Inner join, outer join, cross join? Wat geeft?
Het is een geldige vraag. Ik zag ooit een Visual Basic-code met daarin T-SQL-codes. De VB-code haalt tabelrecords op met meerdere SELECT-instructies, één SELECT * per tabel. Vervolgens combineert het meerdere resultaatsets tot een recordset. Absurd?
Voor de jonge ontwikkelaars die het deden, was het dat niet. Maar toen ze me vroegen te evalueren waarom het systeem traag was, was dat het eerste dat mijn aandacht trok. Dat klopt. Ze hebben nog nooit van SQL-joins gehoord. Eerlijk gezegd waren ze eerlijk en stonden ze open voor suggesties.
Hoe beschrijf je SQL-joins? Misschien herinner je je één nummer - Stel je voor door John Lennon:
Je zou kunnen zeggen dat ik een dromer ben, maar ik ben niet de enige.
Ik hoop dat je je ooit bij ons zult voegen, en dat de wereld één zal zijn.
In de context van het nummer is samenvoegen verenigen. In een SQL-database vormt het combineren van records van 2 of meer tabellen in één resultaatset een join .
Dit artikel is het begin van een driedelige serie over SQL-joins:
- INNER JOIN
- OUTER JOIN, inclusief LEFT, RIGHT en FULL
- CROSS JOIN
Maar voordat we INNER JOIN gaan bespreken, laten we de joins in het algemeen beschrijven.

Meer over SQL JOIN
Joins verschijnen direct na de FROM-clausule. In zijn eenvoudigste vorm lijkt het op het gebruik van de SQL-92-standaard:
FROM <table source> [<alias1>]
<join type> JOIN <table source> [<alias2>] [ON <join condition>]
[<join type> JOIN <table source> [<alias3>] [ON <join condition>]
<join type> JOIN <table source> [<aliasN>] [ON <join condition>]]
[WHERE <condition>]Laten we de alledaagse dingen rondom de JOIN beschrijven.
Tabelbronnen
Volgens Microsoft kun je maximaal 256 tabellen toevoegen. Het hangt natuurlijk af van uw serverbronnen. Ik heb in mijn leven nog nooit aan meer dan 10 tafels deelgenomen, om nog maar te zwijgen van 256. Hoe dan ook, tabelbronnen kunnen een van de volgende zijn:
- Tabel
- Bekijken
- Tabel of bekijk synoniem
- Tabelvariabele
- Tabelwaardefunctie
- Afgeleide tabel
Tabelalias
Een alias is optioneel, maar het verkort uw code en minimaliseert typen. Het helpt u ook fouten te voorkomen wanneer een kolomnaam voorkomt in twee of meer tabellen die worden gebruikt in een SELECT, UPDATE, INSERT of DELETE. Het voegt ook duidelijkheid toe aan uw code. Het is optioneel, maar ik raad het gebruik van aliassen aan. (Tenzij je graag tabelbronnen op naam typt.)
Voorwaarde voor deelname
Het sleutelwoord ON gaat vooraf aan de join-voorwaarde die een enkele join of kolommen met twee sleutels uit de 2 samengevoegde tabellen kan zijn. Of het kan een samengestelde join zijn die meer dan 2 sleutelkolommen gebruikt. Het definieert hoe tabellen gerelateerd zijn.
We gebruiken de join-voorwaarde echter alleen voor INNER- en OUTER-joins. Als u het op een CROSS JOIN gebruikt, wordt er een fout gegenereerd.
Omdat samenvoegvoorwaarden de relaties definiëren, hebben ze operators nodig.
De meest voorkomende operator voor join-voorwaarden is de operator gelijkheid (=). Andere operators zoals> of
De meeste joins kunnen worden herschreven als subquery's en omgekeerd. Bekijk dit artikel voor meer informatie over subquery's in vergelijking met joins.
Het gebruik van afgeleide tabellen in een join ziet er als volgt uit:
Het voegt zich bij het resultaat van een andere SELECT-instructie, en het is volkomen geldig.
U zult meer voorbeelden hebben, maar laten we nog een laatste ding over SQL JOINS behandelen. Het is hoe de Query Optimizer-processen van SQL Server joins verwerken.
Om te begrijpen hoe het proces werkt, moet u de twee soorten bewerkingen kennen:
Eén woord:prestatie.
