"Maar het werkte prima op onze ontwikkelserver!"
Hoe vaak heb ik het niet gehoord toen hier en daar problemen met de prestaties van SQL-query's optraden? Ik zei het zelf terug in de dag. Ik nam aan dat een query die in minder dan een seconde wordt uitgevoerd, prima zou werken op productieservers. Maar ik had het mis.
Herken je deze ervaring? Als je om wat voor reden dan ook nog steeds in deze boot zit, is dit bericht iets voor jou. Het geeft u een betere maatstaf voor het verfijnen van uw SQL-queryprestaties. We zullen het hebben over drie van de meest kritische figuren in STATISTICS IO.
Als voorbeeld gebruiken we de AdventureWorks-voorbeelddatabase.
Schakel STATISTICS IO in voordat u onderstaande query's gaat uitvoeren. Zo doet u het in een queryvenster:
USE AdventureWorks
GO
SET STATISTICS IO ONZodra u een zoekopdracht uitvoert met STATISTICS IO ON, verschijnen er verschillende berichten. U kunt deze zien op het tabblad Berichten van het queryvenster in SQL Server Management Studio (zie Afbeelding 1):
Nu we klaar zijn met de korte intro, gaan we dieper graven.
1. Hoge logische waarden
Het eerste punt in onze lijst is de meest voorkomende boosdoener:hoge logische waarden.
Logische leesbewerkingen zijn het aantal pagina's dat uit de gegevenscache is gelezen. Een pagina is 8 KB groot. Gegevenscache daarentegen verwijst naar RAM dat wordt gebruikt door SQL Server.
Logische uitlezingen zijn cruciaal voor het afstemmen van prestaties. Deze factor bepaalt hoeveel een SQL Server nodig heeft om de vereiste resultatenset te produceren. Daarom is het enige dat u moet onthouden:hoe hoger de logische waarden, hoe langer de SQL Server moet werken. Het betekent dat uw zoekopdracht langzamer zal zijn. Verminder het aantal logische leesbewerkingen en u zult uw queryprestaties verbeteren.
Maar waarom zou je logische uitlezingen gebruiken in plaats van verstreken tijd?
- De verstreken tijd hangt af van andere dingen die door de server worden gedaan, niet alleen van uw vraag.
- De verstreken tijd kan veranderen van ontwikkelingsserver naar productieserver. Dit gebeurt wanneer beide servers verschillende capaciteiten en hardware- en softwareconfiguraties hebben.
Als u vertrouwt op de verstreken tijd, zult u zeggen:"Maar het werkte prima op onze ontwikkelingsserver!" vroeg of laat.
Waarom logische uitlezingen gebruiken in plaats van fysieke uitlezingen?
- Fysieke leesbewerkingen zijn het aantal pagina's dat is gelezen van schijven naar de gegevenscache (in het geheugen). Zodra de pagina's die nodig zijn voor een zoekopdracht zich in de gegevenscache bevinden, is het niet nodig om ze opnieuw van schijven te lezen.
- Als dezelfde query opnieuw wordt uitgevoerd, zijn de fysieke uitlezingen nul.
Logische leesbewerkingen zijn de logische keuze voor het verfijnen van de prestaties van SQL-query's.
Laten we naar een voorbeeld gaan om dit in actie te zien.
Voorbeeld van logische uitlezingen
Stel dat u de lijst met klanten nodig heeft met bestellingen die op 11 juli 2011 zijn verzonden. U komt met de onderstaande vrij eenvoudige vraag:
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM Sales.SalesOrderHeader a
INNER JOIN Sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'Het is eenvoudig. Deze query heeft de volgende output:

Vervolgens controleert u het STATISTICS IO-resultaat van deze zoekopdracht:

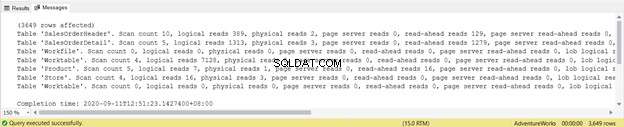
De uitvoer toont de logische leesbewerkingen van elk van de vier tabellen die in de query worden gebruikt. In totaal is de som van de logische uitlezingen 729. U kunt ook fysieke uitlezingen zien met een totale som van 21. Maar probeer de query opnieuw uit te voeren, en het zal nul zijn.
