Enkele predikaten
Het schatten van het aantal rijen dat wordt gekwalificeerd door een enkel querypredikaat is vaak eenvoudig. Wanneer een predikaat een eenvoudige vergelijking maakt tussen een kolom en een scalaire waarde, is de kans groot dat de kardinaliteitsschatter zal een schatting van goede kwaliteit kunnen afleiden uit het statistische histogram. De volgende AdventureWorks-query produceert bijvoorbeeld een exact correcte schatting van 203 rijen (ervan uitgaande dat er geen wijzigingen in de gegevens zijn aangebracht sinds de statistieken zijn gemaakt):
SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.TransactionDate = '20070903';
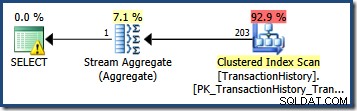
Kijken naar het statistiekenhistogram voor de TransactionDate kolom, is het duidelijk te zien waar deze schatting vandaan komt:
DBCC SHOW_STATISTICS (
'Production.TransactionHistory',
'TransactionDate')
WITH HISTOGRAM;
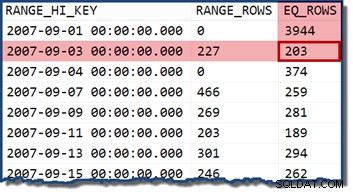
Als we de query wijzigen om een datum op te geven die binnen een histogram-bucket valt, gaat de kardinaliteitsschatter ervan uit dat de waarden gelijkmatig zijn verdeeld. Een datum gebruiken van 2007-09-02 produceert een schatting van 227 rijen (van de RANGE_ROWS binnenkomst). Een interessante kanttekening is dat de schatting op 227 rijen blijft, ongeacht het tijdsgedeelte dat we aan de datumwaarde toevoegen (de TransactionDate kolom is een datetime gegevenstype).
Als we de zoekopdracht opnieuw proberen met een datum van 2007-09-05 of 2007-09-06 (die beide vallen tussen de 2007-09-04 en 2007-09-07 histogramstappen), gaat de kardinaliteitsschatter uit van de 466 RANGE_ROWS zijn gelijk verdeeld over de twee waarden, waarbij in beide gevallen 233 rijen worden geschat.
Er zijn veel andere details in de kardinaliteitsschatting voor eenvoudige predikaten, maar het voorgaande is een opfriscursus voor onze huidige doeleinden.
De problemen van meerdere predikaten
Wanneer een query meer dan één kolompredikaat bevat, wordt het schatten van de kardinaliteit moeilijker. Beschouw de volgende vraag met twee eenvoudige predikaten (die elk gemakkelijk op zichzelf kunnen worden geschat):
SELECT
COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
AND TH.TransactionDate BETWEEN '20070901' AND '20080313'; De specifieke waardenbereiken in de query zijn bewust gekozen zodat beide predikaten exact dezelfde rijen identificeren. We zouden de querywaarden gemakkelijk kunnen wijzigen om te resulteren in elke mate van overlap, inclusief helemaal geen overlap. Stel je nu voor dat je de kardinaliteitsschatter bent:hoe zou je een kardinaliteitsschatting afleiden voor deze zoekopdracht?
Het probleem is moeilijker dan het op het eerste gezicht lijkt. Standaard maakt SQL Server automatisch statistieken met één kolom voor beide predikaatkolommen. We kunnen ook handmatig statistieken met meerdere kolommen maken. Geeft dit ons voldoende informatie om een goede schatting te maken voor deze specifieke waarden? Hoe zit het met het meer algemene geval waarin er een . kan zijn? mate van overlap?
Met behulp van de twee statistische objecten met één kolom kunnen we gemakkelijk een schatting voor elk predikaat afleiden met behulp van de histogrammethode die in de vorige sectie is beschreven. Voor de specifieke waarden in de bovenstaande query laten de histogrammen zien dat de TransactionID bereik zal naar verwachting overeenkomen met 68412.4 rijen, en de TransactionDate bereik zal naar verwachting overeenkomen met 68.413 rijen. (Als de histogrammen perfect waren, zouden deze twee getallen precies hetzelfde zijn.)
Wat de histogrammen niet kunnen vertel ons hoeveel van deze twee sets rijen dezelfde rijen zullen zijn . Alles wat we kunnen zeggen op basis van de histograminformatie is dat onze schatting ergens tussen nul (voor helemaal geen overlap) en 68412,4 rijen (volledige overlap) moet liggen.
