Het beste scenario is dat je, in het geval van een databasefout, een goed Disaster Recovery Plan (DRP) hebt en een omgeving met hoge beschikbaarheid met een automatisch failoverproces, maar... wat gebeurt er als het niet lukt voor een onverwachte reden? Wat als u een handmatige failover moet uitvoeren? In deze blog delen we enkele aanbevelingen die u kunt volgen voor het geval u een failover van uw database moet uitvoeren.
Verificatiecontroles
Voordat u een wijziging uitvoert, moet u enkele basiszaken verifiëren om nieuwe problemen na het failoverproces te voorkomen.
Replicatiestatus
Het kan zijn dat het slave-knooppunt op het moment van de storing niet up-to-date is vanwege een netwerkstoring, hoge belasting of een ander probleem, dus u moet ervoor zorgen dat uw slaaf heeft alle (of bijna alle) informatie. Als je meer dan één slave-node hebt, moet je ook controleren welke de meest geavanceerde node is en deze kiezen voor failover.
bijv.:Laten we de replicatiestatus in een MariaDB-server controleren.
MariaDB [(none)]> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.100.110
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000014
Read_Master_Log_Pos: 339
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 635
Relay_Master_Log_File: binlog.000014
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_Errno: 0
Skip_Counter: 0
Exec_Master_Log_Pos: 339
Relay_Log_Space: 938
Until_Condition: None
Until_Log_Pos: 0
Master_SSL_Allowed: No
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_SQL_Errno: 0
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3001
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3001-20
Parallel_Mode: conservative
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0
1 row in set (0.000 sec)In het geval van PostgreSQL is het een beetje anders, omdat je de WAL-status moet controleren en de toegepaste met de opgehaalde moet vergelijken.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)Inloggegevens
Voordat u de failover uitvoert, moet u controleren of uw toepassing/gebruikers toegang hebben tot uw nieuwe master met de huidige inloggegevens. Als u uw databasegebruikers niet repliceert, zijn de inloggegevens misschien gewijzigd, dus moet u ze bijwerken in de slave-knooppunten voordat er wijzigingen worden aangebracht.
e.g.:U kunt de gebruikerstabel in de mysql-database opvragen om de gebruikersreferenties in een MariaDB/MySQL-server te controleren:
MariaDB [(none)]> SELECT Host,User,Password FROM mysql.user;
+-----------------+--------------+-------------------------------------------+
| Host | User | Password |
+-----------------+--------------+-------------------------------------------+
| localhost | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | mysql | invalid |
| 127.0.0.1 | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.100 | cmon | *F80B5EE41D1FB1FA67D83E96FCB1638ABCFB86E2 |
| 127.0.0.1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| ::1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.112 | user1 | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 127.0.0.1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| ::1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 192.168.100.110 | rpl_user | *EEA7B018B16E0201270B3CDC0AF8FC335048DC63 |
+-----------------+--------------+-------------------------------------------+
12 rows in set (0.001 sec)In het geval van PostgreSQL kunt u de opdracht '\du' gebruiken om de rollen te kennen, en u moet ook het configuratiebestand pg_hba.conf controleren om de gebruikerstoegang te beheren (geen inloggegevens). Dus:
postgres=# \du
List of roles
Role name | Attributes | Member of
------------------+------------------------------------------------------------+-----------
admindb | Superuser, Create role, Create DB | {}
cmon_replication | Replication | {}
cmonexporter | | {}
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
s9smysqlchk | Superuser, Create role, Create DB | {}En pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD
host replication cmon_replication localhost md5
host replication cmon_replication 127.0.0.1/32 md5
host all s9smysqlchk localhost md5
host all s9smysqlchk 127.0.0.1/32 md5
local all all trust
host all all 127.0.0.1/32 trustNetwerk-/firewalltoegang
De inloggegevens zijn niet het enige mogelijke probleem om toegang te krijgen tot je nieuwe master. Als het knooppunt zich in een ander datacenter bevindt, of als u een lokale firewall hebt om verkeer te filteren, moet u controleren of u er toegang toe hebt of zelfs of u de netwerkroute heeft om het nieuwe hoofdknooppunt te bereiken.
