Historisch gezien was de moeilijkste taak bij het werken met PostgreSQL het omgaan met de upgrades. De meest intuïtieve upgrade-manier die u kunt bedenken, is door een replica in een nieuwe versie te genereren en een failover van de toepassing erin uit te voeren. Met PostgreSQL was dit gewoon niet mogelijk op een native manier. Om upgrades uit te voeren, moest je andere manieren van upgraden bedenken, zoals het gebruik van pg_upgrade, dumpen en herstellen, of het gebruik van tools van derden, zoals Slony of Bucardo, die allemaal hun eigen kanttekeningen hebben.
Waarom was dit? Vanwege de manier waarop PostgreSQL replicatie implementeert.
Ingebouwde PostgreSQL-streamingreplicatie is wat fysiek wordt genoemd:het repliceert de wijzigingen op byte-per-byte-niveau, waardoor een identieke kopie van de database op een andere server wordt gemaakt. Deze methode heeft veel beperkingen bij het bedenken van een upgrade, omdat je simpelweg geen replica kunt maken in een andere serverversie of zelfs in een andere architectuur.
Dus hier is waar PostgreSQL 10 een game-wisselaar wordt. Met deze nieuwe versies 10 en 11 implementeert PostgreSQL ingebouwde logische replicatie die u, in tegenstelling tot fysieke replicatie, kunt repliceren tussen verschillende hoofdversies van PostgreSQL. Dit opent natuurlijk een nieuwe deur voor het upgraden van strategieën.
Laten we in deze blog kijken hoe we onze PostgreSQL 10 kunnen upgraden naar PostgreSQL 11 zonder downtime met behulp van logische replicatie. Laten we eerst een inleiding tot logische replicatie doornemen.
Wat is logische replicatie?
Logische replicatie is een methode voor het repliceren van gegevensobjecten en hun wijzigingen, op basis van hun replicatie-identiteit (meestal een primaire sleutel). Het is gebaseerd op een publicatie- en abonnementsmodus, waarbij een of meer abonnees zich abonneren op een of meer publicaties op een uitgeversknooppunt.
Een publicatie is een set wijzigingen die is gegenereerd op basis van een tabel of een groep tabellen (ook wel replicatieset genoemd). Het knooppunt waar een publicatie is gedefinieerd, wordt uitgever genoemd. Een abonnement is de downstream-kant van logische replicatie. Het knooppunt waar een abonnement is gedefinieerd, wordt de abonnee genoemd en definieert de verbinding met een andere database en reeks publicaties (een of meer) waarop het zich wil abonneren. Abonnees halen gegevens uit de publicaties waarop ze geabonneerd zijn.
Logische replicatie is gebouwd met een architectuur die vergelijkbaar is met fysieke streamingreplicatie. Het wordt geïmplementeerd door "walsender" en "apply"-processen. Het walsender-proces start de logische decodering van de WAL en laadt de standaard plug-in voor logische decodering. De plug-in transformeert de gelezen wijzigingen van WAL naar het logische replicatieprotocol en filtert de gegevens volgens de publicatiespecificatie. De gegevens worden vervolgens continu overgedragen met behulp van het streaming-replicatieprotocol naar de toepassingswerker, die de gegevens toewijst aan lokale tabellen en de individuele wijzigingen toepast zodra ze worden ontvangen, in een correcte transactievolgorde.
