Toen SQL Server 2012 nog in bèta was, blogde ik over het nieuwe FORMAT() functie:SQL Server v.Next (Denali):CTP3 T-SQL Verbeteringen:FORMAT().
Op dat moment was ik zo enthousiast over de nieuwe functionaliteit, dat ik er niet eens aan dacht om prestatietests te doen. Ik heb hier in een recentere blogpost op ingegaan, maar alleen in de context van het strippen van de tijd van een datetime:Tijd trimmen van datetime - een vervolg.
Vorige week trollde mijn goede vriend Jason Horner (blog | @jasonhorner) me met deze tweets:
| |
Mijn probleem hiermee is alleen dat FORMAT() ziet er handig uit, maar het is extreem inefficiënt in vergelijking met andere benaderingen (oh en dat AS VARCHAR ding is ook slecht). Als je dit oney-twosy doet en voor kleine resultatensets, zou ik me er niet al te veel zorgen over maken; maar op schaal kan het behoorlijk duur worden. Laat me dit illustreren met een voorbeeld. Laten we eerst een kleine tabel maken met 1000 pseudo-willekeurige datums:
SELECT TOP (1000) d = DATEADD(DAY, CHECKSUM(NEWID())%1000, o.create_date) INTO dbo.dtTest FROM sys.all_objects AS o ORDER BY NEWID(); GO CREATE CLUSTERED INDEX d ON dbo.dtTest(d);
Laten we nu de cache vullen met de gegevens uit deze tabel en drie veelvoorkomende manieren illustreren waarop mensen de neiging hebben om precies de tijd te presenteren:
SELECT d, CONVERT(DATE, d), CONVERT(CHAR(10), d, 120), FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest;
Laten we nu afzonderlijke query's uitvoeren die deze verschillende technieken gebruiken. We zullen ze elke 5 keer uitvoeren en we zullen de volgende variaties uitvoeren:
- Alle 1.000 rijen selecteren
- Bovenkant selecteren (1) gerangschikt op de geclusterde indexsleutel
- Toewijzen aan een variabele (waardoor een volledige scan wordt afgedwongen, maar voorkomt dat SSMS-rendering de prestaties verstoort)
Hier is het script:
-- select all 1,000 rows GO SELECT d FROM dbo.dtTest; GO 5 SELECT d = CONVERT(DATE, d) FROM dbo.dtTest; GO 5 SELECT d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest; GO 5 SELECT d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest; GO 5 -- select top 1 GO SELECT TOP (1) d FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) CONVERT(DATE, d) FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest ORDER BY d; GO 5 -- force scan but leave SSMS mostly out of it GO DECLARE @d DATE; SELECT @d = d FROM dbo.dtTest; GO 5 DECLARE @d DATE; SELECT @d = CONVERT(DATE, d) FROM dbo.dtTest; GO 5 DECLARE @d CHAR(10); SELECT @d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest; GO 5 DECLARE @d CHAR(10); SELECT @d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest; GO 5
Nu kunnen we de prestaties meten met de volgende vraag (mijn systeem is vrij stil; op het uwe moet u mogelijk meer geavanceerde filtering uitvoeren dan alleen execution_count ):
SELECT [t] = CONVERT(CHAR(255), t.[text]), s.total_elapsed_time, avg_elapsed_time = CONVERT(DECIMAL(12,2),s.total_elapsed_time / 5.0), s.total_worker_time, avg_worker_time = CONVERT(DECIMAL(12,2),s.total_worker_time / 5.0), s.total_clr_time FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.[sql_handle]) AS t WHERE s.execution_count = 5 AND t.[text] LIKE N'%dbo.dtTest%' ORDER BY s.last_execution_time;
