ProxySQL bevindt zich gewoonlijk tussen de applicatie- en databaselagen, in de zogenaamde reverse-proxy-laag. Wanneer uw applicatiecontainers worden georkestreerd en beheerd door Kubernetes, wilt u misschien ProxySQL gebruiken voor uw databaseservers.
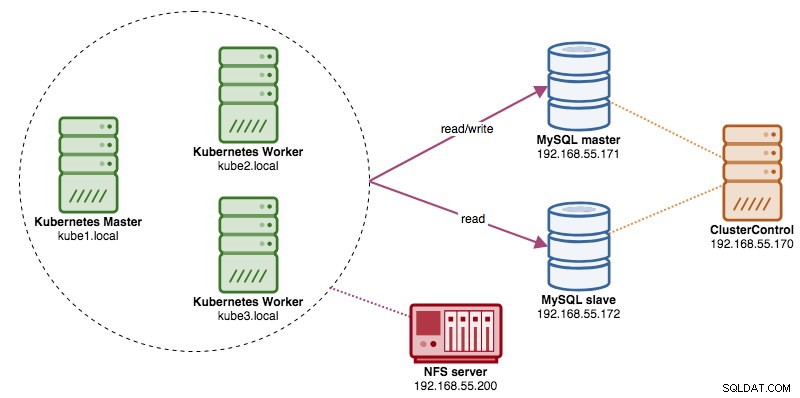
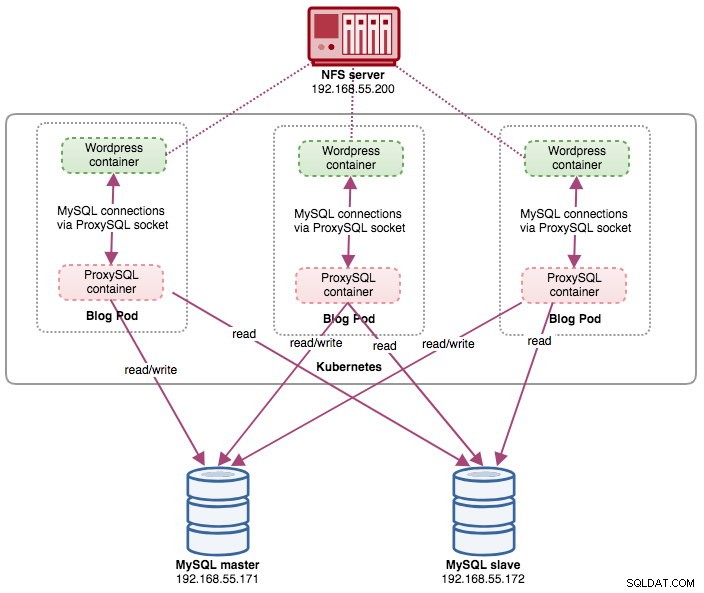
In dit bericht laten we u zien hoe u ProxySQL op Kubernetes uitvoert als een hulpcontainer in een pod. We gaan Wordpress gebruiken als voorbeeldtoepassing. De dataservice wordt geleverd door onze MySQL-replicatie met twee knooppunten, geïmplementeerd met ClusterControl en buiten het Kubernetes-netwerk op een bare-metal infrastructuur, zoals geïllustreerd in het volgende diagram:
ProxySQL Docker-afbeelding
In dit voorbeeld gaan we de ProxySQL Docker-afbeelding gebruiken die wordt onderhouden door Verschillend, een algemene openbare afbeelding die is gebouwd voor multifunctioneel gebruik. De afbeelding wordt geleverd zonder entrypointscript en ondersteunt Galera Cluster (naast ingebouwde ondersteuning voor MySQL-replicatie), waar een extra script vereist is voor statuscontroledoeleinden.
Om een ProxySQL-container uit te voeren, voert u simpelweg de volgende opdracht uit:
$ docker run -d -v /path/to/proxysql.cnf:/etc/proxysql.cnf severalnines/proxysqlDeze afbeelding raadt u aan een ProxySQL-configuratiebestand te binden aan het koppelpunt, /etc/proxysql.cnf, hoewel u dit kunt overslaan en later kunt configureren met de ProxySQL-beheerdersconsole. Voorbeeldconfiguraties vindt u op de Docker Hub-pagina of de Github-pagina.
