Van tijd tot tijd zie ik iemand een vereiste uitspreken om een willekeurig nummer voor een sleutel te maken. Meestal is dit om een soort surrogaat-Klant-ID of Gebruikers-ID aan te maken dat een uniek nummer is binnen een bepaald bereik, maar niet opeenvolgend wordt uitgegeven en daarom veel minder te raden is dan een IDENTITY waarde.
NEWID() lost het gokprobleem op, maar de prestatievermindering is meestal een dealbreaker, vooral wanneer ze worden geclusterd:veel bredere sleutels dan gehele getallen en paginasplitsingen vanwege niet-sequentiële waarden. NEWSEQUENTIALID() lost het probleem met het opsplitsen van pagina's op, maar is nog steeds een zeer brede sleutel, en introduceert opnieuw het probleem dat u de volgende waarde (of recentelijk uitgegeven waarden) met enige nauwkeurigheid kunt raden.
Als resultaat willen ze een techniek om een willekeurige en uniek geheel getal. Op zichzelf een willekeurig getal genereren is niet moeilijk, met behulp van methoden zoals RAND() of CHECKSUM(NEWID()) . Het probleem ontstaat wanneer u botsingen moet detecteren. Laten we eens kijken naar een typische benadering, ervan uitgaande dat we CustomerID-waarden tussen 1 en 1.000.000 willen:
DECLARE @rc INT =0, @CustomerID INT =ABS(CHECKSUM(NEWID())) % 1000000 + 1; -- of ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1; -- of CONVERT (INT, RAND() * 1000000) + 1; WHILE @rc =0BEGIN INDIEN NIET BESTAAT (SELECTEER 1 VAN dbo.Customers WHERE CustomerID =@CustomerID) BEGIN INSERT dbo.Customers(CustomerID) SELECT @CustomerID; SET @rc =1; EINDE ANDERS BEGIN SELECTEREN @Klant-ID =ABS(CHECKSUM(NEWID())) % 1000000 + 1, @rc =0; EINDE
Naarmate de tabel groter wordt, wordt niet alleen het controleren op duplicaten duurder, maar neemt ook uw kans op het genereren van een duplicaat toe. Dus deze aanpak lijkt misschien goed te werken als de tafel klein is, maar ik vermoed dat het in de loop van de tijd steeds meer pijn zal doen.
Een andere aanpak
Ik ben een grote fan van hulptabellen; Ik schrijf al tien jaar in het openbaar over kalendertabellen en tabellen met getallen en gebruik ze al veel langer. En dit is een geval waarin ik denk dat een vooraf ingevulde tabel erg handig kan zijn. Waarom vertrouwen op het genereren van willekeurige getallen tijdens runtime en omgaan met potentiële duplicaten, als u al die waarden van tevoren kunt invullen en weet - met 100% zekerheid, als u uw tabellen beschermt tegen ongeautoriseerde DML - dat de volgende waarde die u selecteert nooit is geweest eerder gebruikt?
TABEL MAKEN dbo.RandomNumbers1( RowID INT, Value INT, --UNIQUE, PRIMARY KEY (RowID, Value));;MET x AS ( SELECT TOP (1000000) s1.[object_id] FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 ORDER BY s1.[object_id])INSERT dbo.RandomNumbers(RijID, Waarde)SELECT r =ROW_NUMBER ) OVER (ORDER BY [object_id]), n =ROW_NUMBER() OVER (ORDER BY NEWID())VAN xORDER BY r;
Deze populatie duurde 9 seconden om te maken (in een VM op een laptop) en nam ongeveer 17 MB op schijf in beslag. De gegevens in de tabel zien er als volgt uit:
(Als we ons zorgen zouden maken over de manier waarop de getallen worden ingevuld, zouden we een unieke beperking aan de kolom Waarde kunnen toevoegen, waardoor de tabel 30 MB zou worden. Als we paginacompressie hadden toegepast, zou het respectievelijk 11 MB of 25 MB zijn geweest. )
Ik heb nog een kopie van de tabel gemaakt en deze gevuld met dezelfde waarden, zodat ik twee verschillende methoden kon testen om de volgende waarde af te leiden:
TABEL MAKEN dbo.RandomNumbers2( RowID INT, Value INT, -- UNIEKE PRIMAIRE SLEUTEL (RowID, Value)); INSERT dbo.RandomNumbers2(RowID, Value) SELECT RowID, Value FROM dbo.RandomNumbers1;
Nu, wanneer we een nieuw willekeurig nummer willen, kunnen we er gewoon een van de stapel bestaande nummers halen en verwijderen. Dit voorkomt dat we ons zorgen hoeven te maken over duplicaten en stelt ons in staat om nummers te trekken - met behulp van een geclusterde index - die eigenlijk al in willekeurige volgorde staan. (Strikt genomen hoeven we niet te verwijderen de cijfers zoals we ze gebruiken; we zouden een kolom kunnen toevoegen om aan te geven of een waarde is gebruikt - dit zou het gemakkelijker maken om die waarde te herstellen en opnieuw te gebruiken in het geval dat een klant later wordt verwijderd of er iets misgaat buiten deze transactie, maar voordat ze volledig zijn gemaakt.)
