Mensen vragen zich af of ze hun best moeten doen om uitzonderingen te voorkomen, of dat ze het systeem gewoon moeten laten afhandelen. Ik heb verschillende discussies gezien waarin mensen debatteren of ze er alles aan moeten doen om een uitzondering te voorkomen, omdat foutafhandeling 'duur' is. Het lijdt geen twijfel dat foutafhandeling niet gratis is, maar ik zou voorspellen dat een overtreding van een beperking minstens zo efficiënt is als eerst controleren op een mogelijke overtreding. Dit kan bijvoorbeeld anders zijn voor een belangrijke overtreding dan een schending van een statische beperking, maar in dit bericht ga ik me concentreren op de eerste.
De belangrijkste benaderingen die mensen gebruiken om met uitzonderingen om te gaan zijn:
- Laat de engine het maar afhandelen en bel elke uitzondering terug naar de beller.
- Gebruik
BEGIN TRANSACTIONenROLLBACKif@@ERROR <> 0. - Gebruik
TRY/CATCHmetROLLBACKin deCATCHblok (SQL Server 2005+).
En velen nemen de benadering dat ze eerst moeten controleren of ze de overtreding gaan begaan, omdat het schoner lijkt om het duplicaat zelf af te handelen dan de engine te dwingen het te doen. Mijn theorie is dat je moet vertrouwen maar verifiëren; overweeg bijvoorbeeld deze benadering (meestal pseudo-code):
IF NOT EXISTS ([row that would incur a violation])
BEGIN
BEGIN TRY
BEGIN TRANSACTION;
INSERT ()...
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
-- well, we incurred a violation anyway;
-- I guess a new row was inserted or
-- updated since we performed the check
ROLLBACK TRANSACTION;
END CATCH
END
We weten dat de IF NOT EXISTS check garandeert niet dat iemand anders de rij niet heeft ingevoegd tegen de tijd dat we bij de INSERT komen (tenzij we agressieve sloten op de tafel plaatsen en/of SERIALIZABLE gebruiken) ), maar de buitenste controle voorkomt dat we proberen een fout te begaan en vervolgens terug moeten draaien. We blijven buiten de hele TRY/CATCH structuur als we al weten dat de INSERT zal mislukken, en het zou logisch zijn om aan te nemen dat dit – althans in sommige gevallen – efficiënter zal zijn dan het invoeren van de TRY/CATCH onvoorwaardelijk te structureren. Dit heeft weinig zin in een enkele INSERT scenario, maar stel je een geval voor waarin er meer aan de hand is in die TRY blokkering (en meer mogelijke overtredingen die u van tevoren zou kunnen controleren, wat betekent dat u nog meer werk moet verrichten dat u anders zou moeten doen en terugdraaien als er zich een latere overtreding voordoet).
Nu zou het interessant zijn om te zien wat er zou gebeuren als je een niet-standaard isolatieniveau zou gebruiken (iets dat ik in een toekomstige post zal behandelen), vooral met gelijktijdigheid. Voor dit bericht wilde ik echter langzaam beginnen en deze aspecten testen met een enkele gebruiker. Ik heb een tabel gemaakt met de naam dbo.[Objects] , een zeer simplistische tabel:
CREATE TABLE dbo.[Objects] ( ObjectID INT IDENTITY(1,1), Name NVARCHAR(255) PRIMARY KEY ); GO
Ik wilde deze tabel vullen met 100.000 rijen voorbeeldgegevens. Om de waarden in de naamkolom uniek te maken (aangezien de PK de beperking is die ik wilde schenden), heb ik een hulpfunctie gemaakt die een aantal rijen en een minimale tekenreeks nodig heeft. De minimumreeks zou worden gebruikt om ervoor te zorgen dat ofwel (a) de set begon boven de maximale waarde in de tabel Objecten, of (b) de set begon met de minimumwaarde in de tabel Objecten. (Ik zal deze tijdens de tests handmatig specificeren, eenvoudig geverifieerd door de gegevens te inspecteren, hoewel ik die controle waarschijnlijk in de functie had kunnen inbouwen.)