ProxySQL op Kubernetes
Het ontwerpen van de ProxySQL-architectuur is een subjectief onderwerp en sterk afhankelijk van de plaatsing van de applicatie- en databasecontainers, evenals de rol van ProxySQL zelf. ProxySQL routeert niet alleen query's, het kan ook worden gebruikt om query's te herschrijven en in de cache op te slaan. Voor efficiënte cachehits is mogelijk een aangepaste configuratie vereist die specifiek is afgestemd op de werkbelasting van de applicatiedatabase.
Idealiter kunnen we ProxySQL configureren om door Kubernetes te worden beheerd met twee configuraties:
- ProxySQL als Kubernetes-service (gecentraliseerde implementatie).
- ProxySQL als hulpcontainer in een pod (gedistribueerde implementatie).
De eerste optie is vrij eenvoudig, waarbij we een ProxySQL-pod maken en er een Kubernetes-service aan koppelen. Applicaties maken vervolgens verbinding met de ProxySQL-service via netwerken op de geconfigureerde poorten. Standaard ingesteld op 6033 voor MySQL load-balanced poort en 6032 voor ProxySQL-beheerpoort. Deze implementatie wordt behandeld in de komende blogpost.
De tweede optie is een beetje anders. Kubernetes heeft een concept genaamd "pod". U kunt één of meerdere containers per pod hebben, deze zijn relatief strak aan elkaar gekoppeld. De inhoud van een pod bevindt zich altijd op dezelfde locatie en is samen gepland, en wordt uitgevoerd in een gedeelde context. Een pod is de kleinste beheersbare containereenheid in Kubernetes.
Beide implementaties kunnen eenvoudig worden onderscheiden door naar het volgende diagram te kijken:
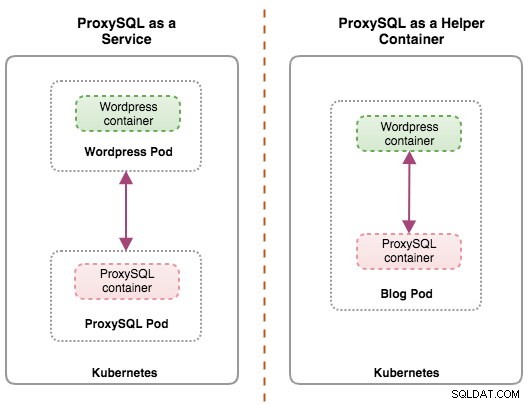
De belangrijkste reden dat pods meerdere containers kunnen hebben, is om hulptoepassingen te ondersteunen die een primaire toepassing ondersteunen. Typische voorbeelden van hulptoepassingen zijn data pullers, data pushers en proxy's. Helper- en primaire applicaties moeten vaak met elkaar communiceren. Meestal wordt dit gedaan via een gedeeld bestandssysteem, zoals getoond in deze oefening, of via de loopback-netwerkinterface, localhost. Een voorbeeld van dit patroon is een webserver samen met een hulpprogramma dat een Git-repository peilt naar nieuwe updates.
Deze blogpost behandelt de tweede configuratie - ProxySQL draaien als een hulpcontainer in een pod.
ProxySQL als helper in een pod
In deze opstelling voeren we ProxySQL uit als een hulpcontainer voor onze Wordpress-container. Het volgende diagram illustreert onze architectuur op hoog niveau:
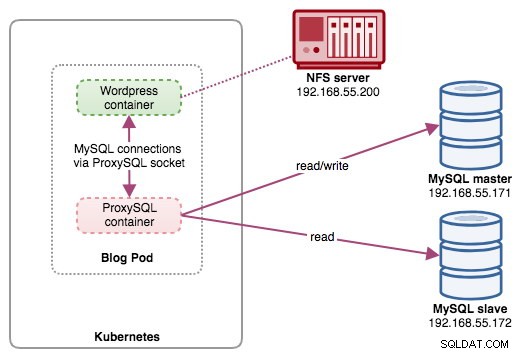
In deze opstelling is de ProxySQL-container nauw gekoppeld aan de Wordpress-container en hebben we deze de "blog"-pod genoemd. Als het opnieuw plannen plaatsvindt, bijvoorbeeld als het Kubernetes-werkknooppunt uitvalt, worden deze twee containers altijd samen opnieuw gepland als één logische eenheid op de volgende beschikbare host. Om de inhoud van de applicatiecontainers persistent te houden over meerdere knooppunten, moeten we een geclusterd of extern bestandssysteem gebruiken, in dit geval NFS.
De rol van ProxySQL is om een database-abstractielaag te leveren aan de toepassingscontainer. Aangezien we een MySQL-replicatie met twee knooppunten gebruiken als de backend-databaseservice, is het splitsen van lezen en schrijven van vitaal belang om het resourceverbruik op beide MySQL-servers te maximaliseren. ProxySQL blinkt hierin uit en vereist minimale tot geen wijzigingen aan de applicatie.