Eén ding is om te weten hoe u query's met joins moet vormen om correcte resultaten te produceren. Een andere is om het zo snel mogelijk te laten lopen. U moet zich hier extra zorgen over maken als u een goede reputatie bij uw gebruikers wilt hebben.
Dus, waar moet je op letten in het Uitvoeringsplan voor deze logische bewerkingen?
Deelname-hints zijn nieuw in SQL Server 2019. Wanneer u deze in uw joins gebruikt, vertelt het de query-optimizer om te stoppen met beslissen wat het beste is voor de query. Jij bent de baas als het gaat om de te gebruiken fysieke join.
Stop nu, daar. De waarheid is dat de query-optimizer doorgaans de beste fysieke join voor uw query selecteert. Als je niet weet wat je doet, gebruik dan geen hints om mee te doen.
De mogelijke hints die je kunt specificeren zijn LOOP, MERGE, HASH of REMOTE.
Ik heb geen join-hints gebruikt, maar hier is de syntaxis:
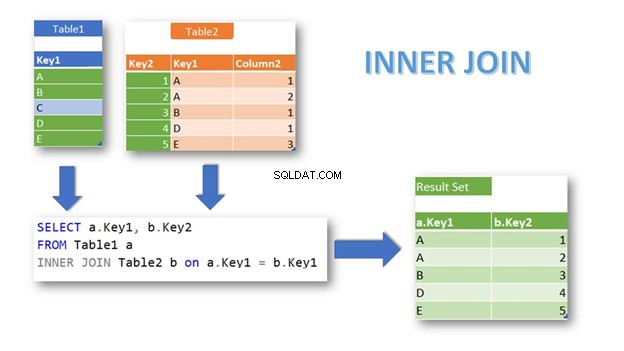
INNER JOIN retourneert de rijen met overeenkomende records in beide tabellen, op basis van een voorwaarde. Het is ook de standaard join als u het trefwoord INNER niet opgeeft:
Zoals u ziet, overeenkomende rijen uit Tabel1 en Tabel2 worden geretourneerd met Sleutel1 als de verbindingsvoorwaarde. De Tabel1 opnemen met Sleutel1 ='C' is uitgesloten omdat er geen overeenkomende records zijn in Tabel2 .
Wanneer ik een vraag stel, is mijn eerste keuze INNER JOIN. OUTER JOIN komt alleen wanneer de vereisten het dicteren.
Er worden twee INNER JOIN-syntaxis ondersteund in T-SQL:SQL-92 en SQL-89.
De eerste join-syntaxis die ik leerde was SQL-89. Toen SQL-92 eindelijk arriveerde, vond ik het te lang. Ik dacht ook dat de uitvoer hetzelfde was, waarom zou ik dan nog meer zoekwoorden typen? Een grafische ontwerper van query's had de gegenereerde code SQL-92, en ik veranderde het terug naar SQL-89. Maar vandaag geef ik de voorkeur aan SQL-92, zelfs als ik meer moet typen. Dit is waarom:
Bovenstaande redenen zijn van mij. Je hebt misschien je redenen waarom je de voorkeur geeft aan SQL-92 of waarom je er een hekel aan hebt. Ik vraag me af wat die redenen zijn. Laat het me weten in het gedeelte Opmerkingen hieronder.
Maar we kunnen dit artikel niet beëindigen zonder voorbeelden en uitleg.
Hier is een voorbeeld van 2 tabellen die samengevoegd zijn met INNER JOIN in SQL-92-syntaxis.
U geeft alleen de kolommen op die u nodig heeft. In het bovenstaande voorbeeld zijn 4 kolommen gespecificeerd. Ik weet dat het te lang is dan SELECT * maar onthoud dit:het is de beste methode.
Let ook op het gebruik van tabelaliassen. Zowel het Product en ProductSubcategory tabellen hebben een kolom met de naam [Naam ]. Als u de alias niet opgeeft, wordt er een fout geactiveerd.
