In verschillende van mijn berichten van het afgelopen jaar heb ik het thema gebruikt van mensen die een bepaald type wacht zien en vervolgens op een "knie-trek"-manier reageren op het wachten dat er is. Meestal betekent dit dat je een slecht internetadvies volgt en een drastische, ongepaste actie onderneemt of tot een conclusie komt over wat de oorzaak van het probleem is en dan tijd en moeite verspilt aan een wilde achtervolging.
Een van de soorten wachten waarbij de reflexmatige reacties het sterkst zijn, en waar enkele van de slechtste adviezen bestaan, is de CXPACKET-wacht. Het is ook het type wacht dat meestal het meest wordt gewacht op de servers van mensen (volgens mijn twee grote enquêtes over wachttypes van 2010 en 2014 - zie hier voor details), dus ik ga het in dit bericht behandelen.
Wat betekent het CXPACKET-wachttype?
De eenvoudigste verklaring is dat CXPACKET betekent dat u parallelle zoekopdrachten hebt en dat u *altijd* zult zien dat CXPACKET wacht op een parallelle zoekopdracht. CXPACKET-wachttijden betekenen NIET dat u problematisch parallellisme heeft - u moet dieper graven om dat te bepalen.
Overweeg als voorbeeld van een parallelle operator de operator Repartition Streams, die het volgende pictogram heeft in grafische queryplannen:

En hier is een afbeelding die laat zien wat er aan de hand is in termen van parallelle threads voor deze operator, met een mate van parallellisme (DOP) gelijk aan 4:
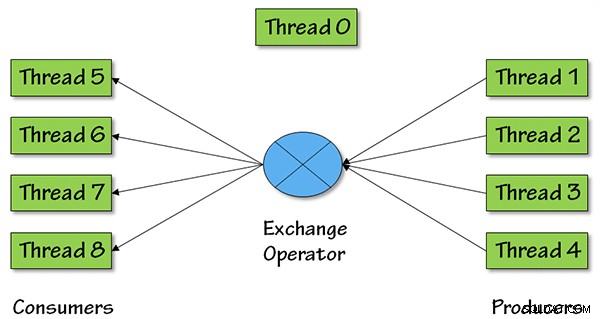
Voor DOP =4 zijn er vier producententhreads, die gegevens ophalen uit eerder in het queryplan, de gegevens gaan dan terug naar de rest van het queryplan via vier consumententhreads.
U kunt de verschillende threads in een parallelle operator zien die wachten op een resource met behulp van de sys.dm_os_waiting_tasks DMV, in de exec_context_id kolom (dit bericht heeft mijn script om dit te doen).
Er is altijd een 'controle'-thread voor elk parallel plan, wat per ongeluk altijd thread-ID 0 is. De controlethread registreert altijd een CXPACKET-wachttijd, met een duur die gelijk is aan de tijdsduur die het plan nodig heeft om uit te voeren. Paul White heeft hier een geweldige uitleg van threads in parallelle plannen.
De enige keer dat non-control threads CXPACKET-wachten registreren, is als ze vóór de andere threads in de operator zijn voltooid. Dit kan gebeuren als een van de threads vastloopt tijdens het lange tijd wachten op een bron, dus kijk wat het wachttype is van de thread die geen CXPACKET laat zien (met mijn script hierboven) en los het probleem op de juiste manier op. Dit kan ook gebeuren vanwege een scheve werkverdeling tussen de threads, en ik zal in mijn volgende post hier dieper op dat geval ingaan (het wordt veroorzaakt door verouderde statistieken en andere kardinaliteitsschattingsproblemen).
Houd er rekening mee dat in SQL Server 2016 SP2 en SQL Server 2017 RTM CU3 consumententhreads niet langer CXPACKET-wachten registreren. Ze registreren CXCONSUMER-wachttijden, die goedaardig zijn en kunnen worden genegeerd. Dit is bedoeld om het aantal CXPACKET-wachten dat wordt gegenereerd te verminderen, en de resterende wachttijden zijn waarschijnlijker.
Onverwacht parallellisme?
Aangezien CXPACKET simpelweg betekent dat er parallellisme plaatsvindt, is het eerste waar u naar moet kijken of u parallellisme verwacht voor de query die het gebruikt. Mijn query geeft u de knooppunt-ID van het queryplan waar het parallellisme plaatsvindt (het haalt de knooppunt-ID uit het XML-queryplan als het wachttype van de thread CXPACKET is), dus zoek naar die knooppunt-ID en bepaal of het parallellisme zinvol is .
