Dit bericht maakt deel uit van een serie artikelen over rijdoelen. Het eerste deel vind je hier:
- Deel 1:Rijdoelen stellen en identificeren
Het is relatief bekend dat het gebruik van TOP of een FAST n queryhint kan een rijdoel instellen in een uitvoeringsplan (zie Rijdoelen instellen en identificeren in Uitvoeringsplannen als u een opfrissing nodig hebt over rijdoelen en hun oorzaken). Het wordt wat minder algemeen erkend dat semi-joins (en anti-joins) ook een rijdoel kunnen introduceren, hoewel dit iets minder waarschijnlijk is dan het geval is voor TOP , FAST , en SET ROWCOUNT .
Dit artikel helpt u te begrijpen wanneer en waarom een semi-join de rijdoellogica van de optimizer aanroept.
Halve deelname
Een semi-join retourneert een rij van één join-invoer (A) als er minstens één . is overeenkomende rij op de andere join-invoer (B).
De essentiële verschillen tussen een semi-join en een gewone join zijn:
- Semi-join retourneert elke rij van invoer A, of niet. Er kan geen rijduplicatie plaatsvinden.
- Regelmatige join dupliceert rijen als er meerdere overeenkomsten zijn met het join-predikaat.
- Semi-join is gedefinieerd om alleen kolommen van invoer A te retourneren.
- Reguliere join kan kolommen van een (of beide) join-invoer retourneren.
T-SQL heeft momenteel geen ondersteuning voor directe syntaxis zoals FROM A SEMI JOIN B ON A.x = B.y , dus we moeten indirecte vormen gebruiken zoals EXISTS , SOME/ANY (inclusief de equivalente afkorting IN voor gelijkheidsvergelijkingen), en stel INTERSECT in .
De beschrijving van een semi-join hierboven verwijst natuurlijk naar de toepassing van een rijdoel, aangezien we geïnteresseerd zijn in het vinden van elke overeenkomende rij in B, niet al zulke rijen . Desalniettemin leidt een logische semi-join uitgedrukt in T-SQL om verschillende redenen mogelijk niet tot een uitvoeringsplan met een rijdoel, wat we hierna zullen uitpakken.
Transformatie en vereenvoudiging
Een logische semi-join kan worden vereenvoudigd of vervangen door iets anders tijdens het compileren en optimaliseren van query's. Het AdventureWorks-voorbeeld hieronder laat zien dat een semi-join volledig wordt verwijderd vanwege een vertrouwde externe sleutelrelatie:
SELECT TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID IN
(
SELECT P.ProductID
FROM Production.Product AS P
);
De refererende sleutel zorgt ervoor dat Product rijen zullen altijd bestaan voor elke geschiedenisrij. Als gevolg hiervan heeft het uitvoeringsplan alleen toegang tot de TransactionHistory tafel:
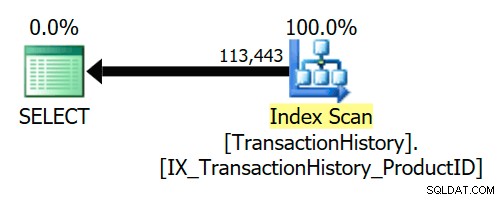
Een meer algemeen voorbeeld wordt gezien wanneer de semi-join kan worden getransformeerd naar een inner join. Bijvoorbeeld:
SELECT P.ProductID
FROM Production.Product AS P
WHERE EXISTS
(
SELECT *
FROM Production.ProductInventory AS INV
WHERE INV.ProductID = P.ProductID
);
Het uitvoeringsplan laat zien dat de optimizer een aggregaat heeft geïntroduceerd (groepering op INV.ProductID ) om ervoor te zorgen dat de inner join alleen Product kan retourneren rijen één keer of helemaal niet (zoals vereist om de semi-join-semantiek te behouden):
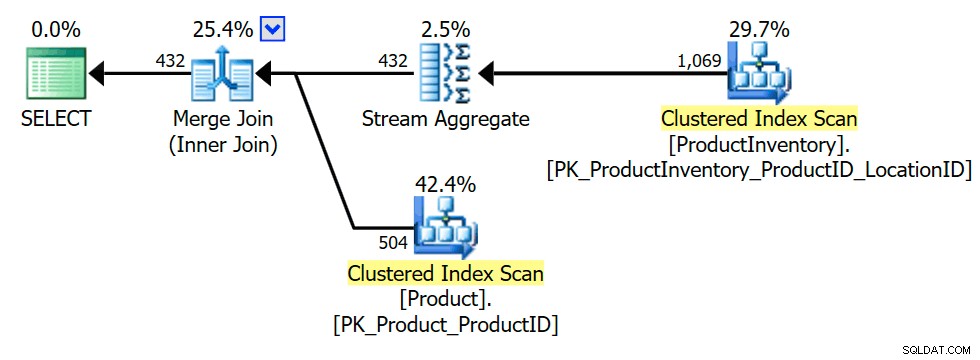
De transformatie naar inner join wordt al vroeg onderzocht omdat de optimizer meer trucjes weet voor inner equijoins dan voor semi-joins, wat mogelijk kan leiden tot meer optimalisatiemogelijkheden. Uiteraard is de uiteindelijke plankeuze nog steeds een op kosten gebaseerde beslissing tussen de onderzochte alternatieven.
