In onze vorige blog over SCUMM-dashboards hebben we gekeken naar het MySQL-overzichtsdashboard. De nieuwe versie van ClusterControl (ver. 1.7) biedt een aantal grafieken met een hoge resolutie van nuttige metrieken, en we hebben de betekenis van elk van de metrieken doorgenomen, en hoe ze u helpen bij het oplossen van problemen met uw database. In deze blog kijken we naar het MySQL Replication-dashboard. Laten we verder gaan met de details van dit dashboard over wat te bieden heeft.
MySQL-replicatiedashboard
Het MySQL-replicatiedashboard biedt een zeer eenvoudige reeks grafieken die het gemakkelijker maken om uw MySQL-master en replica('s) te bewaken. Vanaf de bovenkant toont het de belangrijkste variabelen en informatie om de gezondheid van de replica('s) of zelfs de master te bepalen. Dit dashboard biedt een zeer nuttig onderdeel bij het inspecteren van de gezondheid van de slaves of een master in master-master opstelling. Men kan ook op dit dashboard de creatie van het binaire logboek van de master controleren en de algehele dimensie bepalen, in termen van de gegenereerde grootte, op een bepaalde bepaalde tijdsperiode.
Als eerste in dit dashboard geeft het u de belangrijkste informatie die u mogelijk nodig heeft met de gezondheid van uw replica. Zie onderstaande grafiek:

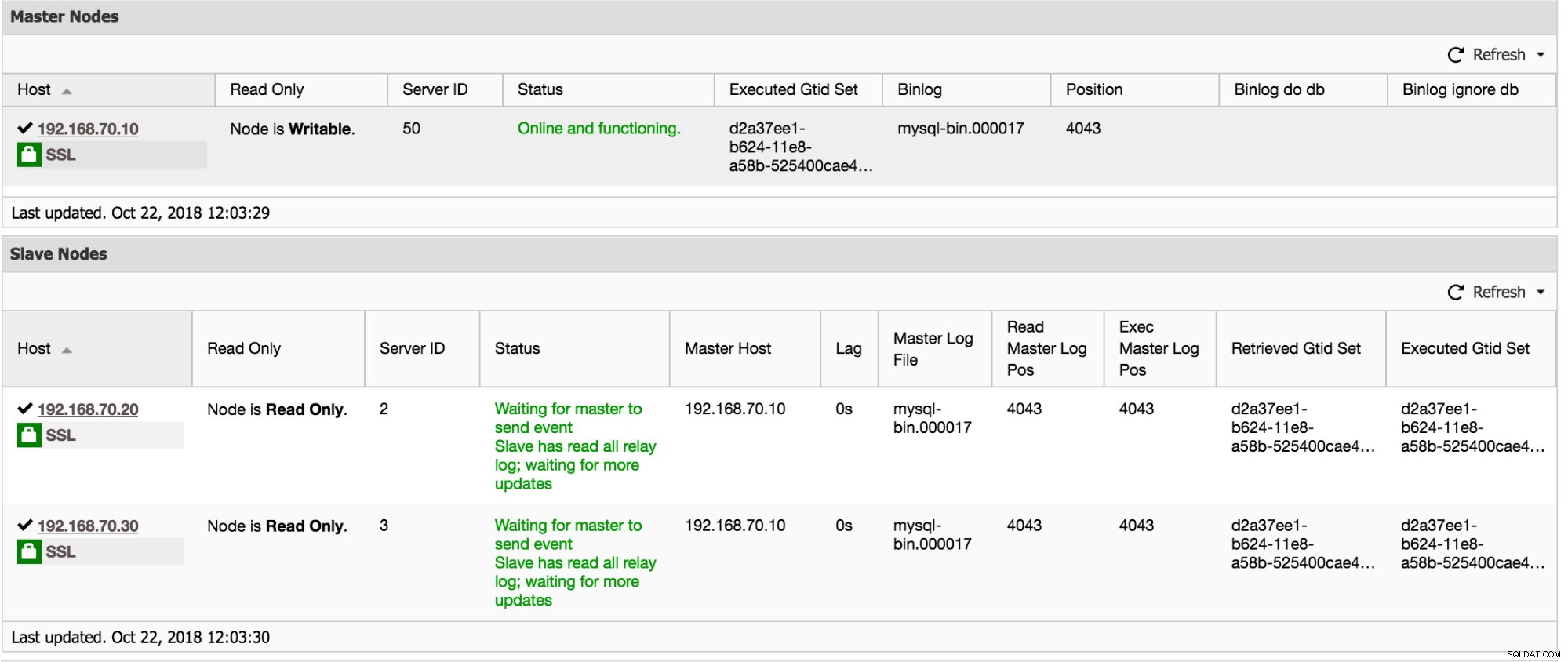
Kortom, het toont u de IO_Thread, SQL_Thread, replicatiefout van de Slave-thread en of de read_only-variabele is ingeschakeld. Uit de voorbeeldscreenshot hierboven blijkt uit alle informatie dat mijn slaaf 192.168.70.20 gezond is en normaal werkt.
