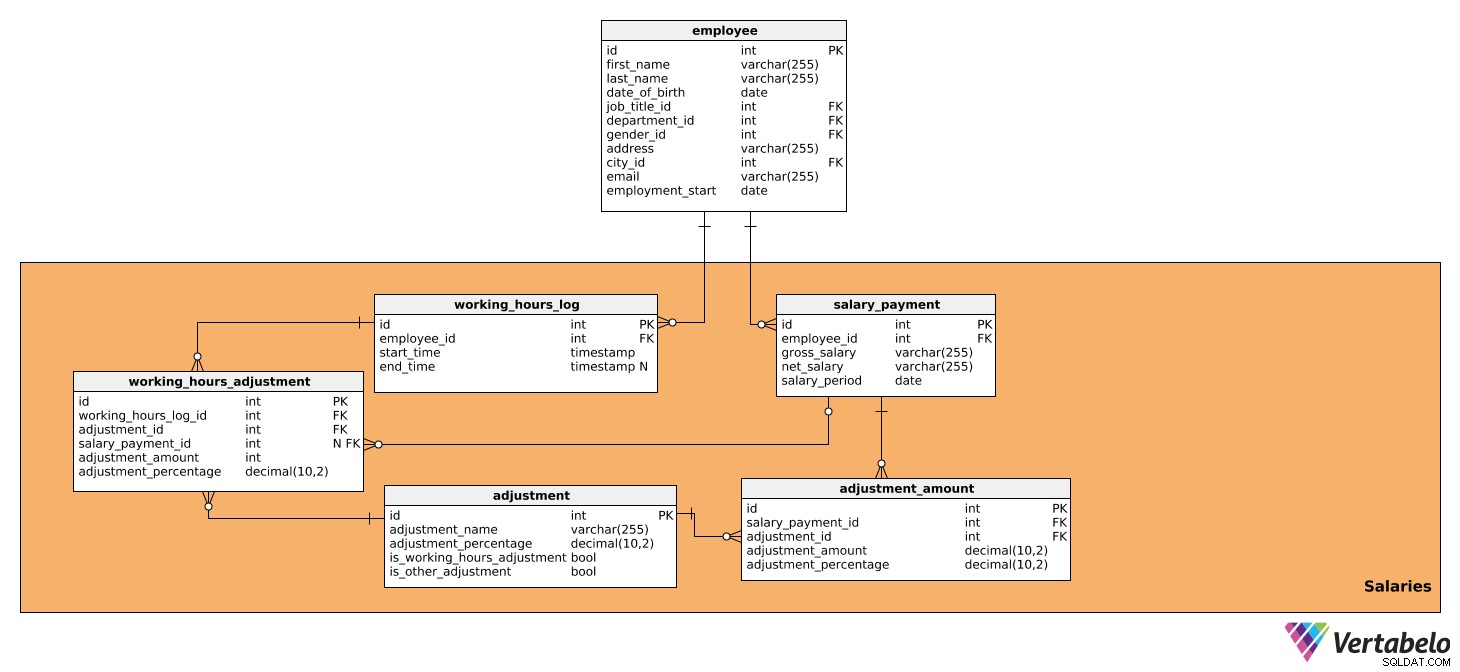
Dit vakgebied bestaat uit tabellen met alle gegevens die direct van invloed zijn op de salarisberekening per periode en het uit te betalen bedrag. Het bestaat uit vijf tabellen:
salary_paymentworking_hours_logworking_hours_adjustmentadjustmentadjustment_amount
Laten we nu naar elke tafel kijken.
De eerste tabel is salary_payment . Het bevat alle relevante details over het salaris dat aan elke werknemer wordt betaald en heeft de volgende kenmerken:
id– Een unieke ID voor elk salaris.employee_id– Verwijst naar deemployeetafel.gross_salary– Het bruto salaris, dat de basis zal zijn voor verdere aanpassingen.net_salary– Het nettoloon (d.w.z. het bedrag dat de werknemer ontvangt na verschillende inhoudingen).salary_period– De periode waarover het salaris wordt berekend en betaald.
Ten tweede is de working_hours_log tafel. Het bevat gegevens over het aantal gewerkte uren per werknemer, wat van invloed kan zijn op bepaalde salarisaanpassingen. Deze tabel heeft de volgende kenmerken:
id– Een unieke ID voor elke logboekinvoer.employee_id– Verwijst naar deemployeetafel.start_time– Het tijdstip waarop de werknemer inlogde, d.w.z. die dag begon te werken.end_time– Wanneer de medewerker is uitgelogd. Het kan NULL zijn omdat we de exacte tijd niet weten totdat de werknemer uitlogt.