Vroege optimalisaties
Hoewel T-SQL geen directe SEMI JOIN heeft syntaxis, de optimizer weet alles over semi-joins native, en kan ze direct manipuleren. De algemene syntaxis van semi-join voor een tijdelijke oplossing worden vroeg in het querycompilatieproces omgezet in een "echte" interne semi-join (ruim voordat zelfs maar een triviaal plan wordt overwogen).
De twee belangrijkste syntaxisgroepen voor tijdelijke oplossingen zijn EXISTS/INTERSECT , en ANY/SOME/IN . De EXISTS en INTERSECT gevallen verschillen alleen doordat de laatste wordt geleverd met een impliciete DISTINCT (groeperen op alle geprojecteerde kolommen). Beide EXISTS en INTERSECT worden geparseerd als een EXISTS met gecorreleerde subquery. De ANY/SOME/IN representaties worden allemaal geïnterpreteerd als een SOMMIGE bewerking. We kunnen deze optimalisatieactiviteit in een vroeg stadium onderzoeken met een paar ongedocumenteerde traceervlaggen, die informatie over optimalisatieactiviteit naar het tabblad SSMS-berichten sturen.
De semi-join die we tot nu toe hebben gebruikt, kan bijvoorbeeld ook worden geschreven met IN :
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.ProductID IN /* or = ANY/SOME */
(
SELECT TH.ProductID
FROM Production.TransactionHistory AS TH
)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON 8621); De invoerstructuur van de optimizer is als volgt:

De scalaire operator ScaOp_SomeComp is de SOME vergelijking hierboven genoemd. De 2 is de code voor een gelijkheidstest, aangezien IN is gelijk aan = SOME . Als u geïnteresseerd bent, zijn er codes van 1 tot 6 die respectievelijk (<, =, <=,>, !=,>=) vergelijkingsoperatoren vertegenwoordigen.
Terugkeren naar de EXISTS syntaxis die ik het liefst gebruik om een semi-join indirect uit te drukken:
SELECT P.ProductID
FROM Production.Product AS P
WHERE EXISTS
(
SELECT *
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON 8621); De invoerboom van de optimizer is:

Die boom is een vrij directe vertaling van de vraagtekst; houd er echter rekening mee dat de SELECT * is al vervangen door een projectie van de constante integerwaarde 1 (zie de voorlaatste tekstregel).
Het volgende dat de optimizer doet, is de subquery in de relationele selectie (=filter) verwijderen met behulp van regel RemoveSubqInSel . De optimizer doet dit altijd, omdat het niet rechtstreeks op subquery's kan werken. Het resultaat is een solliciteer (ook wel een gecorreleerde of laterale verbinding):

(Dezelfde regel voor het verwijderen van subquery's produceert dezelfde uitvoer voor de SOME invoerboom ook).
De volgende stap is om de toepassing te herschrijven als een gewone join met behulp van de ApplyHandler regel familie. Dit is iets wat de optimizer altijd probeert te doen, omdat het meer verkenningsregels heeft voor joins dan voor Apply. Niet elke toepassing kan worden herschreven als een join, maar het huidige voorbeeld is eenvoudig en slaagt:

Merk op dat het type van de join semi is. Dit is inderdaad precies dezelfde boom die we onmiddellijk zouden krijgen als T-SQL syntaxis zou ondersteunen zoals:
SELECT P.ProductID
FROM Production.Product AS P
LEFT SEMI JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID; Het zou fijn zijn om op deze manier vragen directer te kunnen uiten. Hoe dan ook, de geïnteresseerde lezer wordt aangemoedigd om de bovenstaande vereenvoudigingsactiviteiten te verkennen met andere logisch equivalente manieren om deze semi-join in T-SQL te schrijven.
Het belangrijkste in dit stadium is dat de optimizer altijd subquery's verwijdert , deze te vervangen door een toepassing. Vervolgens probeert het de toepassing te herschrijven als een reguliere join om de kansen op het vinden van een goed plan te maximaliseren. Onthoud dat al het voorgaande plaatsvindt voordat zelfs maar een triviaal plan is overwogen. Tijdens op kosten gebaseerde optimalisatie kan de optimizer ook overwegen om de transformatie terug te brengen naar een aanvraag.
