Een veelvoorkomend scenario in veel client-servertoepassingen is dat de eindgebruiker de sorteervolgorde van de resultaten kan dicteren. Sommige mensen willen eerst de laagst geprijsde artikelen zien, sommigen willen eerst de nieuwste artikelen zien en sommigen willen ze alfabetisch zien. Dit is een complexe zaak om te bereiken in Transact-SQL, omdat je niet zomaar kunt zeggen:
PROCEDURE MAKEN dbo.SortOnSomeTable @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'ASBEGIN ... ORDER BY @SortColumn; -- of ... BESTEL DOOR @SortColumn @SortDirection;ENDGO
Dit komt omdat T-SQL geen variabelen toestaat op deze locaties. Als u alleen @SortColumn gebruikt, ontvangt u:
Msg 1008, Level 16, State 1, Line xHet SELECT-item dat wordt geïdentificeerd door het ORDER BY-nummer 1 bevat een variabele als onderdeel van de expressie die een kolompositie identificeert. Variabelen zijn alleen toegestaan bij het ordenen op een uitdrukking die verwijst naar een kolomnaam.
(En als het foutbericht zegt:"een uitdrukking die verwijst naar een kolomnaam", vindt u het misschien dubbelzinnig, en ik ben het ermee eens. Maar ik kan u verzekeren dat dit niet betekent dat een variabele een geschikte uitdrukking is.)
Als u @SortDirection probeert toe te voegen, is de foutmelding iets ondoorzichtiger:
Msg 102, Level 15, State 1, Line xOnjuiste syntaxis bij '@SortDirection'.
Er zijn een paar manieren om dit te omzeilen, en je eerste instinct zou kunnen zijn om dynamische SQL te gebruiken, of om de CASE-expressie te introduceren. Maar zoals met de meeste dingen, zijn er complicaties die je op de een of andere manier kunnen dwingen. Dus welke moet je gebruiken? Laten we eens kijken hoe deze oplossingen kunnen werken en de impact op de prestaties vergelijken voor een paar verschillende benaderingen.
Voorbeeldgegevens
Met behulp van een catalogusweergave die we waarschijnlijk allemaal heel goed begrijpen, sys.all_objects, heb ik de volgende tabel gemaakt op basis van een cross join, waarbij ik de tabel beperkte tot 100.000 rijen (ik wilde gegevens die veel pagina's vulden, maar dat niet veel tijd kostte om te zoeken en test):
DATABASE MAKEN OrderBy;GOUSE OrderBy;GO SELECT TOP (100000) key_col =ROW_NUMBER() OVER (ORDER BY s1.[object_id]), -- een BIGINT met geclusterde index s1.[object_id], -- een INT zonder een indexnaam =s1.name -- een NVARCHAR met een ondersteunende index COLLATE SQL_Latin1_General_CP1_CI_AS, type_desc =s1.type_desc -- een NVARCHAR(60) zonder een index COLLATE SQL_Latin1_General_CP1_CI_AS, s1.modify_date -- een datetime zonder een indexsyINTO d sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2ORDER BY s1.[object_id];
(De truc COLLATE is omdat veel catalogusweergaven verschillende kolommen met verschillende sorteringen hebben, en dit zorgt ervoor dat de twee kolommen overeenkomen voor de doeleinden van deze demo.)
Vervolgens heb ik voorafgaand aan de optimalisatie een typisch geclusterd / niet-geclusterd indexpaar gemaakt dat mogelijk op een dergelijke tabel bestaat (ik kan object_id niet gebruiken voor de sleutel, omdat de cross-join duplicaten creëert):
CREER UNIEKE GECLUSTERDE INDEX key_col OP dbo.sys_objects(key_col); MAAK INDEX-naam OP dbo.sys_objects(name);
Gebruiksvoorbeelden
Zoals hierboven vermeld, willen gebruikers deze gegevens misschien op verschillende manieren geordend zien, dus laten we enkele typische gebruiksscenario's uiteenzetten die we willen ondersteunen (en met ondersteuning bedoel ik demonstreren):
- Geordend op key_col oplopend ** standaard als het de gebruiker niet kan schelen
- Geordend op object_id (oplopend/aflopend)
- Geordend op naam (oplopend/aflopend)
- Geordend op type_desc (oplopend/aflopend)
- Geordend op wijzigingsdatum (oplopend/aflopend)
We laten de key_col-volgorde als standaard, omdat deze het meest efficiënt zou moeten zijn als de gebruiker geen voorkeur heeft; aangezien de key_col een willekeurige surrogaat is die niets mag betekenen voor de gebruiker (en er misschien zelfs niet aan wordt blootgesteld), is er geen reden om omgekeerde sortering op die kolom toe te staan.
