Vorig jaar plaatste ik een tip met de naam Verbeter de efficiëntie van SQL Server door over te schakelen naar IN PLAATS VAN triggers.
De grote reden dat ik de voorkeur geef aan een IN PLAATS VAN een trigger, vooral in gevallen waarin ik veel schendingen van de bedrijfslogica verwacht, is dat het intuïtief lijkt dat het goedkoper zou zijn om een actie helemaal te voorkomen dan om door te gaan en deze uit te voeren (en log het!), alleen om een AFTER-trigger te gebruiken om de overtredende rijen te verwijderen (of de hele bewerking terug te draaien). De resultaten die in die tip werden getoond, toonden aan dat dit inderdaad het geval was - en ik vermoed dat ze nog meer uitgesproken zouden zijn met meer niet-geclusterde indexen die door de operatie worden beïnvloed.
Dat was echter op een trage schijf en op een vroege CTP van SQL Server 2014. Bij het voorbereiden van een dia voor een nieuwe presentatie die ik dit jaar over triggers ga doen, ontdekte ik dat op een recentere build van SQL Server 2014 - gecombineerd met bijgewerkte hardware - het was een beetje lastiger om dezelfde delta in prestaties te demonstreren tussen een AFTER- en IN PLAATS VAN-trigger. Dus ging ik op zoek naar waarom, hoewel ik meteen wist dat dit meer werk zou zijn dan ik ooit voor een enkele dia heb gedaan.
Een ding dat ik wil vermelden is dat triggers tempdb . kunnen gebruiken op verschillende manieren, en dit kan enkele van deze verschillen verklaren. Een AFTER-trigger gebruikt de versieopslag voor de ingevoegde en verwijderde pseudo-tabellen, terwijl een INSTEAD OF-trigger een kopie van deze gegevens in een interne werktabel maakt. Het verschil is subtiel, maar het is het vermelden waard.
De variabelen
Ik ga verschillende scenario's testen, waaronder:
- Drie verschillende triggers:
- Een AFTER-trigger die specifieke rijen verwijdert die mislukken
- Een AFTER-trigger die de hele transactie terugdraait als een rij mislukt
- Een INSTEAD OF-trigger die alleen de rijen invoegt die passeren
- Verschillende herstelmodellen en snapshot-isolatie-instellingen:
- VOLLEDIG met SNAPSHOT ingeschakeld
- VOLLEDIG met SNAPSHOT uitgeschakeld
- EENVOUDIG met SNAPSHOT ingeschakeld
- EENVOUDIG met SNAPSHOT uitgeschakeld
- Verschillende schijflay-outs*:
- Gegevens op SSD, inloggen 7200 RPM HDD
- Gegevens op SSD, log in op SSD
- Gegevens op 7200 RPM HDD, log op SSD
- Gegevens op 7200 RPM HDD, log in op 7200 RPM HDD
- Verschillende uitvalpercentages:
- 10%, 25% en 50% uitvalpercentage over:
- Enkele batch invoegen van 20.000 rijen
- 10 batches van 2000 rijen
- 100 batches van 200 rijen
- 1.000 batches van 20 rijen
- 20.000 singleton-inzetstukken
*
tempdbis een enkel gegevensbestand op een trage 7200 RPM-schijf. Dit is opzettelijk en bedoeld om eventuele knelpunten veroorzaakt door het verschillende gebruik vantempdbte vergroten . Ik ben van plan deze test op een gegeven moment opnieuw te bezoeken wanneertempdbstaat op een snellere SSD. - 10%, 25% en 50% uitvalpercentage over:
Ok, TL;DR al!
Als je alleen de resultaten wilt weten, ga dan naar beneden. Alles in het midden is slechts achtergrond en een uitleg van hoe ik de tests heb opgezet en uitgevoerd. Ik ben er niet kapot van dat niet iedereen geïnteresseerd zal zijn in alle details.
Het scenario
Voor deze specifieke reeks tests is het real-life scenario er een waarbij een gebruiker een schermnaam kiest, en de trigger is ontworpen om gevallen op te vangen waarin de gekozen naam sommige regels schendt. Het kan bijvoorbeeld geen enkele variatie op "ninny-muggins" zijn (je kunt hier zeker je fantasie gebruiken).