Hash en voeg semi-deelname samen
SQL Server heeft drie belangrijke fysieke implementatie-opties beschikbaar voor een logische semi-join. Zolang een equijoin-predikaat aanwezig is, zijn hash en merge-join beschikbaar; beide kunnen werken in de links- en rechts-semi-joinmodes. Geneste loops join ondersteunt alleen left (niet rechts) semi join, maar vereist geen equijoin predikaat. Laten we eens kijken naar de hash- en merge fysieke opties voor onze voorbeeldquery (geschreven als een set die deze keer kruist):
SELECT P.ProductID FROM Production.Product AS P INTERSECT SELECT TH.ProductID FROM Production.TransactionHistory AS TH;
De optimizer kan een plan vinden voor alle vier de combinaties van (links/rechts) en (hash/samenvoegen) semi-join voor deze zoekopdracht:
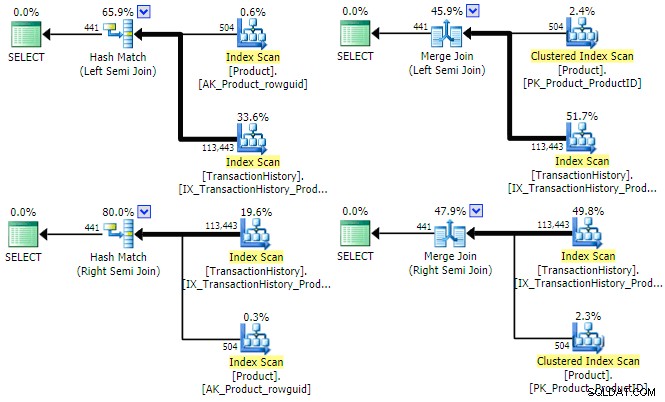
Het is de moeite waard om kort te vermelden waarom de optimizer zowel linker als rechter semi-joins kan overwegen voor elk join-type. Voor hash semi-join is een belangrijke kostenoverweging de geschatte grootte van de hashtabel, die aanvankelijk altijd de linker (bovenste) invoer is. Voor semi-join samenvoegen bepalen de eigenschappen van elke invoer of een één-op-veel- of minder efficiënte veel-op-veel-samenvoeging met werktabel wordt gebruikt.
Het zou uit de bovenstaande uitvoeringsplannen kunnen blijken dat noch hash noch merge semi-join baat zouden hebben bij het instellen van een rijdoel . Beide join-typen testen het join-predikaat altijd bij de join zelf en streven ernaar om alle rijen van beide invoer te verbruiken om een volledige resultatenset te retourneren. Dat wil niet zeggen dat er geen prestatie-optimalisaties bestaan voor hash- en merge-joins in het algemeen - beide kunnen bijvoorbeeld bitmaps gebruiken om het aantal rijen dat de join bereikt te verminderen. Het punt is eerder dat een rijdoel op beide invoer een hash- of merge-semi-join niet efficiënter zou maken.
Nested Loops en Semi Join toepassen
Het resterende fysieke join-type zijn geneste lussen, die in twee smaken verkrijgbaar zijn:gewone (niet-gecorreleerde) geneste lussen en toepassen geneste lussen (soms ook wel een gecorreleerde genoemd of lateraal meedoen).
Reguliere geneste loops join is vergelijkbaar met hash en merge join in die zin dat het join-predikaat wordt geëvalueerd bij de join. Net als voorheen betekent dit dat het geen waarde heeft om een rijdoel voor beide inputs in te stellen. De linker (bovenste) invoer zal uiteindelijk altijd volledig worden verbruikt, en de binnenste invoer heeft geen manier om te bepalen welke rij(en) prioriteit moeten krijgen, aangezien we niet kunnen weten of een rij zal deelnemen of niet totdat het predikaat is getest bij de samenvoeging .
Daarentegen heeft een toepassing van geneste loops-join een of meer buitenste verwijzingen (gecorreleerde parameters) bij de join, met het join predikaat omlaag gedrukt de binnenzijde (onderkant) van de voeg. Dit schept een mogelijkheid voor de nuttige toepassing van een rijdoel. Bedenk dat we voor een semi-join alleen hoeven te controleren op het bestaan van een rij op join-invoer B die overeenkomt met de huidige rij op join-invoer A (denk nu alleen aan geneste loops-joinstrategieën).
Met andere woorden, bij elke iteratie van een toepassing kunnen we stoppen met kijken naar invoer B zodra de eerste overeenkomst is gevonden, met behulp van het ingedrukte join-predikaat. Dit is precies waar een rijdoel goed voor is:het genereren van een deel van een plan dat is geoptimaliseerd om de eerste n overeenkomende rijen snel te retourneren (waarbij n = 1 hier).