Benaderingen die niet werken
De meest gebruikelijke benadering die ik zie wanneer iemand dit probleem voor het eerst begint aan te pakken, is het introduceren van control-of-flow-logica in de query. Ze verwachten dit te kunnen:
SELECT key_col, [object_id], name, type_desc, modified_dateFROM dbo.sys_objectsORDER BY IF @SortColumn ='key_col' key_colIF @SortColumn ='object_id' [object_id]IF @SortColumn ='name' naam...IF @SortDirection ='ASC' ASCELSE DESC;
Dit werkt duidelijk niet. Vervolgens zie ik dat CASE onjuist wordt geïntroduceerd, met een vergelijkbare syntaxis:
SELECT key_col, [object_id], name, type_desc, modified_dateFROM dbo.sys_objectsORDER BY CASE @SortColumn WHEN 'key_col' THEN key_col WHEN 'object_id' THEN [object_id] WHEN 'name' THEN naam ... END CASE @SortDirection WHEN 'ASC' DAN ASC ANDERS OMLAAG EINDE;
Dit is dichterbij, maar het mislukt om twee redenen. Een daarvan is dat CASE een expressie is die precies één waarde van een specifiek gegevenstype retourneert; dit voegt gegevenstypen samen die incompatibel zijn en zal daarom de CASE-expressie verbreken. De andere is dat er geen manier is om de sorteerrichting op deze manier voorwaardelijk toe te passen zonder dynamische SQL te gebruiken.
Benaderingen die wel werken
De drie belangrijkste benaderingen die ik heb gezien zijn als volgt:
Groep compatibele typen en routebeschrijvingen samen
Om CASE te gebruiken met ORDER BY, moet er een aparte uitdrukking zijn voor elke combinatie van compatibele typen en richtingen. In dit geval zouden we zoiets als dit moeten gebruiken:
PROCEDURE MAKEN dbo.Sort_CaseExpanded @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'ASBEGIN STEL NOCOUNT IN; SELECT key_col, [object_id], name, type_desc, wijzigingsdatum VAN dbo.sys_objects ORDER BY CASE WHEN @SortDirection ='ASC' THEN CASE @SortColumn WHEN 'key_col' THEN key_col WHEN 'object_id' THEN [object_id] CASE END END , SortDirection ='DESC' THEN CASE @SortColumn WHEN 'key_col' THEN key_col WHEN 'object_id' THEN [object_id] END END DESC, CASE WHEN @SortDirection ='ASC' THEN CASE @SortColumn WHEN 'name' THEN name 'THEN 'type_desc' type_desc END END, CASE WHEN @SortDirection ='DESC' THEN CASE @SortColumn WHEN 'name' THEN name WHEN 'type_desc' THEN type_desc END END DESC, CASE WHEN @SortColumn ='modify_date' AND @Sortdate END THEN ='ASCdate , CASE WHEN @SortColumn ='modify_date' AND @SortDirection ='DESC' THEN wijzigingsdatum END DESC;END
Je zou kunnen zeggen, wauw, dat is een lelijk stukje code, en ik ben het met je eens. Ik denk dat dit de reden is waarom veel mensen hun gegevens op de front-end cachen en de presentatielaag het in verschillende volgordes laten jongleren. :-)
Je kunt deze logica een beetje verder samenvouwen door alle niet-tekenreekstypen om te zetten in tekenreeksen die correct zullen sorteren, bijvoorbeeld
PROCEDURE MAKEN dbo.Sort_CaseCollapsed @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'ASBEGIN STEL NOCOUNT IN; SELECT key_col, [object_id], naam, type_desc, wijzigingsdatum VAN dbo.sys_objects ORDER BY CASE WHEN @SortDirection ='ASC' THEN CASE @SortColumn WHEN 'key_col' THEN RIGHT('000000000000' + RTRIM(key_col), 12) WHEN ' object_id' THEN RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0') + REPLICATE('0', 23) + RTRIM([object_id]), 24) WHEN 'name' THEN naam WHEN 'type_desc' THEN type_desc WHEN 'modify_date' THEN CONVERT(CHAR(19), wijzigingsdatum, 120) END END, CASE WHEN @SortDirection ='DESC' THEN CASE @SortColumn WHEN 'key_col' THEN RIGHT(' 000000000000' + RTRIM(key_col), 12) WHEN 'object_id' THEN RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0') + REPLICATE('0', 23 ) + RTRIM([object_id]), 24) WHEN 'name' THEN naam WHEN 'type_desc' THEN type_desc WHEN 'modify_date' THEN CONVERT(CHAR(19), wijzigingsdatum, 120) END END DESC;END Toch is het een behoorlijk lelijke puinhoop, en je moet de uitdrukkingen twee keer herhalen om met de verschillende sorteerrichtingen om te gaan. Ik vermoed ook dat het gebruik van OPTION RECOMPILE voor die query zou voorkomen dat je wordt gestoken door het snuiven van parameters. Behalve in het standaardgeval, is het niet zo dat het grootste deel van het werk dat hier wordt gedaan, compilatie zal zijn.