Ondertussen is hier de equivalente SQL-89-syntaxis:
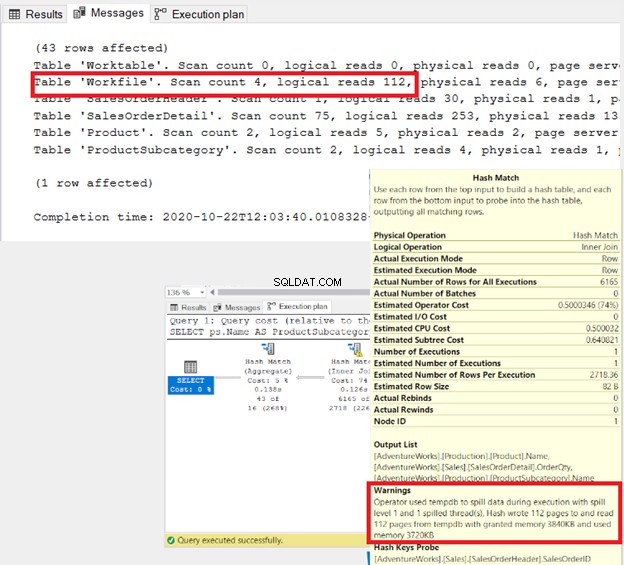
Ze zijn hetzelfde, behalve de join-voorwaarde die in de WHERE-component is gemengd met een AND-sleutelwoord. Maar onder de motorkap, zijn ze echt hetzelfde? Laten we de resultatenset, de STATISTICS IO en het uitvoeringsplan eens bekijken.
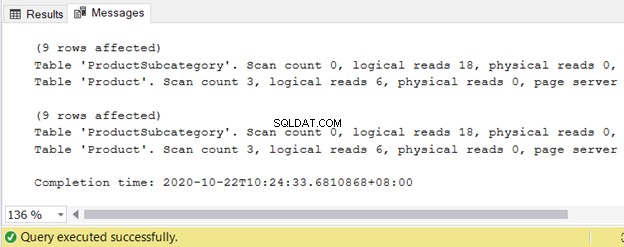
Bekijk de resultatenset van 9 records:
Het zijn niet alleen de resultaten, maar ook de resources die SQL Server nodig heeft, zijn hetzelfde.
Zie de logische waarden:
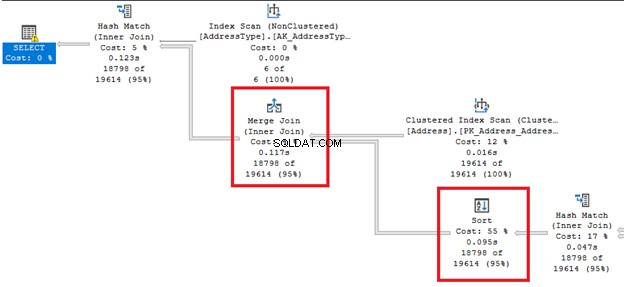
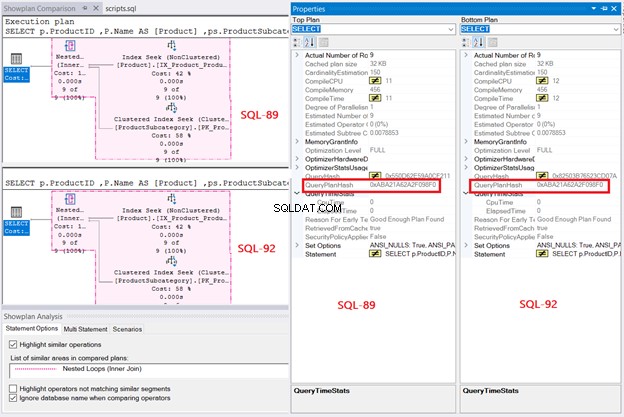
Ten slotte onthult het uitvoeringsplan hetzelfde queryplan voor beide query's wanneer hun QueryPlanHashes zijn gelijk. Let ook op de gemarkeerde bewerkingen in het diagram:
Op basis van de bevindingen is de SQL Server-queryverwerking hetzelfde, of het nu SQL-92 of SQL-89 is. Maar zoals ik al zei, de duidelijkheid in SQL-92 is veel beter voor mij.
Afbeelding 7 toont ook een geneste lusverbinding die in het plan wordt gebruikt. Waarom? De resultaatset is klein.
Bekijk de onderstaande zoekopdracht met behulp van 3 samengevoegde tabellen.
Je kunt ook 2 tabellen samenvoegen met 2 sleutels om het te relateren. Bekijk het voorbeeld hieronder. Het gebruikt 2 voorwaarden voor samenvoegen met een AND-operator.