Er zijn een aantal andere voordelen met ProxySQL in deze opstelling:
- Breng de mogelijkheid voor querycaching het dichtst bij de applicatielaag die in Kubernetes draait.
- Beveilig de implementatie door verbinding te maken via ProxySQL UNIX-socketbestand. Het is als een pijp die de server en de clients kunnen gebruiken om verbinding te maken en verzoeken en gegevens uit te wisselen.
- Gedistribueerde reverse proxy-laag met gedeelde niets-architectuur.
- Minder netwerkoverhead dankzij de implementatie van "skip-networking".
- Stateless implementatiebenadering door gebruik te maken van Kubernetes ConfigMaps.
De database voorbereiden
Maak de wordpress-database en gebruiker op de master en wijs deze toe met de juiste rechten:
mysql-master> CREATE DATABASE wordpress;
mysql-master> CREATE USER example@sqldat.com'%' IDENTIFIED BY 'passw0rd';
mysql-master> GRANT ALL PRIVILEGES ON wordpress.* TO example@sqldat.com'%';Maak ook de ProxySQL-monitoringgebruiker aan:
mysql-master> CREATE USER example@sqldat.com'%' IDENTIFIED BY 'proxysqlpassw0rd';Laad vervolgens de subsidietabel opnieuw:
mysql-master> FLUSH PRIVILEGES;De pod voorbereiden
Kopieer nu de volgende regels in een bestand met de naam blog-deployment.yml op de host waar kubectl is geconfigureerd:
apiVersion: apps/v1
kind: Deployment
metadata:
name: blog
labels:
app: blog
spec:
replicas: 1
selector:
matchLabels:
app: blog
tier: frontend
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: blog
tier: frontend
spec:
restartPolicy: Always
containers:
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: localhost:/tmp/proxysql.sock
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
- name: shared-data
mountPath: /tmp
- image: severalnines/proxysql
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
- name: shared-data
mountPath: /tmp
volumes:
- name: wordpress-persistent-storage
persistentVolumeClaim:
claimName: wp-pv-claim
- name: proxysql-config
configMap:
name: proxysql-configmap
- name: shared-data
emptyDir: {}Het YAML-bestand heeft veel regels en laten we alleen het interessante gedeelte bekijken. Het eerste deel:
apiVersion: apps/v1
kind: DeploymentDe eerste regel is de apiVersion. Ons Kubernetes-cluster draait op v1.12, dus we moeten de Kubernetes v1.12 API-documentatie raadplegen en de resourcedeclaratie volgens deze API volgen. De volgende is de soort, die aangeeft welk type resource we willen inzetten. Deployment, Service, ReplicaSet, DaemonSet, PersistentVolume zijn enkele voorbeelden.
De volgende belangrijke sectie is de sectie "containers". Hier definiëren we alle containers die we samen in deze pod willen uitvoeren. Het eerste deel is de Wordpress-container:
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: localhost:/tmp/proxysql.sock
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
- name: shared-data
mountPath: /tmpIn deze sectie vertellen we Kubernetes om Wordpress 4.9 te implementeren met behulp van de Apache-webserver en we hebben de container de naam "wordpress" gegeven. We willen ook dat Kubernetes een aantal omgevingsvariabelen doorgeeft:
- WORDPRESS_DB_HOST - De databasehost. Omdat onze ProxySQL-container zich in dezelfde Pod als de Wordpress-container bevindt, is het veiliger om in plaats daarvan een ProxySQL-socketbestand te gebruiken. Het formaat om het socketbestand in Wordpress te gebruiken is "localhost:{pad naar het socketbestand}". Het bevindt zich standaard onder de map /tmp van de ProxySQL-container. Dit /tmp-pad wordt gedeeld tussen Wordpress- en ProxySQL-containers met behulp van "shared-data" volumeMounts, zoals verderop wordt weergegeven. Beide containers moeten dit volume koppelen om dezelfde inhoud te delen in de /tmp-map.
- WORDPRESS_DB_USER - Specificeer de gebruiker van de wordpress-database.
- WORDPRESS_DB_PASSWORD - Het wachtwoord voor WORDPRESS_DB_USER . Omdat we het wachtwoord in dit bestand niet willen onthullen, kunnen we het verbergen met Kubernetes Secrets. Hier instrueren we Kubernetes om in plaats daarvan de geheime bron "mysql-pass" te lezen. Geheimen moeten vooraf worden aangemaakt voordat de pod wordt geïmplementeerd, zoals verderop wordt uitgelegd.