VERKLAREN @holding TABLE(CustomerID INT); DELETE TOP (1) dbo.RandomNumbers1OUTPUT verwijderd.Value INTO @holding; INSERT dbo.Customers(CustomerID, ...other columns...) SELECT CustomerID, ...other params... FROM @holding;
Ik heb een tabelvariabele gebruikt om de tussentijdse uitvoer vast te houden, omdat er verschillende beperkingen zijn met configureerbare DML die het onmogelijk kunnen maken om rechtstreeks vanuit de DELETE in de tabel Klanten in te voegen (bijvoorbeeld de aanwezigheid van externe sleutels). Maar ik erken dat het niet altijd mogelijk zal zijn, maar ik wilde ook deze methode testen:
BOVENSTE VERWIJDEREN (1) dbo.RandomNumbers2 OUTPUT verwijderd.Waarde, ...andere parameters... INTO dbo.Klanten(Klant-ID, ...andere kolommen...);
Merk op dat geen van deze oplossingen echt een willekeurige volgorde garandeert, vooral als de tabel met willekeurige getallen andere indexen heeft (zoals een unieke index in de kolom Waarde). Er is geen manier om een bestelling te definiëren voor een DELETE met behulp van TOP; uit de documentatie:
Dus als u willekeurige volgorde wilt garanderen, kunt u in plaats daarvan iets als dit doen:
VERKLAREN @holding TABLE(CustomerID INT);;MET x AS (SELECTEER TOP (1) Waarde UIT dbo.RandomNumbers2 ORDER BY RowID)DELETE x OUTPUT verwijderd.Value INTO @holding; INSERT dbo.Customers(CustomerID, ...other columns...) SELECT CustomerID, ...other params... FROM @holding;
Een andere overweging hierbij is dat voor deze tests de tabellen Klanten een geclusterde primaire sleutel hebben in de kolom Klant-ID; dit zal zeker leiden tot paginasplitsingen als u willekeurige waarden invoegt. In de echte wereld, als je deze vereiste had, zou je waarschijnlijk eindigen in een andere kolom.
Merk op dat ik hier ook transacties en foutafhandeling heb weggelaten, maar deze zouden ook een overweging moeten zijn voor productiecode.