Ik heb een tabel gemaakt met 20.000 unieke gebruikersnamen:
USE model; GO -- 20,000 distinct, good Names ;WITH distinct_Names AS ( SELECT Name FROM sys.all_columns UNION SELECT Name FROM sys.all_objects ) SELECT TOP (20000) Name INTO dbo.GoodNamesSource FROM ( SELECT Name FROM distinct_Names UNION SELECT Name + 'x' FROM distinct_Names UNION SELECT Name + 'y' FROM distinct_Names UNION SELECT Name + 'z' FROM distinct_Names ) AS x; CREATE UNIQUE CLUSTERED INDEX x ON dbo.GoodNamesSource(Name);
Toen heb ik een tabel gemaakt die de bron zou zijn voor mijn "ondeugende namen" om te controleren. In dit geval is het gewoon ninny-muggins-00001 via ninny-muggins-10000 :
USE model;
GO
CREATE TABLE dbo.NaughtyUserNames
(
Name NVARCHAR(255) PRIMARY KEY
);
GO
-- 10,000 "bad" names
INSERT dbo.NaughtyUserNames(Name)
SELECT N'ninny-muggins-' + RIGHT(N'0000' + RTRIM(n),5)
FROM
(
SELECT TOP (10000) n = ROW_NUMBER() OVER (ORDER BY Name)
FROM dbo.GoodNamesSource
) AS x;
Ik heb deze tabellen gemaakt in het model database zodat elke keer dat ik een database maak, deze lokaal zou bestaan, en ik ben van plan veel databases te maken om de bovenstaande scenariomatrix te testen (in plaats van alleen de database-instellingen te wijzigen, het logboek te wissen, enz.). Let op:als u objecten in het model maakt voor testdoeleinden, zorg er dan voor dat u deze objecten verwijdert wanneer u klaar bent.
Even terzijde, ik ga hier opzettelijk belangrijke schendingen en andere foutafhandeling buiten beschouwing laten, waarbij ik de naïeve veronderstelling maak dat de gekozen naam wordt gecontroleerd op uniekheid lang voordat de invoeging ooit wordt geprobeerd, maar binnen dezelfde transactie (net als de controle tegen de ondeugende namentabel had van tevoren kunnen worden gemaakt).
Om dit te ondersteunen, heb ik ook de volgende drie bijna identieke tabellen gemaakt in model , voor testisolatiedoeleinden:
USE model; GO -- AFTER (rollback) CREATE TABLE dbo.UserNames_After_Rollback ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Rollback(DateCreated) INCLUDE(Name); -- AFTER (delete) CREATE TABLE dbo.UserNames_After_Delete ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Delete(DateCreated) INCLUDE(Name); -- INSTEAD CREATE TABLE dbo.UserNames_Instead ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_Instead(DateCreated) INCLUDE(Name); GO
En de volgende drie triggers, één voor elke tafel:
USE model;
GO
-- AFTER (rollback)
CREATE TRIGGER dbo.trUserNames_After_Rollback
ON dbo.UserNames_After_Rollback
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
IF EXISTS
(
SELECT 1 FROM inserted AS i
WHERE EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
)
)
BEGIN
ROLLBACK TRANSACTION;
END
END
GO
-- AFTER (delete)
CREATE TRIGGER dbo.trUserNames_After_Delete
ON dbo.UserNames_After_Delete
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
DELETE d
FROM inserted AS i
INNER JOIN dbo.NaughtyUserNames AS n
ON i.Name = n.Name
INNER JOIN dbo.UserNames_After_Delete AS d
ON i.UserID = d.UserID;
END
GO
-- INSTEAD
CREATE TRIGGER dbo.trUserNames_Instead
ON dbo.UserNames_Instead
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserNames_Instead(Name)
SELECT i.Name
FROM inserted AS i
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
);
END
GO U zou waarschijnlijk extra handelingen willen overwegen om de gebruiker op de hoogte te stellen dat zijn keuze is teruggedraaid of genegeerd, maar ook dit is voor de eenvoud weggelaten.
De testopstelling
Ik heb voorbeeldgegevens gemaakt die de drie uitvalpercentages vertegenwoordigen die ik wilde testen, waarbij ik 10 procent veranderde in 25 en vervolgens 50, en deze tabellen ook toevoegde aan model :
USE model;
GO
DECLARE @pct INT = 10, @cap INT = 20000;
-- change this ----^^ to 25 and 50
DECLARE @good INT = @cap - (@cap*(@pct/100.0));
SELECT Name, rn = ROW_NUMBER() OVER (ORDER BY NEWID())
INTO dbo.Source10Percent FROM
-- change this ^^ to 25 and 50
(
SELECT Name FROM
(
SELECT TOP (@good) Name FROM dbo.GoodNamesSource ORDER BY NEWID()
) AS g
UNION ALL
SELECT Name FROM
(
SELECT TOP (@cap-@good) Name FROM dbo.NaughtyUserNames ORDER BY NEWID()
) AS b
) AS x;
CREATE UNIQUE CLUSTERED INDEX x ON dbo.Source10Percent(rn);
-- and here as well -------------------------^^ Elke tabel heeft 20.000 rijen, met een verschillende mix van namen die slagen en mislukken, en de rijnummerkolom maakt het gemakkelijk om de gegevens op te delen in verschillende batchgroottes voor verschillende tests, maar met herhaalbare foutpercentages voor alle tests.