Natuurlijk kan een rijdoel een goede zaak zijn of niet, afhankelijk van de omstandigheden. Er is in dat opzicht niets bijzonders aan het semi-join row-doel. Overweeg een situatie waarin de binnenkant van de semi-join complexer is dan een enkele simpele tafeltoegang, misschien een multi-table join. Het instellen van een rijdoel kan de optimizer helpen bij het selecteren van een efficiënte navigatiestrategie alleen voor die specifieke substructuur , het vinden van de eerste overeenkomende rij om te voldoen aan de semi-join via geneste loops-joins en index-zoekopdrachten. Zonder het rijdoel kan de optimizer natuurlijk hash kiezen of joins samenvoegen met sorts om de verwachte kosten van het retourneren van alle mogelijke rijen te minimaliseren. Merk op dat hier een aanname is, namelijk dat mensen typisch semi-joins schrijven met de verwachting dat er inderdaad een rij bestaat die aan de zoekvoorwaarde voldoet. Dit lijkt mij een redelijke veronderstelling.
Hoe dan ook, het belangrijkste punt in dit stadium is:Alleen van toepassing zijn geneste loops join heeft een rijdoel toegepast door de optimizer (onthoud echter dat een rijdoel voor het toepassen van geneste lussen alleen wordt toegevoegd als het rijdoel lager is dan de schatting zonder). We zullen een paar uitgewerkte voorbeelden bekijken om dit hopelijk allemaal duidelijk te maken.
Voorbeelden van geneste lussen semi-join
Met het volgende script worden twee tijdelijke heaptabellen gemaakt. De eerste heeft nummers van 1 tot en met 20; de andere heeft 10 exemplaren van elk nummer in de eerste tabel:
DROP TABLE IF EXISTS #E1, #E2;
CREATE TABLE #E1 (c1 integer NULL);
CREATE TABLE #E2 (c1 integer NULL);
INSERT #E1 (c1)
SELECT
SV.number
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 20;
INSERT #E2 (c1)
SELECT
(SV.number % 20) + 1
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 200; Zonder indexen en een relatief klein aantal rijen, kiest de optimizer een implementatie van geneste lussen (in plaats van hash of merge) voor de volgende semi-join-query). De ongedocumenteerde traceervlaggen stellen ons in staat om de optimalisatie-outputboom en rijdoelinformatie te zien:
SELECT E1.c1
FROM #E1 AS E1
WHERE E1.c1 IN
(SELECT E2.c1 FROM #E2 AS E2)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612);