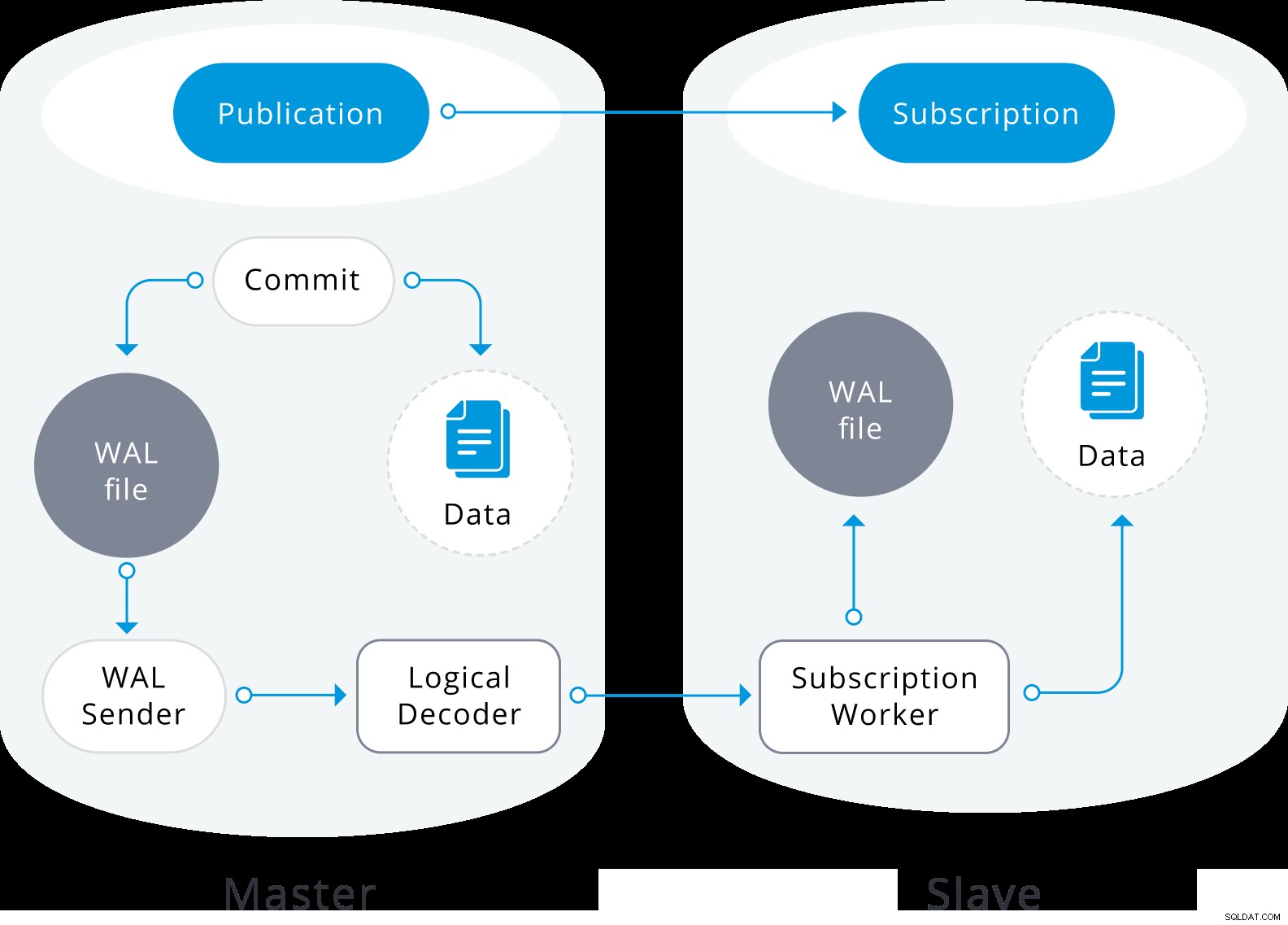 Logisch replicatiediagram
Logisch replicatiediagram Logische replicatie begint door een momentopname te maken van de gegevens in de uitgeversdatabase en die naar de abonnee te kopiëren. De initiële gegevens in de bestaande geabonneerde tabellen worden snapshots genomen en gekopieerd in een parallelle instantie van een speciaal soort toepassingsproces. Dit proces maakt een eigen tijdelijke replicatiesleuf en kopieert de bestaande gegevens. Zodra de bestaande gegevens zijn gekopieerd, gaat de werknemer naar de synchronisatiemodus, die ervoor zorgt dat de tabel in een gesynchroniseerde staat wordt gebracht met het hoofdtoepassingsproces door alle wijzigingen die tijdens de eerste gegevenskopie hebben plaatsgevonden, te streamen met behulp van standaard logische replicatie. Zodra de synchronisatie is voltooid, wordt de controle over de replicatie van de tabel teruggegeven aan het hoofdtoepassingsproces waar de replicatie gewoon doorgaat. De wijzigingen op de uitgever worden in realtime naar de abonnee verzonden.