Natuurlijk hebben we een plek nodig om de resultaten vast te leggen. Ik koos ervoor om hiervoor een aparte database te gebruiken, elke test meerdere keren uit te voeren, simpelweg de duur vast te leggen.
CREATE DATABASE ControlDB; GO USE ControlDB; GO CREATE TABLE dbo.Tests ( TestID INT, DiskLayout VARCHAR(15), RecoveryModel VARCHAR(6), TriggerType VARCHAR(14), [snapshot] VARCHAR(3), FailureRate INT, [sql] NVARCHAR(MAX) ); CREATE TABLE dbo.TestResults ( TestID INT, BatchDescription VARCHAR(15), Duration INT );
Ik heb de dbo.Tests . ingevuld tabel met het volgende script, zodat ik verschillende delen kon uitvoeren om de vier databases in te stellen om overeen te komen met de huidige testparameters. Merk op dat D:\ een SSD is, terwijl G:\ een 7200 RPM-schijf is:
TRUNCATE TABLE dbo.Tests;
TRUNCATE TABLE dbo.TestResults;
;WITH d AS
(
SELECT DiskLayout FROM (VALUES
('DataSSD_LogHDD'),
('DataSSD_LogSSD'),
('DataHDD_LogHDD'),
('DataHDD_LogSSD')) AS d(DiskLayout)
),
t AS
(
SELECT TriggerType FROM (VALUES
('After_Delete'),
('After_Rollback'),
('Instead')) AS t(TriggerType)
),
m AS
(
SELECT RecoveryModel = 'FULL'
UNION ALL SELECT 'SIMPLE'
),
s AS
(
SELECT IsSnapshot = 0
UNION ALL SELECT 1
),
p AS
(
SELECT FailureRate = 10
UNION ALL SELECT 25
UNION ALL SELECT 50
)
INSERT ControlDB.dbo.Tests
(
TestID,
DiskLayout,
RecoveryModel,
TriggerType,
IsSnapshot,
FailureRate,
Command
)
SELECT
TestID = ROW_NUMBER() OVER
(
ORDER BY d.DiskLayout, t.TriggerType, m.RecoveryModel, s.IsSnapshot, p.FailureRate
),
d.DiskLayout,
m.RecoveryModel,
t.TriggerType,
s.IsSnapshot,
p.FailureRate,
[sql]= N'SET NOCOUNT ON;
CREATE DATABASE ' + QUOTENAME(d.DiskLayout)
+ N' ON (name = N''data'', filename = N''' + CASE d.DiskLayout
WHEN 'DataSSD_LogHDD' THEN N'D:\data\data1.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data1.ldf'');'
WHEN 'DataSSD_LogSSD' THEN N'D:\data\data2.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data2.ldf'');'
WHEN 'DataHDD_LogHDD' THEN N'G:\data\data3.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data3.ldf'');'
WHEN 'DataHDD_LogSSD' THEN N'G:\data\data4.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data4.ldf'');' END
+ '