De resultaten waren in mijn geval redelijk consistent:
| Query (afgekort) | Duur (microseconden) | |||
|---|---|---|---|---|
| total_elapsed | avg_elapsed | total_clr | ||
| SELECTEER 1000 rijen | SELECT d FROM dbo.dtTest ORDER BY d; |
1,170 |
234.00 |
0 |
SELECT d = CONVERT(DATE, d) FROM dbo.dtTest ORDER BY d; |
2,437 |
487.40 |
0 |
|
SELECT d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ORD ... |
151,521 |
30,304.20 |
0 |
|
SELECT d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest ORDER ... |
240,152 |
48,030.40 |
107,258 |
|
| SELECT TOP (1) | SELECT TOP (1) d FROM dbo.dtTest ORDER BY d; |
251 |
50.20 |
0 |
SELECT TOP (1) CONVERT(DATE, d) FROM dbo.dtTest ORDER BY ... |
440 |
88.00 |
0 |
|
SELECT TOP (1) CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ... |
301 |
60.20 |
0 |
|
SELECT TOP (1) FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest O ... |
1,094 |
218.80 |
589 |
|
| Assign variable | DECLARE @d DATE; SELECT @d = d FROM dbo.dtTest; |
639 |
127.80 |
0 |
DECLARE @d DATE; SELECT @d = CONVERT(DATE, d) FROM dbo.d ... |
644 |
128.80 |
0 |
|
DECLARE @d CHAR(10); SELECT @d = CONVERT(CHAR(10), d, 12 ... | 1,972 |
394.40 |
0 |
|
DECLARE @d CHAR(10); SELECT @d = FORMAT(d, 'yyyy-MM-dd') ... |
118,062 |
23,612.40 |
98,556 |
|
And to visualize the avg_elapsed_time . te visualiseren output (klik om te vergroten):
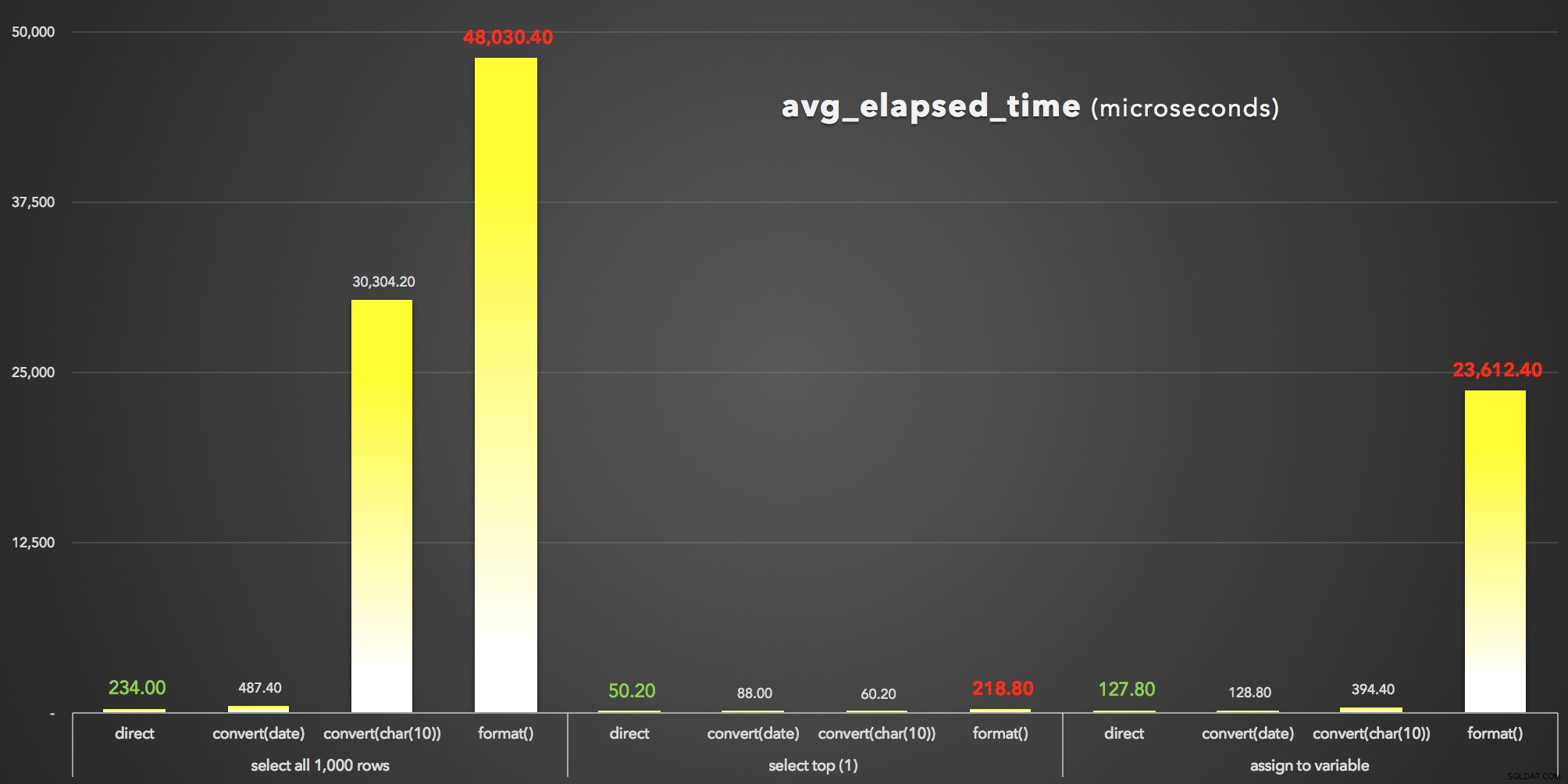 FORMAT() is duidelijk de verliezer:avg_elapsed_time results (microseconds)
FORMAT() is duidelijk de verliezer:avg_elapsed_time results (microseconds)
Wat we (opnieuw) van deze resultaten kunnen leren:
- Allereerst,
FORMAT()is duur . FORMAT()kan weliswaar meer flexibiliteit bieden en intuïtievere methoden bieden die consistent zijn met die in andere talen zoals C#. Echter, naast de overhead, en terwijlCONVERT()stijlnummers zijn cryptisch en minder uitputtend, het kan zijn dat u toch de oudere benadering moet gebruiken, aangezienFORMAT()is alleen geldig in SQL Server 2012 en nieuwer.- Zelfs de standby
CONVERT()methode kan drastisch duur zijn (hoewel alleen ernstig in het geval dat SSMS de resultaten moest weergeven - het behandelt strings duidelijk anders dan datumwaarden). - Het was altijd het meest efficiënt om de datetime-waarde rechtstreeks uit de database te halen. U moet een profiel maken van de extra tijd die uw toepassing nodig heeft om de datum naar wens te formatteren op de presentatielaag - het is zeer waarschijnlijk dat u niet wilt dat SQL Server zich met het opmaken van de indeling gaat bemoeien (en in feite zouden velen beweren dat dit is waar die logica altijd thuishoort).
We hebben het hier alleen over microseconden, maar we hebben het ook over slechts 1.000 rijen. Schaal dat uit naar uw werkelijke tabelgroottes, en de impact van het kiezen van de verkeerde opmaakbenadering kan verwoestend zijn.
Als je dit experiment op je eigen computer wilt uitproberen, heb ik een voorbeeldscript geüpload:FormatIsNiceAndAllBut.sql_.zip