U kunt meer vinden over logische replicatie in de volgende blogs:
- Een overzicht van logische replicatie in PostgreSQL
- PostgreSQL-streamingreplicatie versus logische replicatie
PostgreSQL 10 upgraden naar PostgreSQL 11 met logische replicatie
Nu we dus weten waar deze nieuwe functie over gaat, kunnen we nadenken over hoe we deze kunnen gebruiken om het upgradeprobleem op te lossen.
We gaan logische replicatie configureren tussen twee verschillende hoofdversies van PostgreSQL (10 en 11), en natuurlijk, nadat je dit hebt laten werken, is het alleen een kwestie van een applicatie-failover in de database uitvoeren met de nieuwere versie.
We gaan de volgende stappen uitvoeren om logische replicatie te laten werken:
- Configureer het uitgeversknooppunt
- Configureer het abonneeknooppunt
- Maak de abonneegebruiker
- Maak een publicatie
- Maak de tabelstructuur in de abonnee
- Maak het abonnement
- Controleer de replicatiestatus
Dus laten we beginnen.
Aan de uitgeverskant gaan we de volgende parameters configureren in het postgresql.conf-bestand:
- listen_addresses:op welk(e) IP-adres(sen) moet worden geluisterd. We gebruiken '*' voor iedereen.
- wal_level:bepaalt hoeveel informatie naar de WAL wordt geschreven. We gaan het op logisch zetten.
- max_replication_slots:specificeert het maximum aantal replicatiesleuven dat de server kan ondersteunen. Het moet worden ingesteld op ten minste het aantal abonnementen dat naar verwachting verbinding zal maken, plus enige reserve voor tafelsynchronisatie.
- max_wal_senders:specificeert het maximum aantal gelijktijdige verbindingen vanaf stand-by servers of streaming-basisback-upclients. Het moet worden ingesteld op ten minste hetzelfde als max_replication_slots plus het aantal fysieke replica's dat tegelijkertijd is verbonden.
Houd er rekening mee dat voor sommige van deze parameters een herstart van de PostgreSQL-service vereist was.
Het bestand pg_hba.conf moet ook worden aangepast om replicatie mogelijk te maken. We moeten de replicatiegebruiker toestaan verbinding te maken met de database.
Laten we op basis hiervan onze uitgever (in dit geval onze PostgreSQL 10-server) als volgt configureren:
- postgresql.conf:
listen_addresses = '*' wal_level = logical max_wal_senders = 8 max_replication_slots = 4 - pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD host all rep 192.168.100.144/32 md5
We moeten de gebruiker wijzigen (in ons voorbeeld rep), die zal worden gebruikt voor replicatie, en het IP-adres 192.168.100.144/32 voor het IP-adres dat overeenkomt met onze PostgreSQL 11.
Aan de abonneezijde moeten ook de max_replication_slots worden ingesteld. In dit geval moet het worden ingesteld op ten minste het aantal abonnementen dat aan de abonnee wordt toegevoegd.
De andere parameters die hier ook moeten worden ingesteld zijn:
- max_logical_replication_workers:Specificeert het maximum aantal logische replicatieworkers. Dit omvat zowel werknemers voor toepassing als tabelsynchronisatie. Werknemers voor logische replicatie worden genomen uit de pool die is gedefinieerd door max_worker_processes. Het moet worden ingesteld op ten minste het aantal abonnementen, plus wat reserve voor de tafelsynchronisatie.
- max_worker_processes:Stelt het maximum aantal achtergrondprocessen in dat het systeem kan ondersteunen. Het moet mogelijk worden aangepast om plaats te bieden aan replicatiewerkers, ten minste max_logical_replication_workers + 1. Voor deze parameter is een PostgreSQL-herstart vereist.
We moeten onze abonnee (in dit geval onze PostgreSQL 11-server) dus als volgt configureren:
- postgresql.conf:
listen_addresses = '*' max_replication_slots = 4 max_logical_replication_workers = 4 max_worker_processes = 8
Aangezien deze PostgreSQL 11 binnenkort onze nieuwe master zal zijn, moeten we overwegen om de parameters wal_level en archive_mode in deze stap toe te voegen, om te voorkomen dat de service later opnieuw wordt opgestart.
wal_level = logical
archive_mode = onDeze parameters zijn handig als we een nieuwe replicatieslave willen toevoegen of voor het gebruik van PITR-back-ups.