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET RECOVERY ' + m.RecoveryModel + ';'';'
+ CASE WHEN s.IsSnapshot = 1 THEN
'
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET ALLOW_SNAPSHOT_ISOLATION ON;'';
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET READ_COMMITTED_SNAPSHOT ON;'';'
ELSE '' END
+ '
DECLARE @d DATETIME2(7), @i INT, @LoopID INT, @loops INT, @perloop INT;
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT LoopID, loops, perloop FROM dbo.Loops;
OPEN c;
FETCH c INTO @LoopID, @loops, @perloop;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC sp_executesql N''TRUNCATE TABLE '
+ QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + ';'';
SELECT @d = SYSDATETIME(), @i = 1;
WHILE @i <= @loops
BEGIN
BEGIN TRY
INSERT ' + QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + '(Name)
SELECT Name FROM ' + QUOTENAME(d.DiskLayout) + '.dbo.Source' + RTRIM(p.FailureRate) + 'Percent
WHERE rn > (@i-1)*@perloop AND rn <= @i*@perloop;
END TRY
BEGIN CATCH
SET @TestID = @TestID;
END CATCH
SET @i += 1;
END
INSERT ControlDB.dbo.TestResults(TestID, LoopID, Duration)
SELECT @TestID, @LoopID, DATEDIFF(MILLISECOND, @d, SYSDATETIME());
FETCH c INTO @LoopID, @loops, @perloop;
END
CLOSE c;
DEALLOCATE c;
DROP DATABASE ' + QUOTENAME(d.DiskLayout) + ';'
FROM d, t, m, s, p; -- implicit CROSS JOIN! Do as I say, not as I do! :-) Daarna was het eenvoudig om alle tests meerdere keren uit te voeren:
USE ControlDB;
GO
SET NOCOUNT ON;
DECLARE @TestID INT, @Command NVARCHAR(MAX), @msg VARCHAR(32);
DECLARE d CURSOR LOCAL FAST_FORWARD FOR
SELECT TestID, Command
FROM ControlDB.dbo.Tests ORDER BY TestID;
OPEN d;
FETCH d INTO @TestID, @Command;
WHILE @@FETCH_STATUS <> -1
BEGIN
SET @msg = 'Starting ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
EXEC sp_executesql @Command, N'@TestID INT', @TestID;
SET @msg = 'Finished ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
FETCH d INTO @TestID, @Command;
END
CLOSE d;
DEALLOCATE d;
GO 10
Op mijn systeem duurde dit bijna 6 uur, dus wees voorbereid om dit ononderbroken zijn gang te laten gaan. Zorg er ook voor dat u geen actieve verbindingen of queryvensters hebt geopend tegen het model database, anders kunt u deze foutmelding krijgen wanneer het script probeert een database te maken:
Kon geen exclusieve lock op database 'model' verkrijgen. Probeer de bewerking later opnieuw.
Resultaten
Er zijn veel gegevenspunten om naar te kijken (en naar alle zoekopdrachten die worden gebruikt om de gegevens af te leiden, wordt verwezen in de bijlage). Houd er rekening mee dat elke hier aangegeven gemiddelde duur meer dan 10 tests is en in totaal 100.000 rijen invoegt in de bestemmingstabel.
Grafiek 1 – Totaaloverzichten
De eerste grafiek toont algemene aggregaten (gemiddelde duur) voor de verschillende variabelen afzonderlijk (dus *alle* tests gebruiken een AFTER-trigger die wordt verwijderd, *alle* tests gebruiken een AFTER-trigger die wordt teruggedraaid, enz.).
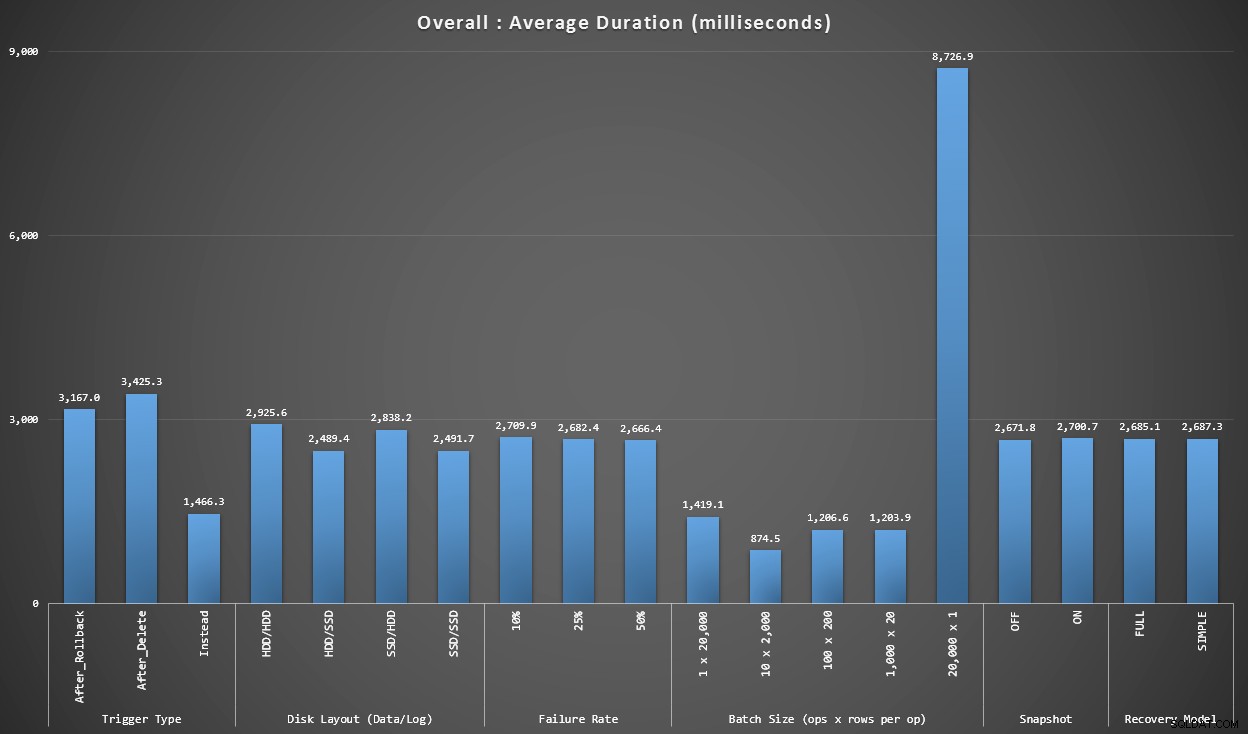
Gemiddelde duur, in milliseconden, voor elke afzonderlijke variabele
Een paar dingen vallen ons meteen op:
- De INSTEAD OF-trigger is hier twee keer zo snel als beide AFTER-triggers.
- Het hebben van het transactielog op SSD maakte een klein verschil. Locatie van het gegevensbestand veel minder.
- De batch van 20.000 singleton inserts was 7-8x langzamer dan elke andere batchdistributie.
- Het invoegen van een enkele batch van 20.000 rijen was langzamer dan een van de niet-singleton-distributies.
- Foutpercentage, snapshot-isolatie en herstelmodel hadden weinig of geen invloed op de prestaties.
Grafiek 2 – Beste 10 algemeen
Deze grafiek toont de snelste 10 resultaten wanneer elke variabele wordt overwogen. Dit zijn allemaal IN PLAATS VAN triggers waarbij het grootste percentage rijen faalt (50%). Verrassend genoeg had de snelste (hoewel niet veel) zowel gegevens als inloggen op dezelfde HDD (geen SSD). Er is hier een mix van schijflay-outs en herstelmodellen, maar alle 10 hadden snapshot-isolatie ingeschakeld en de top 7-resultaten hadden allemaal betrekking op de batchgrootte van 10 x 2.000 rijen.
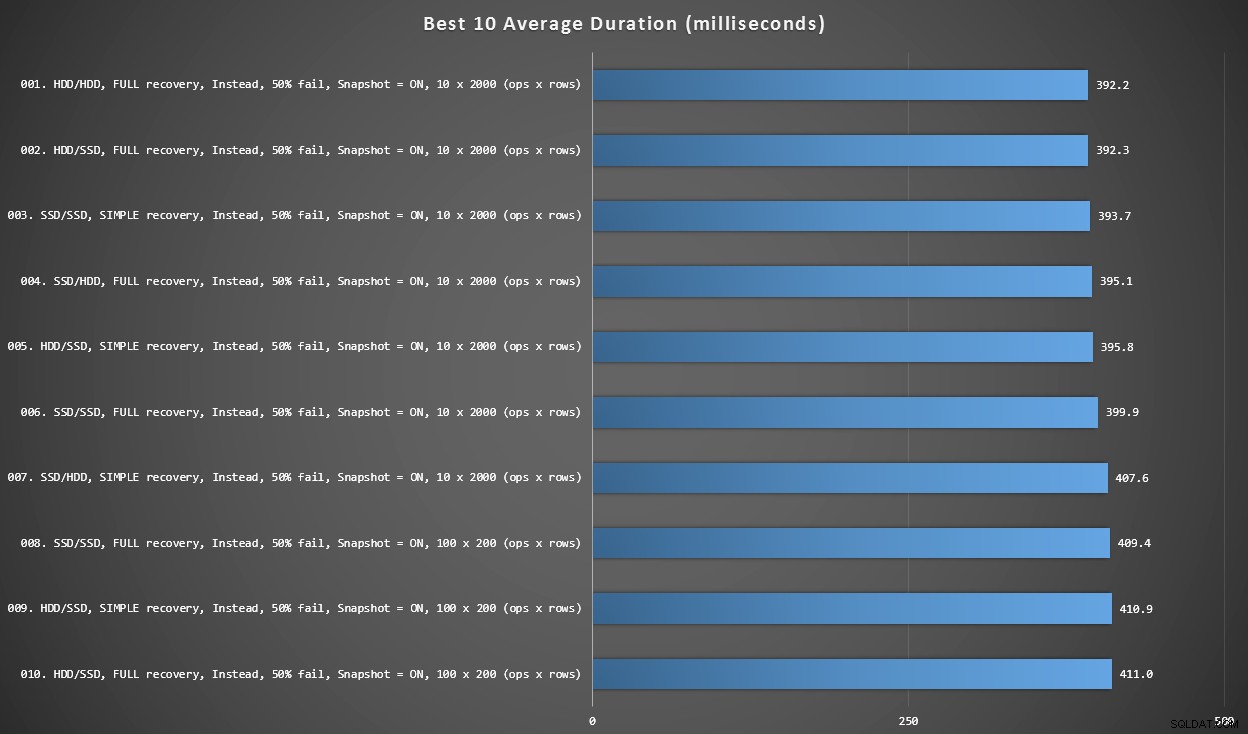
Beste 10 duur, in milliseconden, rekening houdend met elke variabele
De snelste AFTER-trigger – een ROLLBACK-variant met een uitvalpercentage van 10% in de batchgrootte van 100 x 200 rijen – kwam binnen op positie #144 (806 ms).
