Er is zoveel dat je kunt zeggen over geschiedenis en belang. Geschiedenis van een land, van beschaving, van ieder van ons. Ik hou van citaten en zoals deze van Teddy Roosevelt (coole kerel):
Hoe meer je weet over het verleden, hoe beter je voorbereid bent op de toekomst.Waarom ben ik poëtisch (of probeer ik) over geschiedenis in een blog over SQL Server? Omdat geschiedenis in SQL Server ook belangrijk is. Wanneer er een prestatieprobleem bestaat in SQL Server, is het ideaal om het probleem live op te lossen, maar in sommige gevallen kan historische informatie een rokend wapen zijn, of op zijn minst een startpunt. Een geweldige bron van historische informatie in SQL Server is de ERRORLOG. Ik vermeldde in mijn oorspronkelijke bericht, Prestatieproblemen:de eerste ontmoeting, dat de ERRORLOG voor mij een bijzaak was. Niet meer. Tijdens klantaudits leggen we altijd de ERRORLOG's vast, en hoewel we op de hoogte worden gebracht van zeer ernstige waarschuwingen (die naar het logboek worden geschreven), is het niet ongehoord om andere interessante informatie in het logboek te vinden. We bereiden ons voor op de toekomst door gebruik te maken van de historische info in de logs; de informatie kan ons helpen een probleem of potentieel probleem op te lossen voordat het catastrofaal wordt.
Het ERRORLOG bekijken
Allereerst zullen we enkele opties bekijken voor het bekijken van de ERROLOG. Als ik verbonden ben met een instantie, navigeer ik er meestal naartoe via SSMS (Beheer | SQL Server-logboeken, klik met de rechtermuisknop op een logboek en selecteer SQL Server-logboek weergeven). Vanuit dit venster kan ik gewoon door het logboek scrollen of de filter- of zoekopties gebruiken om de resultatenset te verfijnen. Ik kan ook meerdere bestanden bekijken door ze in het linkerdeelvenster te selecteren.
Als ik naar gegevens kijk die zijn vastgelegd in een van onze gezondheidsaudits, open ik de logbestanden in een teksteditor en bekijk ik ze (ik heb wel de mogelijkheid om naar de viewer te gaan en ze ook te laden). De logbestanden staan in de logmap (standaardlocatie:C:\Program Files\Microsoft SQL Server\MSSQL12.SQL2014\MSSQL\Log) als ik ze ooit op de server wilde bekijken. Velen van jullie geven er misschien de voorkeur aan om het logboek te bekijken en/of te doorzoeken met behulp van de ongedocumenteerde procedure sp_readerrorlog of uitgebreide opgeslagen procedure xp_readerrorlog.
En tot slot, als je helemaal van PowerShell houdt, is dat ook een optie om het logboek op die manier te lezen (zie dit bericht:PowerShell gebruiken om SQL Server 2012-foutlogboeken te ontleden). De methode is aan jou - gebruik wat je weet en wat voor jou werkt - het is de inhoud die er echt toe doet. En onthoud dat er momenten zijn waarop u eenvoudigweg het logboek moet lezen om de volgorde van de gebeurtenissen te begrijpen, en er zijn andere momenten waarop u naar een specifieke fout of informatie kunt zoeken.
Wat staat er in het ERRORLOG?
Dus welke informatie kunnen we behalve fouten in het ERRORLOG vinden? Ik heb hieronder veel van de items vermeld die ik het nuttigst vond. Merk op dat dit geen uitputtende lijst is (en ik weet zeker dat velen van jullie suggesties zullen hebben over wat er zou kunnen worden toegevoegd - voel je vrij om een opmerking te plaatsen en ik kan dit bijwerken!), maar nogmaals, dit is wat ik ben op zoek naar eerste wanneer ik proactief naar een instantie kijk.