In de uitgever moeten we de gebruiker maken waarmee onze abonnee verbinding zal maken:
world=# CREATE ROLE rep WITH LOGIN PASSWORD '*****' REPLICATION;
CREATE ROLEDe rol die voor de replicatieverbinding wordt gebruikt, moet het kenmerk REPLICATION hebben. Toegang voor de rol moet worden geconfigureerd in pg_hba.conf en moet het kenmerk LOGIN hebben.
Om de initiële gegevens te kunnen kopiëren, moet de rol die wordt gebruikt voor de replicatieverbinding het SELECT-privilege hebben op een gepubliceerde tabel.
world=# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep;
GRANTWe zullen pub1-publicatie maken in het uitgeversknooppunt, voor alle tabellen:
world=# CREATE PUBLICATION pub1 FOR ALL TABLES;
CREATE PUBLICATIONDe gebruiker die een publicatie maakt, moet het CREATE-privilege in de database hebben, maar om een publicatie te maken die alle tabellen automatisch publiceert, moet de gebruiker een superuser zijn.
Om de gemaakte publicatie te bevestigen, gaan we de pg_publication-catalogus gebruiken. Deze catalogus bevat informatie over alle publicaties die in de database zijn aangemaakt.
world=# SELECT * FROM pg_publication;
-[ RECORD 1 ]+------
pubname | pub1
pubowner | 16384
puballtables | t
pubinsert | t
pubupdate | t
pubdelete | tKolombeschrijvingen:
- pubname:naam van de publicatie.
- pubowner:Eigenaar van de publicatie.
- puballtables:indien waar, bevat deze publicatie automatisch alle tabellen in de database, inclusief alle tabellen die in de toekomst zullen worden gemaakt.
- pubinsert:indien waar, worden INSERT-bewerkingen gerepliceerd voor tabellen in de publicatie.
- pubupdate:Indien waar, worden UPDATE-bewerkingen gerepliceerd voor tabellen in de publicatie.
- pubdelete:indien waar, worden DELETE-bewerkingen gerepliceerd voor tabellen in de publicatie.
Omdat het schema niet wordt gerepliceerd, moeten we een back-up maken in PostgreSQL 10 en deze herstellen in onze PostgreSQL 11. De back-up wordt alleen gemaakt voor het schema, omdat de informatie bij de eerste overdracht wordt gerepliceerd.
In PostgreSQL 10:
$ pg_dumpall -s > schema.sqlIn PostgreSQL 11:
$ psql -d postgres -f schema.sqlZodra we ons schema in PostgreSQL 11 hebben, maken we het abonnement, waarbij we de waarden van host, dbname, gebruiker en wachtwoord vervangen door de waarden die overeenkomen met onze omgeving.
PostgreSQL 11:
world=# CREATE SUBSCRIPTION sub1 CONNECTION 'host=192.168.100.143 dbname=world user=rep password=*****' PUBLICATION pub1;
NOTICE: created replication slot "sub1" on publisher
CREATE SUBSCRIPTIONHet bovenstaande start het replicatieproces, dat de initiële tabelinhoud van de tabellen in de publicatie synchroniseert en vervolgens begint met het repliceren van incrementele wijzigingen in die tabellen.
De gebruiker die een abonnement aanmaakt, moet een supergebruiker zijn. Het proces voor het aanvragen van een abonnement wordt uitgevoerd in de lokale database met de rechten van een supergebruiker.
Om het aangemaakte abonnement te verifiëren, kunnen we de pg_stat_subscription-catalogus gebruiken. Deze weergave bevat één rij per abonnement voor de hoofdwerker (met null-PID als de werknemer niet actief is) en extra rijen voor werknemers die de eerste gegevenskopie van de geabonneerde tabellen verwerken.
world=# SELECT * FROM pg_stat_subscription;
-[ RECORD 1 ]---------+------------------------------
subid | 16428
subname | sub1
pid | 1111
relid |
received_lsn | 0/172AF90
last_msg_send_time | 2018-12-05 22:11:45.195963+00
last_msg_receipt_time | 2018-12-05 22:11:45.196065+00
latest_end_lsn | 0/172AF90
latest_end_time | 2018-12-05 22:11:45.195963+00Kolombeschrijvingen:
- subid:OID van het abonnement.