Grafiek 3 – Slechtste 10 algemeen
Deze grafiek toont de langzaamste 10 resultaten wanneer elke variabele wordt overwogen; het zijn allemaal AFTER-varianten, ze hebben allemaal de 20.000 singleton-inserts en ze hebben allemaal gegevens en inloggen op dezelfde trage HDD.
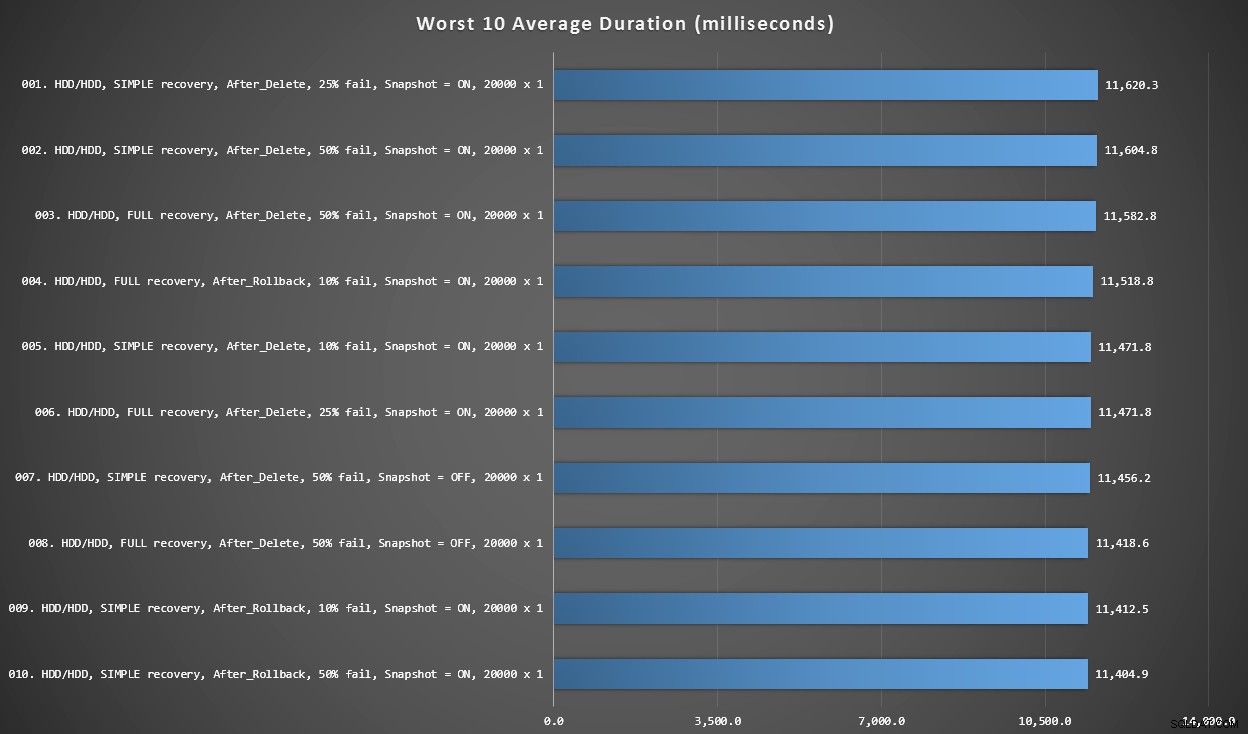
Slechtste 10 duur, in milliseconden, rekening houdend met elke variabele
De langzaamste INSTEAD OF-test was in positie #97, op 5.680 ms - een 20.000 singleton-inserttest waarbij 10% faalde. Het is ook interessant om op te merken dat geen enkele AFTER-trigger met de batchgrootte van 20.000 singleton inserts het beter deed - in feite was het 96ste slechtste resultaat een AFTER-test (verwijderen) die binnenkwam op 10.219 ms - bijna het dubbele van het volgende langzaamste resultaat.