Prestatietesten
Om realistische prestatievergelijkingen te maken, heb ik vijf opgeslagen procedures gemaakt, die de volgende scenario's vertegenwoordigen (testsnelheid, distributie en botsingsfrequentie van de verschillende willekeurige methoden, evenals de snelheid van het gebruik van een vooraf gedefinieerde tabel met willekeurige getallen):
- Runtime-generatie met
CHECKSUM(NEWID()) - Runtime-generatie met
CRYPT_GEN_RANDOM() - Runtime-generatie met
RAND() - Vooraf gedefinieerde getallentabel met tabelvariabele
- Vooraf gedefinieerde getallentabel met directe invoeging
Ze gebruiken een logtabel om de duur en het aantal botsingen bij te houden:
MAAK TABEL dbo.CustomerLog( LogID INT IDENTITY(1,1) PRIMAIRE SLEUTEL, pid INT, botsingen INT, duur INT -- microseconden);
De code voor de procedures volgt (klik om te tonen/verbergen):
/* Runtime met CHECKSUM(NEWID()) */ PROCEDURE MAKEN [dbo].[AddCustomer_Runtime_Checksum]ASBEGIN STEL NOCOUNT IN; DECLARE @start DATETIME2(7) =SYSDATETIME(), @duration INT, @CustomerID INT =ABS(CHECKSUM(NEWID())) % 1000000 + 1, @collisions INT =0, @rc INT =0; WHILE @rc =0 BEGIN INDIEN NIET BESTAAT (SELECTEER 1 VANUIT dbo.Customers_Runtime_Checksum WHERE CustomerID =@CustomerID ) BEGIN INSERT dbo.Customers_Runtime_Checksum(CustomerID) SELECT @CustomerID; SET @rc =1; EINDE ANDERS BEGIN SELECTEREN @CustomerID =ABS(CHECKSUM(NEWID())) % 1000000 + 1, @collisions +=1, @rc =0; END END SELECT @duration =DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 1, @collisions, @duration;ENDGO /* runtime met CRYPT_GEN_RANDOM() */ CREATE PROCEDURE [dbo].[AddCustomer_Runtime_CryptGen]ASBEGIN STEL NOCOUNT IN; DECLARE @start DATETIME2(7) =SYSDATETIME(), @duration INT, @CustomerID INT =ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1, @collisions INT =0, @rc INT =0; WHILE @rc =0 BEGIN INDIEN NIET BESTAAT (SELECTEER 1 VANUIT dbo.Customers_Runtime_CryptGen WHERE CustomerID =@CustomerID ) BEGIN