- subnaam:naam van het abonnement.
- pid:proces-ID van het abonnementswerkproces.
- relid:OID van de relatie die de worker aan het synchroniseren is; null voor de belangrijkste sollicitant.
- received_lsn:laatst ontvangen loglocatie voor vooruitschrijven, waarbij de initiële waarde van dit veld 0 is.
- last_msg_send_time:Verzendtijd van het laatste bericht ontvangen van de oorspronkelijke WAL-afzender.
- last_msg_receipt_time:Ontvangsttijd van het laatste bericht ontvangen van de oorspronkelijke WAL-afzender.
- latest_end_lsn:Laatste write-ahead loglocatie gerapporteerd aan oorspronkelijke WAL-afzender.
- latest_end_time:Tijd van de laatste write-ahead loglocatie gerapporteerd aan de oorspronkelijke WAL-afzender.
Om de status van replicatie in de master te verifiëren, kunnen we pg_stat_replication gebruiken:
world=# SELECT * FROM pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 1178
usesysid | 16427
usename | rep
application_name | sub1
client_addr | 192.168.100.144
client_hostname |
client_port | 58270
backend_start | 2018-12-05 22:11:45.097539+00
backend_xmin |
state | streaming
sent_lsn | 0/172AF90
write_lsn | 0/172AF90
flush_lsn | 0/172AF90
replay_lsn | 0/172AF90
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | asyncKolombeschrijvingen:
- pid:proces-ID van een WAL-afzenderproces.
- usesysid:OID van de gebruiker die is aangemeld bij dit WAL-afzenderproces.
- usename:naam van de gebruiker die is aangemeld bij dit WAL-afzenderproces.
- application_name:Naam van de applicatie die is verbonden met deze WAL-afzender.
- client_addr:IP-adres van de client die is verbonden met deze WAL-afzender. Als dit veld null is, geeft dit aan dat de client is verbonden via een Unix-socket op de servermachine.
- client_hostname:Hostnaam van de verbonden client, zoals gerapporteerd door een reverse DNS-lookup van client_addr. Dit veld is alleen niet-null voor IP-verbindingen en alleen als log_hostname is ingeschakeld.
- client_port:TCP-poortnummer dat de client gebruikt voor communicatie met deze WAL-zender, of -1 als een Unix-socket wordt gebruikt.
- backend_start:Tijd waarop dit proces is gestart.
- backend_xmin:de xmin-horizon van deze stand-by, gerapporteerd door hot_standby_feedback.
- status:huidige WAL-afzenderstatus. De mogelijke waarden zijn:opstarten, inhalen, streamen, back-up en stoppen.
- sent_lsn:Laatste schrijf-ahead loglocatie verzonden via deze verbinding.
- write_lsn:Laatste write-ahead loglocatie die door deze standby-server naar schijf is geschreven.
- flush_lsn:Laatste write-ahead loglocatie naar schijf gewist door deze standby-server.
- replay_lsn:de locatie van het laatst teruggeschreven logbestand is opnieuw afgespeeld in de database op deze standby-server.
- write_lag:tijd verstreken tussen het lokaal wissen van recente WAL en het ontvangen van een melding dat deze standby-server het heeft geschreven (maar nog niet heeft gewist of toegepast).
- flush_lag:tijd verstreken tussen het lokaal wissen van recente WAL en het ontvangen van de melding dat deze standby-server het heeft geschreven en gewist (maar nog niet heeft toegepast).
- replay_lag:tijd verstreken tussen het lokaal wissen van recente WAL en het ontvangen van een melding dat deze standby-server deze heeft geschreven, gewist en toegepast.
- sync_priority:prioriteit van deze standby-server om te worden gekozen als de synchrone standby in een op prioriteit gebaseerde synchrone replicatie.
- sync_state:Synchrone status van deze standby-server. De mogelijke waarden zijn async, potential, sync, quorum.