De volgende tabel die we zullen analyseren is working_hours_adjustment . Deze tabel wordt alleen gebruikt bij de berekening van aanpassingen op basis van de gewerkte uren, d.w.z. de uren die een TRUE-waarde hebben in is_working_hours_adjustment in de adjustment tafel. De attributen zijn als volgt:
id– Een unieke ID voor elke aanpassing.working_hours_log_id– Verwijst naar deworking_hours_logtafel.adjustment_id- Verwijst naar deadjustmenttafel.salary_payment_id– Verwijst naar desalary_paymenttafel. Deze waarde kan NULL zijn omdatsalary_payment_idwordt slechts één keer per maand gebruikt, wanneer we een salarisberekening starten.adjustment_amount– Het bedrag van de aanpassing.adjustment_percentage– Het procentuele bedrag van de aanpassing. Dit wordt gebruikt voor historische doeleinden, aangezien het percentage in de loop van de tijd kan veranderen.
De volgende tabel waar we het over zullen hebben is de adjustment tafel. Het bevat informatie over alle aanpassingen die worden gebruikt voor de salarisberekening, dus alle belastingen en premies die van invloed zijn op het salaris. Ook staan er alle aanpassingen in die afhankelijk zijn van gewerkte en niet gewerkte uren, zoals toeslagen, overwerk, ziekteverlof en zwangerschaps-/vaderschapsverlof. Daarvoor hebben we de volgende gegevens nodig:
id– Een unieke ID voor elke aanpassing.adjustment_name– Een naam die die aanpassing beschrijft.adjustment_percentage– Het percentage van de specifieke aanpassing.is_working_hours_adjustment– Dit is een vlagmarkering als een aanpassing direct afhankelijk is van werktijden, b.v. overwerk, ziekteverlof, enz.is_other_adjustment– Dit is een vlag die aanpassingen markeert die niet . zijn rechtstreeks afhankelijk zijn van gewerkte uren, zoals belastingaftrek, socialezekerheidsbijdragen, werkgeversbijdragen, enz.
Daarna hebben we de adjustment_amount tafel. Het wordt gebruikt om alle salarisaanpassingen te berekenen, behalve die al in de working_hours_adjustment , d.w.z. die met een TRUE-waarde in is_other_adjustment in de adjustment tafel. De tabel bevat de volgende attributen:
id– Een unieke ID voor elke invoer van het aanpassingsbedrag.salary_payment_id– Verwijst naar desalary_paymenttafel.adjustment_id– Verwijst naar deadjustmenttafel.adjustment_amount– Het bedrag van elke berekende aanpassing.adjustment_percentage- Het procentuele bedrag van de aanpassing. Het wordt gebruikt voor historische doeleinden, aangezien het percentage in de loop van de tijd kan veranderen.
Laat me je een voorbeeld geven van hoe de tabellen working_hours_log , working_hours_adjustment , adjustment , en adjustment_amount samenwerken om een salaris te berekenen. Elke dag registreert de medewerker wanneer hij of zij op het werk aankomt en wanneer hij of zij vertrekt. Deze gegevens zijn te zien in de working_hours_log tafel. Laten we zeggen dat onze werknemer een maand lang 10 uur overwerk heeft gemaakt en dat hij of zij volgens het beleid van het bedrijf 20% meer per uur zal krijgen voor elk uur overwerk. Door te verwijzen naar de adjustment tabel, zullen we de vereiste aanpassing kunnen vinden, d.w.z. overwerk, dat een bepaald percentage zal hebben (20%). We hebben ook is_working_hours_adjustment ingesteld op WAAR. Door gegevens uit die twee tabellen te gebruiken, kunnen we de aanpassing berekenen en opslaan in de working_hours_adjustment tafel.
Nu kunnen we alle andere aanpassingen berekenen die niet afhankelijk van de gewerkte uren. Dit wordt gedaan in de adjustment_amount tafel. Net zoals we hierboven hebben gedaan, verwijzen we naar de adjustment tabel en zoek de aanpassingen die we nodig hebben - b.v. belastingaftrek, socialezekerheidsbijdrage of werkgeversbijdrage - en de relevante percentages. De is_other_adjustment markering in de adjustment tabel wordt ingesteld op TRUE voor deze aanpassingen.
Op basis van die berekeningen kunnen we bruto- en nettoloongegevens opslaan in de salary_payment tafel.
Door dit voorbeeld door te nemen, hebben we alles in ons gegevensmodel behandeld!
Vind je het Payroll Data Model leuk?
Ik heb geprobeerd een model te maken dat in bijna alle situaties kan worden gebruikt. Het is echter onmogelijk om in een artikel van deze lengte alle specifieke parameters die van invloed zijn op de loonberekening op te nemen. Door algemene principes te behandelen, heb ik geprobeerd dit model nuttig te maken als een solide basis voor uw salarisgegevensmodel.
Wat vindt u van het salarisgegevensmodel? Is het toepasbaar als oplossing voor uw salariswensen? Heb je iets anders bedacht? Zijn er specifieke problemen die u hebt gevonden die het gegevensmodel aanzienlijk zouden veranderen? Laat je mening horen in de comments.