CREATE FUNCTION dbo.GenerateRows(@n INT, @minString NVARCHAR(32)) RETURNS TABLE AS RETURN ( SELECT TOP (@n) name = name + '_' + RTRIM(rn) FROM ( SELECT a.name, rn = ROW_NUMBER() OVER (PARTITION BY a.name ORDER BY a.name) FROM sys.all_objects AS a CROSS JOIN sys.all_objects AS b WHERE a.name >= @minString AND b.name >= @minString ) AS x ); GO
Dit geldt voor een CROSS JOIN van sys.all_objects op zichzelf, waarbij een uniek rijnummer aan elke naam wordt toegevoegd, zodat de eerste 10 resultaten er als volgt uitzien:
Het vullen van de tabel met 100.000 rijen was eenvoudig:
INSERT dbo.[Objects](name) SELECT name FROM dbo.GenerateRows(100000, N'') ORDER BY name; GO
Omdat we nu nieuwe unieke waarden in de tabel gaan invoegen, heb ik een procedure gemaakt om aan het begin en het einde van elke test wat op te schonen - naast het verwijderen van nieuwe rijen die we hebben toegevoegd, zal het ook opschonen de cache en buffers. Niet iets dat u natuurlijk in een procedure op uw productiesysteem wilt coderen, maar prima voor lokale prestatietests.
CREATE PROCEDURE dbo.EH_Cleanup -- P.S. "EH" stands for Error Handling, not "Eh?" AS BEGIN SET NOCOUNT ON; DELETE dbo.[Objects] WHERE ObjectID > 100000; DBCC FREEPROCCACHE; DBCC DROPCLEANBUFFERS; END GO
Ik heb ook een logtabel gemaakt om de start- en eindtijden voor elke test bij te houden:
CREATE TABLE dbo.RunTimeLog ( LogID INT IDENTITY(1,1), Spid INT, InsertType VARCHAR(255), ErrorHandlingMethod VARCHAR(255), StartDate DATETIME2(7) NOT NULL DEFAULT SYSUTCDATETIME(), EndDate DATETIME2(7) ); GO
Ten slotte behandelt de opgeslagen testprocedure verschillende dingen. We hebben drie verschillende foutafhandelingsmethoden, zoals beschreven in de opsommingstekens hierboven:"JustInsert", "Rollback" en "TryCatch"; we hebben ook drie verschillende invoegtypen:(1) alle invoegingen slagen (alle rijen zijn uniek), (2) alle invoegingen mislukken (alle rijen zijn duplicaten) en (3) halve invoegingen slagen (de helft van de rijen is uniek en de helft de rijen zijn duplicaten). Hieraan gekoppeld zijn twee verschillende benaderingen:controleer op de overtreding voordat u de insert probeert, of ga gewoon door en laat de engine bepalen of deze geldig is. Ik dacht dat dit een goede vergelijking zou geven van de verschillende technieken voor foutafhandeling in combinatie met verschillende kans op botsingen om te zien of een hoog of laag percentage botsingen de resultaten significant zou beïnvloeden.
Voor deze tests heb ik 40.000 rijen gekozen als mijn totale aantal invoegpogingen, en in de procedure voer ik een samenvoeging uit van 20.000 unieke of niet-unieke rijen met 20.000 andere unieke of niet-unieke rijen. Je kunt zien dat ik de cutoff-strings in de procedure hard heb gecodeerd; houd er rekening mee dat deze onderbrekingen op uw systeem vrijwel zeker op een andere plaats zullen plaatsvinden.