Ook willen we poort 80 van de container publiceren voor de eindgebruiker. De Wordpress-inhoud die in /var/www/html in de container is opgeslagen, wordt gemount in onze permanente opslag die op NFS draait.
Vervolgens definiëren we de ProxySQL-container:
- image: severalnines/proxysql:1.4.12
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
- name: shared-data
mountPath: /tmp
ports:
- containerPort: 6033
name: proxysqlIn het bovenstaande gedeelte vertellen we Kubernetes om een ProxySQL te implementeren met behulp van severalnines/proxysql afbeeldingsversie 1.4.12. We willen ook dat Kubernetes ons aangepaste, vooraf geconfigureerde configuratiebestand koppelt en toewijst aan /etc/proxysql.cnf in de container. Er zal een volume zijn met de naam "shared-data" dat wordt toegewezen aan de /tmp-map om te delen met de Wordpress-afbeelding - een tijdelijke map die de levensduur van een pod deelt. Hierdoor kan het ProxySQL-socketbestand (/tmp/proxysql.sock) worden gebruikt door de Wordpress-container bij het verbinden met de database, waarbij het TCP/IP-netwerk wordt omzeild.
Het laatste deel is de sectie "volumes":
volumes:
- name: wordpress-persistent-storage
persistentVolumeClaim:
claimName: wp-pv-claim
- name: proxysql-config
configMap:
name: proxysql-configmap
- name: shared-data
emptyDir: {}Kubernetes moet drie volumes voor deze pod maken:
- wordpress-persistent-storage - Gebruik de PersistentVolumeClaim bron om NFS-export toe te wijzen aan de container voor permanente gegevensopslag voor Wordpress-inhoud.
- proxysql-config - Gebruik de ConfigMap bron om het ProxySQL-configuratiebestand toe te wijzen.
- shared-data - Gebruik de emptyDir bron om een gedeelde map voor onze containers in de pod te koppelen. emptyDir resource is een tijdelijke map die de levensduur van een pod deelt.
Daarom moeten we, op basis van onze YAML-definitie hierboven, een aantal Kubernetes-bronnen voorbereiden voordat we kunnen beginnen met het implementeren van de "blog"-pod:
- PersistentVolume en PersistentVolumeClaim - Om de webinhoud van onze Wordpress-toepassing op te slaan, zodat we de laatste wijzigingen niet verliezen wanneer de pod wordt verplaatst naar een ander werkknooppunt.
- Geheimen - Om het gebruikerswachtwoord van de Wordpress-database in het YAML-bestand te verbergen.
- ConfigMap - Om het configuratiebestand toe te wijzen aan de ProxySQL-container, zodat Kubernetes het automatisch opnieuw kan koppelen wanneer het opnieuw wordt gepland naar een ander knooppunt.
PersistentVolume en PersistentVolumeClaim
Een goede permanente opslag voor Kubernetes moet toegankelijk zijn voor alle Kubernetes-knooppunten in het cluster. Omwille van deze blogpost hebben we NFS gebruikt als de PersistentVolume (PV)-provider omdat het eenvoudig is en out-of-the-box wordt ondersteund. De NFS-server bevindt zich ergens buiten ons Kubernetes-netwerk en we hebben deze geconfigureerd om alle Kubernetes-knooppunten toe te staan met de volgende regel in /etc/exports:
/nfs 192.168.55.*(rw,sync,no_root_squash,no_all_squash)Houd er rekening mee dat het NFS-clientpakket op alle Kubernetes-knooppunten moet zijn geïnstalleerd. Anders zou Kubernetes de NFS niet correct kunnen mounten. Op alle knooppunten:
$ sudo apt-install nfs-common #Ubuntu/Debian
$ yum install nfs-utils #RHEL/CentOSZorg er ook voor dat op de NFS-server de doelmap bestaat:
(nfs-server)$ mkdir /nfs/kubernetes/wordpressMaak vervolgens een bestand met de naam wordpress-pv-pvc.yml en voeg de volgende regels toe:
apiVersion: v1
kind: PersistentVolume
metadata:
name: wp-pv
labels:
app: blog
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 3Gi
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /nfs/kubernetes/wordpress
server: 192.168.55.200
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: wp-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
selector:
matchLabels:
app: blog
tier: frontendIn de bovenstaande definitie willen we dat Kubernetes 3 GB volumeruimte op de NFS-server toewijst voor onze Wordpress-container. Let op voor productiegebruik, NFS moet worden geconfigureerd met automatische voorziening en opslagklasse.