Bekijk de logische lezing van SalesOrderHeader . nauwkeuriger . Vraag je je af waarom het 689 logische reads heeft? Misschien heb je overwogen om het uitvoeringsplan van de onderstaande query te bekijken:
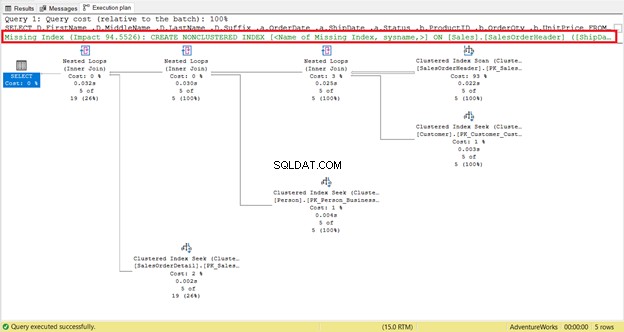
Om te beginnen is er een indexscan die is uitgevoerd in SalesOrderHeader met een kostprijs van 93%. Wat zou er kunnen gebeuren? Stel dat je de eigenschappen ervan hebt gecontroleerd:
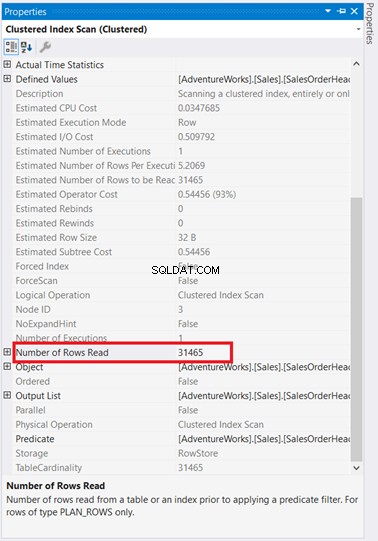
Wauw! 31.465 rijen gelezen voor slechts 5 geretourneerde rijen? Het is absurd!
Het aantal logische leesbewerkingen verminderen
Het is niet zo moeilijk om die 31.465 rijen te verminderen die worden gelezen. SQL Server gaf ons al een idee. Ga naar het volgende:
STAP 1:volg de aanbeveling van SQL Server en voeg de ontbrekende index toe
Is het ontbrekende indexadvies in het uitvoeringsplan u opgevallen (Figuur 4)? Zal dat het probleem oplossen?
Er is één manier om erachter te komen:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_ShipDate]
ON [Sales].[SalesOrderHeader] ([ShipDate])Voer de query opnieuw uit en bekijk de wijzigingen in de logische uitlezingen van STATISTICS IO.

Zoals u kunt zien in STATISTICS IO (Afbeelding 6), is er een enorme afname in logische uitlezingen van 689 naar 17. De nieuwe algemene logische uitlezingen zijn 57, wat een aanzienlijke verbetering is ten opzichte van 729 logische uitlezingen. Maar laten we voor de zekerheid het uitvoeringsplan nog eens bekijken.
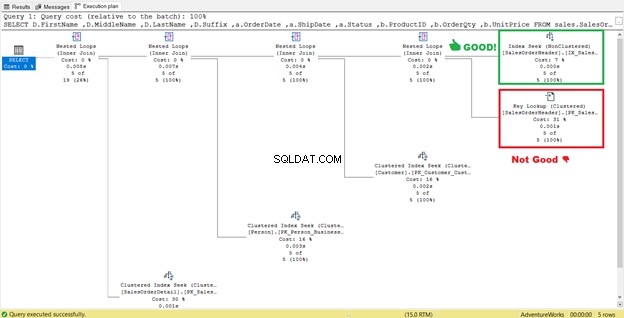
Het lijkt erop dat er een verbetering is in het plan, wat resulteert in minder logische leesbewerkingen. De indexscan is nu een indexzoekopdracht. SQL Server hoeft niet langer rij voor rij te inspecteren om de records te krijgen met de Shipdate=’07/11/2011′ . Maar er ligt nog steeds iets op de loer in dat plan, en het klopt niet.
Je hebt stap 2 nodig.
STAP 2:wijzig de index en voeg toe aan de meegeleverde kolommen:orderdatum, status en klant-ID
Zie je die Key Lookup-operator in het uitvoeringsplan (Figuur 7)? Het betekent dat de gemaakte niet-geclusterde index niet voldoende is - de queryprocessor moet de geclusterde index opnieuw gebruiken.
Laten we de eigenschappen ervan controleren.
