De kwaliteit van een uitvoeringsplan is sterk afhankelijk van de nauwkeurigheid van het geschatte aantal rijen dat door elke planoperator wordt uitgevoerd. Als het geschatte aantal rijen aanzienlijk afwijkt van het werkelijke aantal rijen, kan dit een aanzienlijke invloed hebben op de kwaliteit van het uitvoeringsplan van een query. Een slechte plankwaliteit kan verantwoordelijk zijn voor overmatige I/O, opgeblazen CPU, geheugendruk, verminderde doorvoer en verminderde algehele gelijktijdigheid.
Met "plankwaliteit" bedoel ik dat SQL Server een uitvoeringsplan genereert dat resulteert in keuzes van de fysieke operator die de huidige staat van de gegevens weerspiegelen. Door dergelijke beslissingen te nemen op basis van nauwkeurige gegevens, is de kans groter dat de zoekopdracht correct wordt uitgevoerd. De kardinaliteitsschattingswaarden worden gebruikt als input voor de operatorkosten, en wanneer de waarden te ver van de werkelijkheid af liggen, kan de negatieve impact op het uitvoeringsplan uitgesproken worden. Deze schattingen worden doorgegeven aan de verschillende kostenmodellen die aan de query zelf zijn gekoppeld, en schattingen van slechte rijen kunnen van invloed zijn op een verscheidenheid aan beslissingen, waaronder indexselectie, zoek- versus scanbewerkingen, parallelle versus seriële uitvoering, selectie van join-algoritmen, interne versus externe fysieke join selectie (bijv. build versus probe), spoolgeneratie, bladwijzerzoekopdrachten versus volledige geclusterde of heaptabeltoegang, stream- of hash-aggregatieselectie en of een gegevenswijziging al dan niet een breed of smal plan gebruikt.
Laten we als voorbeeld zeggen dat u de volgende SELECT . hebt query (met behulp van de Credit-database):
SELECT m.member_no, m.lastname, p.payment_no, p.payment_dt, p.payment_amt FROM dbo.member AS m INNER JOIN dbo.payment AS p ON m.member_no = p.member_no;
Is, op basis van de querylogica, de volgende vorm van het plan wat u zou verwachten te zien?
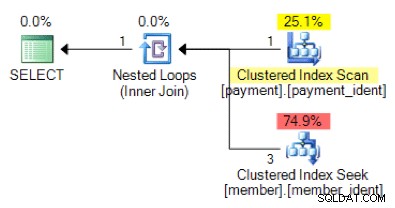
En hoe zit het met dit alternatieve plan, waar we in plaats van een geneste lus een hash-overeenkomst hebben?
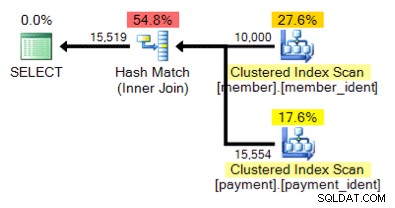
Het "juiste" antwoord is afhankelijk van een paar andere factoren, maar een belangrijke factor is het aantal rijen in elk van de tabellen. In sommige gevallen is het ene fysieke join-algoritme geschikter dan het andere - en als de aanvankelijke aannames voor kardinaliteitsschattingen niet correct zijn, gebruikt uw zoekopdracht mogelijk een niet-optimale benadering.
Identificeren kardinaliteit schatting problemen is relatief eenvoudig. Als u een daadwerkelijk uitvoeringsplan heeft, kunt u de geschatte versus daadwerkelijke rijtellingswaarden voor operators vergelijken en scheeftrekkingen zoeken. SQL Sentry Plan Explorer vereenvoudigt deze taak door u in staat te stellen werkelijke versus geschatte rijen voor alle operators te zien in een enkel planboomtabblad in plaats van de individuele operators in het grafische plan te moeten aanwijzen:

Scheefheid leidt niet altijd tot plannen van slechte kwaliteit, maar als je prestatieproblemen hebt met een zoekopdracht en je ziet zulke scheeftrekkingen in het plan, dan is dit een gebied dat nader onderzoek waard is.