dbo.Customers_Runtime_CryptGen(CustomerID) SELECTEER @CustomerID; SET @rc =1; EINDE ANDERS BEGIN SELECTEREN @CustomerID =ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1, @collisions +=1, @rc =0; END END SELECT @duration =DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 2, @collisions, @duration;ENDGO /* runtime met RAND() */ CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Rand]ASBEGIN STEL NOCOUNT IN; DECLARE @start DATETIME2(7) =SYSDATETIME(), @duration INT, @CustomerID INT =CONVERT(INT, RAND() * 1000000) + 1, @collisions INT =0, @rc INT =0; TERWIJL @rc =0 BEGIN INDIEN NIET BESTAAT (SELECTEER 1 VANUIT dbo.Customers_Runtime_Rand WHERE CustomerID =@CustomerID ) BEGIN INSERT dbo.Customers_Runtime_Rand(CustomerID) SELECT @CustomerID; SET @rc =1; EINDE ANDERS BEGIN SELECTEREN @CustomerID =CONVERT(INT, RAND() * 1000000) + 1, @collisions +=1, @rc =0; END END SELECT @duration =DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 3, @collisions, @duration;ENDGO /* vooraf gedefinieerd met een tabelvariabele */ CREATE PROCEDURE [dbo].[AddCustomer_Predefined_TableVariable]ASBEGIN STEL NOCOUNT IN; DECLARE @start DATETIME2(7) =SYSDATETIME(), @duration INT; VERKLAREN @holding TABLE(Klant-ID INT); DELETE TOP (1) dbo.RandomNumbers1 OUTPUT verwijderd.Waarde INTO @holding; INSERT dbo.Customers_Predefined_TableVariable(CustomerID) SELECT CustomerID FROM @holding; SELECT @duration =DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, duration) SELECT 4, @duration;ENDGO /* vooraf gedefinieerd met een directe invoeging */ PROCEDURE MAKEN [dbo].[AddCustomer_Predefined_Direct]ASBEGIN STEL NOCOUNT IN; DECLARE @start DATETIME2(7) =SYSDATETIME(), @duration INT; VERWIJDER BOVEN (1) dbo.RandomNumbers2 OUTPUT verwijderd.Waarde IN dbo.Customers_Predefined_Direct; SELECT @duration =DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, duration) SELECT 5, @duration;ENDGO
En om dit te testen, zou ik elke opgeslagen procedure 1.000.000 keer uitvoeren:
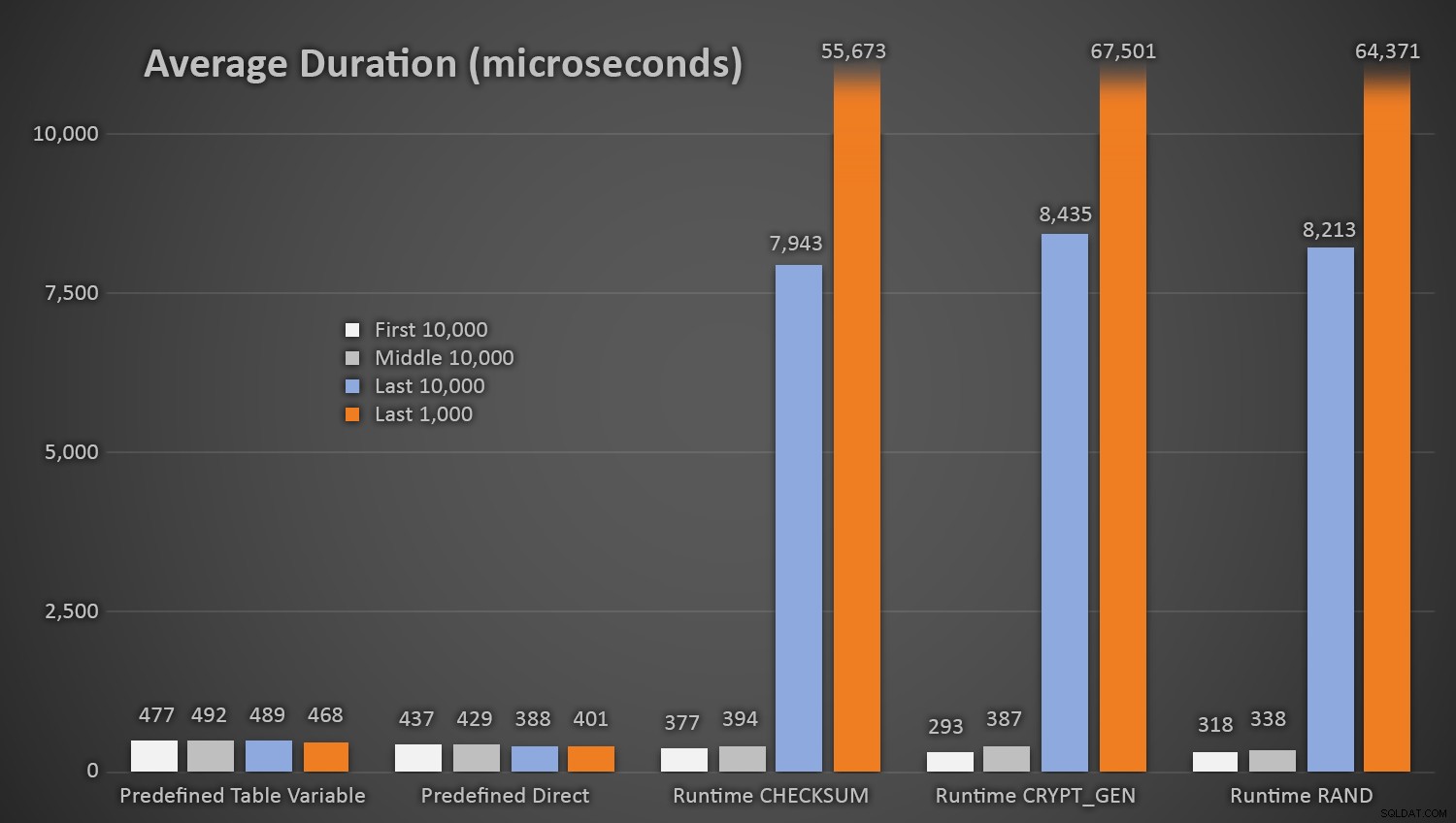
EXEC dbo.AddCustomer_Runtime_Checksum;EXEC dbo.AddCustomer_Runtime_CryptGen;EXEC dbo.AddCustomer_Runtime_Rand;EXEC dbo.AddCustomer_Predefined_TableVariable;EXEC dbo.AddCustomer_Pre000000_Direct>GO 1Het is niet verrassend dat de methoden die de vooraf gedefinieerde tabel met willekeurige getallen gebruikten iets langer duurde *aan het begin van de test*, omdat ze elke keer zowel lees- als schrijf-I/O moesten uitvoeren. Houd er rekening mee dat deze getallen in microseconden zijn , hier zijn de gemiddelde duur voor elke procedure, met verschillende tussenpozen onderweg (gemiddeld over de eerste 10.000 executies, de middelste 10.000 executies, de laatste 10.000 executies en de laatste 1.000 executies):
Gemiddelde duur (in microseconden) van willekeurige generatie met verschillende benaderingenDit werkt goed voor alle methoden wanneer er weinig rijen in de tabel Klanten zijn, maar naarmate de tabel groter en groter wordt, nemen de kosten van het controleren van het nieuwe willekeurige getal met de bestaande gegevens met behulp van de runtime-methoden aanzienlijk toe, zowel vanwege de toegenomen I /O en ook omdat het aantal botsingen omhoog gaat (waardoor je het opnieuw moet proberen). Vergelijk de gemiddelde duur binnen de volgende reeksen van botsingen (en onthoud dat dit patroon alleen van invloed is op de runtime-methoden):
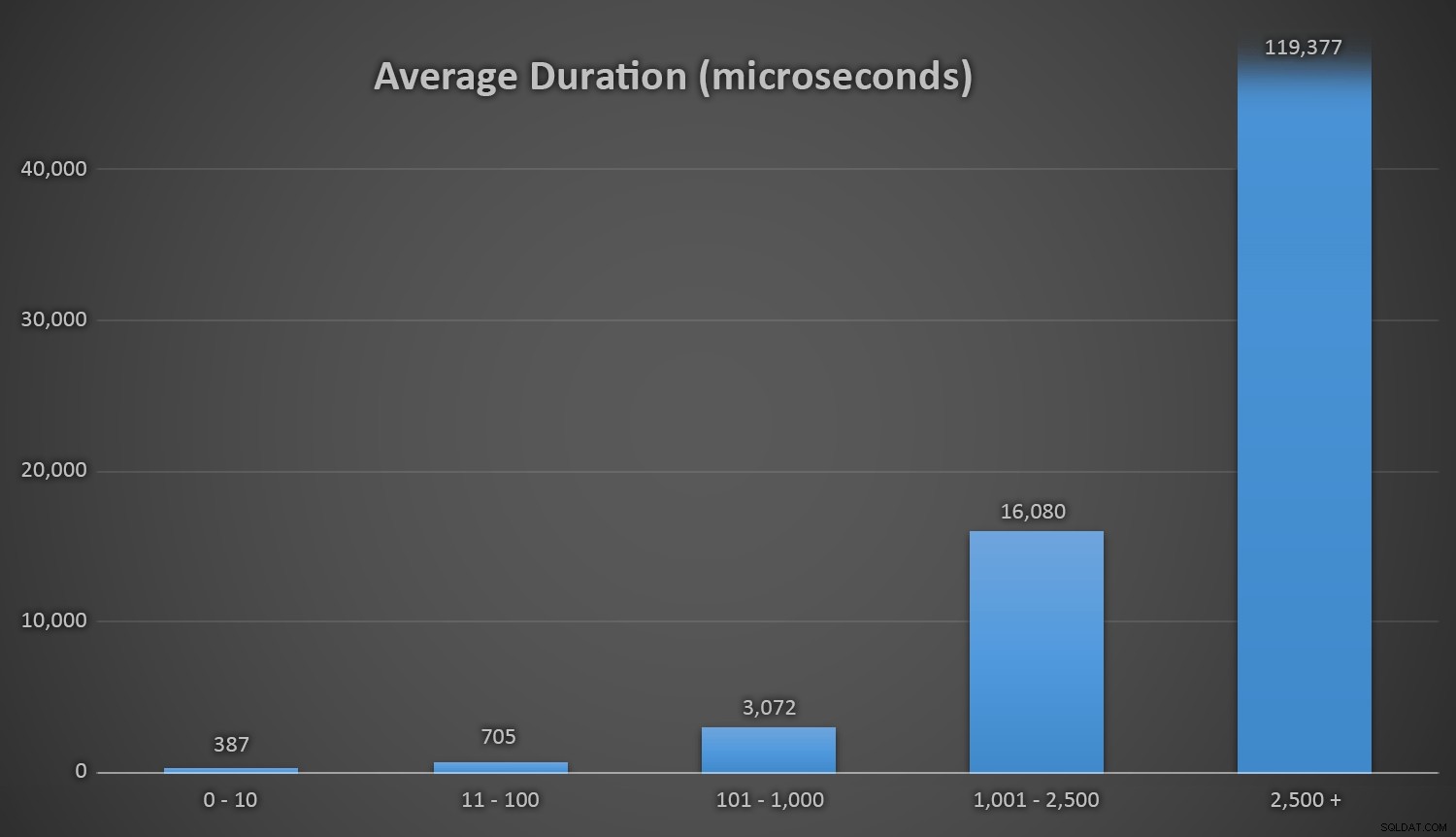
Gemiddelde duur (in microseconden) tijdens verschillende reeksen van botsingenIk wou dat er een eenvoudige manier was om de duur te vergelijken met het aantal botsingen. Ik laat je met deze lekkernij:bij de laatste drie invoegingen moesten de volgende runtime-methoden zoveel pogingen uitvoeren voordat ze uiteindelijk de laatste unieke ID tegenkwamen waarnaar ze op zoek waren, en dit is hoe lang het duurde:
| Aantal botsingen | Duur (microseconden) | ||
|---|---|---|---|