Het geschatte uitvoeringsplan bevat een semi-join geneste loops-join, met 200 rijen per volledige scan van tabel #E2 . De 20 herhalingen van de lus geven een totale schatting van 4.000 rijen:
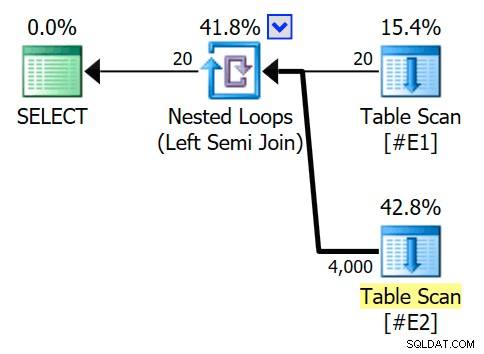
De eigenschappen van de geneste lussen-operator laten zien dat het predikaat wordt toegepast bij de join wat betekent dat dit een niet-gecorreleerde geneste loops-join is :
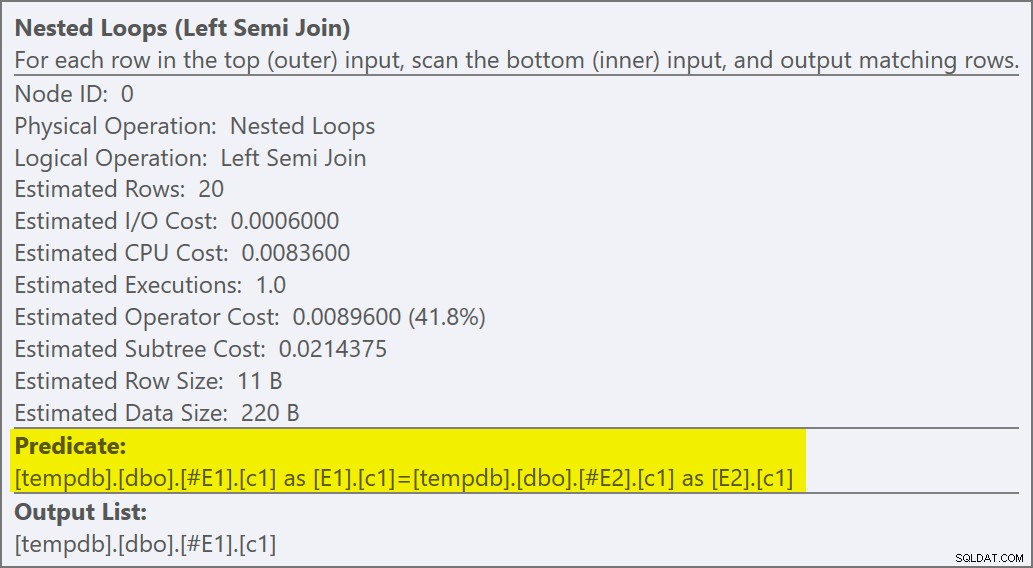
De uitvoer van de traceervlag (op het tabblad SSMS-berichten) toont een semi-join met geneste lussen en geen rijdoel (RowGoal 0):

Houd er rekening mee dat het post-uitvoeringsplan voor deze speelgoedquery niet in totaal 4.000 rijen toont die uit tabel #E2 zijn gelezen. Geneste lussen semi-join (gecorreleerd of niet) zullen stoppen met zoeken naar meer rijen aan de binnenzijde (per iteratie) zodra de eerste match voor de huidige buitenste rij wordt gevonden. Nu is de volgorde van de rijen die worden aangetroffen bij de heapscan van #E2 bij elke iteratie niet-deterministisch (en kan bij elke iteratie anders zijn), dus in principe bijna alle rijen zouden bij elke iteratie kunnen worden getest, in het geval dat de overeenkomende rij zo laat mogelijk wordt aangetroffen (of zelfs, in het geval van geen overeenkomende rij, helemaal niet).
Als we bijvoorbeeld uitgaan van een runtime-implementatie waarbij rijen toevallig elke keer in dezelfde volgorde worden gescand (bijvoorbeeld "invoegvolgorde"), zou het totale aantal gescande rijen in dit speelgoedvoorbeeld 20 rijen zijn bij de eerste iteratie, 1 rij op de tweede iteratie, 2 rijen op de derde iteratie, enzovoort voor een totaal van 20 + 1 + 2 + (...) + 19 =210 rijen. Het is zeer waarschijnlijk dat u dit totaal waarneemt, wat meer zegt over de beperkingen van eenvoudige demonstratiecode dan over iets anders. Men kan niet vertrouwen op de volgorde van rijen die worden geretourneerd door een ongeordende toegangsmethode, net zomin als men kan vertrouwen op de schijnbaar geordende uitvoer van een query zonder een ORDER BY op het hoogste niveau. clausule.
Semi-deelname toepassen
We maken nu een niet-geclusterde index op de grotere tabel (om de optimizer aan te moedigen een semi-join toepassen te kiezen) en voeren de query opnieuw uit:
CREATE NONCLUSTERED INDEX nc1 ON #E2 (c1);