Grafiek 4 – Type logschijf, Singleton-invoegingen
De grafieken hierboven geven ons een globaal beeld van de grootste pijnpunten, maar ze zijn ofwel te veel ingezoomd of niet genoeg ingezoomd. Deze grafiek filtert naar gegevens op basis van de realiteit:in de meeste gevallen zal dit type operatie een singleton-insert zijn. Ik dacht dat ik het zou uitsplitsen naar uitvalpercentage en het type schijf waarop het logboek zich bevindt, maar kijk alleen naar rijen waar de batch uit 20.000 afzonderlijke bijlagen bestaat.
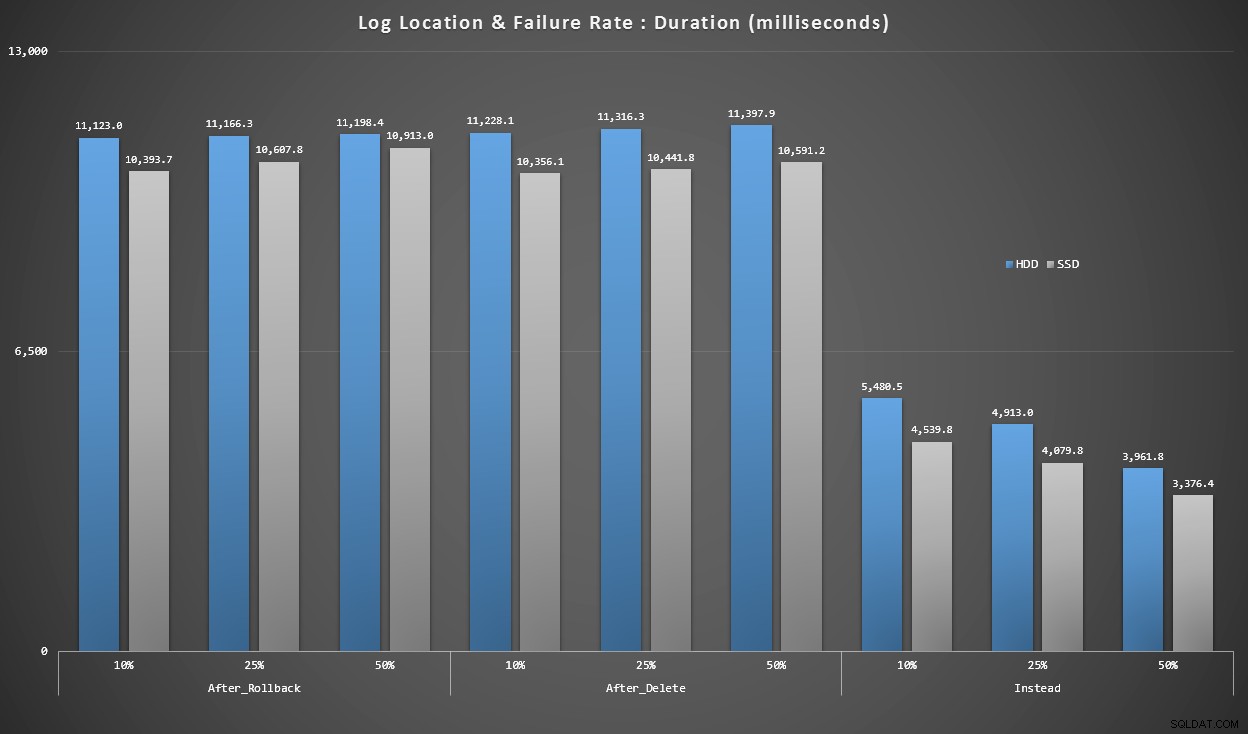
Duur, in milliseconden, gegroepeerd op uitvalpercentage en loglocatie, voor 20.000 individuele inzetstukken
Hier zien we dat alle AFTER-triggers gemiddeld in het bereik van 10-11 seconden liggen (afhankelijk van de loglocatie), terwijl alle IN PLAATS VAN-triggers ver onder de 6-secondengrens liggen.