Het maken van statistieken met meerdere kolommen biedt geen hulp voor deze zoekopdracht (of voor bereikquery's in het algemeen). Statistieken met meerdere kolommen maken nog steeds alleen een histogram over de eerstgenoemde kolom, in wezen dupliceren van het histogram dat is gekoppeld aan een van de automatisch gemaakte statistieken. De extra dichtheid informatie die door de statistiek met meerdere kolommen wordt geleverd, kan nuttig zijn om informatie over gemiddelde gevallen te geven voor zoekopdrachten die meerdere gelijkheidspredikaten bevatten, maar ze helpen ons hier niet.
Om een schatting te maken met een hoge mate van betrouwbaarheid, hebben we SQL Server nodig om betere informatie te geven over de datadistributie – zoiets als een multi-dimensionaal statistiek histogram. Voor zover ik weet, biedt geen enkele commerciële database-engine momenteel een dergelijke faciliteit, hoewel er verschillende technische artikelen over dit onderwerp zijn gepubliceerd (waaronder een Microsoft Research-engine die een interne ontwikkeling van SQL Server 2000 gebruikte).
Zonder iets te weten over gegevenscorrelaties en overlappingen voor bepaalde waardebereiken, is het niet duidelijk hoe we verder moeten gaan om een goede schatting voor onze zoekopdracht te maken. Dus, wat doet SQL Server hier?
SQL Server 7 – 2012
De kardinaliteitsschatter in deze versies van SQL Server gaat er doorgaans van uit dat waarden van verschillende attributen in een tabel volledig onafhankelijk van elkaar worden gedistribueerd. Deze onafhankelijkheidsveronderstelling is zelden een nauwkeurige weergave van de echte gegevens, maar het heeft wel het voordeel dat het eenvoudigere berekeningen mogelijk maakt.
EN Selectiviteit
Met behulp van de aanname van onafhankelijkheid, twee predikaten verbonden door AND (bekend als een conjunctie ) met selectiviteiten S1 en S2 , resulteren in een gecombineerde selectiviteit van:
(S1 * S2)
Als de term u niet bekend is, selectiviteit is een getal tussen 0 en 1, dat de fractie rijen in de tabel vertegenwoordigt die het predikaat passeren. Als een predikaat bijvoorbeeld 12 rijen selecteert uit een tabel van 100 rijen, is de selectiviteit (12/100) =0,12.
In ons voorbeeld is de TransactionHistory tabel bevat in totaal 113.443 rijen. Het predikaat op TransactionID wordt geschat (uit het histogram) om 68.412,4 rijen te kwalificeren, dus de selectiviteit is (68.412,4 / 113.443) of ongeveer 0,603055 . Het predikaat op TransactionDate heeft naar schatting een selectiviteit van (68.413 / 113.443) =ongeveer 0,603061 .
Vermenigvuldiging van de twee selectiviteiten (met behulp van de bovenstaande formule) geeft een gecombineerde schatting van de selectiviteit van 0,363679 . Vermenigvuldiging van deze selectiviteit met de kardinaliteit van de tabel (113.443) geeft de uiteindelijke schatting van 41.256.8 rijen:
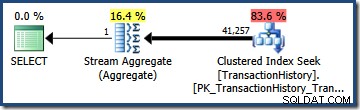
OF Selectiviteit
Twee predikaten verbonden door OR (een disjunctie ) met selectiviteiten S1 en S2 , resulteert in een gecombineerde selectiviteit van:
(S1 + S2) – (S1 * S2)
De intuïtie achter de formule is om de twee selectiviteiten op te tellen en vervolgens de schatting voor hun conjunctie af te trekken (met behulp van de vorige formule). Het is duidelijk dat we twee predikaten kunnen hebben, elk met een selectiviteit van 0,8, maar ze simpelweg bij elkaar optellen zou een onmogelijke gecombineerde selectiviteit van 1,6 opleveren. Ondanks de aanname van onafhankelijkheid, moeten we erkennen dat de twee predikaten een overlap kunnen hebben, dus om dubbeltellingen te voorkomen, wordt de geschatte selectiviteit van de conjunctie afgetrokken.
We kunnen ons lopende voorbeeld eenvoudig aanpassen om OR . te gebruiken :
SELECT COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
OR TH.TransactionDate BETWEEN '20070901' AND '20080313';
De predikaatselectiviteiten vervangen door de OR formule geeft een gecombineerde selectiviteit van:
(0.603055 + 0.603061) - (0.603055 * 0.603061) = 0.842437
Vermenigvuldigd met het aantal rijen in de tabel, geeft deze selectiviteit ons de uiteindelijke kardinaliteitsschatting van 95.568.6 :
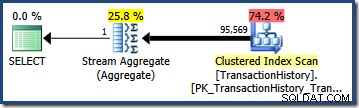
Geen van beide schattingen (41.257 voor de AND vraag; 95.569 voor de OR query) is bijzonder goed omdat beide gebaseerd zijn op een modelleringsaanname die niet goed overeenkomt met de gegevensdistributie. Beide zoekopdrachten retourneren feitelijk 68,413 rijen (omdat de predikaten exact dezelfde rijen identificeren).