Bovendien heeft ClusterControl ook informatie om te verzamelen als u naar Cluster -> Overzicht gaat. Scroll naar beneden en je ziet de onderstaande grafiek:
Een andere plaats om de replicatie-instellingen te bekijken is de topologieweergave van de replicatie-instellingen, toegankelijk via Cluster -> Topologie. Het geeft in een oogopslag een overzicht van de verschillende knooppunten in de installatie, hun rollen, replicatievertraging, opgehaalde GTID en meer. Zie onderstaande grafiek:
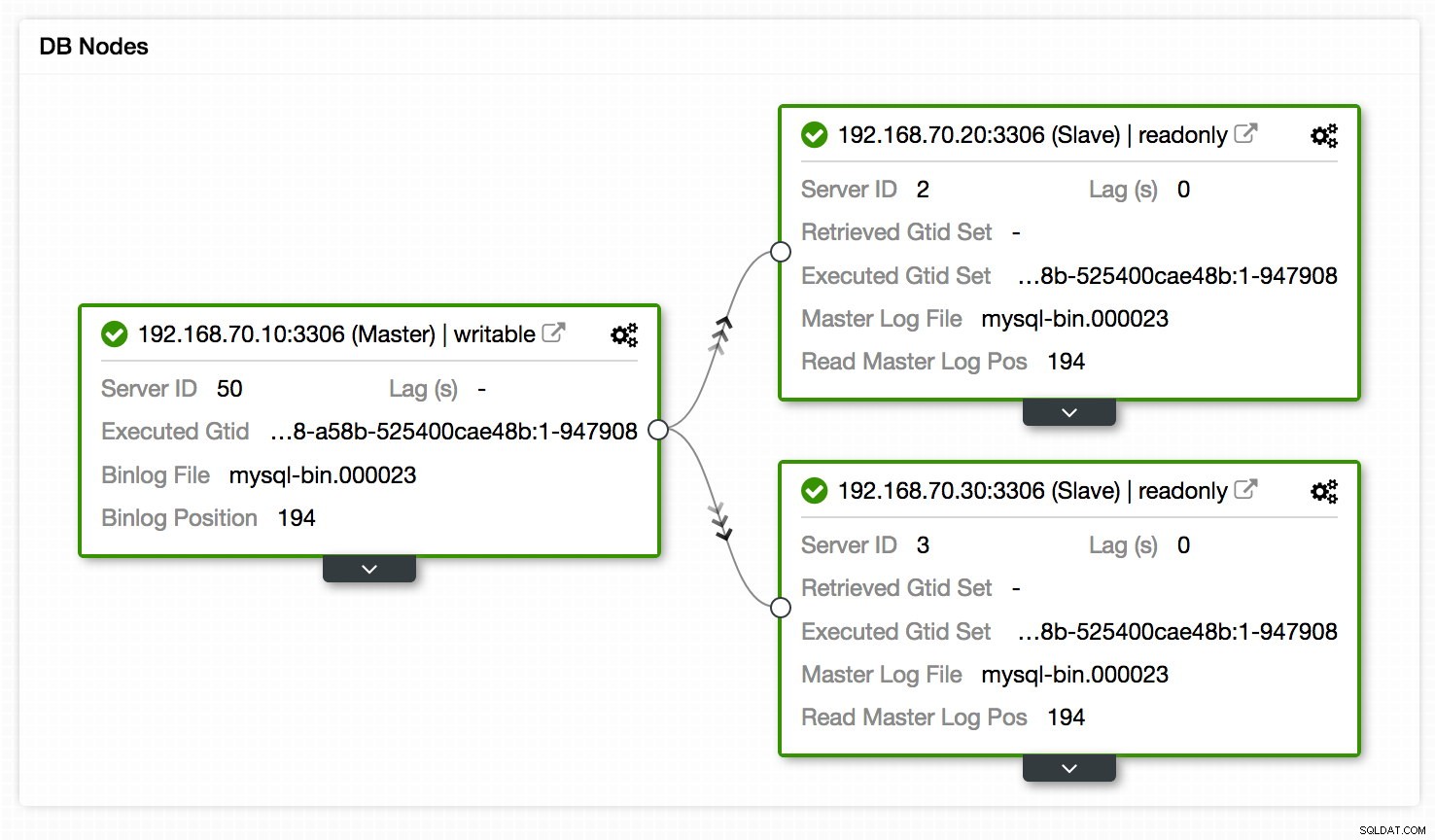
Daarnaast toont de Topologieweergave ook alle verschillende knooppunten die deel uitmaken van uw databasecluster, of het nu de databaseknooppunten, load balancers (ProxySQL/MaxScale/HaProxy) of arbiters (garbd) zijn, evenals de verbindingen daartussen. De knooppunten, verbindingen en hun statussen worden ontdekt door ClusterControl. Omdat ClusterControl de knooppunten continu bewaakt en statusinformatie bijhoudt, worden eventuele wijzigingen in de topologie weergegeven in de webinterface. In het geval dat een storing van knooppunten wordt gemeld, kunt u deze weergave samen met de SCUMM-dashboards gebruiken om te zien welke impact dat zou kunnen hebben.