Maak de PV- en PVC-bronnen:
$ kubectl create -f wordpress-pv-pvc.ymlControleer of deze bronnen zijn gemaakt en of de status "Gebonden" moet zijn:
$ kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/wp-pv 3Gi RWO Recycle Bound default/wp-pvc 22h
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/wp-pvc Bound wp-pv 3Gi RWO 22hGeheimen
De eerste is om een geheim te maken dat door de Wordpress-container moet worden gebruikt voor WORDPRESS_DB_PASSWORD omgevingsvariabele. De reden is simpelweg omdat we het wachtwoord niet in leesbare tekst in het YAML-bestand willen weergeven.
Maak een geheime bron met de naam mysql-pass en geef het wachtwoord dienovereenkomstig door:
$ kubectl create secret generic mysql-pass --from-literal=password=passw0rdControleer of ons geheim is aangemaakt:
$ kubectl get secrets mysql-pass
NAME TYPE DATA AGE
mysql-pass Opaque 1 7h12mConfigMap
We moeten ook een ConfigMap-bron maken voor onze ProxySQL-container. Een Kubernetes ConfigMap-bestand bevat sleutel-waardeparen van configuratiegegevens die kunnen worden gebruikt in pods of worden gebruikt om configuratiegegevens op te slaan. Met ConfigMaps kunt u configuratie-artefacten loskoppelen van afbeeldingsinhoud om gecontaineriseerde toepassingen draagbaar te houden.
Aangezien onze databaseserver al draait op bare-metal servers met een statische hostnaam en IP-adres plus een statische gebruikersnaam en wachtwoord voor bewaking, zal in dit geval het ConfigMap-bestand vooraf geconfigureerde configuratie-informatie opslaan over de ProxySQL-service die we willen gebruiken.
Maak eerst een tekstbestand met de naam proxysql.cnf en voeg de volgende regels toe:
datadir="/var/lib/proxysql"
admin_variables=
{
admin_credentials="admin:adminpassw0rd"
mysql_ifaces="0.0.0.0:6032"
refresh_interval=2000
}
mysql_variables=
{
threads=4
max_connections=2048
default_query_delay=0
default_query_timeout=36000000
have_compress=true
poll_timeout=2000
interfaces="0.0.0.0:6033;/tmp/proxysql.sock"
default_schema="information_schema"
stacksize=1048576
server_version="5.1.30"
connect_timeout_server=10000
monitor_history=60000
monitor_connect_interval=200000
monitor_ping_interval=200000
ping_interval_server_msec=10000
ping_timeout_server=200
commands_stats=true
sessions_sort=true
monitor_username="proxysql"
monitor_password="proxysqlpassw0rd"
}
mysql_servers =
(
{ address="192.168.55.171" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.171" , port=3306 , hostgroup=20, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=20, max_connections=100 }
)
mysql_users =
(
{ username = "wordpress" , password = "passw0rd" , default_hostgroup = 10 , active = 1 }
)
mysql_query_rules =
(
{
rule_id=100
active=1
match_pattern="^SELECT .* FOR UPDATE"
destination_hostgroup=10
apply=1
},
{
rule_id=200
active=1
match_pattern="^SELECT .*"
destination_hostgroup=20
apply=1
},
{
rule_id=300
active=1
match_pattern=".*"
destination_hostgroup=10
apply=1
}
)
mysql_replication_hostgroups =
(
{ writer_hostgroup=10, reader_hostgroup=20, comment="MySQL Replication 5.7" }
)Besteed extra aandacht aan de secties "mysql_servers" en "mysql_users", waar u mogelijk de waarden moet aanpassen aan uw databaseclusterconfiguratie. In dit geval hebben we twee databaseservers die draaien in MySQL-replicatie, zoals samengevat in de volgende Topologie-screenshot genomen uit ClusterControl:
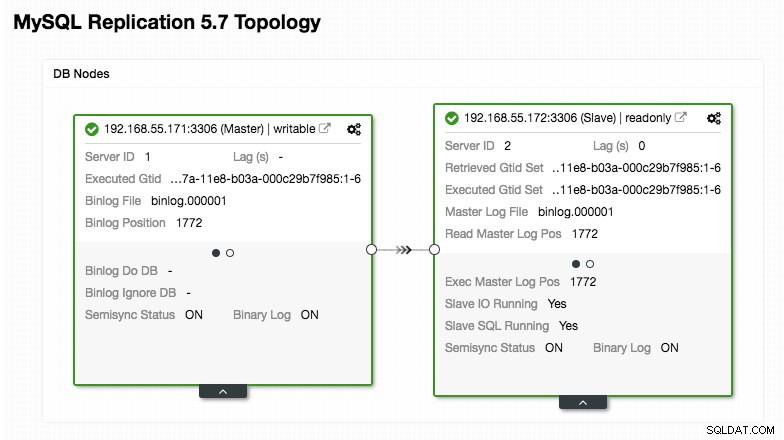
Alle schrijfbewerkingen moeten naar het hoofdknooppunt gaan, terwijl de leesbewerkingen worden doorgestuurd naar hostgroep 20, zoals gedefinieerd in de sectie "mysql_query_rules". Dat is de basis van het splitsen van lezen/schrijven en we willen ze helemaal gebruiken.