Om te controleren wanneer de eerste overdracht is voltooid, kunnen we het PostgreSQL-logboek op de abonnee zien:
2018-12-05 22:11:45.096 UTC [1111] LOG: logical replication apply worker for subscription "sub1" has started
2018-12-05 22:11:45.103 UTC [1112] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has started
2018-12-05 22:11:45.114 UTC [1113] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has started
2018-12-05 22:11:45.156 UTC [1112] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has finished
2018-12-05 22:11:45.162 UTC [1114] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has started
2018-12-05 22:11:45.168 UTC [1113] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has finished
2018-12-05 22:11:45.206 UTC [1114] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has finishedOf het controleren van de srsubstate-variabele in de pg_subscription_rel-catalogus. Deze catalogus bevat de status voor elke gerepliceerde relatie in elk abonnement.
world=# SELECT * FROM pg_subscription_rel;
-[ RECORD 1 ]---------
srsubid | 16428
srrelid | 16387
srsubstate | r
srsublsn | 0/172AF20
-[ RECORD 2 ]---------
srsubid | 16428
srrelid | 16393
srsubstate | r
srsublsn | 0/172AF58
-[ RECORD 3 ]---------
srsubid | 16428
srrelid | 16400
srsubstate | r
srsublsn | 0/172AF90Kolombeschrijvingen:
- srsubid:verwijzing naar abonnement.
- srrelid:verwijzing naar relatie.
- srsubstate:Statuscode:i =initialiseren, d =gegevens worden gekopieerd, s =gesynchroniseerd, r =gereed (normale replicatie).
- srsublsn:LSN beëindigen voor s- en r-statussen.
We kunnen enkele testrecords in onze PostgreSQL 10 invoegen en valideren dat we ze in onze PostgreSQL 11 hebben:
PostgreSQL 10:
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5001,'city1','USA','District1',10000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5002,'city2','ITA','District2',20000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5003,'city3','CHN','District3',30000);
INSERT 0 1PostgreSQL 11:
world=# SELECT * FROM city WHERE id>5000;
id | name | countrycode | district | population
------+-------+-------------+-----------+------------
5001 | city1 | USA | District1 | 10000
5002 | city2 | ITA | District2 | 20000
5003 | city3 | CHN | District3 | 30000
(3 rows)Op dit moment hebben we alles klaar om onze applicatie naar onze PostgreSQL 11 te verwijzen.
Hiervoor moeten we allereerst bevestigen dat we geen replicatievertraging hebben.
Op de master:
world=# SELECT application_name, pg_wal_lsn_diff(pg_current_wal_lsn(), replay_lsn) lag FROM pg_stat_replication;
-[ RECORD 1 ]----+-----
application_name | sub1
lag | 0En nu hoeven we alleen ons eindpunt van onze applicatie of load balancer (als we die hebben) te veranderen naar de nieuwe PostgreSQL 11-server.
Als we een load balancer zoals HAProxy hebben, kunnen we deze configureren met de PostgreSQL 10 als actief en de PostgreSQL 11 als back-up, op deze manier:
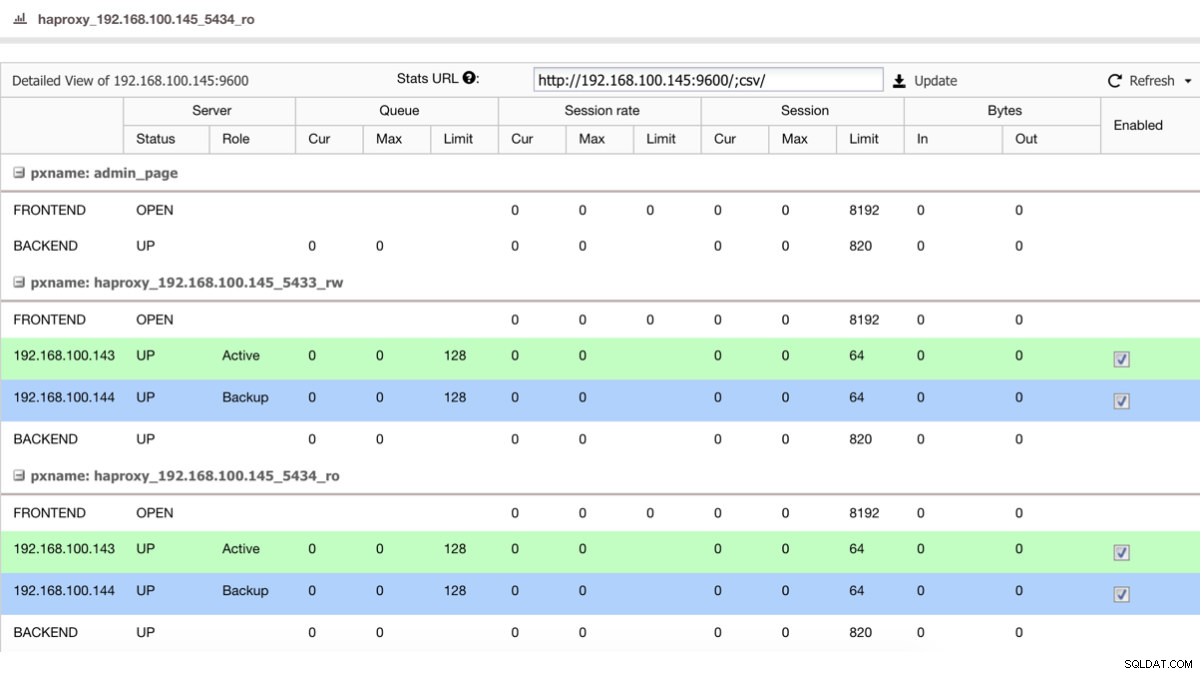 HAProxy-statusweergave
HAProxy-statusweergave Dus als u de master in PostgreSQL 10 gewoon afsluit, begint de back-upserver, in dit geval in PostgreSQL 11, het verkeer op een transparante manier voor de gebruiker/toepassing te ontvangen.
Aan het einde van de migratie kunnen we het abonnement in onze nieuwe master in PostgreSQL 11 verwijderen:
world=# DROP SUBSCRIPTION sub1;
NOTICE: dropped replication slot "sub1" on publisher
DROP SUBSCRIPTIONEn controleer of het correct is verwijderd:
world=# SELECT * FROM pg_subscription_rel;
(0 rows)
world=# SELECT * FROM pg_stat_subscription;
(0 rows)Beperkingen
Houd rekening met de volgende beperkingen voordat u de logische replicatie gebruikt:
- Het databaseschema en de DDL-opdrachten worden niet gerepliceerd. Het initiële schema kan worden gekopieerd met pg_dump --schema-only.
- Sequentiegegevens worden niet gerepliceerd. De gegevens in seriële of identiteitskolommen die worden ondersteund door reeksen, worden gerepliceerd als onderdeel van de tabel, maar de reeks zelf geeft nog steeds de startwaarde van de abonnee weer.
- Replicatie van TRUNCATE-commando's wordt ondersteund, maar enige voorzichtigheid is geboden bij het afkappen van groepen tabellen die zijn verbonden door externe sleutels. Bij het repliceren van een afkapactie zal de abonnee dezelfde groep tabellen afkappen die op de uitgever is afgekapt, ofwel expliciet gespecificeerd of impliciet verzameld via CASCADE, minus tabellen die geen deel uitmaken van het abonnement. Dit werkt correct als alle betrokken tabellen deel uitmaken van hetzelfde abonnement. Maar als sommige tabellen die op de abonnee moeten worden afgekapt, externe-sleutelkoppelingen hebben naar tabellen die geen deel uitmaken van hetzelfde (of een willekeurig) abonnement, dan zal de toepassing van de afkapactie op de abonnee mislukken.
- Grote objecten worden niet gerepliceerd. Daar is geen oplossing voor, behalve het opslaan van gegevens in normale tabellen.
- Replicatie is alleen mogelijk van basistabellen naar basistabellen. Dat wil zeggen, de tabellen aan de publicatie- en aan de abonnementszijde moeten normale tabellen zijn, geen views, gematerialiseerde views, partitie-roottabellen of vreemde tabellen. In het geval van partities kunt u een partitiehiërarchie één-op-één repliceren, maar u kunt momenteel niet repliceren naar een anders gepartitioneerde opstelling.
Conclusie
Uw PostgreSQL-server up-to-date houden door regelmatige upgrades uit te voeren was een noodzakelijke maar moeilijke taak tot de PostgreSQL 10-versie.
In deze blog hebben we een korte introductie gegeven tot logische replicatie, een PostgreSQL-functie die native is geïntroduceerd in versie 10, en we hebben je laten zien hoe het je kan helpen deze uitdaging aan te gaan zonder downtime-strategie.