De Topologieweergave heeft enige gelijkenis met Orchestrator waarin u de knooppunten kunt beheren, masters kunt wijzigen door het object naar de gewenste master te slepen en neer te zetten, knooppunten opnieuw te starten en gegevens te synchroniseren. Als u meer wilt weten over onze Topologieweergave, raden we u aan onze vorige blog te lezen - "Uw clustertopologie visualiseren in ClusterControl".
Laten we nu verder gaan met de grafieken.
-
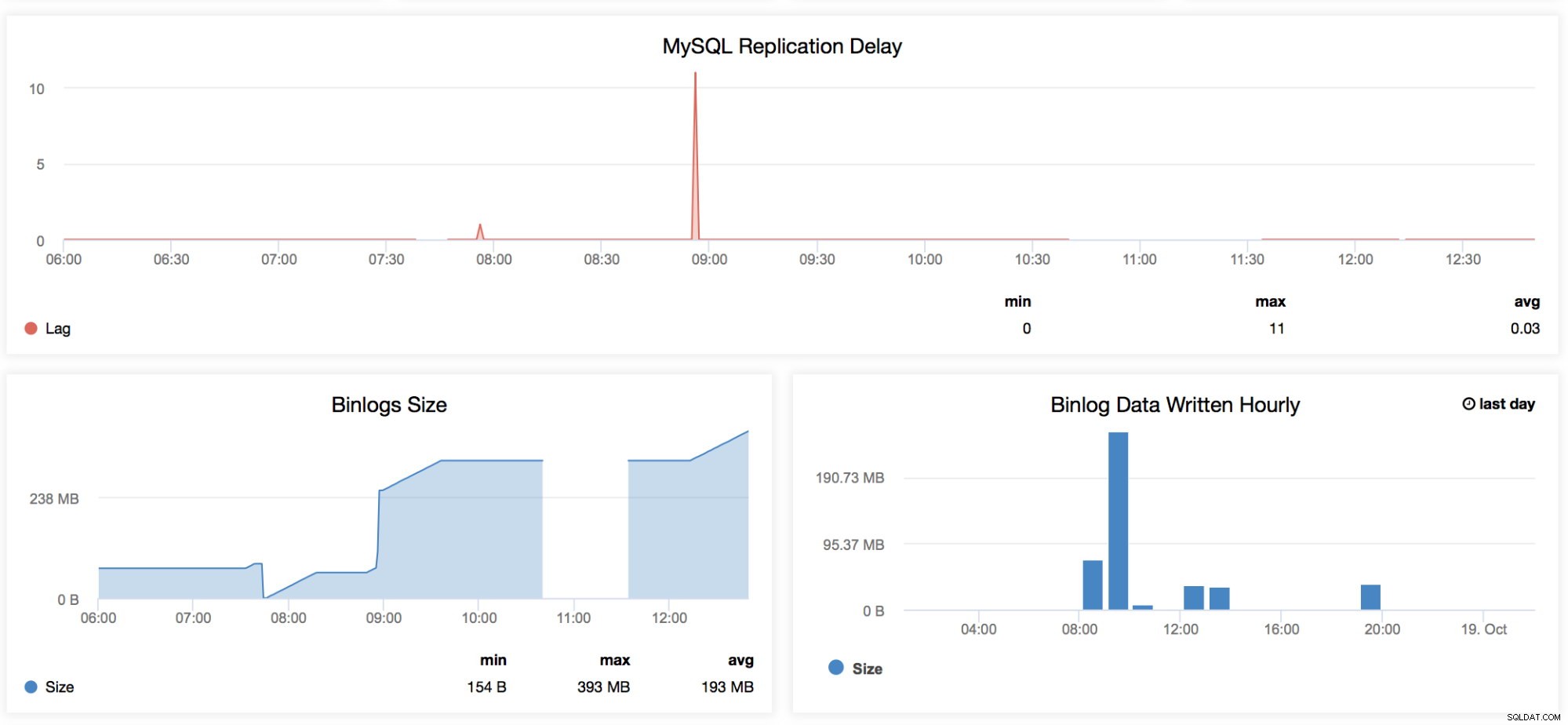
Vertraging MySQL-replicatie
Deze grafiek is zeer bekend bij iedereen die MySQL beheert, vooral degenen die dagelijks aan hun master-slave-configuratie werken. Deze grafiek bevat de trends voor alle vertragingen die zijn geregistreerd voor een specifiek tijdbereik dat in dit dashboard is gespecificeerd. Wanneer we de periodieke herfsttijd willen controleren die onze replica heeft, dan is deze grafiek goed om naar te kijken. Er zijn bepaalde gelegenheden dat een replica om vreemde redenen kan achterblijven, zoals uw RAID heeft een gedegradeerde BBU en moet worden vervangen, een tabel heeft geen unieke sleutel maar niet op de master, een ongewenste volledige tabelscan of volledige indexscan, of een slechte query werd uitgevoerd door een ontwikkelaar. Dit is ook een goede indicator om te bepalen of slaafvertraging een belangrijk probleem is, dan wilt u misschien profiteren van parallelle replicatie. -
Binlog Grootte