| CHECKSUM(NEWID()) | 3e tot laatste rij | 63.545 | 639.358 |
| 2e tot laatste rij | 164.807 | 1.605.695 | |
| Laatste rij | 30.630 | 296.207 | |
| CRYPT_GEN_RANDOM() | 3e tot laatste rij | 219.766 | 2.229.166 |
| 2e tot laatste rij | 255.463 | 2.681.468 | |
| Laatste rij | 136.342 | 1.434.725 | |
| RAND() | 3e tot laatste rij | 129.764 | 1.2155.994 |
| 2e tot laatste rij | 220.195 | 2.088.992 | |
| Laatste rij | 440.765 | 4.161.925 | |
Overmatige duur en botsingen aan het einde van de regel
Het is interessant om op te merken dat de laatste rij niet altijd de rij is die het hoogste aantal botsingen oplevert, dus dit kan een echt probleem worden lang voordat je meer dan 999.000 waarden hebt opgebruikt.
Een andere overweging
U kunt overwegen een soort waarschuwing of melding in te stellen wanneer de tabel RandomNumbers onder een bepaald aantal rijen begint te komen (op dat moment kunt u de tabel opnieuw vullen met een nieuwe set van bijvoorbeeld 1.000.001 - 2.000.000). Je zou iets soortgelijks moeten doen als je willekeurige getallen on-the-fly zou genereren - als je dat binnen een bereik van 1 - 1.000.000 houdt, dan zou je de code moeten veranderen om getallen uit een ander bereik te genereren zodra je' heb al die waarden opgebruikt.
Als je de random number at runtime-methode gebruikt, kun je deze situatie vermijden door constant de poolgrootte te veranderen waaruit je een willekeurig getal trekt (wat ook zou moeten stabiliseren en het aantal botsingen drastisch zou moeten verminderen). Bijvoorbeeld in plaats van:
DECLARE @CustomerID INT =ABS(CHECKSUM(NEWID())) % 1000000 + 1;
U kunt de pool baseren op het aantal rijen dat al in de tabel staat:
DECLARE @total INT =1000000 + ISNULL( (SELECT SUM(row_count) FROM sys.dm_db_partition_stats WHERE [object_id] =OBJECT_ID('dbo.Customers') AND index_id =1),0);
Nu is uw enige echte zorg wanneer u de bovengrens nadert voor INT …
Opmerking:ik heb hier onlangs ook een tip over geschreven op MSSQLTips.com.