bijvoorbeeld:iptables. Laten we het verkeer van het netwerk 167.124.57.0/24 toestaan en de huidige regels controleren nadat we het hebben toegevoegd:
$ iptables -A INPUT -s 167.124.57.0/24 -m state --state NEW -j ACCEPT
$ iptables -L -n
Chain INPUT (policy ACCEPT)
target prot opt source destination
ACCEPT all -- 167.124.57.0/24 0.0.0.0/0 state NEW
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destinationbijvoorbeeld:routes. Laten we aannemen dat uw nieuwe hoofdknooppunt zich in het netwerk 10.0.0.0/24 bevindt, uw toepassingsserver zich in 192.168.100.0/24 bevindt en dat u het externe netwerk kunt bereiken via 192.168.100.100, dus voeg in uw toepassingsserver de bijbehorende route toe:
$ route add -net 10.0.0.0/24 gw 192.168.100.100
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.100.1 0.0.0.0 UG 0 0 0 eth0
10.0.0.0 192.168.100.100 255.255.255.0 UG 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1027 0 0 eth0
192.168.100.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0Actiepunten
Na het controleren van alle genoemde punten, zou u klaar moeten zijn om de acties uit te voeren om uw database te failoveren.
Nieuw IP-adres
Omdat je een slave-node gaat promoten, zal het master-IP-adres veranderen, dus je zult het in je applicatie of clienttoegang moeten veranderen.
Het gebruik van een Load Balancer is een uitstekende manier om dit probleem/deze wijziging te voorkomen. Na het failoverproces zal de Load Balancer de oude master als offline detecteren en (afhankelijk van de configuratie) het verkeer naar de nieuwe sturen om erop te schrijven, dus je hoeft niets in je applicatie te veranderen.
e.g.:Laten we een voorbeeld bekijken voor een HAProxy-configuratie:
listen haproxy_5433
bind *:5433
mode tcp
timeout client 10800s
timeout server 10800s
balance leastconn
option tcp-check
server 192.168.100.119 192.168.100.119:5432 check
server 192.168.100.120 192.168.100.120:5432 checkIn dit geval, als één knooppunt niet beschikbaar is, zal HAProxy daar geen verkeer naartoe sturen en het verkeer alleen naar het beschikbare knooppunt sturen.
De Slave-knooppunten opnieuw configureren
Als je meer dan één slave-node hebt, moet je, nadat je er een hebt gepromoveerd, de rest van de slaves opnieuw configureren om verbinding te maken met de nieuwe master. Dit kan een tijdrovende taak zijn, afhankelijk van het aantal nodes.
Controleer en configureer de back-ups
Nadat je alles op zijn plaats hebt (nieuwe master gepromoveerd, slaves opnieuw geconfigureerd, applicatie schrijven in de nieuwe master), is het belangrijk om de nodige acties te ondernemen om een nieuw probleem te voorkomen, dus back-ups zijn een must in deze stap. Hoogstwaarschijnlijk had u vóór het incident een back-upbeleid (zo niet, dan moet u het zeker hebben), dus u moet controleren of de back-ups nog steeds actief zijn of dat ze het zullen doen in de nieuwe topologie. Het kan zijn dat de back-ups op de oude master draaiden, of dat je de slave-node gebruikt die nu master is, dus je moet dit controleren om er zeker van te zijn dat je back-upbeleid nog steeds werkt na de wijzigingen.
Databasecontrole
Als je een failover-proces uitvoert, is monitoring een must voor, tijdens en na het proces. Hiermee kunt u een probleem voorkomen voordat het erger wordt, een onverwacht probleem detecteren tijdens de failover of zelfs weten of er daarna iets misgaat. U moet bijvoorbeeld controleren of uw toepassing toegang heeft tot uw nieuwe master door het aantal actieve verbindingen te controleren.