Deze grafieken zijn aan elkaar gerelateerd. De grafiek Binlog-grootte laat zien hoe uw node het binaire logboek genereert en helpt bij het bepalen van de dimensie op basis van de tijdsperiode die u aan het scannen bent. -
Binlog-gegevens per uur geschreven
De Binlog-gegevens per uur geschreven is een grafiek op basis van de huidige dag en de vorige geregistreerde dag. Dit kan handig zijn wanneer u wilt bepalen hoe groot uw knooppunt is dat schrijfbewerkingen accepteert, wat u later kunt gebruiken voor capaciteitsplanning.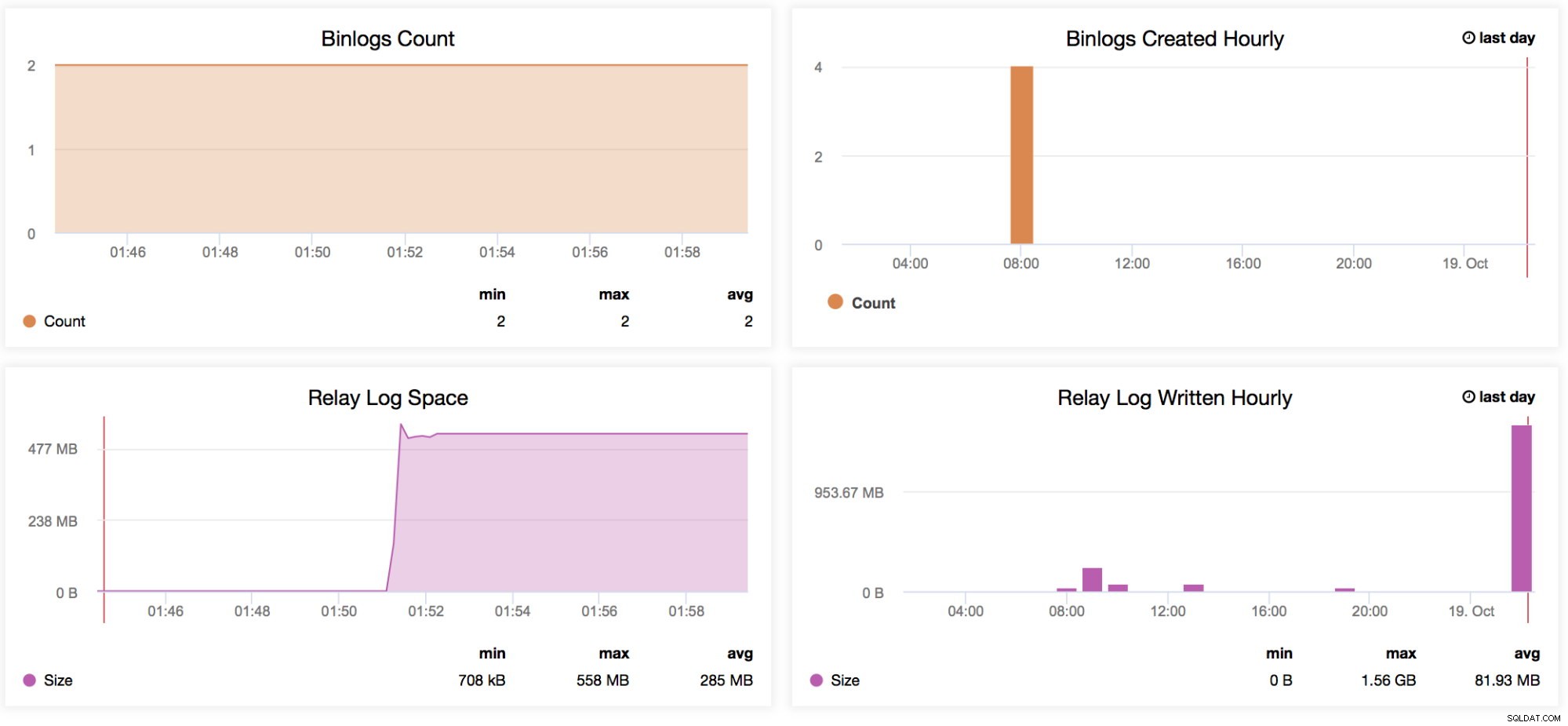
-
Binlogs tellen
Laten we zeggen dat u voor een bepaalde week veel verkeer verwacht. U wilt vergelijken hoe grote schrijfacties door uw meester en slaven gaan met de vorige week. Deze grafiek is erg handig voor dit soort situaties - Om te bepalen hoe hoog de gegenereerde binaire logs waren op de master zelf of zelfs op de slaves als de log_slave_updates variabele is ingeschakeld. U kunt deze indicator ook gebruiken om de gegenereerde binaire loggegevens van master vs slaves te bepalen, vooral als u enkele tabellen of schema's (replicate_ignore_db, replicate_ignore_table, replicate_wild_do_table) op uw slaves filtert die zijn gegenereerd terwijl log_slave_updates is ingeschakeld. -
Binlogs gemaakt per uur
Deze grafiek is een snel overzicht om uw binlogs die elk uur zijn gemaakt te vergelijken met de datum van gisteren en vandaag. -
Relay Log Space
