Gastauteur:Michael J Swart (@MJSwart)
Ik besteed veel tijd aan het vertalen van softwarevereisten naar schema's en queries. Deze eisen zijn soms eenvoudig te implementeren, maar vaak moeilijk. Ik wil het hebben over UI-ontwerpkeuzes die leiden tot patronen voor gegevenstoegang die lastig te implementeren zijn met SQL Server.
Sorteren op kolom
Sorteren op kolom is zo'n bekend patroon dat we het als vanzelfsprekend kunnen beschouwen. Elke keer dat we interactie hebben met software die een tabel weergeeft, kunnen we verwachten dat de kolommen als volgt kunnen worden gesorteerd:
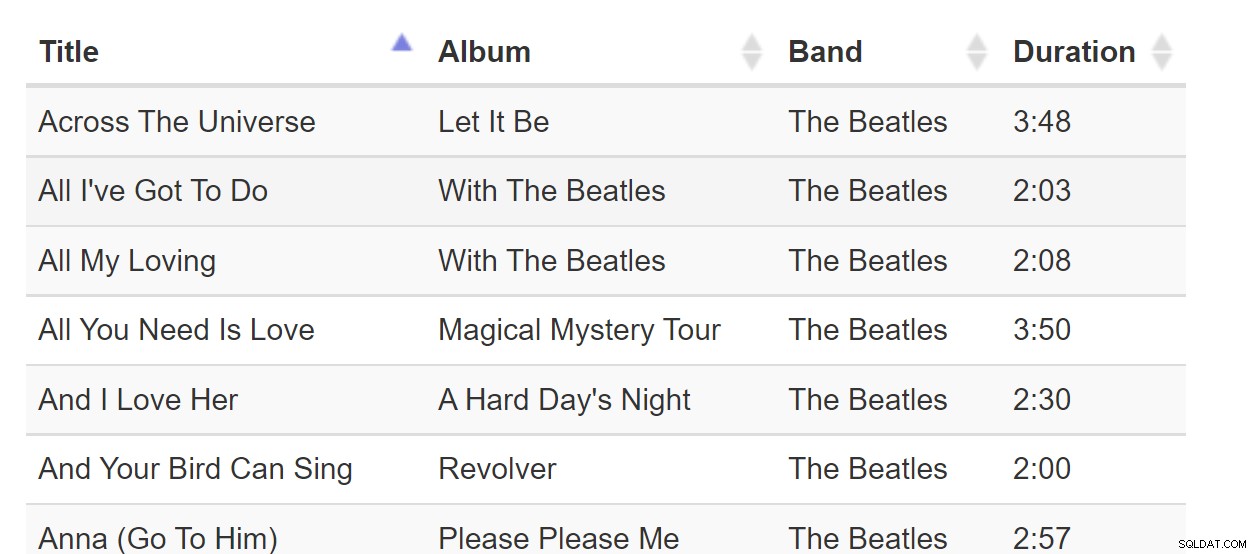
Sort-By-Colunn is een geweldig patroon wanneer alle gegevens in de browser passen. Maar als de dataset miljarden rijen groot is, kan dit lastig worden, zelfs als de webpagina maar één pagina met gegevens nodig heeft. Overweeg deze tabel met liedjes:
CREATE TABLE Songs
(
Title NVARCHAR(300) NOT NULL,
Album NVARCHAR(300) NOT NULL,
Band NVARCHAR(300) NOT NULL,
DurationInSeconds INT NOT NULL,
CONSTRAINT PK_Songs PRIMARY KEY CLUSTERED (Title),
);
CREATE NONCLUSTERED INDEX IX_Songs_Album
ON dbo.Songs(Album)
INCLUDE (Band, DurationInSeconds);
CREATE NONCLUSTERED INDEX IX_Songs_Band
ON dbo.Songs(Band); En bekijk deze vier zoekopdrachten gesorteerd op elke kolom:
SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Title; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Album; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Band; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY DurationInSeconds;
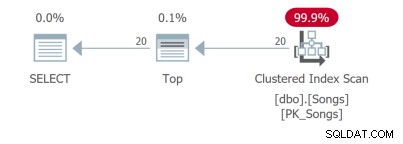
Zelfs voor een zoekopdracht die zo eenvoudig is, zijn er verschillende queryplannen. De eerste twee zoekopdrachten gebruiken dekkende indexen:
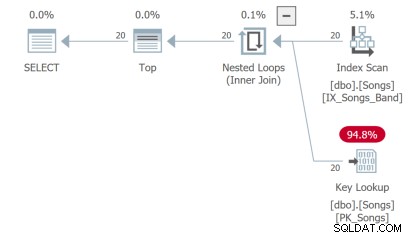
De derde zoekopdracht moet een sleutelzoekopdracht uitvoeren, wat niet ideaal is:
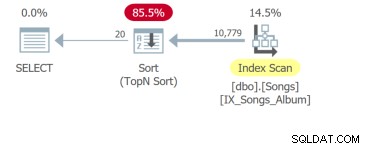
Maar het ergste is de vierde query die de hele tabel moet scannen en een sortering moet uitvoeren om de eerste 20 rijen te retourneren:
Het punt is dat, hoewel het enige verschil de ORDER BY-component is, deze zoekopdrachten afzonderlijk moeten worden geanalyseerd. De basiseenheid van SQL-tuning is de query. Dus als je me UI-vereisten laat zien met tien sorteerbare kolommen, laat ik je tien query's zien om te analyseren.
