De serializable isolatieniveau biedt volledige bescherming van gelijktijdigheidseffecten die de gegevensintegriteit kunnen bedreigen en tot onjuiste queryresultaten kunnen leiden. Het gebruik van serialiseerbare isolatie betekent dat als een transactie waarvan kan worden aangetoond dat deze de juiste resultaten oplevert zonder gelijktijdige activiteit, deze correct blijft presteren wanneer deze concurreert met een combinatie van gelijktijdige transacties.
Dit is een zeer krachtige garantie , en een die waarschijnlijk overeenkomt met de intuïtieve transactie-isolatieverwachtingen van veel T-SQL-programmeurs (hoewel in werkelijkheid relatief weinig hiervan routinematig serialiseerbare isolatie in productie zullen gebruiken).
De SQL-standaard definieert drie extra isolatieniveaus die een veel zwakkere ACID . bieden isolatiegaranties dan serialiseerbaar, in ruil voor potentieel hogere gelijktijdigheid en minder potentiële bijwerkingen zoals blokkering, deadlocking en afbreken van de vastleggingstijd.
In tegenstelling tot serialiseerbare isolatie, worden de andere isolatieniveaus uitsluitend gedefinieerd in termen van bepaalde gelijktijdigheidsverschijnselen die kunnen worden waargenomen. Het op één na sterkste van de standaard isolatieniveaus na serializable heet herhaalbaar lezen . De SQL-standaard specificeert dat transacties op dit niveau een enkel gelijktijdigheidsfenomeen toestaan dat bekend staat als een fantoom .
Net zoals we eerder belangrijke verschillen hebben gezien tussen de gemeenschappelijke intuïtieve betekenis van ACID-transactie-eigenschappen en de realiteit, omvat het spookverschijnsel een breder scala aan gedragingen dan vaak wordt gewaardeerd.
Dit bericht in de serie kijkt naar de daadwerkelijke garanties die worden geboden door de herhaalbare lees isolatieniveau, en toont enkele van de fantoomgerelateerde gedragingen die kunnen worden aangetroffen. Om enkele punten te illustreren, verwijzen we naar de volgende eenvoudige voorbeeldquery, waarbij de eenvoudige taak is om het totale aantal rijen in een tabel te tellen:
SELECT COUNT_BIG(*) FROM dbo.SomeTable;
Herhaalbaar lezen
Een vreemd ding over het herhaalbare leesisolatieniveau is dat het niet . doet daadwerkelijk garanderen dat reads herhaalbaar zijn , althans in een algemeen begrepen betekenis. Dit is een ander voorbeeld waarbij alleen intuïtieve betekenis misleidend kan zijn. Het tweemaal uitvoeren van dezelfde zoekopdracht binnen dezelfde herhaalbare leestransactie kan inderdaad verschillende resultaten opleveren.
Bovendien betekent de SQL Server-implementatie van herhaalbaar lezen dat een enkele lezing van een set gegevens soms enkele rijen kan missen dat zou logischerwijs in het zoekresultaat moeten worden meegenomen. Hoewel dit onmiskenbaar implementatiespecifiek is, is dit gedrag volledig in overeenstemming met de definitie van herhaalbaar lezen in de SQL-standaard.
Het laatste dat ik snel wil opmerken voordat ik in details ga duiken, is dat herhaalbare read in SQL Server niet bieden een point-in-time weergave van de gegevens.
Niet-herhaalbare lezingen
Het herhaalbare leesisolatieniveau biedt een garantie dat gegevens niet veranderen voor de duur van de transactie nadat deze is gelezen voor de eerste keer.
Er zijn een paar subtiliteiten in die definitie. Ten eerste kunnen gegevens worden gewijzigd na de transactie begint maar voordat de gegevens eerst zijn benaderd. Ten tweede is er geen garantie dat de transactie daadwerkelijk alle gegevens zal tegenkomen die logisch in aanmerking komen. Van beide zullen we binnenkort voorbeelden zien.
Er is nog een andere inleiding die we snel uit de weg moeten ruimen, die te maken heeft met de voorbeeldquery die we zullen gebruiken. Eerlijk gezegd is de semantiek van deze zoekopdracht een beetje vaag. Met het risico een beetje filosofisch te klinken, wat betekent het betekent om het aantal rijen in de tabel te tellen? Moet het resultaat de staat van de tafel weergeven zoals deze op een bepaald moment was? Moet dit tijdstip het begin of het einde van de transactie zijn, of iets anders?