CREATE PROCEDURE dbo.EH_Insert @ErrorHandlingMethod VARCHAR(255), @InsertType VARCHAR(255), @RowSplit INT = 20000 AS BEGIN SET NOCOUNT ON; -- clean up any new rows and drop buffers/clear proc cache EXEC dbo.EH_Cleanup; DECLARE @CutoffString1 NVARCHAR(255), @CutoffString2 NVARCHAR(255), @Name NVARCHAR(255), @Continue BIT = 1, @LogID INT; -- generate a new log entry INSERT dbo.RunTimeLog(Spid, InsertType, ErrorHandlingMethod) SELECT @@SPID, @InsertType, @ErrorHandlingMethod; SET @LogID = SCOPE_IDENTITY(); -- if we want everything to succeed, we need a set of data -- that has 40,000 rows that are all unique. So union two -- sets that are each >= 20,000 rows apart, and don't -- already exist in the base table: IF @InsertType = 'AllSuccess' SELECT @CutoffString1 = N'database_audit_specifications_1000', @CutoffString2 = N'dm_clr_properties_1398'; -- if we want them all to fail, then it's easy, we can just -- union two sets that start at the same place as the initial -- population: IF @InsertType = 'AllFail' SELECT @CutoffString1 = N'', @CutoffString2 = N''; -- and if we want half to succeed, we need 20,000 unique -- values, and 20,000 duplicates: IF @InsertType = 'HalfSuccess' SELECT @CutoffString1 = N'database_audit_specifications_1000', @CutoffString2 = N''; DECLARE c CURSOR LOCAL STATIC FORWARD_ONLY READ_ONLY FOR SELECT name FROM dbo.GenerateRows(@RowSplit, @CutoffString1) UNION ALL SELECT name FROM dbo.GenerateRows(@RowSplit, @CutoffString2); OPEN c; FETCH NEXT FROM c INTO @Name; WHILE @@FETCH_STATUS = 0 BEGIN SET @Continue = 1; -- let's only enter the primary code block if we -- have to check and the check comes back empty -- (in other words, don't try at all if we have -- a duplicate, but only check for a duplicate -- in certain cases: IF @ErrorHandlingMethod LIKE 'Check%' BEGIN IF EXISTS (SELECT 1 FROM dbo.[Objects] WHERE Name = @Name) SET @Continue = 0; END IF @Continue = 1 BEGIN -- just let the engine catch IF @ErrorHandlingMethod LIKE '%Insert' BEGIN INSERT dbo.[Objects](name) SELECT @name; END -- begin a transaction, but let the engine catch IF @ErrorHandlingMethod LIKE '%Rollback' BEGIN BEGIN TRANSACTION; INSERT dbo.[Objects](name) SELECT @name; IF @@ERROR <> 0 BEGIN ROLLBACK TRANSACTION; END ELSE BEGIN COMMIT TRANSACTION; END END -- use try / catch IF @ErrorHandlingMethod LIKE '%TryCatch' BEGIN BEGIN TRY BEGIN TRANSACTION; INSERT dbo.[Objects](name) SELECT @Name; COMMIT TRANSACTION; END TRY BEGIN CATCH ROLLBACK TRANSACTION; END CATCH END END FETCH NEXT FROM c INTO @Name; END CLOSE c; DEALLOCATE c; -- update the log entry UPDATE dbo.RunTimeLog SET EndDate = SYSUTCDATETIME() WHERE LogID = @LogID; -- clean up any new rows and drop buffers/clear proc cache EXEC dbo.EH_Cleanup; END GO