- Of de server nu fysiek of virtueel is (kijk naar de vermelding Systeemfabrikant)
- Trace-vlaggen ingeschakeld bij opstarten
- Als u in de invoer voor de opstartparameters van het register helemaal naar rechts scrolt, ziet u of er traceervlaggen zijn ingeschakeld:
 Traceervlaggen ingeschakeld bij opstarten
Traceervlaggen ingeschakeld bij opstarten
- Als u in de invoer voor de opstartparameters van het register helemaal naar rechts scrolt, ziet u of er traceervlaggen zijn ingeschakeld:
- Trace-vlaggen ingeschakeld of uitgeschakeld nadat de instantie is gestart
- Als gebruikers (of een toepassing) een traceringsvlag in- of uitschakelen met DBCC TRACEON of DBCC TRACEOFF, verschijnt er een vermelding in het logboek
- Aantal cores en sockets gedetecteerd door SQL Server
- Ik verifieer altijd graag dat SQL Server alle beschikbare hardware ziet - en zo niet, dan is dat een rode vlag om verder te onderzoeken. Zie voor een goed voorbeeld het bericht van Jonathan, Performance Problems with SQL Server 0212 Enterprise Edition Under CAL Licensing, en Glenn's post, Balancing Your Available SQL Server Core Licenses Equly Across NUMA Nodes, dat ook enkele handige TSQL bevat om het logboek te doorzoeken.
- Houd er rekening mee dat de tekst voor dit item verschilt tussen SQL Server-versies.
- Hoeveelheid geheugen gedetecteerd door SQL Server
- Nogmaals, ik wil controleren of SQL Server al het beschikbare geheugen ziet.
- Bevestiging dat Vergrendelde pagina's in geheugen (LPIM) is ingeschakeld
- Hoewel deze optie is ingeschakeld via het Windows-beveiligingsbeleid, kunt u controleren of deze is ingeschakeld door te zoeken naar het bericht 'Vergrendelde pagina's in geheugenbeheer gebruiken' in het logboek.
- Houd er rekening mee dat als u Trace Flag 834 in gebruik heeft, het bericht geen vergrendelde pagina's zal zeggen, maar dat er grote pagina's worden gebruikt voor de bufferpool.
- Versie van CLR in gebruik
- Succes of mislukking van de Service Principal Name (SPN)-registratie
- Hoe lang duurt het voordat een database online komt
- Het logboek registreert wanneer de database opstart en wanneer deze online is - ik controleer of een database buitensporig veel tijd nodig heeft om op te komen.
- Status van Service Broker en Database Mirroring-eindpunten – belangrijk als u een van beide functies gebruikt
- Bevestiging dat Instant File Initialization (IFI) is ingeschakeld*
- Standaard wordt deze informatie niet gelogd, maar als u Trace Flag 3004 inschakelt (en 3605 om de uitvoer naar het logboek te forceren), wanneer u een gegevensbestand maakt of laat groeien, ziet u berichten in het logboek om aan te geven of IFI is in gebruik of niet.
- Status van SQL-sporen
- Als je een SQL-tracering start of stopt, wordt deze gelogd en kijk ik of er sporen zijn die verder gaan dan de standaardtracering (tijdelijk of langdurig). Als u een monitoringtool van derden gebruikt, zoals de Performance Advisor van SQL Sentry, ziet u mogelijk een actieve tracering die altijd actief is, maar alleen specifieke gebeurtenissen vastlegt, of u ziet mogelijk een traceerstart, wordt voor een korte duur uitgevoerd en vervolgens stop. Ik maak me geen zorgen over een of twee extra sporen, tenzij ze veel gebeurtenissen vastleggen, maar ik let zeker op wanneer er meerdere sporen worden uitgevoerd.
- De laatste keer dat CHECKDB werd voltooid
- Dit bericht wordt vaak verkeerd begrepen door mensen - wanneer de instantie opstart, leest het de opstartpagina voor elke database en merkt het op wanneer CHECKDB voor het laatst succesvol is uitgevoerd. De meeste mensen lezen niet het hele bericht:
 Datum waarop DBCC CHECKDB voor het laatst met succes is voltooid
Datum waarop DBCC CHECKDB voor het laatst met succes is voltooid De datum voor voltooiing van CHECKDB is 11 november 2012, maar de ERRORLOG-datum is 7 juli 2015. Het is belangrijk om te begrijpen dat SQL Server niet doet. voer CHECKDB uit tegen databases bij het opstarten, het controleert de dbcclastknowngood-waarde op de opstartpagina (om te zien wanneer dat wordt bijgewerkt, bekijk mijn bericht, What Checks Update dbcclastknowngood. Ook als DBCC CHECKDB nog nooit tegen een database is uitgevoerd, dan is er geen invoer zal hier voor de database verschijnen.
- Dit bericht wordt vaak verkeerd begrepen door mensen - wanneer de instantie opstart, leest het de opstartpagina voor elke database en merkt het op wanneer CHECKDB voor het laatst succesvol is uitgevoerd. De meeste mensen lezen niet het hele bericht:
- CHECKDB voltooiing
- Als CHECKDB wordt uitgevoerd tegen een database, wordt de uitvoer vastgelegd in het logboek.