In het onderstaande voorbeeld is het Product tafel heeft 9 records - een kleine set. De samengevoegde tabel is SalesOrderDetail - een grote set. De Query Optimizer gebruikt een geneste lus-join, zoals weergegeven in afbeelding 8.
In het onderstaande voorbeeld wordt een Merge Join gebruikt omdat beide invoertabellen zijn gesorteerd op SalesOrderID.
In het volgende voorbeeld wordt een hash-join gebruikt:
In het onderstaande voorbeeld is de SalesPerson tabel heeft een niet-geclusterde ColumnStore-index op de TerritoryID kolom. De Query Optimizer heeft gekozen voor een geneste lusverbinding, zoals weergegeven in afbeelding 11.
Overweeg deze verklaring met een geneste subquery:
Dezelfde resultaten kunnen verschijnen als je het verandert in een INNER JOIN, zoals hieronder:
Een andere manier om het te herschrijven is door een afgeleide tabel te gebruiken als tabelbron voor de INNER JOIN:
Alle 3 de zoekopdrachten leveren dezelfde 48 records op.
De volgende query gebruikt een geneste lus:
Als je het tot een hash-join wilt forceren, gebeurt dit als volgt:
Houd er echter rekening mee dat STATISTICS IO laat zien dat de prestaties slecht zullen worden als je het dwingt tot een hash-join.
Ondertussen gebruikt de onderstaande query een Merge Join:
Dit wordt het als je het dwingt tot een geneste lus:
Na het controleren van de STATISTICS IO van beide, vereist het forceren van een geneste lus meer middelen om de query te verwerken:
Het gebruik van join-hints zou dus je laatste redmiddel moeten zijn bij het tweaken voor prestaties. Laat uw SQL Server het voor u afhandelen.
U kunt INNER JOIN ook gebruiken in een UPDATE-statement. Hier is een voorbeeld:
Aangezien het mogelijk is om een join in een UPDATE te gebruiken, waarom probeert u het dan niet met DELETE en INSERT?
Dus, wat is er zo belangrijk aan SQL-join?
Ondertussen liet dit bericht 10 voorbeelden van INNER JOINs zien. Het zijn niet alleen voorbeeldcodes. Sommige bevatten ook een inspectie van hoe de code van binnenuit werkt. Het is niet alleen bedoeld om u te helpen coderen, maar om u te helpen bewust te zijn van de prestaties. Uiteindelijk moeten de resultaten niet alleen correct zijn, maar ook snel worden geleverd.
We zijn nog niet klaar. Het volgende artikel gaat over OUTER JOINS. Blijf op de hoogte.
Met SQL-joins kunt u gegevens uit meer dan één tabel ophalen en combineren. Bekijk deze video voor meer informatie over SQL Joins.SQL JOIN versus subquery's
Joins en afgeleide tabellen
FROM table1 a
INNER JOIN (SELECT y.column3 from table2 x
INNER JOIN table3 y on x.column1 = y.column1) b ON a.col1 = b.col2Hoe SQL Server-processen samenkomen

Waarom moeten we ons hier druk over maken?
Doe mee met hints
<join type> <join hint> JOIN <table source> [<alias>] ON <join condition>Alles over INNER JOIN
INNER JOIN-syntaxis
SQL-92 INNER JOIN
FROM <table source1> [<alias1>]
INNER JOIN <table source2> [<alias2>] ON <join condition1>
[INNER JOIN <table source3> [<alias3>] ON <join condition2>
INNER JOIN <table sourceN> [<aliasN>] ON <join conditionN>]
[WHERE <condition>]SQL-89 INNER JOIN
FROM <table source1> [alias1], <table source2> [alias2] [, <table source3> [alias3], <table sourceN> [aliasN]]
WHERE (<join condition1>)
[AND (<join condition2>)
AND (<join condition3>)
AND (<join conditionN>)]Welke INNER JOIN-syntaxis is beter?