SELECT E1.c1
FROM #E1 AS E1
WHERE E1.c1 IN
(SELECT E2.c1 FROM #E2 AS E2)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612); Het uitvoeringsplan bevat nu een toepassings-semi-join, met 1 rij per indexzoekopdracht (en 20 iteraties zoals voorheen):
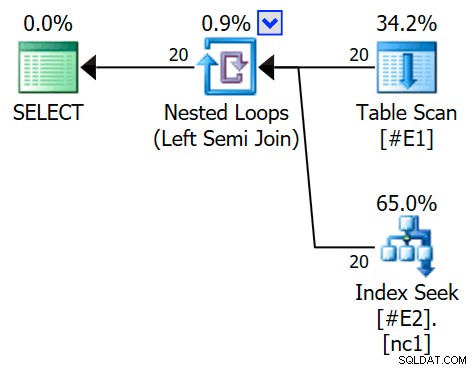
We kunnen zien dat het een semi-join toepassen . is omdat de join-eigenschappen een buitenste referentie tonen in plaats van een join-predikaat:
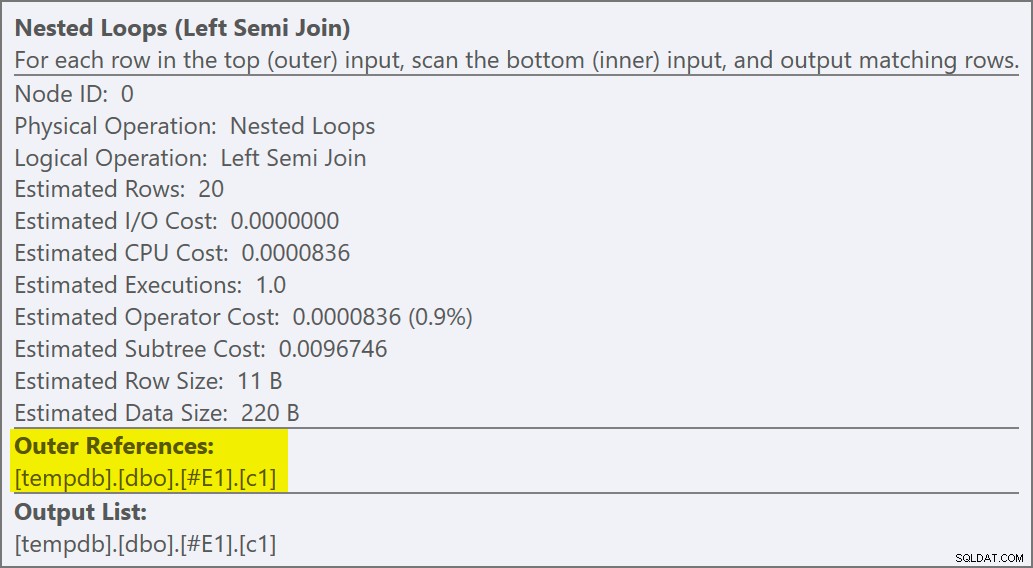
Het join-predikaat is naar beneden geduwd de binnenkant van de toepassing, en afgestemd op de nieuwe index:
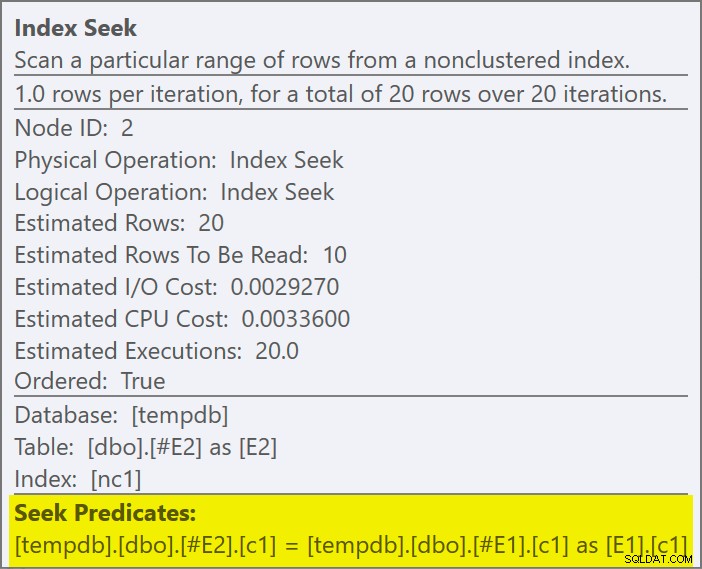
Elke zoekopdracht zal naar verwachting 1 rij retourneren, ondanks het feit dat elke waarde 10 keer wordt gedupliceerd in die tabel; dit is een effect van het rijdoel . Het rijdoel is gemakkelijker te identificeren op SQL Server-builds die de EstimateRowsWithoutRowGoal blootleggen plan-kenmerk (SQL Server 2017 CU3 op het moment van schrijven). In een toekomstige versie van Plan Explorer zal dit ook worden weergegeven in tooltips voor relevante operators:

De uitvoer van de traceervlag is:
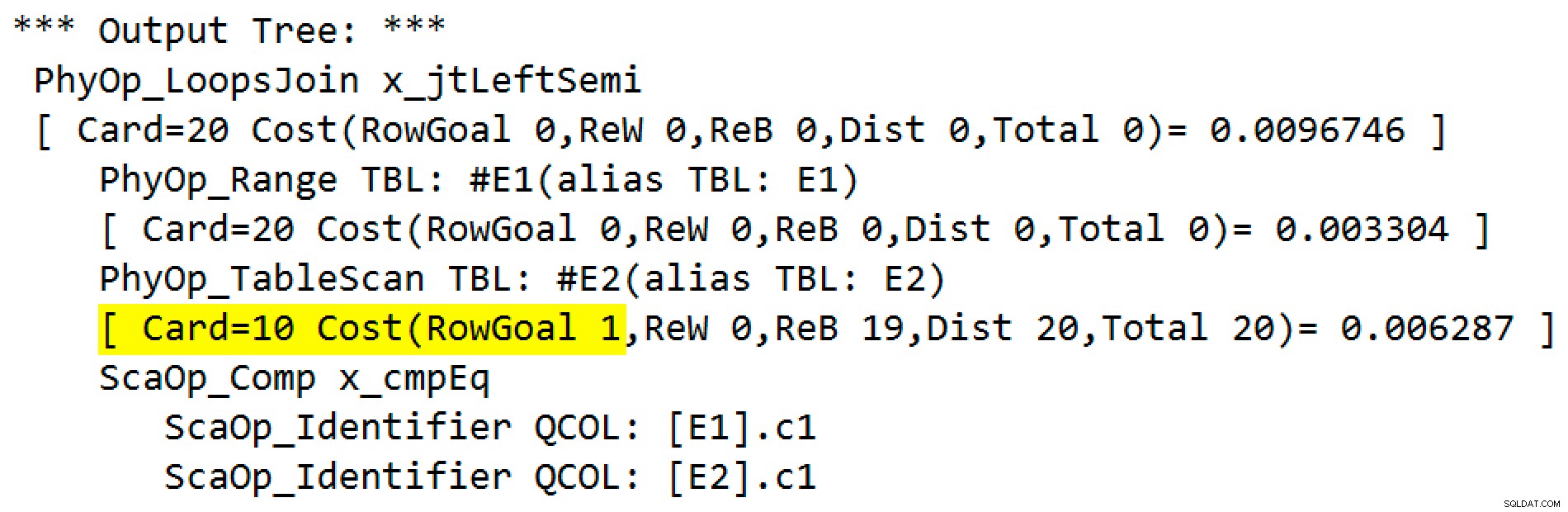
De fysieke operator is veranderd van een loops-join naar een toepassing die wordt uitgevoerd in de linker semi-join-modus. Toegang tot tafel #E2 een rijdoel van 1 heeft behaald (de kardinaliteit zonder het rijdoel wordt weergegeven als 10). Het rijdoel is in dit geval geen groot probleem, omdat de kosten van het ophalen van naar schatting tien rijen per zoekactie niet veel meer zijn dan voor één rij. Rijdoelen uitschakelen voor deze zoekopdracht (met behulp van traceervlag 4138 of de DISABLE_OPTIMIZER_ROWGOAL vraaghint) zou de vorm van het plan niet veranderen.
Desalniettemin kan bij meer realistische zoekopdrachten de kostenreductie als gevolg van het binnenste rij-doel het verschil maken tussen concurrerende implementatie-opties. Als u bijvoorbeeld het rijdoel uitschakelt, kan het optimalisatieprogramma in plaats daarvan een hash- of merge-semi-join kiezen, of een van de vele andere opties die voor de query worden overwogen. Als er niets anders is, weerspiegelt het rijdoel hier nauwkeurig het feit dat een semi-join van toepassing zijn, stopt met zoeken aan de binnenkant zodra de eerste overeenkomst is gevonden, en doorgaat naar de volgende rij aan de buitenkant.