Identificatie van problemen met kardinaliteitsschattingen is relatief eenvoudig, maar de oplossing is dat vaak niet. Er zijn een aantal hoofdoorzaken waarom problemen met kardinaliteitsschattingen kunnen optreden, en ik zal tien van de meest voorkomende redenen in dit bericht behandelen.
Ontbrekende of verouderde statistieken
Van alle redenen voor problemen met kardinaliteitsschattingen, is dit degene die u hoopt om te zien, omdat het vaak het gemakkelijkst aan te pakken is. In dit scenario ontbreken uw statistieken of zijn ze verouderd. Mogelijk hebt u database-opties voor het automatisch aanmaken en bijwerken van statistieken uitgeschakeld, "niet opnieuw berekend" ingeschakeld voor specifieke statistieken, of heeft u tabellen die groot genoeg zijn zodat uw automatische statistische updates gewoon niet vaak genoeg plaatsvinden.
Problemen met steekproeven
Het kan zijn dat de nauwkeurigheid van het statistische histogram onvoldoende is, bijvoorbeeld als u een zeer grote tabel heeft met significante en/of frequente scheeftrekkingen in de gegevens. Mogelijk moet u uw steekproef van de standaardinstelling wijzigen, of als zelfs dat niet helpt, onderzoek dan met behulp van afzonderlijke tabellen, gefilterde statistieken of gefilterde indexen.
Verborgen kolomcorrelaties
De query-optimizer gaat ervan uit dat kolommen binnen dezelfde tabel onafhankelijk zijn. Als u bijvoorbeeld een kolom stad en staat hebt, weten we intuïtief dat deze twee kolommen gecorreleerd zijn, maar SQL Server begrijpt dit niet tenzij we het helpen met een bijbehorende index met meerdere kolommen, of met handmatig gemaakte multi-kolommen. kolom statistieken. Zonder de optimizer te helpen met correlatie, kan de selectiviteit van uw predikaten overdreven zijn.
Hieronder ziet u een voorbeeld van twee gecorreleerde predikaten:
SELECT lastname, firstname FROM dbo.member WHERE city = 'Minneapolis' AND state_prov - 'MN';
Ik weet toevallig dat 10% van onze 10.000 rij member tabel in aanmerking komen voor deze combinatie, maar de query-optimizer vermoedt dat dit 1% van de 10.000 rijen is:
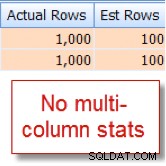
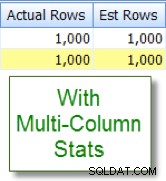
Vergelijk dit nu met de juiste schatting die ik zie na het toevoegen van statistieken met meerdere kolommen:
Kolomvergelijkingen tussen tabellen
Problemen met kardinaliteitsschattingen kunnen optreden bij het vergelijken van kolommen binnen dezelfde tabel. Dit is een bekend probleem. Als u dit moet doen, kunt u de kardinaliteitsschattingen van de kolomvergelijkingen verbeteren door in plaats daarvan berekende kolommen te gebruiken of door de query te herschrijven om self-joins of algemene tabeluitdrukkingen te gebruiken.
Tabel Variabel Gebruik
Veel gebruik van tabelvariabelen? Tabelvariabelen tonen een kardinaliteitsschatting van "1" - wat voor slechts een klein aantal rijen misschien geen probleem is, maar voor grote of vluchtige resultatensets kan dit een aanzienlijke invloed hebben op de kwaliteit van het queryplan. Hieronder ziet u een screenshot van de schatting van een operator van 1 rij versus de werkelijke 1.600.000 rijen van de @charge tabelvariabele:

Als dit uw hoofdoorzaak is, doet u er goed aan om waar mogelijk alternatieven zoals tijdelijke tabellen en/of permanente verzameltabellen te onderzoeken.