Deze grafiek dient als basis voor de gegenereerde relay-logboeken van uw replica. Wanneer het samen met de MySQL-replicatievertragingsgrafiek wordt gebruikt, helpt het te bepalen hoe groot het aantal gegenereerde relay-logboeken is, waarmee de beheerder rekening moet houden in termen van schijfbeschikbaarheid van de huidige replica. Het kan problemen veroorzaken wanneer uw slave ernstig achterblijft en grote aantallen relaislogboeken genereert. Dit kan uw schijfruimte snel in beslag nemen. Er zijn bepaalde situaties dat, vanwege een groot aantal schrijfbewerkingen van de master, de slave/replica enorm achterblijft, waardoor het genereren van een grote hoeveelheid logs ernstige problemen kan veroorzaken op die replica. Dit kan het operationele team helpen bij het praten met hun management over capaciteitsplanning. -
Relay-logboek per uur geschreven
Hetzelfde als de relay-logboekruimte, maar voegt een snel overzicht toe om uw relay-logboeken te vergelijken die zijn geschreven vanaf gisteren en de datum van vandaag.
Conclusie
U hebt geleerd dat het gebruik van SCUMM om uw MySQL-replicatie te bewaken, meer productiviteit en efficiëntie toevoegt aan het operationele team. Het gebruik van de functies die we van eerdere versies hebben gecombineerd met de grafieken die bij SCUMM worden geleverd, is als naar de sportschool gaan en enorme verbeteringen in uw productiviteit zien. Dit is wat SCUMM kan bieden:monitoring op steroïden! (nu pleiten we er niet voor om steroïden te gebruiken als je naar de sportschool gaat!)
In deel 3 van deze blog bespreek ik de InnoDB Metrics en MySQL Performance Schema Dashboards.