Nu kunnen we deze procedure met verschillende argumenten aanroepen om het verschillende gedrag te krijgen dat we zoeken, in een poging 40.000 waarden in te voegen (en natuurlijk wetend hoeveel er in elk geval zouden moeten slagen of mislukken). Voor elke 'foutafhandelingsmethode' (probeer gewoon de insert, gebruik begin tran/rollback of try/catch) en elk type insert (allemaal slagen, half slagen en geen enkele), gecombineerd met het al dan niet controleren op de overtreding ten eerste geeft dit ons 18 combinaties:
EXEC dbo.EH_Insert 'JustInsert', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustInsert', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustInsert', 'AllFail', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'AllFail', 20000; EXEC dbo.EH_Insert 'JustRollback', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustRollback', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustRollback', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'AllFail', 20000;
Nadat we dit hebben uitgevoerd (het duurt ongeveer 8 minuten op mijn systeem), hebben we enkele resultaten in ons logboek. Ik heb de hele batch vijf keer uitgevoerd om er zeker van te zijn dat we fatsoenlijke gemiddelden kregen en eventuele afwijkingen glad te strijken. Dit zijn de resultaten:
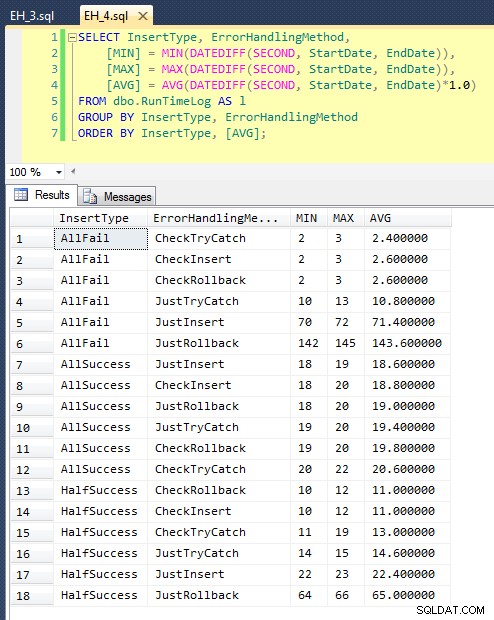
De grafiek die alle looptijden in één keer uitzet, laat een aantal serieuze uitschieters zien:
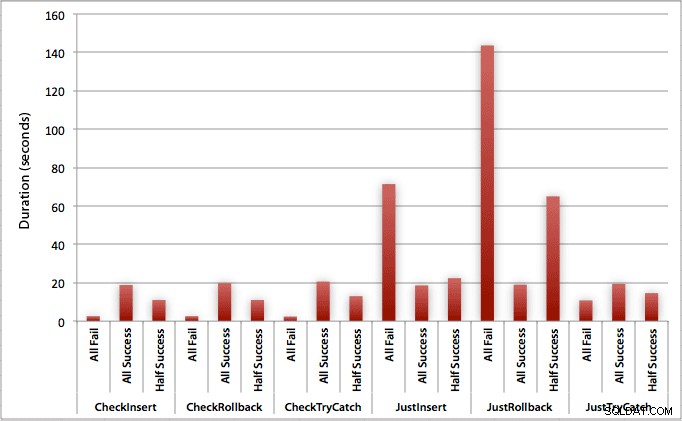
Je kunt zien dat, in gevallen waarin we een hoge mate van mislukking verwachten (in deze test 100%), het starten van een transactie en het terugdraaien van de transactie verreweg de minst aantrekkelijke benadering is (3,59 milliseconden per poging), terwijl je de motor gewoon laat stijgen een fout is ongeveer half zo erg (1,785 milliseconden per poging). De volgende slechtste presteerder was het geval waarin we een transactie beginnen en deze vervolgens terugdraaien, in een scenario waarin we verwachten dat ongeveer de helft van de pogingen zal mislukken (gemiddeld 1,625 milliseconden per poging). De 9 gevallen aan de linkerkant van de grafiek, waar we eerst de overtreding controleren, kwamen niet hoger dan 0,515 milliseconden per poging.
Dat gezegd hebbende, laten de afzonderlijke grafieken voor elk scenario (hoog % succes, hoog % mislukking en 50-50) echt de impact van elke methode zien.