Een van de meest voorkomende gevallen van onverwacht parallellisme is wanneer een tabelscan plaatsvindt waarbij u een kleinere indexzoektocht of -scan verwacht. U ziet dit ofwel in het queryplan of u ziet veel PAGEIOLATCH_SH-wachttijden (hier in detail besproken) samen met de CXPACKET-wachttijden (een klassiek wachtstatistiekenpatroon om op te letten). Er zijn verschillende oorzaken van onverwachte tafelscans, waaronder:
- Ontbrekende niet-geclusterde index, dus een tabelscan is het enige alternatief
- Verouderde statistieken, dus de Query Optimizer denkt dat een tabelscan de beste methode voor gegevenstoegang is
- Een impliciete conversie vanwege een niet-overeenkomend gegevenstype tussen een tabelkolom en een variabele of parameter, wat betekent dat een niet-geclusterde index niet kan worden gebruikt
- Rekenkunde wordt uitgevoerd op een tabelkolom in plaats van een variabele of parameter, wat betekent dat een niet-geclusterde index niet kan worden gebruikt
In al deze gevallen wordt de oplossing bepaald door wat u denkt dat de oorzaak is.
Maar wat als er geen duidelijke rootcase is en de query gewoon duur genoeg wordt geacht om een parallel plan te rechtvaardigen?
Voorkomen van parallellisme
De Query Optimizer besluit onder meer een parallel queryplan te maken als het seriële plan hogere kosten heeft dan de cost threshold for parallelism , een sp_configure-instelling voor de instantie. De kostendrempel voor parallellisme (of CTFP) is standaard ingesteld op vijf, wat betekent dat een plan niet erg duur hoeft te zijn om de totstandkoming van een parallel plan te activeren.
Een van de gemakkelijkste manieren om ongewenst parallellisme te voorkomen, is door de CTFP naar een veel hoger getal te verhogen. Hoe hoger u het instelt, hoe kleiner de kans dat parallelle plannen worden gemaakt. Sommige mensen pleiten ervoor om CTFP ergens tussen 25 en 50 in te stellen, maar zoals bij alle aanpasbare instellingen, is het het beste om verschillende waarden te testen en te zien wat het beste werkt voor uw omgeving. Als je een wat meer programmatische methode wilt om een goede CTFP-waarde te kiezen, schreef Jonathan een blogpost met een vraag om de plancache te analyseren en een voorgestelde waarde voor CTFP te produceren. Als voorbeeld hebben we een client met CTFP ingesteld op 200 en een andere op het maximum - 32767 - als een manier om elke vorm van parallellisme met geweld te voorkomen.
Je vraagt je misschien af waarom de tweede client CTFP moest gebruiken als een voorhamermethode om parallellisme te voorkomen, terwijl je zou denken dat ze de 'max. mate van parallellisme' (of MAXDOP) van de server eenvoudig op 1 konden zetten. Nou, iedereen met elk toestemmingsniveau kan geef een query-MAXDOP-hint op en overschrijf de MAXDOP-instelling van de server, maar CTFP kan niet worden overschreven.
En dat is een andere methode om parallellisme te beperken:een MAXDOP-hint instellen op de query die u niet parallel wilt laten lopen.
Je kunt ook de MAXDOP-instelling van de server verlagen, maar dat is een drastische oplossing omdat het kan voorkomen dat alles parallellisme gebruikt. Het is tegenwoordig gebruikelijk dat servers gemengde workloads hebben, bijvoorbeeld met sommige OLTP-query's en sommige rapportagequery's. Als u de server MAXDOP verlaagt, gaat u de prestaties van de rapportagequery's belemmeren.
Een betere oplossing als er een gemengde werklast is, zou zijn om CTFP te gebruiken zoals ik hierboven heb beschreven of om Resource Governor te gebruiken (wat alleen voor Enterprise is, vrees ik). U kunt Resource Governor gebruiken om de werkbelastingen in werkbelastinggroepen te scheiden en vervolgens een MAX_DOP (het onderstrepingsteken is geen typfout) voor elke werkbelastinggroep instellen. En het goede aan het gebruik van Resource Governor is dat de MAX_DOP niet kan worden overschreven door een MAXDOP-queryhint.
Samenvatting
Trap niet in de val door te denken dat CXPACKET automatisch wacht op een slecht parallellisme, en volg zeker niet de internetadviezen die ik heb gezien over het dichtslaan van de server door MAXDOP in te stellen op 1. Neem de tijd om te onderzoeken waarom u ziet dat CXPACKET wacht en of het iets is dat moet worden aangepakt of slechts een artefact van een werkbelasting die correct wordt uitgevoerd.
Wat algemene wachtstatistieken betreft, kunt u meer informatie vinden over het gebruik ervan voor het oplossen van problemen met de prestaties in:
- Mijn serie SQLskills-blogposts, te beginnen met Wachtstatistieken, of vertel me alsjeblieft waar het pijn doet
- Mijn bibliotheek met wachttypes en vergrendelingsklassen hier
- Mijn online Pluralsight-trainingscursus SQL Server:prestatieproblemen oplossen met behulp van wachtstatistieken
- SQL Sentry Performance Advisor
In het volgende artikel in de serie zal ik scheef parallellisme bespreken en je een eenvoudige manier geven om het te zien gebeuren. Tot dan, veel plezier met het oplossen van problemen!