Merk op dat er duplicaten zijn gemaakt in tabel #E2 zodat het doel voor het toepassen van semi-joinrij (1) lager zou zijn dan de normale schatting (10, uit statistische dichtheidsinformatie). Als er geen duplicaten waren, zoekt de rijschatting voor elke zoekopdracht naar #E2 zou ook 1 rij zijn, dus een rijdoel van 1 zou niet worden toegepast (onthoud de algemene regel hierover!)
Rij doelen versus top
Aangezien uitvoeringsplannen de aanwezigheid van een rijdoel helemaal niet aangeven vóór SQL Server 2017 CU3, zou men kunnen denken dat het duidelijker zou zijn geweest om deze optimalisatie te implementeren met een expliciete Top-operator in plaats van een verborgen eigenschap zoals een rijdoel. Het idee zou zijn om simpelweg een Top (1)-operator aan de binnenkant van een semi/anti-join toe te passen in plaats van een rijdoel in te stellen bij de join zelf.
Het op deze manier inzetten van een Top-operator zou niet geheel zonder precedent zijn geweest. Er is bijvoorbeeld al een speciale versie van Top, bekend als een row count top, te zien in uitvoeringsplannen voor gegevensmodificatie wanneer een SET ROWCOUNT is van kracht (merk op dat dit specifieke gebruik sinds 2005 is afgeschaft, hoewel het nog steeds is toegestaan in SQL Server 2017). De implementatie van het aantal rijen bovenaan is een beetje onhandig omdat de operator bovenaan altijd wordt weergegeven als een Top (0) in het uitvoeringsplan, ongeacht de daadwerkelijke limiet voor het tellen van rijen.
Er is geen dwingende reden waarom het doel van het toepassen van semi-joinrij niet vervangen had kunnen worden door een expliciete Top (1)-operator. Dat gezegd hebbende, zijn er enkele redenen om de voorkeur te geven om dat niet te doen:
- Het toevoegen van een expliciete Top (1) vereist meer inspanning en testen van optimalisatiecodering dan het toevoegen van een rijdoel (dat al voor andere dingen wordt gebruikt).
- Top is geen relationele operator; de optimizer heeft weinig ondersteuning om erover te redeneren. Dit kan een negatieve invloed hebben op de kwaliteit van het plan door het vermogen van de optimizer om delen van een queryplan te transformeren, b.v. door aggregaten, verbindingen, filters en verbindingen te verplaatsen.