Importeer vervolgens het configuratiebestand in ConfigMap:
$ kubectl create configmap proxysql-configmap --from-file=proxysql.cnf
configmap/proxysql-configmap createdControleer of de ConfigMap in Kubernetes is geladen:
$ kubectl get configmap
NAME DATA AGE
proxysql-configmap 1 45sDe pod implementeren
Nu zouden we goed moeten zijn om de blogpod te implementeren. Stuur de implementatietaak naar Kubernetes:
$ kubectl create -f blog-deployment.ymlControleer de pod-status:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-t4cb7 2/2 Running 0 100sEr moet 2/2 onder de kolom GEREED worden weergegeven, wat aangeeft dat er twee containers in de pod draaien. Gebruik de optie-vlag -c om de Wordpress- en ProxySQL-containers in de blogpod te controleren:
$ kubectl logs blog-54755cbcb5-t4cb7 -c wordpress
$ kubectl logs blog-54755cbcb5-t4cb7 -c proxysqlIn het ProxySQL-containerlogboek zou u de volgende regels moeten zien:
2018-10-20 08:57:14 [INFO] Dumping current MySQL Servers structures for hostgroup ALL
HID: 10 , address: 192.168.55.171 , port: 3306 , weight: 1 , status: ONLINE , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:
HID: 10 , address: 192.168.55.172 , port: 3306 , weight: 1 , status: OFFLINE_HARD , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:
HID: 20 , address: 192.168.55.171 , port: 3306 , weight: 1 , status: ONLINE , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:
HID: 20 , address: 192.168.55.172 , port: 3306 , weight: 1 , status: ONLINE , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:HID 10 (schrijver-hostgroep) mag slechts één ONLINE-knooppunt hebben (dat een enkele master aangeeft) en de andere host moet ten minste de OFFLINE_HARD-status hebben. Voor HID 20 wordt verwacht dat het ONLINE is voor alle knooppunten (dit geeft meerdere leesreplica's aan).
Gebruik de vlag omschrijven om een samenvatting van de implementatie te krijgen:
$ kubectl describe deployments blogOnze blog is nu actief, maar we hebben er geen toegang toe van buiten het Kubernetes-netwerk zonder de service te configureren, zoals uitgelegd in de volgende sectie.
De blogservice maken
De laatste stap is om een service aan onze pod te koppelen. Dit om ervoor te zorgen dat onze Wordpress blogpod ook van buitenaf toegankelijk is. Maak een bestand met de naam blog-svc.yml en plak de volgende regel:
apiVersion: v1
kind: Service
metadata:
name: blog
labels:
app: blog
tier: frontend
spec:
type: NodePort
ports:
- name: blog
nodePort: 30080
port: 80
selector:
app: blog
tier: frontendMaak de dienst:
$ kubectl create -f blog-svc.ymlControleer of de service correct is aangemaakt:
example@sqldat.com:~/proxysql-blog# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