Een rang toepassen met behulp van vensterfuncties
Ik ontdekte deze handige truc van AndriyM, hoewel het het meest nuttig is in gevallen waarin alle potentiële volgordekolommen van compatibele typen zijn, anders is de uitdrukking die wordt gebruikt voor ROW_NUMBER() even complex. Het slimste is dat we, om te wisselen tussen oplopende en aflopende volgorde, het ROW_NUMBER() vermenigvuldigen met 1 of -1. We kunnen het in deze situatie als volgt toepassen:
PROCEDURE MAKEN dbo.Sort_RowNumber @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'ASBEGIN STEL NOCOUNT IN;;WITH x AS ( SELECT key_col, [object_id], name, type_desc, wijzigingsdatum, rn =ROW_NUMBER() OVER ( ORDER BY CASE @SortColumn WHEN 'key_col' THEN RIGHT('000000000000' + RTRIM(key_col), 12) WHEN ' object_id' THEN RIGHT(COALESCE(NULLIF(LEFT(RTRIM([object_id]),1),'-'),'0') + REPLICATE('0', 23) + RTRIM([object_id]), 24) WHEN 'name' THEN naam WHEN 'type_desc' THEN type_desc WHEN 'modify_date' THEN CONVERT(CHAR(19), modified_date, 120) END ) * CASE @SortDirection WHEN 'ASC' THEN 1 ELSE -1 END FROM dbo.sys_objects ) SELECT key_col , [object_id], naam, type_desc, wijzigingsdatum FROM x ORDER BY rn;ENDGO Nogmaals, OPTION RECOMPILE kan hier helpen. Ook zult u in sommige van deze gevallen merken dat banden verschillend worden behandeld door de verschillende plannen - wanneer u bijvoorbeeld op naam bestelt, ziet u meestal key_col in oplopende volgorde binnen elke set dubbele namen verschijnen, maar u kunt ook zien de waarden door elkaar. Om meer voorspelbaar gedrag te bieden in het geval van gelijkspel, kunt u altijd een extra ORDER BY-clausule toevoegen. Merk op dat als u key_col aan het eerste voorbeeld zou toevoegen, u er een expressie van moet maken zodat key_col niet tweemaal in de ORDER BY wordt vermeld (u kunt dit bijvoorbeeld doen met key_col + 0).
