Veel productie-T-SQL-code wordt geschreven met de impliciete aanname dat de onderliggende gegevens tijdens de uitvoering niet zullen veranderen. Zoals we in het vorige artikel in deze serie zagen, is dit een onveilige veronderstelling omdat gegevens en indexitems onder ons kunnen bewegen, zelfs tijdens de uitvoering van een enkele instructie.
Waar de T-SQL-programmeur zich bewust is van de soorten correctheids- en gegevensintegriteitsproblemen die kunnen optreden als gevolg van gelijktijdige gegevenswijzigingen door andere processen, is de meest aangeboden oplossing om de kwetsbare verklaringen in een transactie te verpakken. Het is niet duidelijk hoe dezelfde soort redenering zou worden toegepast op het geval met één verklaring, dat standaard al is verpakt in een automatische vastleggingstransactie.
Als we dat even terzijde laten, lijkt het idee om een belangrijk deel van de T-SQL-code te beschermen met een transactie, gebaseerd op een verkeerd begrip van de bescherming die wordt geboden door de ACID-transactie-eigenschappen. Het belangrijke element van dat acroniem voor de huidige discussie is de Isolatie eigendom. Het idee is dat het gebruik van een transactie automatisch volledige isolatie biedt van de effecten van andere gelijktijdige activiteiten.
De waarheid is dat transacties onder SERIALIZABLE geef alleen een graad op van isolatie, die afhangt van het momenteel effectieve isolatieniveau voor transacties. Om te begrijpen wat dit allemaal betekent voor onze dagelijkse T SQL-coderingspraktijken, we zullen eerst gedetailleerd kijken naar het serialiseerbare isolatieniveau.
Serializeerbare isolatie
Serializable is de meest geïsoleerde van de standaard transactie-isolatieniveaus. Het is ook de standaard isolatieniveau gespecificeerd door de SQL-standaard, hoewel SQL Server (zoals de meeste commerciële databasesystemen) in dit opzicht verschilt van de standaard. Het standaard isolatieniveau in SQL Server is read-commit, een lager isolatieniveau dat we later in de serie zullen onderzoeken.
De definitie van het serialiseerbare isolatieniveau in de SQL-92-standaard bevat de volgende tekst (nadruk van mij):
Een serialiseerbare uitvoering wordt gedefinieerd als een uitvoering van de operaties van gelijktijdige uitvoering van SQL-transacties die het hetzelfde effect produceren als sommige seriële uitvoeringen van diezelfde SQL-transacties. Een seriële uitvoering is een uitvoering waarbij elke SQL-transactie volledig wordt uitgevoerd voordat de volgende SQL-transactie begint.
Er moet hier een belangrijk onderscheid worden gemaakt tussen echt geserialiseerde uitvoering (waarbij elke transactie feitelijk uitsluitend wordt voltooid voordat de volgende begint) en serialiseerbaar isolatie, waarbij transacties alleen dezelfde effecten hoeven te hebben alsof ze werden serieel uitgevoerd (in een niet-gespecificeerde volgorde).
Anders gezegd:een echt databasesysteem mag fysiek overlappen de uitvoering van serialiseerbare transacties in de tijd (waardoor de gelijktijdigheid toeneemt) zolang de effecten van die transacties nog steeds overeenkomen met een mogelijke volgorde van seriële uitvoering. Met andere woorden, serialiseerbare transacties zijn mogelijk serialiseerbaar in plaats van eigenlijk geserialiseerd .
Logisch serialiseerbare transacties
Laat alle fysieke overwegingen (zoals vergrendeling) even buiten beschouwing en denk alleen aan de logische verwerking van twee gelijktijdige serialiseerbare transacties.
Overweeg een tabel die een groot aantal rijen bevat, waarvan er vijf voldoen aan een interessant vraagpredikaat. Een serialiseerbare transactie T1 begint met het tellen van het aantal rijen in de tabel dat overeenkomt met dit predikaat. Enige tijd na T1 begint, maar voordat het wordt vastgelegd, een tweede serialiseerbare transactie T2 begint. Transactie T2 voegt vier nieuwe rijen toe die ook voldoen aan het query-predikaat aan de tabel, en commits. Het onderstaande diagram toont de tijdsvolgorde van gebeurtenissen:

De vraag is, hoeveel rijen moet de query in serialiseerbare transactie T1 tellen? Onthoud dat we het hier puur over de logische vereisten hebben, dus denk niet na over welke sloten kunnen worden gebruikt, enzovoort.
