Het is goed, maar kan soms ook slecht zijn.
Het snuiven van parameters gaat over de query-optimizer die de waarde van de opgegeven parameter gebruikt om het best mogelijke queryplan te vinden. Een van de vele keuzes en een die vrij gemakkelijk te begrijpen is, is of de hele tabel moet worden gescand om de waarden te krijgen of dat het sneller zal zijn met behulp van indexzoekopdrachten. Als de waarde in uw parameter zeer selectief is, zal de optimizer waarschijnlijk een queryplan maken met seeks en als dit niet het geval is, zal de query een scan van uw tabel uitvoeren.
Het queryplan wordt vervolgens in de cache opgeslagen en opnieuw gebruikt voor opeenvolgende query's met verschillende waarden. Het slechte deel van het snuiven van parameters is wanneer het in de cache opgeslagen plan niet de beste keuze is voor een van die waarden.
Voorbeeldgegevens:
create table T
(
ID int identity primary key,
Value int not null,
AnotherValue int null
);
create index IX_T_Value on T(Value);
insert into T(Value) values(1);
insert into T(Value)
select 2
from sys.all_objects;
T is een tabel met een paar duizend rijen met een niet-geclusterde index op Value. Er is één rij waar de waarde 1 is en de rest heeft de waarde 2 .
Voorbeeldzoekopdracht:
select *
from T
where Value = @Value;
De keuzes die de query-optimizer hier heeft, zijn om ofwel een geclusterde indexscan uit te voeren en de waar-clausule tegen elke rij te controleren of een indexzoekopdracht te gebruiken om rijen te vinden die overeenkomen en vervolgens een sleutelzoekopdracht uit te voeren om de waarden uit de kolommen te krijgen waarnaar wordt gevraagd in de kolomlijst.
Wanneer de gesnoven waarde 1 is het zoekplan ziet er als volgt uit:

En wanneer de gesnoven waarde 2 is het ziet er zo uit:
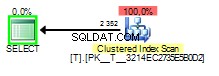
Het slechte deel van het snuiven van parameters vindt in dit geval plaats wanneer het queryplan wordt gebouwd met het snuiven van een 1 maar later uitgevoerd met de waarde 2 .
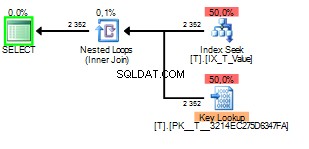
U kunt zien dat de Key Lookup 2352 keer is uitgevoerd. Een scan zou duidelijk de betere keuze zijn.
Om samen te vatten, zou ik zeggen dat het snuiven van parameters een goede zaak is en dat je moet proberen om zoveel mogelijk te laten gebeuren door parameters voor je vragen te gebruiken. Soms kan het fout gaan en in die gevallen is het hoogstwaarschijnlijk te wijten aan scheve gegevens die knoeien met uw statistieken.
Bijwerken:
Hier is een zoekopdracht tegen een aantal dmv's die u kunt gebruiken om te achterhalen welke zoekopdrachten het duurst zijn op uw systeem. Wijzig de volgorde per clausule om verschillende criteria te gebruiken voor wat u zoekt. Ik denk dat TotalDuration is een goede plek om te beginnen.
set transaction isolation level read uncommitted;
select top(10)
PlanCreated = qs.creation_time,
ObjectName = object_name(st.objectid),
QueryPlan = cast(qp.query_plan as xml),
QueryText = substring(st.text, 1 + (qs.statement_start_offset / 2), 1 + ((isnull(nullif(qs.statement_end_offset, -1), datalength(st.text)) - qs.statement_start_offset) / 2)),
ExecutionCount = qs.execution_count,
TotalRW = qs.total_logical_reads + qs.total_logical_writes,
AvgRW = (qs.total_logical_reads + qs.total_logical_writes) / qs.execution_count,
TotalDurationMS = qs.total_elapsed_time / 1000,
AvgDurationMS = qs.total_elapsed_time / qs.execution_count / 1000,
TotalCPUMS = qs.total_worker_time / 1000,
AvgCPUMS = qs.total_worker_time / qs.execution_count / 1000,
TotalCLRMS = qs.total_clr_time / 1000,
AvgCLRMS = qs.total_clr_time / qs.execution_count / 1000,
TotalRows = qs.total_rows,
AvgRows = qs.total_rows / qs.execution_count
from sys.dm_exec_query_stats as qs
cross apply sys.dm_exec_sql_text(qs.sql_handle) as st
cross apply sys.dm_exec_text_query_plan(qs.plan_handle, qs.statement_start_offset, qs.statement_end_offset) as qp
--order by ExecutionCount desc
--order by TotalRW desc
order by TotalDurationMS desc
--order by AvgDurationMS desc
;