blog NodePort 10.96.140.37 <none> 80:30080/TCP 26s
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 43hPoort 80 die door de blogpod is gepubliceerd, is nu toegewezen aan de buitenwereld via poort 30080. We hebben toegang tot onze blogpost op https://{any_kubernetes_host}:30080/ en moeten worden omgeleid naar de installatiepagina van Wordpress. Als we doorgaan met de installatie, wordt het gedeelte over de databaseverbinding overgeslagen en wordt deze pagina direct weergegeven:
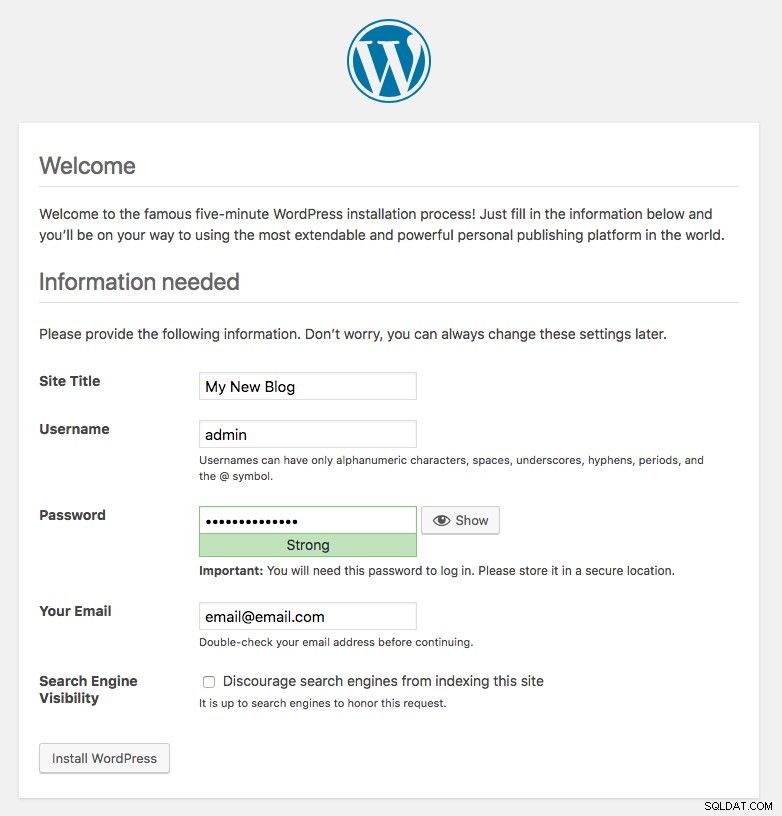
Het geeft aan dat onze MySQL- en ProxySQL-configuratie correct is geconfigureerd in het wp-config.php-bestand. Anders wordt u doorgestuurd naar de databaseconfiguratiepagina.
Onze implementatie is nu voltooid.
ProxySQL-container in een pod beheren
Failover en herstel worden naar verwachting automatisch afgehandeld door Kubernetes. Als de Kubernetes-worker bijvoorbeeld uitvalt, wordt de pod opnieuw gemaakt in het volgende beschikbare knooppunt na --pod-eviction-timeout (standaard 5 minuten). Als de container crasht of doodgaat, zal Kubernetes hem vrijwel onmiddellijk vervangen.
Sommige algemene beheertaken zullen naar verwachting anders zijn wanneer ze binnen Kubernetes worden uitgevoerd, zoals weergegeven in de volgende secties.
Op en neer schalen
In de bovenstaande configuratie implementeerden we één replica in onze implementatie. Om op te schalen, wijzigt u eenvoudig de spec.replicas waarde dienovereenkomstig met behulp van kubectl edit commando:
$ kubectl edit deployment blogHet opent de implementatiedefinitie in een standaard tekstbestand en wijzigt eenvoudig de spec.replicas waarde naar iets hogers, bijvoorbeeld "replica's:3". Sla vervolgens het bestand op en controleer onmiddellijk de uitrolstatus met behulp van de volgende opdracht:
$ kubectl rollout status deployment blog
Waiting for deployment "blog" rollout to finish: 1 of 3 updated replicas are available...
Waiting for deployment "blog" rollout to finish: 2 of 3 updated replicas are available...
deployment "blog" successfully rolled outOp dit moment hebben we drie blogpods (Wordpress + ProxySQL) die gelijktijdig in Kubernetes draaien:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-6fnqn 2/2 Running 0 11m
blog-54755cbcb5-cwpdj 2/2 Running 0 11m
blog-54755cbcb5-jxtvc 2/2 Running 0 22mOp dit moment ziet onze architectuur er ongeveer zo uit:
Houd er rekening mee dat er mogelijk meer maatwerk nodig is dan onze huidige configuratie om Wordpress soepel te laten draaien in een productieomgeving met horizontale schaal (denk aan statische inhoud, sessiebeheer en andere). Die vallen eigenlijk buiten het bestek van deze blogpost.
Verkleiningsprocedures zijn vergelijkbaar.