- Wijzigingen in instantie-instellingen
- Als u instellingen op instantieniveau wijzigt (bijv. max. servergeheugen, kostendrempel voor parallellisme) met sp_configure of via de gebruikersinterface (merk op dat wie niet wordt geregistreerd heb het gewijzigd).
- Wijzigingen in database-instellingen
- Heeft iemand AUTO_SHRINK ingeschakeld? De HERSTEL-optie wijzigen in EENVOUDIG en dan terug naar VOLLEDIG? Je vindt het hier.
- Wijzigingen in databasestatus
- Als iemand een database OFFLINE neemt (of ONLINE brengt), wordt dit gelogd.
- Deadlock-informatie*
- Als u deadlock-informatie moet vastleggen, geen tracering wilt uitvoeren, en u gebruikt SQL Server 2005 tot en met 2008R2, gebruik traceringsvlag 1222 om deadlock-informatie naar het logboek te schrijven in XML-indeling. Voor degenen onder u die SQL Server 2000 en lager gebruiken, kunt u vlag 1204 traceren (deze traceringsvlag is ook beschikbaar in SQL Server 2005+, maar levert minimale informatie op). Als u SQL Server 2012 of hoger gebruikt, is dit niet nodig, aangezien de system_health-gebeurtenissessie deze informatie vastlegt (en het is er ook in 2008 en 20082, maar u moet het uit de ring_buffer versus het event_file-doel halen).
- FlushCache-berichten
- Als de cache wordt leeggemaakt door SQL Server omdat het controlepuntproces het herstelinterval voor de database overschrijdt, ziet u een reeks FlushCache-berichten in het logboek (zie dit bericht van Bob Dorr voor meer informatie). Verwar deze berichten niet met de berichten die verschijnen wanneer u DBCC FREEPROCCACHE of DBCC FREESYSTEMCACHE uitvoert:
 Bericht na het uitvoeren van DBCC FREEPROCCACHE of DBCC FREESYSTEMCACHE
Bericht na het uitvoeren van DBCC FREEPROCCACHE of DBCC FREESYSTEMCACHE
- Als de cache wordt leeggemaakt door SQL Server omdat het controlepuntproces het herstelinterval voor de database overschrijdt, ziet u een reeks FlushCache-berichten in het logboek (zie dit bericht van Bob Dorr voor meer informatie). Verwar deze berichten niet met de berichten die verschijnen wanneer u DBCC FREEPROCCACHE of DBCC FREESYSTEMCACHE uitvoert:
- AppDomain-berichten verwijderen
- Het logboek geeft ook aan wanneer AppDomains worden gemaakt, en u ziet beide alleen als u CLR gebruikt. Als ik zie dat AppDomain berichten ontlaadt vanwege geheugendruk, is dat iets om verder te onderzoeken.
Er is andere informatie in het logboek die nuttig is, zoals de authenticatiemodus die wordt gebruikt, of de Dedicated Admin Connection (DAC) is ingeschakeld, enz. Maar ik kan die ook krijgen van sys.configurations en ik controleer die met de instantie-baselines Ik heb het eerder besproken (Proactieve SQL Server-statuscontroles, deel 3:instantie- en database-instellingen).
Wat staat er niet in de ERROLOG, dat je zou verwachten?
Dit is een korte lijst, voor nu, want ik vermoed dat sommigen van jullie misschien andere dingen hebben gevonden waarvan je dacht dat ze in het logboek zouden staan, maar die niet waren...
- Databasebestanden of bestandsgroepen toevoegen of verwijderen
- Starten of stoppen van Extended Events Sessions
- Als u echter een DDL-trigger of gebeurtenismelding op serverniveau implementeert, kunt u deze informatie loggen. Zie Jonathan's post, Logging Extended Events changes to the ERRORLOG, voor meer details.
