Mijn collega Steve Wright (blog | @SQL_Steve) prikte me onlangs met een vraag over een vreemd resultaat dat hij zag. Om een aantal functionaliteiten te testen in onze nieuwste tool, SQL Sentry Plan Explorer PRO, had hij een brede en grote tabel gemaakt en voerde hij er verschillende query's op uit. In één geval gaf hij veel gegevens terug, maar STATISTICS IO liet zien dat er maar heel weinig voorlezingen plaatsvonden. Ik heb een paar mensen gepingd op #sqlhelp en aangezien het leek alsof niemand dit probleem had gezien, dacht ik dat ik erover zou bloggen.
TL;DR-versie
Kortom, houd er rekening mee dat er enkele scenario's zijn waarin u niet kunt vertrouwen op STATISTICS IO om je de waarheid te vertellen. In sommige gevallen (deze met TOP en parallellisme), zal het logische metingen enorm onderrapporteren. Dit kan ertoe leiden dat je denkt dat je een zeer I/O-vriendelijke vraag hebt, terwijl dat niet zo is. Er zijn andere, meer voor de hand liggende gevallen, zoals wanneer u een heleboel I/O hebt verborgen door het gebruik van scalaire, door de gebruiker gedefinieerde functies. We denken dat Plan Explorer die gevallen duidelijker maakt; deze is echter een beetje lastiger.
De probleemquery
De tabel heeft 37 miljoen rijen, tot 250 bytes per rij, ongeveer 1 miljoen pagina's en een zeer lage fragmentatie (0,42% op niveau 0, 15% op niveau 1 en 0 daarbuiten). Er zijn geen berekende kolommen, geen UDF's in het spel en geen indexen behalve een geclusterde primaire sleutel op de leidende INT kolom. Een eenvoudige query die 500.000 rijen retourneert, alle kolommen, met behulp van TOP en SELECTEER * :
SET STATISTICS IO ON; SELECT TOP 500000 * FROM dbo.OrderHistory WHERE OrderDate < (SELECT '19961029');
(En ja, ik besef dat ik mijn eigen regels overtreed en SELECT * gebruik en TOP zonder ORDER BY , maar omwille van de eenvoud doe ik mijn best om mijn invloed op de optimizer te minimaliseren.)
Resultaten:
(500000 rij(en) beïnvloed)Tabel 'OrderHistory'. Scan count 1, logische leest 23, fysieke leest 0, read-ahead leest 0, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.
We retourneren 500.000 rijen en het duurt ongeveer 10 seconden. Ik weet meteen dat er iets mis is met het logische leesnummer. Zelfs als ik de onderliggende gegevens niet al wist, kan ik aan de rasterresultaten in Management Studio zien dat dit meer dan 23 pagina's aan gegevens ophaalt, of ze nu uit het geheugen of de cache komen, en dit zou ergens in
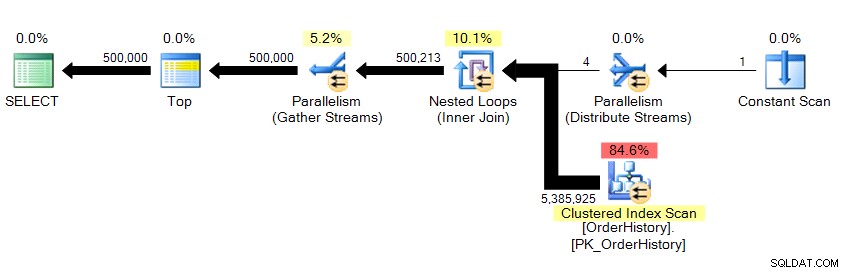
... we zien dat er parallellisme is, en dat we de hele tabel hebben gescand. Dus hoe is het mogelijk dat er maar 23 logische reads zijn?
Nog een "identieke" zoekopdracht
Een van mijn eerste vragen aan Steve was:"Wat gebeurt er als je parallellisme elimineert?" Dus ik probeerde het uit. Ik nam de originele subquery-versie en voegde MAXDOP 1 toe :
SET STATISTICS IO ON; SELECT TOP 500000 * FROM dbo.OrderHistory WHERE OrderDate < (SELECT '19961029') OPTION (MAXDOP 1);
Resultaten en plan:
(500000 rij(en) beïnvloed)Tabel 'OrderHistory'. Scantelling 1, logische leest 149589, fysieke leest 0, read-ahead leest 0, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.
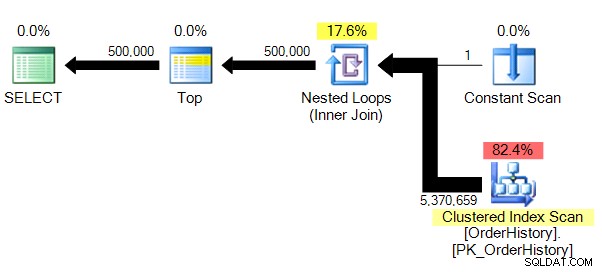
We hebben een iets minder complex plan, en zonder het parallellisme (om voor de hand liggende redenen), STATISTICS IO laat ons veel meer geloofwaardige cijfers zien voor logische leestellingen.