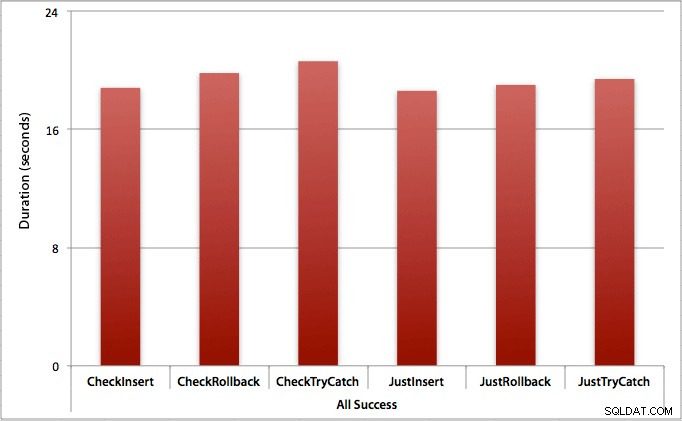
Waar alle invoegingen slagen
In dit geval zien we dat de overhead van het eerst controleren op de overtreding verwaarloosbaar is, met een gemiddeld verschil van 0,7 seconden over de batch (of 125 microseconden per invoegpoging):
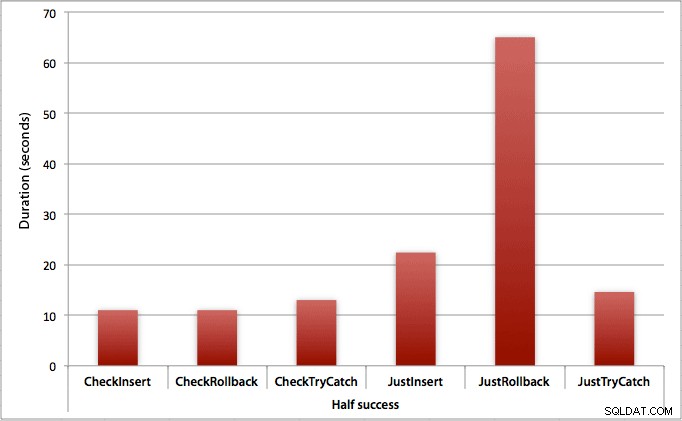
Waar slechts de helft van de inserts slaagt
Wanneer de helft van de inserts faalt, zien we een grote sprong in de duur voor de insert / rollback-methoden. Het scenario waarin we een transactie starten en terugdraaien is ongeveer 6x langzamer over de batch in vergelijking met eerst controleren (1,625 milliseconden per poging versus 0,275 milliseconden per poging). Zelfs de TRY/CATCH-methode is 11% sneller als we eerst controleren:
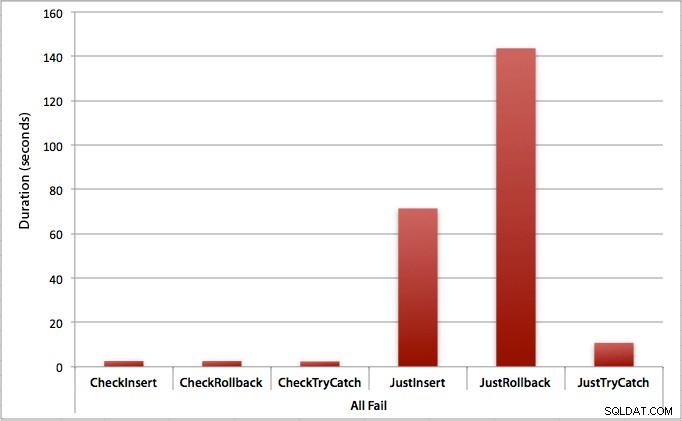
Waar alle inserts falen
Zoals je zou verwachten, toont dit de meest uitgesproken impact van foutafhandeling en de meest voor de hand liggende voordelen van eerst controleren. De rollback-methode is in dit geval bijna 70x langzamer wanneer we niet controleren in vergelijking met wanneer we dat wel doen (3,59 milliseconden per poging versus 0,065 milliseconden per poging):
Wat zegt dit ons? Als we denken dat we een hoog faalpercentage zullen hebben, of geen idee hebben wat ons potentiële faalpercentage zal zijn, dan is het enorm de moeite waard om eerst te controleren om overtredingen in de motor te voorkomen. Zelfs in het geval dat we elke keer een succesvolle invoeging hebben, zijn de kosten om eerst te controleren marginaal en gemakkelijk te rechtvaardigen door de mogelijke kosten van het later afhandelen van fouten (tenzij uw verwachte uitvalpercentage precies 0%) is.
Dus voorlopig denk ik dat ik bij mijn theorie blijf dat het in eenvoudige gevallen zinvol is om te controleren op een mogelijke overtreding voordat ik SQL Server vertel om door te gaan en toch in te voegen. In een toekomstig bericht zal ik kijken naar de prestatie-impact van verschillende isolatieniveaus, gelijktijdigheid en misschien zelfs een paar andere foutafhandelingstechnieken.
[Terzijde:ik schreef in februari een verkorte versie van dit bericht als tip voor mssqltips.com.]