10 INNER JOIN-voorbeelden
1. 2 tafels samenvoegen
-- Display Vests, Helmets, and Light products
USE AdventureWorks
GO
SELECT
p.ProductID
,P.Name AS [Product]
,ps.ProductSubcategoryID
,ps.Name AS [ProductSubCategory]
FROM Production.Product p
INNER JOIN Production.ProductSubcategory ps ON P.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE P.ProductSubcategoryID IN (25, 31, 33); -- for vest, helmet, and light
-- product subcategories-- Display Vests, Helmets, and Light products
USE AdventureWorks
GO
SELECT
p.ProductID
,P.Name AS [Product]
,ps.ProductSubcategoryID
,ps.Name AS [ProductSubCategory]
FROM Production.Product p, Production.ProductSubcategory ps
WHERE P.ProductSubcategoryID = ps.ProductSubcategoryID
AND P.ProductSubcategoryID IN (25, 31, 33);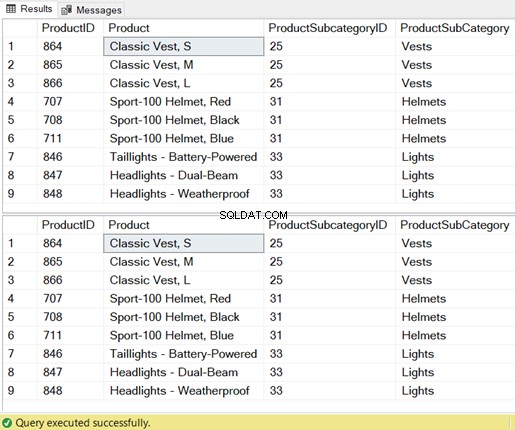
2. Meerdere tabellen samenvoegen
-- Get the total number of orders per Product Category
USE AdventureWorks
GO
SELECT
ps.Name AS ProductSubcategory
,SUM(sod.OrderQty) AS TotalOrders
FROM Production.Product p
INNER JOIN Sales.SalesOrderDetail sod ON P.ProductID = sod.ProductID
INNER JOIN Sales.SalesOrderHeader soh ON sod.SalesOrderID = soh.SalesOrderID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE soh.OrderDate BETWEEN '1/1/2014' AND '12/31/2014'
AND p.ProductSubcategoryID IN (1,2)
GROUP BY ps.Name
HAVING ps.Name IN ('Mountain Bikes', 'Road Bikes')3. Samengestelde deelname
SELECT
a.column1
,b.column1
,b.column2
FROM Table1 a
INNER JOIN Table2 b ON a.column1 = b.column1 AND a.column2 = b.column24. INNER JOIN Fysieke join met geneste lus gebruiken
USE AdventureWorks
GO
SELECT
sod.SalesOrderDetailID
,sod.ProductID
,P.Name
,P.ProductNumber
,sod.OrderQty
FROM Sales.SalesOrderDetail sod
INNER JOIN Production.Product p ON sod.ProductID = p.ProductID
WHERE P.ProductSubcategoryID IN(25, 31, 33);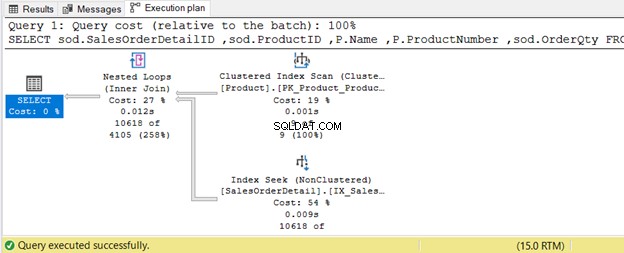
5. INNER JOIN Een fysieke samenvoeging gebruiken
SELECT
soh.SalesOrderID
,soh.OrderDate
,sod.SalesOrderDetailID
,sod.ProductID
,sod.LineTotal
FROM Sales.SalesOrderHeader soh
INNER JOIN sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID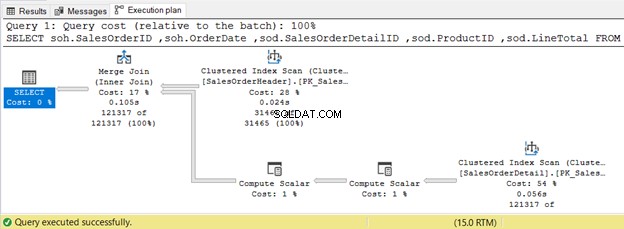
6. INNER JOIN Een fysieke hash-join gebruiken
SELECT
s.Name AS Store