Wanneer wordt dit lastig?
De functie Sorteren op kolom is een geweldig UI-patroon, maar het kan lastig worden als de gegevens afkomstig zijn van een enorme groeiende tabel met heel veel kolommen. Het kan verleidelijk zijn om dekkingsindexen voor elke kolom te maken, maar dat heeft andere compromissen. Columnstore-indexen kunnen in sommige omstandigheden helpen, maar dat introduceert een ander niveau van onhandigheid. Er is niet altijd een gemakkelijk alternatief.
Paginaresultaten
Het gebruik van paginaresultaten is een goede manier om de gebruiker niet te overstelpen met te veel informatie tegelijk. Het is ook een goede manier om de databaseservers niet te overbelasten... meestal.
Overweeg dit ontwerp:

De gegevens achter dit voorbeeld vereisen het tellen en verwerken van de volledige dataset om het aantal resultaten te rapporteren. De query voor dit voorbeeld kan de volgende syntaxis gebruiken:
... ORDER BY LastModifiedTime OFFSET @N ROWS FETCH NEXT 25 ROWS ONLY;
Het is een handige syntaxis en de query produceert slechts 25 rijen. Maar alleen omdat de resultatenset klein is, betekent dit niet noodzakelijk dat het goedkoop is. Net zoals we zagen met het Sort-By-Column-patroon, is een TOP-operator alleen goedkoop als hij niet eerst veel gegevens hoeft te sorteren.
Asynchrone paginaverzoeken
Terwijl een gebruiker van de ene pagina met resultaten naar de volgende navigeert, kunnen de betrokken webverzoeken worden gescheiden door seconden of minuten. Dit leidt tot problemen die veel lijken op de valkuilen die worden gezien bij het gebruik van NOLOCK. Bijvoorbeeld:
SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY; -- wait a little bit SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 25 ROWS FETCH NEXT 25 ROWS ONLY;
Wanneer een rij tussen de twee verzoeken wordt toegevoegd, kan de gebruiker dezelfde rij twee keer zien. En als een rij wordt verwijderd, kan de gebruiker een rij missen terwijl hij door de pagina's navigeert. Dit patroon met wisselresultaten is gelijk aan "Geef me rijen 26-50". Wanneer de echte vraag zou moeten zijn:"Geef me de volgende 25 rijen". Het verschil is subtiel.
Betere patronen
Met Paged-Results kan die "OFFSET @N RIJEN" langer en langer duren naarmate @N groeit. Overweeg in plaats daarvan Load-More-knoppen of Oneindig scrollen. Met Load-More paging is er in ieder geval een kans om efficiënt gebruik te maken van een index. De zoekopdracht zou er ongeveer zo uitzien:
SELECT [Some Columns] FROM [Some Table] WHERE [Sort Value] > @Bookmark ORDER BY [Sort Value] FETCH NEXT 25 ROWS ONLY;
Het heeft nog steeds last van enkele van de valkuilen van asynchrone paginaverzoeken, maar vanwege de bladwijzer gaat de gebruiker verder waar hij was gebleven.