Wat is de waarheid?
Het is niet moeilijk om te zien dat een van deze vragen niet de hele waarheid vertelt. Terwijl STATISTICS IO vertelt ons misschien niet het hele verhaal, misschien doet Trace dat wel. Als we runtime-statistieken ophalen door een daadwerkelijk uitvoeringsplan in Plan Explorer te genereren, zien we dat de magische low-read-query in feite de gegevens uit het geheugen of de schijf haalt, en niet uit een wolk van magisch elfenstof. In feite heeft het *meer* reads dan de andere versie:

Het is dus duidelijk dat er leesacties plaatsvinden, ze verschijnen alleen niet correct in de STATISTICS IO uitvoer.
Wat is het probleem?
Nou, ik zal heel eerlijk zijn:ik weet het niet, behalve het feit dat parallellisme zeker een rol speelt, en het lijkt een soort race-conditie te zijn. STATISTIEKEN IO (en aangezien we daar de gegevens vandaan halen, toont ons tabblad Tabel I/O) een zeer misleidend aantal uitlezingen. Het is duidelijk dat de query alle gegevens retourneert waarnaar we op zoek zijn, en het is duidelijk uit de traceerresultaten dat het reads en geen osmose gebruikt om dit te doen. Ik vroeg Paul White (blog | @SQL_Kiwi) ernaar en hij suggereerde dat slechts enkele van de pre-thread I/O-tellingen in het totaal worden opgenomen (en is het ermee eens dat dit een bug is).
Als je dit thuis wilt uitproberen, heb je alleen AdventureWorks nodig (dit zou moeten overeenkomen met de versies van 2008, 2008 R2 en 2012), en de volgende vraag:
SET STATISTICS IO ON; DBCC SETCPUWEIGHT(1000) WITH NO_INFOMSGS; GO SELECT TOP (15000) * FROM Sales.SalesOrderHeader WHERE OrderDate < (SELECT '20080101'); SELECT TOP (15000) * FROM Sales.SalesOrderHeader WHERE OrderDate < (SELECT '20080101') OPTION (MAXDOP 1); DBCC SETCPUWEIGHT(1) WITH NO_INFOMSGS;
(Merk op dat SETCPUWEIGHT wordt alleen gebruikt om parallellisme over te halen. Zie voor meer informatie de blogpost van Paul White over Plan Costing.)
Resultaten:
Tabel 'Verkooporderkop'. Scan count 1, logische leest 4, fysieke leest 0, read-ahead leest 0, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.Tabel 'SalesOrderHeader'. Scan count 1, logische leest 333, fysieke leest 0, read-ahead leest 0, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.
Paul wees op een nog eenvoudiger repro:
SET STATISTICS IO ON; GO SELECT TOP (15000) * FROM Production.TransactionHistory WHERE TransactionDate < (SELECT '20080101') OPTION (QUERYTRACEON 8649, MAXDOP 4); SELECT TOP (15000) * FROM Production.TransactionHistory AS th WHERE TransactionDate < (SELECT '20080101');
Resultaten:
Tabel 'Transactiegeschiedenis'. Scan count 1, logische leest 5, fysieke leest 0, read-ahead leest 0, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.Tabel 'TransactionHistory'. Scan count 1, logische leest 110, fysieke leest 0, read-ahead leest 0, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.
Het lijkt er dus op dat we dit gemakkelijk naar believen kunnen reproduceren met een TOP operator en een laag genoeg DOP. Ik heb een bug ingediend:
- STATISTICS IO rapporteert te weinig logische reads voor parallelle plannen
En Paul heeft twee andere, enigszins gerelateerde bugs met betrekking tot parallellisme ingediend, de eerste als resultaat van ons gesprek:
- Kardinaliteitsschattingsfout met gepusht predikaat bij een zoekopdracht [ gerelateerde blogpost ]
- Slechte prestatie met parallellisme en top [gerelateerde blogpost]
(Voor de nostalgische mensen, hier zijn zes andere parallellisme-bugs waar ik een paar jaar geleden op wees.)
Wat is de les?
Wees voorzichtig met het vertrouwen op één enkele bron. Als je alleen kijkt naar STATISTICS IO na het wijzigen van een zoekopdracht als deze, kom je misschien in de verleiding om je te concentreren op de wonderbaarlijke daling van het aantal reads in plaats van op de toename van de duur. Op dat moment kun je jezelf een schouderklopje geven, vroeg stoppen met werken en genieten van je weekend, denkend dat je zojuist een enorme prestatie-impact op je vraag hebt gemaakt. Terwijl natuurlijk niets minder waar is.