,SUM(soh.TotalDue) AS TotalSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.Store s ON soh.SalesPersonID = s.SalesPersonID
GROUP BY s.Name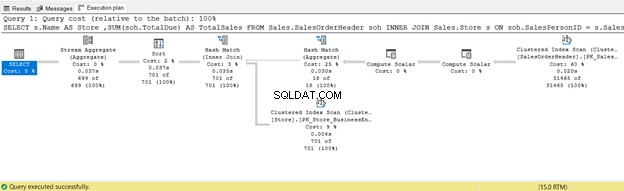
7. INNER JOIN Adaptive Physical Join gebruiken
SELECT
sp.BusinessEntityID
,sp.SalesQuota
,st.Name AS Territory
FROM Sales.SalesPerson sp
INNER JOIN Sales.SalesTerritory st ON sp.TerritoryID = st.TerritoryID
WHERE sp.TerritoryID BETWEEN 1 AND 5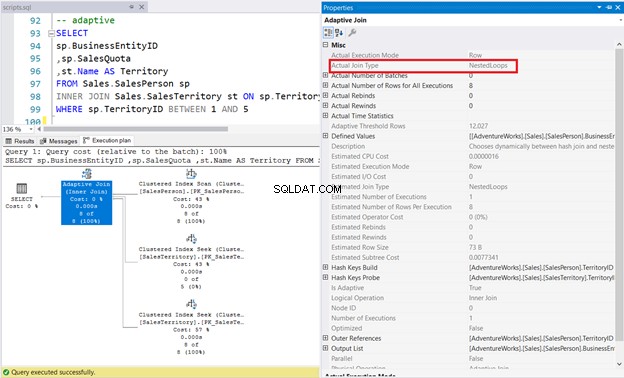
8. Twee manieren om een subquery te herschrijven naar een INNER JOIN
SELECT [SalesOrderID], [OrderDate], [ShipDate], [CustomerID]
FROM Sales.SalesOrderHeader
WHERE [CustomerID] IN (SELECT [CustomerID] FROM Sales.Customer
WHERE PersonID IN (SELECT BusinessEntityID FROM Person.Person
WHERE lastname LIKE N'I%' AND PersonType='SC'))SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.PersonType = 'SC'
AND p.lastname LIKE N'I%'SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN (SELECT c.CustomerID, P.PersonType, P.LastName
FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = P.BusinessEntityID
WHERE p.PersonType = 'SC'
AND p.LastName LIKE N'I%') AS q ON o.CustomerID = q.CustomerID9. Deelnametips gebruiken
SELECT
sod.SalesOrderDetailID
,sod.ProductID
,P.Name
,P.ProductNumber
,sod.OrderQty
FROM Sales.SalesOrderDetail sod
INNER JOIN Production.Product p ON sod.ProductID = p.ProductID
WHERE P.ProductSubcategoryID IN(25, 31, 33);SELECT
sod.SalesOrderDetailID
,sod.ProductID
,P.Name
,P.ProductNumber
,sod.OrderQty
FROM Sales.SalesOrderDetail sod
INNER HASH JOIN Production.Product p ON sod.ProductID = p.ProductID
WHERE P.ProductSubcategoryID IN(25, 31, 33);SELECT
soh.SalesOrderID
,soh.OrderDate
,sod.SalesOrderDetailID
,sod.ProductID
,sod.LineTotal
FROM Sales.SalesOrderHeader soh
INNER JOIN sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderIDSELECT
soh.SalesOrderID
,soh.OrderDate
,sod.SalesOrderDetailID
,sod.ProductID
,sod.LineTotal
FROM Sales.SalesOrderHeader soh
INNER LOOP JOIN sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID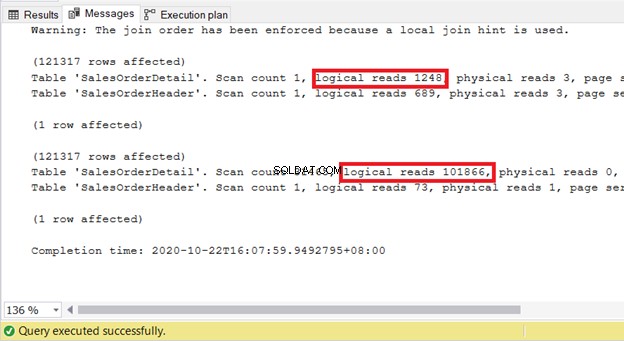
10. INNER JOIN gebruiken in UPDATE
UPDATE Sales.SalesOrderHeader
SET ShipDate = getdate()
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.PersonType = 'SC'SQL Join en INNER JOIN Takeaways
Zie ook