- DBCC DROPCLEANBUFFERS wordt uitgevoerd verschijnt in het ERRORLOG
Het logboek beheren
Houd er rekening mee dat SQL Server standaard alleen de meest recente zes (6) logbestanden bewaart (naast het huidige bestand) en dat het logbestand elke keer dat de SQL Server opnieuw wordt opgestart, wordt herstart. Als gevolg hiervan kunt u soms extreem grote logbestanden hebben die enige tijd nodig hebben om te openen en lastig zijn om door te graven. Aan de andere kant, als u een geval tegenkomt waarin de instantie een paar keer opnieuw wordt opgestart, kunt u belangrijke informatie verliezen. Het wordt aanbevolen om het aantal bewaarde bestanden te verhogen naar een hogere waarde (bijv. 30) en een agenttaak te maken om eenmaal per week over het bestand te rollen met sp_cycle_errorlog.
Naast het beheren van de bestanden, kunt u ook beïnvloeden welke informatie naar het logboek wordt geschreven. Een van de meest voorkomende vermeldingen die rommel in de ERRORLOG veroorzaken, is de succesvolle back-upinvoer:
 Back-up succesvol voltooid
Back-up succesvol voltooid
Als je een instance hebt met meerdere databases en er worden regelmatig back-ups van transactielogboeken gemaakt (bijvoorbeeld elke 15 minuten), dan zul je zien dat het logboek snel vol raakt met berichten, wat het vinden van een echt probleem moeilijker maakt. Gelukkig kun je traceringsvlag 3226 gebruiken om succesvolle back-upberichten uit te schakelen (er zullen nog steeds fouten in het logboek verschijnen en alle vermeldingen blijven bestaan in msdb).
Een andere reeks berichten die het logboek vervuilen, zijn succesvolle aanmeldingsberichten. Dit is een optie die u configureert voor de instantie op het tabblad Beveiliging:
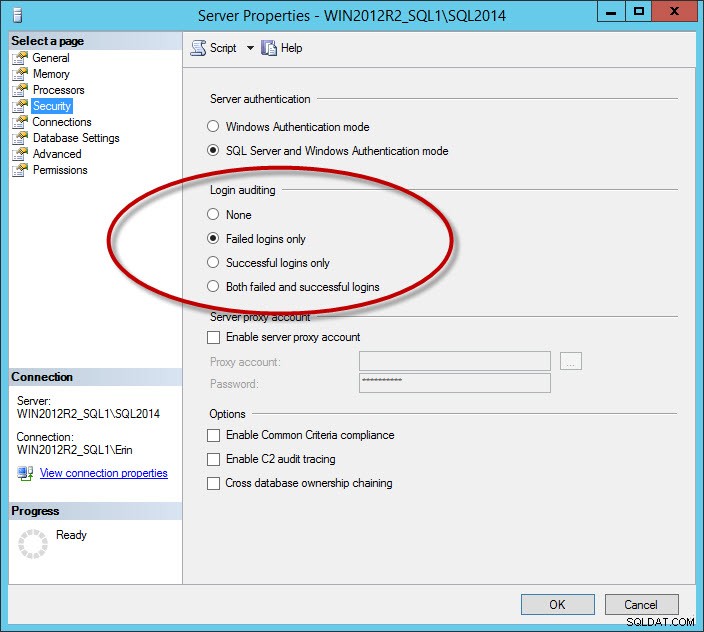 Beveiligingsoptie om geslaagde en/of mislukte aanmeldingen vast te leggen
Beveiligingsoptie om geslaagde en/of mislukte aanmeldingen vast te leggen
Als u succesvolle aanmeldingen registreert, of mislukte en succesvolle aanmeldingen, kunt u zeer grote logbestanden hebben, zelfs als u de bestanden dagelijks doorrolt (dit hangt af van hoeveel gebruikers verbinding maken). Ik raad aan om alleen mislukte aanmeldingen vast te leggen. Voor bedrijven die succesvolle aanmeldingen moeten registreren, kunt u overwegen de Audit-functie te gebruiken, die is toegevoegd in SQL Server 2008. Kanttekening:als u de instelling voor aanmeldingscontrole wijzigt, wordt deze pas van kracht nadat u de instantie opnieuw hebt opgestart.
Onderschat het ERRORLOG niet
Zoals u kunt zien, bevat het ERRORLOG geweldige informatie die u niet alleen kunt gebruiken bij het oplossen van problemen met de prestaties of het onderzoeken van fouten, maar ook bij het proactief bewaken van een instantie. In het logboek vind je informatie die nergens anders te vinden is; zorg ervoor dat je het regelmatig controleert en laat het niet als een bijzaak achter.
Bekijk de andere delen in deze serie:
- Deel 1:Schijfruimte
- Deel 2:Onderhoud
- Deel 3:Instantie- en database-instellingen