Configuratiebeheer
Configuratiebeheer is belangrijk in ProxySQL. Dit is waar de magie gebeurt, waar u uw eigen set queryregels kunt definiëren om querycaching, firewalling en herschrijven uit te voeren. In tegenstelling tot de gebruikelijke praktijk, waar ProxySQL zou worden geconfigureerd via de beheerdersconsole en persistent zou worden gemaakt door "OPSLAAN .. OP SCHIJF" te gebruiken, houden we het alleen bij configuratiebestanden om de zaken in Kubernetes draagbaarder te maken. Dat is de reden waarom we ConfigMaps gebruiken.
Omdat we vertrouwen op onze gecentraliseerde configuratie die is opgeslagen door Kubernetes ConfigMaps, zijn er een aantal manieren om configuratiewijzigingen door te voeren. Ten eerste door de opdracht kubectl edit te gebruiken:
$ kubectl edit configmap proxysql-configmapHet opent de configuratie in een standaard teksteditor en u kunt er direct wijzigingen in aanbrengen en het tekstbestand opslaan als u klaar bent. Anders zou het opnieuw maken van de configmaps ook moeten doen:
$ vi proxysql.cnf # edit the configuration first
$ kubectl delete configmap proxysql-configmap
$ kubectl create configmap proxysql-configmap --from-file=proxysql.cnfNadat de configuratie in ConfigMap is gepusht, start u de pod of container opnieuw zoals wordt weergegeven in het gedeelte Servicebeheer. Door de container te configureren via de ProxySQL-beheerdersinterface (poort 6032) wordt deze niet persistent nadat de pod opnieuw is gepland door Kubernetes.
Servicecontrole
Aangezien de twee containers in een pod nauw aan elkaar zijn gekoppeld, is de beste manier om de ProxySQL-configuratiewijzigingen toe te passen, Kubernetes te dwingen de pod te vervangen. Bedenk dat we nu drie blogpods hebben nadat we zijn opgeschaald:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-6fnqn 2/2 Running 0 31m
blog-54755cbcb5-cwpdj 2/2 Running 0 31m
blog-54755cbcb5-jxtvc 2/2 Running 1 22mGebruik de volgende opdracht om één pod tegelijk te vervangen:
$ kubectl get pod blog-54755cbcb5-6fnqn -n default -o yaml | kubectl replace --force -f -
pod "blog-54755cbcb5-6fnqn" deleted
pod/blog-54755cbcb5-6fnqnVerifieer vervolgens met het volgende:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-6fnqn 2/2 Running 0 31m
blog-54755cbcb5-cwpdj 2/2 Running 0 31m
blog-54755cbcb5-qs6jm 2/2 Running 1 2m26sU zult zien dat de meest recente pod opnieuw is opgestart door naar de kolommen AGE en RESTART te kijken, deze heeft een andere podnaam bedacht. Herhaal dezelfde stappen voor de overige peulen. Anders kunt u ook de opdracht "docker kill" gebruiken om de ProxySQL-container handmatig in het Kubernetes-werkknooppunt te doden. Bijvoorbeeld:
(kube-worker)$ docker kill $(docker ps | grep -i proxysql_blog | awk {'print $1'})Kubernetes zal dan de gedode ProxySQL-container vervangen door een nieuwe.
Bewaking
Gebruik de opdracht kubectl exec om de SQL-instructie uit te voeren via de mysql-client. Bijvoorbeeld om de vertering van zoekopdrachten te controleren:
$ kubectl exec -it blog-54755cbcb5-29hqt -c proxysql -- mysql -uadmin -p -h127.0.0.1 -P6032
mysql> SELECT * FROM stats_mysql_query_digest;Of met een oneliner:
$ kubectl exec -it blog-54755cbcb5-29hqt -c proxysql -- mysql -uadmin -p -h127.0.0.1 -P6032 -e 'SELECT * FROM stats_mysql_query_digest'Door de SQL-instructie te wijzigen, kunt u andere ProxySQL-componenten controleren of beheertaken uitvoeren via deze beheerdersconsole. Nogmaals, het blijft alleen bestaan tijdens de levensduur van de ProxySQL-container en wordt niet behouden als de pod opnieuw wordt gepland.
Laatste gedachten
ProxySQL speelt een sleutelrol als u uw applicatiecontainers wilt schalen en een intelligente manier wilt hebben om toegang te krijgen tot een gedistribueerde database-backend. Er zijn een aantal manieren om ProxySQL op Kubernetes te implementeren om onze applicatiegroei te ondersteunen wanneer deze op grote schaal wordt uitgevoerd. Deze blogpost behandelt er slechts één.
In een aanstaande blogpost gaan we kijken hoe ProxySQL gecentraliseerd kan worden uitgevoerd door het als een Kubernetes-service te gebruiken.