Trace Flag 4137 – Minimale selectiviteit
Voor SQL Server 2008 (R1) tot en met 2012 heeft Microsoft een fix uitgebracht die de manier verandert waarop selectiviteit wordt berekend voor de AND alleen naamval (conjunctieve predikaten). Het Knowledge Base-artikel in die link bevat niet veel details, maar het blijkt dat de fix de gebruikte selectiviteitsformule verandert. In plaats van de individuele selectiviteiten te vermenigvuldigen, gebruikt de kardinaliteitsschatting voor conjunctieve predikaten nu alleen de laagste selectiviteit.
Om het gewijzigde gedrag te activeren, is de ondersteunde traceervlag 4137 vereist. Een apart Knowledge Base-artikel documenteert dat deze traceringsvlag ook wordt ondersteund voor gebruik per query via de QUERYTRACEON hint:
SELECT COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
AND TH.TransactionDate BETWEEN '20070901' AND '20080313'
OPTION (QUERYTRACEON 4137); Als deze vlag actief is, gebruikt de kardinaliteitsschatting de minimale selectiviteit van de twee predikaten, wat resulteert in een schatting van 68.412.4 rijen:
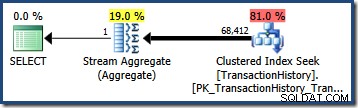
Dit is toevallig zo goed als perfect voor onze zoekopdracht omdat onze testpredikaten exact gecorreleerd zijn (en de schattingen die zijn afgeleid van de basishistogrammen zijn ook erg goed).
Het is redelijk zeldzaam dat predikaten op deze manier perfect gecorreleerd zijn met echte gegevens, maar de traceringsvlag kan in sommige gevallen niettemin helpen. Merk op dat het minimale selectiviteitsgedrag van toepassing is op alle conjunctieve (AND ) predikaten in de query; er is geen manier om het gedrag op een gedetailleerder niveau te specificeren.
Er is geen corresponderende traceringsvlag om disjunctief te schatten (OR ) predikaten met minimale selectiviteit.
SQL Server 2014
Selectiviteitsberekening in SQL Server 2014 gedraagt zich hetzelfde als eerdere versies (en traceringsvlag 4137 werkt als voorheen) als het compatibiliteitsniveau van de database lager is dan 120, of als traceringsvlag 9481 is actief. Het instellen van het databasecompatibiliteitsniveau is de officiële manier om de kardinaliteitsschatter van vóór 2014 te gebruiken in SQL Server 2014. Traceervlag 9481 is effectief om hetzelfde te doen als op het moment van schrijven, en werkt ook met QUERYTRACEON , hoewel het niet is gedocumenteerd om dit te doen. Er is geen manier om te weten wat het RTM-gedrag van deze vlag zal zijn.
Als de nieuwe kardinaliteitsschatter actief is, gebruikt SQL Server 2014 een andere standaardformule voor het combineren van conjunctieve en disjunctieve predikaten. Hoewel niet gedocumenteerd, is de selectiviteitsformule voor voegwoorden nu verschillende keren ontdekt en gedocumenteerd. De eerste die ik me herinner, staat in deze Portugese blogpost en het vervolgdeel twee verscheen een paar weken later. Samenvattend, de 2014-benadering van conjunctieve predikaten is het gebruik van exponentiële uitstel: gegeven een tabel met kardinaliteit C, en predikaat selectiviteiten S1 , S2 , S3 … Sn , waarbij S1 is de meest selectieve en Sn de minste:
Estimate = C * S1 * SQRT(S2) * SQRT(SQRT(S3)) * SQRT(SQRT(SQRT(S4))) …
De schatting wordt berekend met het meest selectieve predikaat vermenigvuldigd met de tabelkardinaliteit, vermenigvuldigd met de vierkantswortel van het volgende meest selectieve predikaat, enzovoort, waarbij elke nieuwe selectiviteit een extra vierkantswortel krijgt.
Eraan herinnerend dat selectiviteit een getal tussen 0 en 1 is, is het duidelijk dat het toepassen van een vierkantswortel het getal dichter bij 1 brengt. Het effect is dat alle predikaten in de uiteindelijke schatting worden meegenomen, maar dat de impact van de minder selectieve predikaten wordt verminderd exponentieel. Er zit aantoonbaar meer logica in dit idee dan onder de onafhankelijkheidsaanname , maar het is nog steeds een vaste formule - het verandert niet op basis van de werkelijke mate van gegevenscorrelatie.