De twee transacties overlappen elkaar fysiek in de tijd, wat prima is. Serialiseerbare isolatie vereist alleen dat de resultaten van deze twee transacties overeenkomen met een mogelijke seriële uitvoering. Er zijn duidelijk twee mogelijkheden voor een logisch serieel transactieschema T1 en T2 :
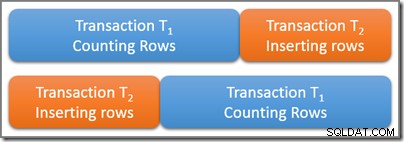
Het eerste mogelijke seriële schema gebruiken (T1 dan T2 ) de T1 tellende zoekopdracht zou vijf rijen bevatten , omdat de tweede transactie pas begint als de eerste is voltooid. Met behulp van het tweede mogelijke logische schema, de T1 zoekopdracht telt negen rijen , omdat het invoegen van vier rijen logisch voltooid was voordat de teltransactie begon.
Beide antwoorden zijn logisch correct onder serialiseerbare isolatie. Bovendien is er geen ander antwoord mogelijk (dus transactie T1 kon bijvoorbeeld geen zeven rijen tellen). Welke van de twee mogelijke resultaten daadwerkelijk wordt waargenomen, hangt af van de precieze timing en een aantal implementatiedetails die specifiek zijn voor de gebruikte database-engine.
Merk op dat we niet concluderen dat de transacties op de een of andere manier op de een of andere manier opnieuw worden besteld. De fysieke uitvoering is vrij om te overlappen, zoals weergegeven in het eerste diagram, zolang de database-engine ervoor zorgt dat de resultaten weerspiegelen wat er zou zijn gebeurd als ze in een van de twee mogelijke seriële reeksen waren uitgevoerd.
Serializable en de gelijktijdigheidsverschijnselen
Naast logische serialisatie vermeldt de SQL-standaard ook dat een transactie die op het serialiseerbare isolatieniveau werkt, bepaalde gelijktijdigheidsverschijnselen niet mag ervaren. Het mag geen niet-vastgelegde gegevens lezen (geen vuile leesbewerkingen ); en zodra de gegevens zijn gelezen, moet een herhaling van dezelfde bewerking exact dezelfde set gegevens retourneren (herhaalbare uitlezingen zonder fantomen ).
De standaard maakt er een punt van te zeggen dat die gelijktijdigheidsverschijnselen worden uitgesloten op het serialiseerbare isolatieniveau als een direct gevolg te eisen dat de transactie logisch serialiseerbaar is. Met andere woorden, de vereiste van serialiseerbaarheid is op zichzelf voldoende om de vuile lees-, niet-herhaalbare lees- en fantoomconcurrency-fenomenen te vermijden. Daarentegen is het vermijden van de drie gelijktijdigheidsverschijnselen alleen niet voldoende om serialiseerbaarheid te garanderen, zoals we binnenkort zullen zien.
Intuïtief vermijden serialiseerbare transacties alle concurrency-gerelateerde verschijnselen, omdat ze moeten handelen alsof ze volledig geïsoleerd zijn uitgevoerd. In die zin komt het serialiseerbare transactie-isolatieniveau goed overeen met de algemene verwachtingen van T-SQL-programmeurs.
Serialiseerbare implementaties
SQL Server gebruikt toevallig een vergrendelingsimplementatie van het serialiseerbare isolatieniveau, waarbij fysieke vergrendelingen worden verkregen en vastgehouden tot het einde van de transactie (vandaar de verouderde tabelhint HOLDLOCK als synoniem voor SERIALIZABLE ).
Deze strategie is niet voldoende om een technische garantie van volledige serialiseerbaarheid te bieden, omdat nieuwe of gewijzigde gegevens kunnen verschijnen in een reeks rijen die eerder door de transactie zijn verwerkt. Dit gelijktijdigheidsfenomeen staat bekend als een fantoom en kan resulteren in effecten die in geen enkel serieel schema hadden kunnen optreden.