Tekst zoeken naar subtekenreeks
Zoeken is overal op internet. Maar welke oplossing moet er aan de achterkant worden gebruikt? Ik wil waarschuwen tegen het zoeken naar een subtekenreeks met behulp van het LIKE-filter van SQL Server met jokertekens zoals deze:
SELECT Title, Category FROM MyContent WHERE Title LIKE '%' + @SearchTerm + '%';
Dit kan leiden tot onhandige resultaten zoals deze:
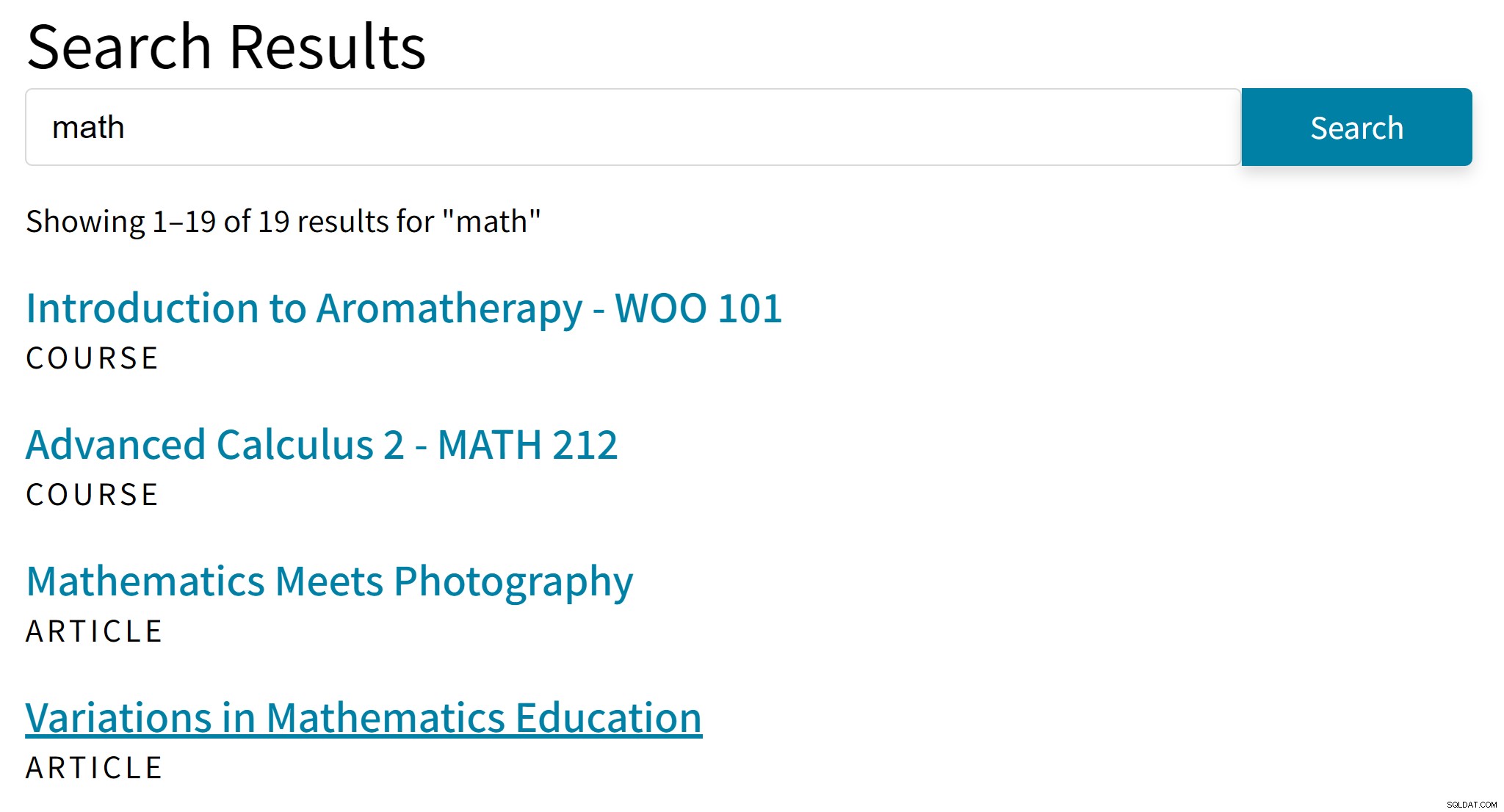
'Aromatherapie' is waarschijnlijk geen goede hit voor de zoekterm 'wiskunde'. Ondertussen ontbreken in de zoekresultaten artikelen die alleen algebra of trigonometrie vermelden.
Het kan ook erg moeilijk zijn om efficiënt te werken met SQL Server. Er is geen eenvoudige index die dit soort zoekopdrachten ondersteunt. Paul White gaf een lastige oplossing met Trigram Wildcard String Search in SQL Server. Er zijn ook problemen die kunnen optreden met sorteringen en Unicode. Het kan een dure oplossing worden voor een niet zo goede gebruikerservaring.
Wat u in plaats daarvan kunt gebruiken
Het zoeken in volledige tekst van SQL Server lijkt te kunnen helpen, maar ik heb het persoonlijk nooit gebruikt. In de praktijk heb ik alleen succes gezien in oplossingen buiten SQL Server (bijvoorbeeld Elasticsearch).
Conclusie
In mijn ervaring heb ik gemerkt dat softwareontwerpers vaak erg ontvankelijk zijn voor feedback dat hun ontwerpen soms lastig te implementeren zijn. Als dat niet het geval is, vond ik het nuttig om de valkuilen, de kosten en de levertijd te benadrukken. Dat soort feedback is nodig om onderhoudbare, schaalbare oplossingen te bouwen.
Over de auteur
 Michael J Swart is een gepassioneerde databaseprofessional en blogger die zich richt op database-ontwikkeling en software-architectuur. Hij praat graag over alles wat met data te maken heeft en draagt bij aan gemeenschapsprojecten. Michael blogt als "Database Whisperer" op michaeljswart.com.
Michael J Swart is een gepassioneerde databaseprofessional en blogger die zich richt op database-ontwikkeling en software-architectuur. Hij praat graag over alles wat met data te maken heeft en draagt bij aan gemeenschapsprojecten. Michael blogt als "Database Whisperer" op michaeljswart.com.