Belangrijke statistieken om te controleren
Laten we eens kijken naar enkele van de belangrijkste statistieken om rekening mee te houden:
- Replicatievertraging
- Replicatiestatus
- Aantal verbindingen
- Netwerkgebruik/fouten
- Serverbelasting (CPU, geheugen, schijf)
- Database- en systeemlogboeken
Terugdraaien
Als er iets mis is gegaan, moet je natuurlijk terug kunnen draaien. Het blokkeren van verkeer naar het oude knooppunt en het zo geïsoleerd mogelijk houden, kan hiervoor een goede strategie zijn, dus voor het geval u moet terugdraaien, heeft u het oude knooppunt beschikbaar. Als het terugdraaien na enkele minuten plaatsvindt, moet u, afhankelijk van het verkeer, waarschijnlijk de gegevens van deze minuten in de oude master invoeren, dus zorg ervoor dat u ook uw tijdelijke masternode beschikbaar en geïsoleerd hebt om deze informatie op te nemen en terug toe te passen .
Automatiseer het failoverproces met ClusterControl
Als je al deze noodzakelijke taken ziet om een failover uit te voeren, wil je deze waarschijnlijk automatiseren en al dit handmatige werk vermijden. Hiervoor kunt u profiteren van enkele van de functies die ClusterControl u kan bieden voor verschillende databasetechnologieën, zoals automatisch herstel, back-ups, gebruikersbeheer, bewaking en andere functies, allemaal vanuit hetzelfde systeem.
Met ClusterControl kunt u de replicatiestatus en de vertraging ervan verifiëren, referenties maken of wijzigen, de netwerk- en hoststatus kennen en zelfs nog meer verificaties.
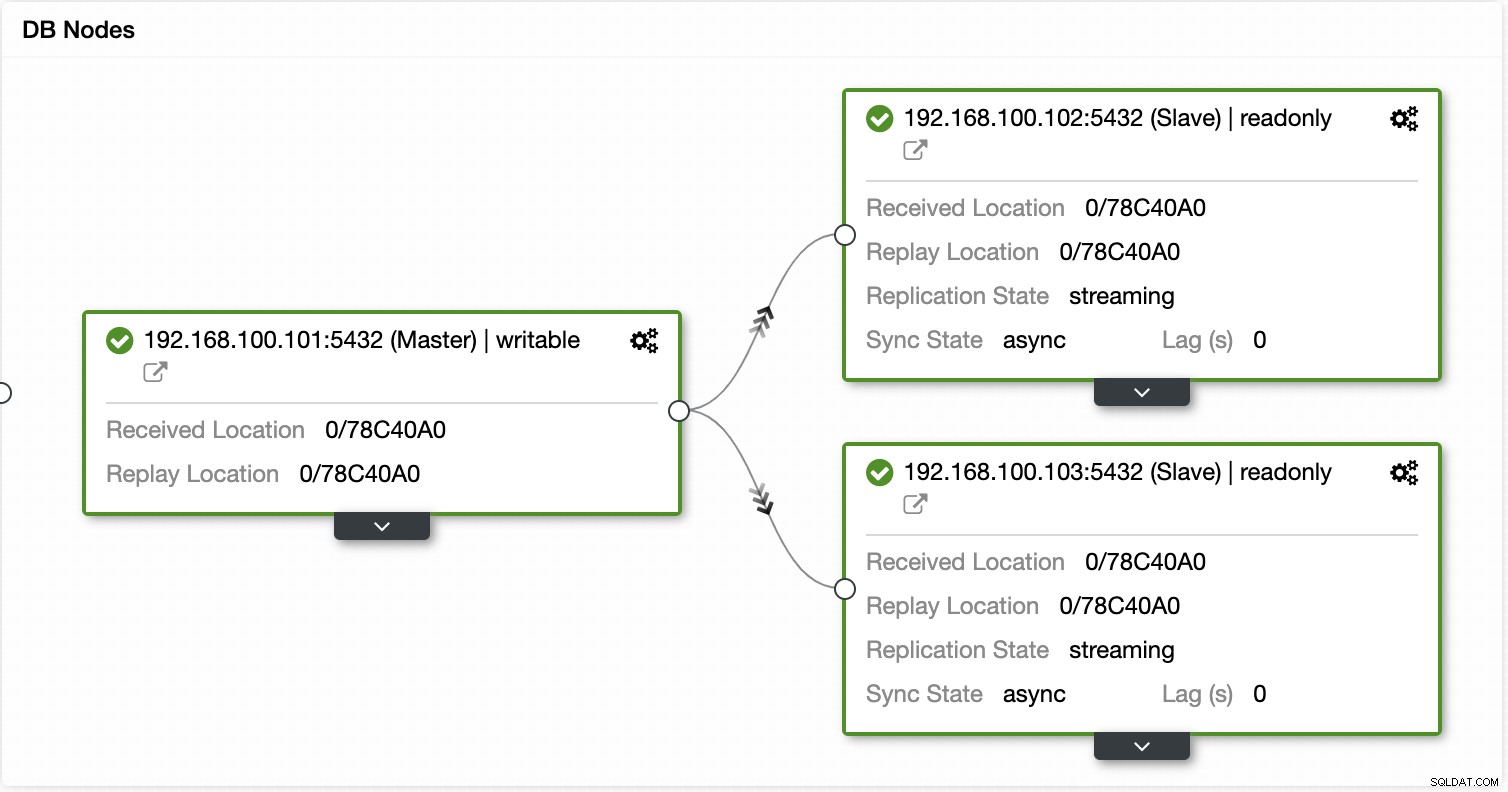
Met ClusterControl kunt u ook verschillende cluster- en knooppuntacties uitvoeren, zoals slaaf promoten , database en server opnieuw opstarten, databaseknooppunten toevoegen of verwijderen, load balancer-knooppunten toevoegen of verwijderen, een replicatieslave opnieuw opbouwen en meer.
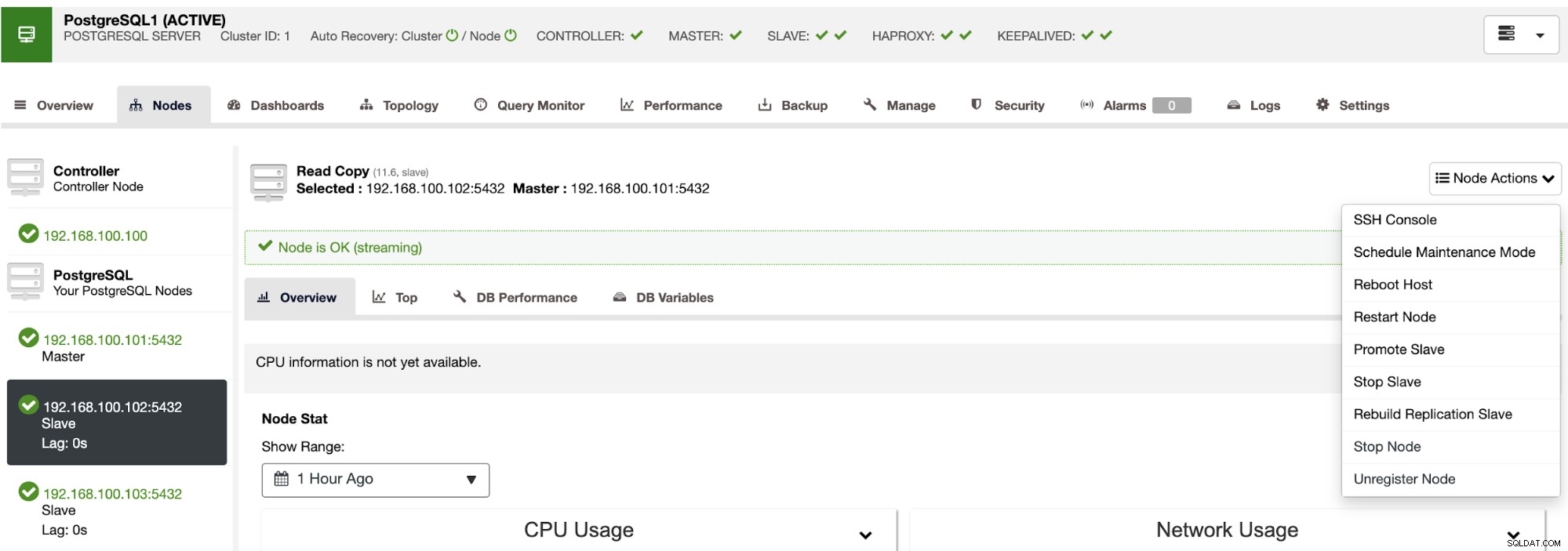
Met deze acties kunt u indien nodig uw failover terugdraaien door opnieuw op te bouwen en te promoten de vorige meester.