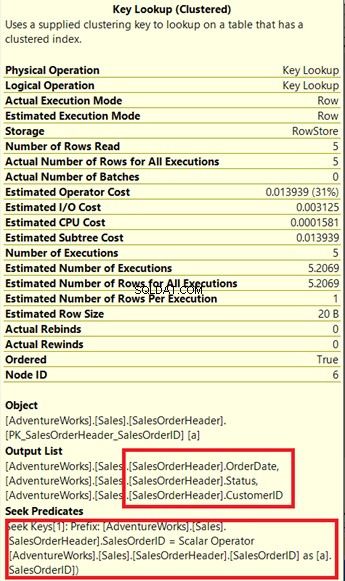
Let op het bijgevoegde vak onder de Uitvoerlijst . Het komt voor dat we OrderDate . nodig hebben , Status , en Klant-ID in de resultaatset. Om die waarden te verkrijgen, gebruikte de queryprocessor de geclusterde index (Zie de Seek Predicates ) om naar de tafel te gaan.
We moeten die Key Lookup verwijderen. De oplossing is om de OrderDate . op te nemen , Status , en Klant-ID kolommen in de eerder gemaakte index.
- Klik met de rechtermuisknop op de IX_SalesOrderHeader_ShipDate in SSMS.
- Selecteer Eigenschappen .
- Klik op de Opgenomen kolommen tabblad.
- Voeg Orderdatum toe , Status , en Klant-ID .
- Klik op OK .
Nadat u de index opnieuw hebt gemaakt, voert u de query opnieuw uit. Verwijdert dit Key Lookup en logische uitlezingen verminderen?

Het werkte! Van 17 logische uitlezingen naar 2 (Figuur 9).
En de Key Lookup ?
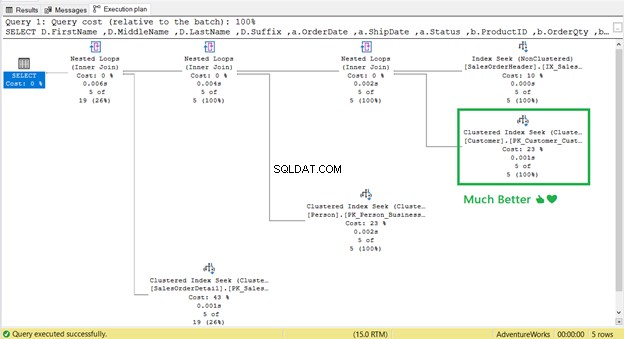
Het is weg! Geclusterde index zoeken heeft Key Lookup vervangen.
De afhaalmaaltijd
Dus, wat hebben we geleerd?
Een van de belangrijkste manieren om logische leesbewerkingen te verminderen en de prestaties van SQL-query's te verbeteren, is door een geschikte index te maken. Maar er is een addertje onder het gras. In ons voorbeeld verminderde het de logische uitlezingen. Soms zal het tegenovergestelde juist zijn. Het kan ook de prestaties van andere gerelateerde zoekopdrachten beïnvloeden.
Controleer daarom altijd de STATISTICS IO en het uitvoeringsplan na het aanmaken van de index.
2. Logische uitlezingen met hoge lob
Het is vrijwel hetzelfde als punt #1, maar het gaat over gegevenstypen tekst , ntekst , afbeelding , varchar (max ), nvarchar (max ), varbinair (max ), of kolomwinkel indexpagina's.
Laten we naar een voorbeeld verwijzen:lob logische reads genereren.
Voorbeeld van Lob logische uitlezingen
Stel dat u een product met zijn prijs, kleur, miniatuurafbeelding en een grotere afbeelding op een webpagina wilt weergeven. U komt dus met een eerste vraag zoals hieronder weergegeven:
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,b.Name AS ProductSubcategory
,d.ThumbNailPhoto
,d.LargePhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
ORDER BY ProductSubcategory, ProductName, a.ColorVervolgens voer je het uit en zie je de uitvoer zoals hieronder:

Omdat je zo'n prestatiegerichte kerel (of gal) bent, check je meteen de STATISTICS IO. Hier is het:

Het voelt als vuil in je ogen. 665 lob logische leest? U kunt dit niet accepteren. Om nog maar te zwijgen van 194 logische leesbewerkingen, elk van ProductPhoto en ProductProductPhoto tafels. Je denkt inderdaad dat deze zoekopdracht enkele wijzigingen behoeft.
Lob logische uitlezingen verminderen
De vorige query had 97 rijen geretourneerd. Alle 97 fietsen. Denk je dat dit goed is om op een webpagina weer te geven?