- Het zou een strakke koppeling introduceren tussen de toepassing van de semi-joint en de top. Speciale gevallen en strakke koppelingen zijn geweldige manieren om bugs te introduceren en toekomstige wijzigingen moeilijker en foutgevoeliger te maken.
- De Top (1) zou logischerwijs overbodig zijn en alleen aanwezig zijn vanwege het neveneffect van het rijdoel.
Dat laatste punt is de moeite waard om uit te breiden met een voorbeeld:
SELECT
P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT TOP (1)
TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
);
De TOP (1) in de bestaande subquery wordt vereenvoudigd door de optimizer, wat een eenvoudig semi-join-uitvoeringsplan oplevert:
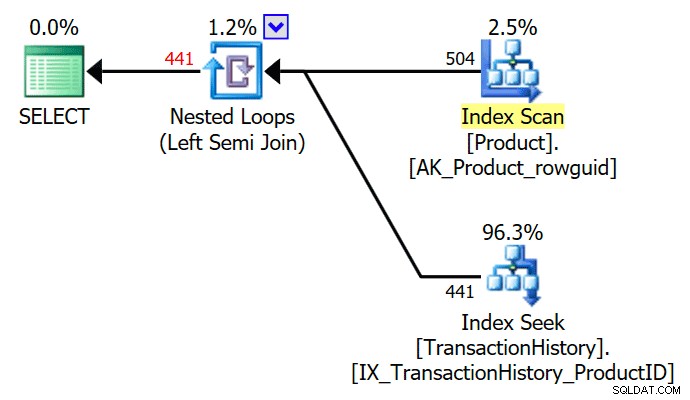
De optimizer kan ook een overtollige DISTINCT of GROUP BY in de subquery. De volgende geven allemaal hetzelfde plan als hierboven:
-- Redundant DISTINCT
SELECT P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT DISTINCT
TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
);
-- Redundant GROUP BY
SELECT P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
GROUP BY TH.ProductID
);
-- Redundant DISTINCT TOP (1)
SELECT P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT DISTINCT TOP (1)
TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
); Samenvatting en laatste gedachten
Alleen van toepassing zijn geneste lussen semi-join kan een rijdoel hebben dat is ingesteld door de optimizer. Dit is het enige join-type dat het (de) join-predikaat(en) naar beneden duwt vanuit de join, waardoor testen op het bestaan van een match vroeg kan worden uitgevoerd . Niet-gecorreleerde geneste lussen semi-join bijna nooit* stelt een rijdoel in, en een hash of merge semi-join evenmin. Toepassen van geneste lussen kan worden onderscheiden van niet-gecorreleerde geneste lussen door de aanwezigheid van buitenste referenties (in plaats van een predikaat) op de geneste lussen join-operator voor een toepassing.
De kans dat een 'apply semi join' in het uiteindelijke uitvoeringsplan wordt gezien, hangt enigszins af van vroege optimalisatieactiviteiten. Bij gebrek aan directe T-SQL-syntaxis, moeten we semi-joins in indirecte termen uitdrukken. Deze worden geparseerd in een logische boomstructuur met een subquery, die vroege optimalisatieactiviteit omzet in een toepassing, en vervolgens waar mogelijk in een niet-gecorreleerde semi-join.
Deze vereenvoudigingsactiviteit bepaalt of een logische semi-join aan de cost-based optimizer wordt gepresenteerd als een Apply of gewone semi-join. Indien gepresenteerd als een logische pas toe semi-join, zal de CBO vrijwel zeker een definitief uitvoeringsplan produceren met fysieke toepassing van geneste lussen (en dus een rijdoel instellen). Wanneer de CBO een niet-gecorreleerde semi-join krijgt, mag overweeg transformatie naar een toepassing (of misschien niet). De uiteindelijke keuze van het plan is zoals gewoonlijk een reeks op kosten gebaseerde beslissingen.
Zoals alle rijdoelen, kan het semi-joinrijdoel een goede of een slechte zaak zijn voor de prestaties. Wetende dat een semi-join toepassen een rijdoel instelt, zal mensen in ieder geval helpen de oorzaak te herkennen en aan te pakken als zich een probleem voordoet. De oplossing is niet altijd (of zelfs meestal) het uitschakelen van rijdoelen voor de query. Verbeteringen in de indexering (en/of de zoekopdracht) kunnen vaak worden aangebracht om een efficiënte manier te bieden om de eerste overeenkomende rij te vinden.
Ik zal anti-semi-joins behandelen in een apart artikel en de reeks rijdoelen voortzetten.
* De uitzondering is een niet-gecorreleerde semi-join met geneste lussen zonder join-predikaat (een ongebruikelijk beeld). Dit stelt wel een rijdoel in.