Conclusie
Tot nu toe lijkt het mij duidelijk dat de IN PLAATS VAN trigger in de meeste gevallen een winnaar is - in sommige gevallen meer dan in andere (bijvoorbeeld als het percentage mislukkingen stijgt). Andere factoren, zoals het herstelmodel, lijken veel minder invloed te hebben op de algehele prestaties.
Als u andere ideeën heeft voor het opsplitsen van de gegevens, of als u een kopie van de gegevens wilt om uw eigen slicing en dices uit te voeren, laat het me dan weten. Als je hulp wilt bij het opzetten van deze omgeving zodat je je eigen tests kunt uitvoeren, kan ik je daar ook mee helpen.
Hoewel deze test aantoont dat IN PLAATS VAN triggers zeker het overwegen waard zijn, is het niet het hele verhaal. Ik heb deze triggers letterlijk aan elkaar geslagen met behulp van de logica waarvan ik dacht dat die het meest logisch was voor elk scenario, maar triggercode - zoals elke T-SQL-verklaring - kan worden afgestemd voor optimale plannen. In een vervolgbericht zal ik een mogelijke optimalisatie bekijken die de AFTER-trigger competitiever kan maken.
Bijlage
Query's gebruikt voor de sectie Resultaten:
Grafiek 1 – Totaaloverzichten
SELECT RTRIM(l.loops) + ' x ' + RTRIM(l.perloop), AVG(r.Duration*1.0) FROM dbo.TestResults AS r INNER JOIN dbo.Loops AS l ON r.LoopID = l.LoopID GROUP BY RTRIM(l.loops) + ' x ' + RTRIM(l.perloop); SELECT t.IsSnapshot, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.IsSnapshot; SELECT t.RecoveryModel, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.RecoveryModel; SELECT t.DiskLayout, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.DiskLayout; SELECT t.TriggerType, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.TriggerType; SELECT t.FailureRate, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.FailureRate;
Grafiek 2 en 3 – Beste en slechtste 10
;WITH src AS
(
SELECT DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
Batch = RTRIM(l.loops) + ' x ' + RTRIM(l.perloop),
Duration = AVG(Duration*1.0)
FROM dbo.Tests AS t
INNER JOIN dbo.TestResults AS tr
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON tr.LoopID = l.LoopID
GROUP BY DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
RTRIM(l.loops) + ' x ' + RTRIM(l.perloop)
),
agg AS
(
SELECT label = REPLACE(REPLACE(DiskLayout,'Data',''),'_Log','/')
+ ', ' + RecoveryModel + ' recovery, ' + TriggerType
+ ', ' + RTRIM(FailureRate) + '% fail'
+ ', Snapshot = ' + CASE IsSnapshot WHEN 1 THEN 'ON' ELSE 'OFF' END
+ ', ' + Batch + ' (ops x rows)',
best10 = ROW_NUMBER() OVER (ORDER BY Duration),
worst10 = ROW_NUMBER() OVER (ORDER BY Duration DESC),
Duration
FROM src
)
SELECT grp, label, Duration FROM
(
SELECT TOP (20) grp = 'best', label = RIGHT('0' + RTRIM(best10),2) + '. ' + label, Duration
FROM agg WHERE best10 <= 10
ORDER BY best10 DESC
UNION ALL
SELECT TOP (20) grp = 'worst', label = RIGHT('0' + RTRIM(worst10),2) + '. ' + label, Duration
FROM agg WHERE worst10 <= 10
ORDER BY worst10 DESC
) AS b
ORDER BY grp; Grafiek 4 – Type logschijf, Singleton-invoegingen
;WITH x AS
(
SELECT
TriggerType,FailureRate,
LogLocation = RIGHT(DiskLayout,3),
Duration = AVG(Duration*1.0)
FROM dbo.TestResults AS tr
INNER JOIN dbo.Tests AS t
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON l.LoopID = tr.LoopID
WHERE l.loops = 20000
GROUP BY RIGHT(DiskLayout,3), FailureRate, TriggerType
)
SELECT TriggerType, FailureRate,
HDDDuration = MAX(CASE WHEN LogLocation = 'HDD' THEN Duration END),
SSDDuration = MAX(CASE WHEN LogLocation = 'SSD' THEN Duration END)
FROM x
GROUP BY TriggerType, FailureRate
ORDER BY TriggerType, FailureRate;