Om bescherming te bieden tegen het fenomeen phantom concurrency, kunnen vergrendelingen die door SQL Server op het serialiseerbare isolatieniveau worden genomen, ook key-range locking bevatten om te voorkomen dat er nieuwe of gewijzigde rijen verschijnen tussen eerder onderzochte indexsleutelwaarden. Bereikvergrendelingen zijn niet altijd verworven onder het serialiseerbare isolatieniveau; alles wat we in het algemeen kunnen zeggen, is dat SQL Server altijd voldoende vergrendelingen verwerft om te voldoen aan de logische vereisten van het serialiseerbare isolatieniveau. In feite krijgen vergrendelingsimplementaties vaak meer en strengere vergrendelingen dan echt nodig is om de serialiseerbaarheid te garanderen, maar ik dwaal af.
Vergrendelen is slechts een van de mogelijke fysieke implementaties van het serialiseerbare isolatieniveau. We moeten voorzichtig zijn om het specifieke gedrag van de SQL Server-vergrendelingsimplementatie mentaal te scheiden van de logische definitie van serializable.
Zie als voorbeeld van een alternatieve fysieke strategie de PostgreSQL-implementatie van serializable snapshot-isolatie, hoewel dit slechts één alternatief is. Elke verschillende fysieke implementatie heeft natuurlijk zijn eigen sterke en zwakke punten. Merk terzijde op dat Oracle nog steeds geen volledig conforme implementatie van het serialiseerbare isolatieniveau biedt. Het heeft een isolatieniveau genaamd serialiseerbaar, maar het garandeert niet echt dat transacties worden uitgevoerd volgens een mogelijk serieel schema. Oracle biedt in plaats daarvan snapshot-isolatie wanneer serializable wordt aangevraagd, op vrijwel dezelfde manier als PostgreSQL deed vóór serializable snapshot-isolatie (SSI ) is geïmplementeerd.
Snapshot-isolatie voorkomt geen gelijktijdigheidsafwijkingen zoals schrijfscheefheid, wat niet mogelijk is onder echt serialiseerbare isolatie. Als u geïnteresseerd bent, kunt u voorbeelden vinden van schrijffout en andere gelijktijdigheidseffecten die zijn toegestaan door snapshot-isolatie op de SSI-link hierboven. We zullen later in de serie ook de implementatie van het snapshot-isolatieniveau door SQL Server bespreken.
Een momentopname?
Een van de redenen waarom ik veel tijd heb besteed aan het praten over de verschillen tussen logische serialiseerbaarheid en fysiek geserialiseerde uitvoering, is dat het anders gemakkelijk is om garanties af te leiden die misschien niet echt bestaan. Als u bijvoorbeeld serialiseerbare transacties beschouwt als eigenlijk als u de een na de ander uitvoert, zou u kunnen concluderen dat een serialiseerbare transactie noodzakelijkerwijs de database zal zien zoals deze bestond aan het begin van de transactie, wat een point-in-time weergave oplevert.
In feite is dit een implementatiespecifiek detail. Denk aan het vorige voorbeeld, waar serialiseerbare transactie T1 kan legitiem vijf of negen rijen tellen. Als een telling van negen wordt geretourneerd, ziet de eerste transactie duidelijk rijen die niet bestonden op het moment dat de transactie begon. Dit resultaat is mogelijk in SQL Server, maar niet in PostgreSQL SSI, hoewel beide implementaties voldoen aan het logische gedrag dat is gespecificeerd voor het serialiseerbare isolatieniveau.
In SQL Server zien serialiseerbare transacties niet noodzakelijk de gegevens zoals deze bestonden aan het begin van de transactie. De details van de SQL Server-implementatie betekenen veeleer dat een serialiseerbare transactie de laatste vastgelegde gegevens ziet, vanaf het moment dat de gegevens voor het eerst werden vergrendeld voor toegang. Bovendien wordt gegarandeerd dat de set van laatst vastgelegde gegevens die uiteindelijk worden gelezen, het lidmaatschap niet verandert voordat de transactie eindigt.
Volgende keer
Het volgende deel in deze serie onderzoekt het herhaalbare leesisolatieniveau, dat zwakkere garanties voor transactieisolatie biedt dan serialiseerbaar.
[ Zie de index voor de hele serie ]