Dit lijkt misschien een beetje kieskeurig, maar de vraag is een geldige vraag in elke database die gelijktijdige gegevenslezingen en -wijzigingen ondersteunt. Het uitvoeren van onze voorbeeldquery kan een willekeurig lange tijd in beslag nemen (gezien een tabel die groot genoeg is, of bijvoorbeeld beperkte middelen), dus gelijktijdige wijzigingen zijn niet alleen mogelijk, ze kunnen ook onvermijdelijk zijn .
Het fundamentele probleem hier is het potentieel voor het gelijktijdigheidsfenomeen waarnaar wordt verwezen als een fantoom in de SQL-standaard. Terwijl we rijen in de tabel tellen, kan een andere gelijktijdige transactie nieuwe rijen invoegen op een plaats die we al hebben gecontroleerd, of wijzig een rij die we nog niet hebben gecontroleerd, zodanig dat deze naar een plaats gaat waar we al hebben gekeken. Mensen denken vaak aan fantomen als rijen die op magische wijze kunnen verschijnen wanneer ze voor een tweede keer worden gelezen, in een afzonderlijke verklaring, maar de effecten kunnen veel subtieler zijn dan dat.
Voorbeeld van gelijktijdig invoegen
Dit eerste voorbeeld laat zien hoe gelijktijdige invoegingen een niet-herhaalbare . kunnen opleveren lezen en/of resulteren in het overslaan van rijen. Stel je voor dat onze testtabel aanvankelijk vijf rijen . bevat met de onderstaande waarden:

We stellen nu het isolatieniveau in op herhaalbaar lezen, starten een transactie en voeren onze telquery uit. Zoals je zou verwachten, is het resultaat vijf . Geen groot mysterie tot nu toe.
Wordt nog steeds uitgevoerd binnen dezelfde herhaalbare lees transactie , voeren we de telquery opnieuw uit, maar deze keer terwijl een tweede gelijktijdige transactie nieuwe rijen in dezelfde tabel invoegt. Het onderstaande diagram toont de volgorde van gebeurtenissen, waarbij de tweede transactie rijen met waarden 2 en 6 toevoegt (je hebt misschien gemerkt dat deze waarden opvielen door hun afwezigheid net erboven):
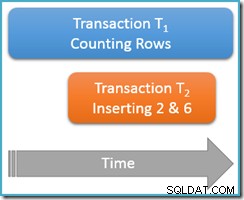
Als onze telquery liep op de serializable isolatieniveau, zou het gegarandeerd zijn om vijf . te tellen of zeven rijen (zie het vorige artikel in deze serie als je een opfriscursus nodig hebt over waarom dat het geval is). Hoe werkt hardlopen op de minder geïsoleerde herhaalbaar leesniveau van invloed op dingen?
Nou, herhaalbare lees isolatie garandeert dat de tweede uitvoering van de telquery alle eerder gelezen rijen zal zien en dat ze in dezelfde staat zullen zijn als voorheen. Het addertje onder het gras is dat herhaalbare leesisolatie niets zegt over hoe de transactie de nieuwe rijen (de fantomen) moet behandelen.
Stel je voor dat onze transactie voor het tellen van rijen (T1 ) heeft een fysieke uitvoeringsstrategie waarbij rijen in oplopende indexvolgorde worden doorzocht. Dit is een veelvoorkomend geval, bijvoorbeeld wanneer een voorwaarts geordende b-tree indexscan wordt gebruikt door de uitvoeringsengine. Nu, net na transactie T1 telt rijen 1 en 3 in oplopende volgorde, transactie T2 kan binnensluipen, nieuwe rijen 2 en 6 invoegen en vervolgens de transactie uitvoeren.
Hoewel we op dit moment vooral aan logisch gedrag denken, moet ik vermelden dat er niets is in de SQL Server-vergrendelingsimplementatie van herhaalbaar lezen om voorkomen transactie T2 van dit te doen. Gedeelde sloten genomen door transactie T1 op eerder gelezen rijen voorkomen dat die rijen worden gewijzigd, maar ze voorkomen niet dat nieuwe rijen worden ingevoegd in het waardenbereik dat is getest door onze telquery (in tegenstelling tot de sleutelbereikvergrendelingen bij het vergrendelen van serialiseerbare isolatie).