Scalaire en MSTV UDF's
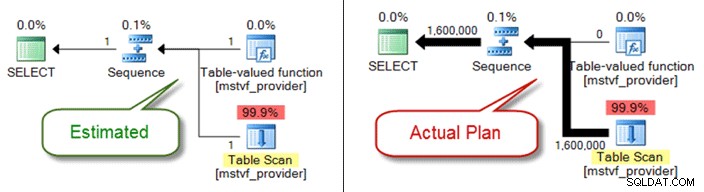
Net als bij tabelvariabelen, zijn multi-statement tabelwaarden en scalaire functies een black-box vanuit het perspectief van kardinaliteitsschatting. Als u hierdoor problemen ondervindt met de kwaliteit van uw plannen, overweeg dan om inline tabelfuncties als alternatief te gebruiken, of u kunt zelfs de functiereferentie volledig verwijderen en alleen rechtstreeks naar objecten verwijzen.
Hieronder ziet u een geschat versus werkelijk plan bij gebruik van een functie met tabelwaarde met meerdere verklaringen:
Problemen met gegevenstype
Impliciete problemen met gegevenstypes in combinatie met zoek- en deelnamevoorwaarden kunnen problemen met kardinaliteitsschattingen veroorzaken. Ze kunnen ook heimelijk vreten aan bronnen op serverniveau (CPU, I/O, geheugen), dus het is belangrijk om ze waar mogelijk aan te pakken.
Complexe predikaten
Je hebt dit patroon waarschijnlijk eerder gezien - een zoekopdracht met een WHERE clausule waarin elke tabelkolomverwijzing is verpakt in verschillende functies, aaneenschakelingsbewerkingen, wiskundige bewerkingen en meer. En hoewel niet alle functieomloop de juiste kardinaliteitsschattingen uitsluit (zoals voor LOWER , UPPER en GETDATE ) er zijn tal van manieren om uw predikaat te begraven tot het punt dat de query-optimizer geen nauwkeurige schattingen meer kan maken.
Complexiteit van zoekopdrachten
Zijn uw vragen, net als begraven predikaten, buitengewoon complex? Ik realiseer me dat 'complex' een subjectieve term is en dat uw beoordeling kan verschillen, maar de meesten zijn het erover eens dat het nesten van weergaven binnen weergaven binnen weergaven die verwijzen naar overlappende tabellen waarschijnlijk niet optimaal is, vooral in combinatie met meer dan 10 tabelkoppelingen, functieverwijzingen en begraven predikaten. Hoewel de query-optimizer bewonderenswaardig werk doet, is het geen magie, en als je aanzienlijke scheeftrekkingen hebt, kan de complexiteit van de query (Zwitserse zakmes-query's) het zeker bijna onmogelijk maken om nauwkeurige rijschattingen voor operators af te leiden.
Gedistribueerde zoekopdrachten
Gebruikt u gedistribueerde zoekopdrachten met gekoppelde servers en ziet u aanzienlijke problemen met kardinaliteitsschattingen? Als dit het geval is, controleer dan de machtigingen die zijn gekoppeld aan de gekoppelde server-principal die wordt gebruikt om toegang te krijgen tot de gegevens. Zonder het minimum db_ddladmin vaste databaserol voor het gekoppelde serveraccount, dit gebrek aan zichtbaarheid van externe statistieken vanwege onvoldoende machtigingen kan de oorzaak zijn van uw kardinaliteitsschattingsproblemen.
En er zijn er nog...
Er zijn nog andere redenen waarom kardinaliteitsschattingen scheef kunnen zijn, maar ik geloof dat ik de meest voorkomende heb behandeld. Het belangrijkste punt is om aandacht te besteden aan de scheeftrekkingen in verband met bekende, slecht presterende zoekopdrachten. Ga er niet vanuit dat het plan is gegenereerd op basis van nauwkeurige rijtellingsvoorwaarden. Als deze cijfers scheef zijn, moet u dit eerst proberen op te lossen.