Een index kan helpen, maar waarom zou u de query niet eerst vereenvoudigen? Op deze manier kunt u selectief zijn in wat SQL Server teruggeeft. U kunt de lob-logische uitlezingen verminderen.
- Voeg een filter toe voor de productsubcategorie en laat de klant kiezen. Neem dit dan op in de WHERE-clausule.
- Verwijder de ProductSubcategory kolom, aangezien u een filter voor de subcategorie Product toevoegt.
- Verwijder de Grote foto kolom. Vraag hiernaar wanneer de gebruiker een specifiek product selecteert.
- Gebruik paging. De klant kan niet alle 97 fietsen tegelijk bekijken.
Op basis van de hierboven beschreven bewerkingen wijzigen we de zoekopdracht als volgt:
- Verwijder ProductSubcategory en Grote foto kolommen uit de resultatenset.
- Gebruik OFFSET en FETCH om paginering in de query mogelijk te maken. Vraag slechts 10 producten tegelijk.
- Voeg ProductSubcategoryID toe in de WHERE-clausule op basis van de selectie van de klant.
- Verwijder de ProductSubcategory kolom in de ORDER BY-clausule.
De zoekopdracht ziet er nu als volgt uit:
DECLARE @pageNumber TINYINT
DECLARE @noOfRows TINYINT = 10 -- each page will display 10 products at a time
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,d.ThumbNailPhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
AND a.ProductSubcategoryID = 2 -- Road Bikes
ORDER BY ProductName, a.Color
OFFSET (@pageNumber-1)*@noOfRows ROWS FETCH NEXT @noOfRows ROWS ONLY
-- change the OFFSET and FETCH values based on what page the user is.Zullen lob logische uitlezingen verbeteren met de wijzigingen? STATISTIEKEN IO rapporteert nu:

Productfoto tabel heeft nu 0 lob logische uitlezingen - van 665 lob logische uitlezingen tot geen. Dat is een verbetering.
Afhaalmaaltijden
Een van de manieren om lob-logische leesbewerkingen te verminderen, is door de query te herschrijven om deze te vereenvoudigen.
Verwijder onnodige kolommen en verminder de geretourneerde rijen tot het minst vereiste. Gebruik indien nodig OFFSET en FETCH voor paging.
Controleer altijd STATISTICS IO om ervoor te zorgen dat de querywijzigingen de logische lob-lezingen en de SQL-queryprestaties hebben verbeterd.
3. Hoge werktafel/werkbestand logische uitlezingen
Ten slotte is het een logische lezing van Werktafel en Werkbestand . Maar wat zijn deze tabellen? Waarom verschijnen ze als je ze niet gebruikt in je zoekopdracht?
Werktafel . hebben en Werkbestand verschijnen in de STATISTICS IO betekent dat SQL Server veel meer werk nodig heeft om de gewenste resultaten te krijgen. Het neemt zijn toevlucht tot het gebruik van tijdelijke tabellen in tempdb , namelijk Werktafels en Werkbestanden . Het is niet per se schadelijk om ze in de STATISTICS IO-uitvoer te hebben, zolang de logische uitlezingen nul zijn en het geen problemen oplevert voor de server.
Deze tabellen kunnen verschijnen wanneer er onder andere een ORDER BY, GROUP BY, CROSS JOIN of DISTINCT is.
Voorbeeld van logische uitlezingen van werktafel/werkbestand
Stel dat u alle winkels moet doorzoeken zonder verkoop van bepaalde producten.
Je komt in eerste instantie met het volgende:
SELECT DISTINCT
a.SalesPersonID
,b.ProductID
,ISNULL(c.OrderTotal,0) AS OrderTotal
FROM Sales.Store a
CROSS JOIN Production.Product b
LEFT JOIN (SELECT
b.SalesPersonID
,a.ProductID
,SUM(a.LineTotal) AS OrderTotal
FROM Sales.SalesOrderDetail a
INNER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
WHERE b.SalesPersonID IS NOT NULL
GROUP BY b.SalesPersonID, a.ProductID, b.OrderDate) c ON a.SalesPersonID
= c.SalesPersonID
AND b.ProductID = c.ProductID
WHERE c.OrderTotal IS NULL
ORDER BY a.SalesPersonID, b.ProductIDDeze zoekopdracht leverde 3649 rijen op:
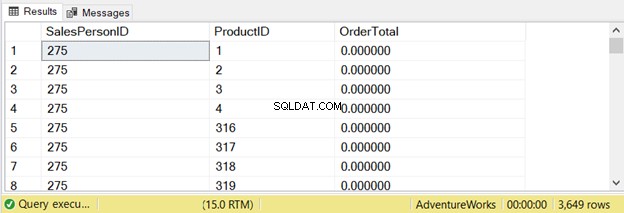
Laten we eens kijken wat de STATISTICS IO vertelt:

Het is de moeite waard om op te merken dat de Werktafel logische waarden zijn 7128. De algemene logische waarden zijn 8853. Als u het uitvoeringsplan controleert, ziet u veel parallellismen, hash-overeenkomsten, spools en indexscans.