De kardinaliteitsschatter voor 2014 gebruikt een exponentiële uitstelformule voor beide conjunctieve en disjunctieve predikaten, hoewel de formule die wordt gebruikt in de disjunctieve (OR ) zaak is nog niet gedocumenteerd (officieel of anderszins).
SQL Server 2014 Selectiviteit Trace-vlaggen
Traceringsvlag 4137 (om minimale selectiviteit te gebruiken) doet niet werken in SQL Server 2014, als de nieuwe kardinaliteitsschatter wordt gebruikt bij het compileren van een query. In plaats daarvan is er een nieuwe traceringsvlag 9471 . Wanneer deze vlag actief is, wordt minimale selectiviteit gebruikt om meerdere conjunctieve en disjunctieve . te schatten predikaten. Dit is een verandering ten opzichte van het 4137-gedrag, dat alleen conjunctieve predikaten trof.
Op dezelfde manier traceervlag 9472 kan worden gespecificeerd om onafhankelijkheid aan te nemen voor meerdere predikaten, zoals eerdere versies deden. Deze vlag verschilt van 9481 (om de kardinaliteitsschatter van vóór 2014 te gebruiken) omdat onder 9472 de nieuwe kardinaliteitsschatter nog steeds wordt gebruikt, alleen de selectiviteitsformule voor meerdere predikaten wordt beïnvloed.
Noch 9471, noch 9472 is gedocumenteerd op het moment van schrijven (hoewel ze mogelijk bij RTM zijn).
Een handige manier om te zien welke selectiviteitsaanname wordt gebruikt in SQL Server 2014 (met de nieuwe kardinaliteitsschatter actief) is om de debug-uitvoer van selectiviteitsberekeningen te onderzoeken die wordt geproduceerd wanneer traceringsvlaggen 2363 en 3604 zijn actief. Het gedeelte waarnaar moet worden gezocht, heeft betrekking op de selectiviteitscalculator die filters combineert, waar u een van de volgende ziet, afhankelijk van de veronderstelling die wordt gebruikt:
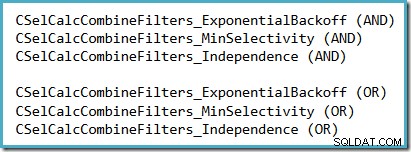
Er is geen realistisch vooruitzicht dat 2363 zal worden gedocumenteerd of ondersteund.
Laatste gedachten
Er is niets magisch aan exponentiële uitstel, minimale selectiviteit of onafhankelijkheid. Elke benadering vertegenwoordigt een (enorm) vereenvoudigende veronderstelling die al dan niet acceptabele schattingen oplevert voor een bepaalde zoekopdracht of gegevensdistributie.
In sommige opzichten, exponentiële uitstel vertegenwoordigt een compromis tussen de twee uitersten van onafhankelijkheid en minimale selectiviteit . Toch is het belangrijk er geen onredelijke verwachtingen van te hebben. Totdat er een nauwkeurigere manier is gevonden om selectiviteit voor meerdere predikaten te schatten (met redelijke prestatiekenmerken), blijft het belangrijk om op de hoogte te zijn van de modelbeperkingen en dienovereenkomstig uit te kijken voor (potentiële) schattingsfouten.
De verschillende traceervlaggen geven enige controle over welke veronderstelling wordt gebruikt, maar de situatie is verre van perfect. Om te beginnen is de fijnste granulariteit waarmee een vlag kan worden toegepast een enkele query - schattingsgedrag kan niet worden gespecificeerd op predikaatniveau. Als u een query hebt waarbij sommige predikaten gecorreleerd zijn en andere onafhankelijk, kunnen de traceringsvlaggen u niet veel helpen zonder de query op de een of andere manier te herstructureren. Evenzo kan een problematische zoekopdracht predikaatcorrelaties hebben die niet goed worden gemodelleerd door een van de beschikbare opties.
Ad-hoc gebruik van de traceervlaggen vereist dezelfde rechten als DBCC TRACEON – namelijk sysadmin . Dat is waarschijnlijk prima voor persoonlijk testen, maar gebruik voor productie een plangids met behulp van de QUERYTRACEON hint is een betere optie. Met een plangids zijn er geen extra rechten vereist om de query uit te voeren (hoewel er natuurlijk verhoogde rechten nodig zijn om de plangids te maken).