Dynamische SQL
Veel mensen hebben bedenkingen bij dynamische SQL - het is onmogelijk om te lezen, het is een voedingsbodem voor SQL-injectie, het leidt tot een opgeblazen plancache, het gaat voorbij aan het doel van het gebruik van opgeslagen procedures... Sommige hiervan zijn gewoon onwaar, en andere zijn gemakkelijk te verminderen. Ik heb hier wat validatie toegevoegd die net zo goed aan een van de bovenstaande procedures kan worden toegevoegd:
PROCEDURE MAKEN dbo.Sort_DynamicSQL @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'ASBEGIN STEL NOCOUNT IN; -- weiger ongeldige sorteerrichtingen:IF UPPER(@SortDirection) NOT IN ('ASC','DESC') BEGIN RAISERROR('Ongeldige parameter voor @SortDirection:%s', 11, 1, @SortDirection); RETOUR -1; END -- verwerp alle onverwachte kolomnamen:IF LOWER(@SortColumn) NOT IN (N'key_col', N'object_id', N'name', N'type_desc', N'modify_date') BEGIN RAISERROR('Ongeldige parameter voor @SortColumn:%s', 11, 1, @SortColumn); RETOUR -1; EINDE SET @SortColumn =QUOTENAME(@SortColumn); VERKLAREN @sql NVARCHAR(MAX); SET @sql =N'SELECT key_col, [object_id], naam, type_desc, wijzigingsdatum VAN dbo.sys_objects ORDER BY ' + @SortColumn + ' ' + @SortDirection + ';'; EXEC sp_executesql @sql;END Prestatievergelijkingen
Ik heb voor elke bovenstaande procedure een in de wrapper opgeslagen procedure gemaakt, zodat ik gemakkelijk alle scenario's kon testen. De vier wrapper-procedures zien er als volgt uit, waarbij de naam van de procedure natuurlijk varieert:
PROCEDURE MAKEN dbo.Test_Sort_CaseExpandedASBEGIN STEL NOCOUNT IN; EXEC dbo.Sort_CaseExpanded; -- standaard EXEC dbo.Sort_CaseExpanded N'name', 'ASC'; EXEC dbo.Sort_CaseExpanded N'name', 'DESC'; EXEC dbo.Sort_CaseExpanded N'object_id', 'ASC'; EXEC dbo.Sort_CaseExpanded N'object_id', 'DESC'; EXEC dbo.Sort_CaseExpanded N'type_desc', 'ASC'; EXEC dbo.Sort_CaseExpanded N'type_desc', 'DESC'; EXEC dbo.Sort_CaseExpanded N'modify_date', 'ASC'; EXEC dbo.Sort_CaseExpanded N'modify_date', 'DESC';END
En toen ik SQL Sentry Plan Explorer gebruikte, genereerde ik daadwerkelijke uitvoeringsplannen (en de bijbehorende statistieken) met de volgende vragen, en herhaalde ik het proces 10 keer om de totale duur samen te vatten:
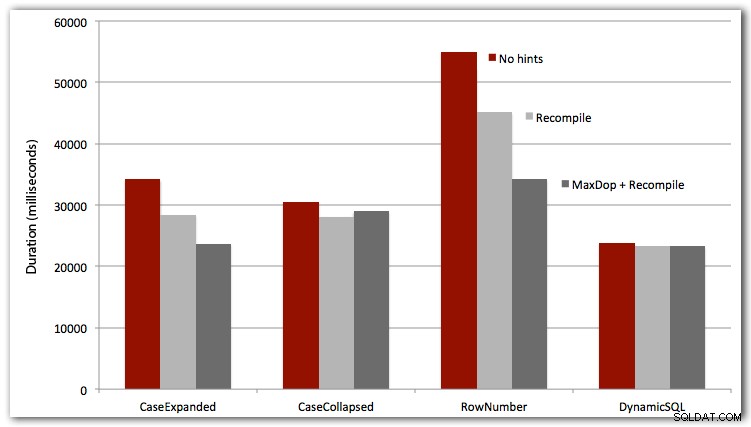
DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;EXEC dbo.Test_Sort_CaseExpanded;--EXEC dbo.Test_Sort_CaseCollapsed;--EXEC dbo.Test_Sort_RowNumber>--EXEC dbo.Test_SortQ; Ik heb ook de eerste drie gevallen getest met OPTIE RECOMPILE (heeft niet veel zin voor het dynamische SQL-geval, omdat we weten dat het elke keer een nieuw plan zal zijn), en alle vier gevallen met MAXDOP 1 om parallellisme-interferentie te elimineren. Dit zijn de resultaten:
Conclusie
Voor regelrechte prestaties wint dynamische SQL elke keer (hoewel slechts met een kleine marge op deze dataset). De ROW_NUMBER()-aanpak, hoewel slim, was de verliezer in elke test (sorry AndriyM).
Het wordt nog leuker als je een WHERE-clausule wilt introduceren, laat staan paging. Deze drie zijn als de perfecte storm om complexiteit te introduceren in wat begint als een eenvoudige zoekopdracht. Hoe meer permutaties uw query heeft, hoe groter de kans dat u de leesbaarheid uit het raam wilt gooien en dynamische SQL wilt gebruiken in combinatie met de instelling "optimaliseren voor ad-hocworkloads" om de impact van plannen voor eenmalig gebruik in uw plancache te minimaliseren.