Het verminderen van logische uitlezingen van werktafels/werkbestanden
Ik kon geen enkele SELECT-instructie construeren met een bevredigend resultaat. De enige keuze is dus om de SELECT-instructie op te splitsen in meerdere query's. Zie hieronder:
SELECT DISTINCT
a.SalesPersonID
,b.ProductID
INTO #tmpStoreProducts
FROM Sales.Store a
CROSS JOIN Production.Product b
SELECT
b.SalesPersonID
,a.ProductID
,SUM(a.LineTotal) AS OrderTotal
INTO #tmpProductOrdersPerSalesPerson
FROM Sales.SalesOrderDetail a
INNER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
WHERE b.SalesPersonID IS NOT NULL
GROUP BY b.SalesPersonID, a.ProductID
SELECT
a.SalesPersonID
,a.ProductID
FROM #tmpStoreProducts a
LEFT JOIN #tmpProductOrdersPerSalesPerson b ON a.SalesPersonID = b.SalesPersonID AND
a.ProductID = b.ProductID
WHERE b.OrderTotal IS NULL
ORDER BY a.SalesPersonID, a.ProductID
DROP TABLE #tmpProductOrdersPerSalesPerson
DROP TABLE #tmpStoreProductsHet is een aantal regels langer en er worden tijdelijke tabellen gebruikt. Laten we nu eens kijken wat de STATISTICS IO onthult:
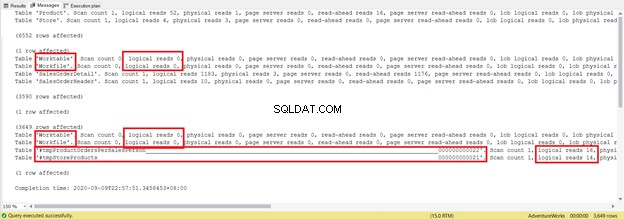
Probeer je niet te concentreren op deze statistische rapportlengte - het is alleen maar frustrerend. Voeg in plaats daarvan logische waarden toe aan elke tabel.
Voor een totaal van 1279 is dit een significante afname, aangezien het 8853 logische reads waren van de enkele SELECT-instructie.
We hebben geen index toegevoegd aan de tijdelijke tabellen. Mogelijk hebt u er een nodig als er veel meer records worden toegevoegd aan SalesOrderHeader en SalesOrderDetail . Maar je begrijpt het punt.
Afhaalmaaltijden
Soms lijkt 1 SELECT-instructie goed. Achter de schermen is echter het tegenovergestelde waar. Werktafels en Werkbestanden met hoge logische leesvertragingen lopen uw SQL-queryprestaties achter.
Als u geen andere manier kunt bedenken om de query te reconstrueren en de indexen zijn nutteloos, probeer dan de "verdeel en heers"-benadering. De Werktafels en Werkbestanden kan nog steeds verschijnen op het tabblad Bericht van SSMS, maar de logische waarden zijn nul. Daarom zal het algemene resultaat minder logische lezingen zijn.
De bottomline in SQL Query Performance en STATISTICS IO
Wat is het probleem met deze 3 vervelende I/O-statistieken?
Het verschil in de prestaties van SQL-query's zal dag en nacht zijn als u op deze cijfers let en ze verlaagt. We hebben alleen enkele manieren gepresenteerd om logische leesbewerkingen te verminderen, zoals:
- het maken van geschikte indexen;
- het vereenvoudigen van zoekopdrachten – het verwijderen van onnodige kolommen en het minimaliseren van de resultatenset;
- een zoekopdracht opsplitsen in meerdere zoekopdrachten.
Er zijn meer dingen zoals het bijwerken van statistieken, het defragmenteren van indexen en het instellen van de juiste FILLFACTOR. Kun je hier meer aan toevoegen in het commentaargedeelte?
Als je dit bericht leuk vindt, deel het dan met je favoriete sociale media.