ClusterControl heeft bewakings- en waarschuwingsservices die u helpen te weten wat er gebeurt of zelfs of er eerder iets is gebeurd.
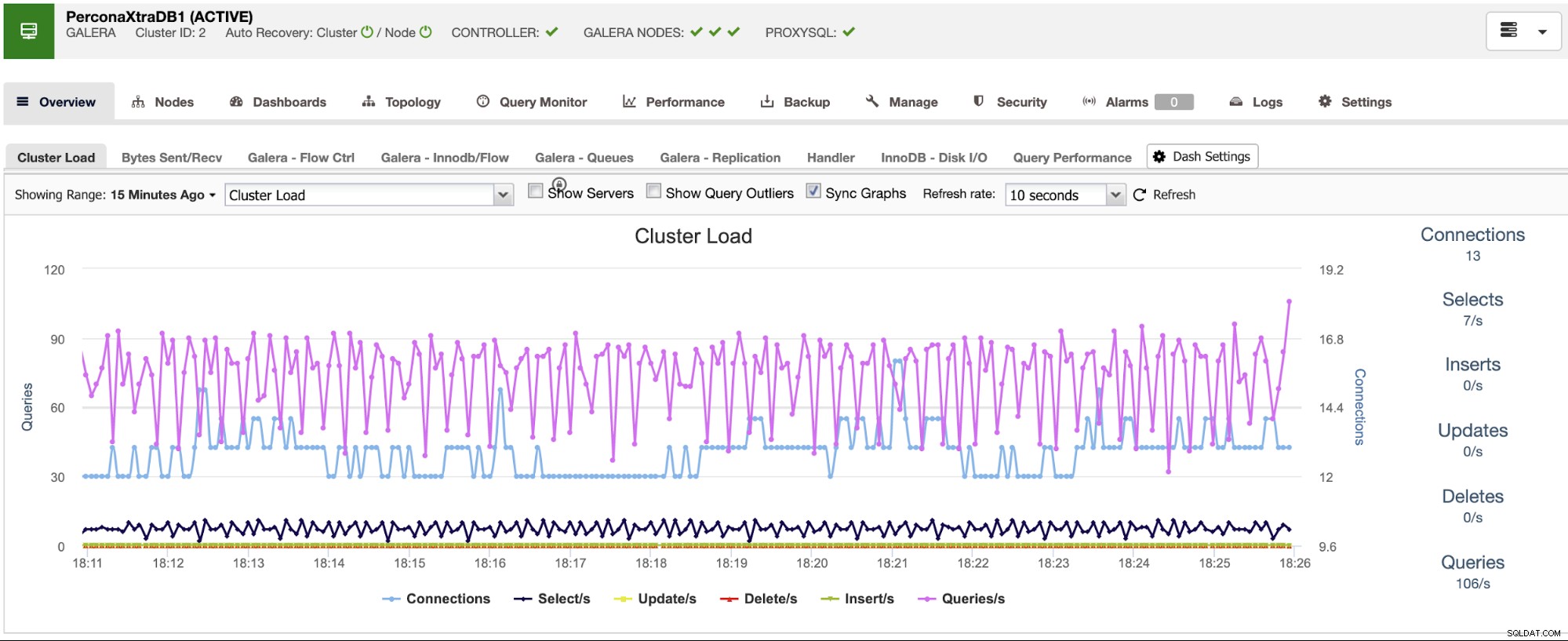
U kunt ook het dashboardgedeelte gebruiken voor een gebruiksvriendelijkere weergave over de status van uw systemen.
Conclusie
In het geval van een storing in de masterdatabase, wil je dat alle informatie aanwezig is om zo snel mogelijk de nodige acties te ondernemen. Het hebben van een goede DRP is de sleutel om uw systeem de hele (of bijna altijd) aan de gang te houden. Deze DRP moet een goed gedocumenteerd failoverproces bevatten om een acceptabele RTO (Recovery Time Objective) voor het bedrijf te hebben.