Hoe dan ook, met de twee nieuwe rijen vastgelegd, transactie T1 gaat door met zoeken in oplopende volgorde, waarbij hij uiteindelijk rijen 4, 5, 6 en 7 tegenkomt. Merk op dat T1 ziet nieuwe rij 6 in dit scenario, maar niet nieuwe rij 2 (vanwege de geordende zoekopdracht en de positie toen de invoeging plaatsvond).
Het resultaat is dat de herhaalbare lees telquery meldt dat de tabel zes rijen . bevat (waarden 1, 3, 4, 5, 6 en 7). Dit resultaat is niet consistent met het vorige resultaat van vijf rijen verkregen binnen de dezelfde transactie . De tweede lezing telde fantoomrij 6 maar miste fantoomrij 2. Tot zover de intuïtieve betekenis van een herhaalbare lezing!
Voorbeeld van gelijktijdige update
Een vergelijkbare situatie kan zich voordoen met een gelijktijdige update in plaats van een inzet. Stel je voor dat onze testtabel opnieuw wordt ingesteld om dezelfde vijf rijen te bevatten als voorheen:

Deze keer voeren we onze telquery slechts één keer . uit bij de herhaalbare lees isolatieniveau, terwijl een tweede gelijktijdige transactie de rij bijwerkt met waarde 5 om een waarde van 2 te krijgen:
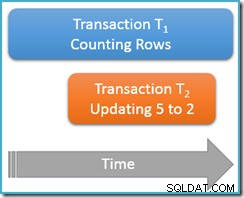
Transactie T1 begint opnieuw met het tellen van rijen, (in oplopende volgorde) waarbij rij 1 en 3 eerst worden tegengekomen. Nu komt transactie T2 binnen, verandert de waarde van rij 5 in 2 en legt vast:

Ik heb de bijgewerkte rij op dezelfde positie als voorheen getoond om de wijziging duidelijk te maken, maar de b-tree-index die we scannen houdt de gegevens in logische volgorde, dus het echte beeld komt hier dichter bij:

Het punt is dat transactie T1 scant tegelijkertijd dezelfde structuur in voorwaartse volgorde, momenteel gepositioneerd net na de invoer voor waarde 3. De telquery gaat verder met scannen vanaf dat punt en vindt rijen 4 en 7 (maar niet rij 5 natuurlijk).
Samenvattend zag de telquery de rijen 1, 3, 4 en 7 in dit scenario. Het rapporteert een telling van vier rijen – wat vreemd is, omdat de tabel vijf rijen lijkt te bevatten overal!
Een tweede uitvoering van de telquery binnen dezelfde herhaalbare leestransactie zou vijf . opleveren rijen, om soortgelijke redenen als voorheen. Als laatste opmerking, voor het geval u zich afvraagt, bieden gelijktijdige verwijderingen geen mogelijkheid voor een fantoom-gebaseerde anomalie onder herhaalbare leesisolatie.
Laatste gedachten
De voorgaande voorbeelden gebruikten beide scans in oplopende volgorde van een indexstructuur om een eenvoudig beeld te geven van het soort effecten dat fantomen kunnen hebben op een herhaalbare leesbare vraag. Het is belangrijk om te begrijpen dat deze illustraties op geen enkele belangrijke manier afhankelijk zijn van de scanrichting of het feit dat een b-tree-index werd gebruikt. Doe alsjeblieft niet vormen de mening dat bestelde scans op de een of andere manier verantwoordelijk zijn en daarom vermeden moeten worden!
Dezelfde gelijktijdigheidseffecten kunnen worden waargenomen bij een aflopende scan van een indexstructuur of in een verscheidenheid aan andere scenario's voor fysieke toegang tot gegevens. Het algemene punt is dat fantoomfenomenen specifiek zijn toegestaan (maar niet vereist) door de SQL-standaard voor transacties op het herhaalbare leesniveau van isolatie.
Niet alle transacties vereisen de volledige isolatiegarantie die wordt geboden door serialiseerbare isolatie, en niet veel systemen zouden de bijwerkingen tolereren als ze dat wel deden. Toch loont het om goed te begrijpen welke garanties de verschillende isolatieniveaus precies bieden.
Volgende keer
Het volgende deel in deze serie kijkt naar de nog zwakkere isolatiegaranties die worden geboden door het standaardisolatieniveau van SQL Server, read commit .
[ Zie de index voor de hele serie ]