Een eenvoudige definitie van de mediaan is:
De mediaan is de middelste waarde in een gesorteerde lijst met getallenOm dat een beetje uit te werken, kunnen we de mediaan van een lijst met getallen vinden met behulp van de volgende procedure:
- Sorteer de getallen (in oplopende of aflopende volgorde, het maakt niet uit welke).
- Het middelste getal (op positie) in de gesorteerde lijst is de mediaan.
- Als er twee "even middelste" getallen zijn, is de mediaan het gemiddelde van de twee middelste waarden.
Aaron Bertrand heeft eerder verschillende manieren getest om de mediaan in SQL Server te berekenen:
- Wat is de snelste manier om de mediaan te berekenen?
- Beste benaderingen voor gegroepeerde mediaan
Rob Farley heeft onlangs een andere benadering toegevoegd die gericht is op installaties van vóór 2012:
- Medianen pre-SQL 2012
Dit artikel introduceert een nieuwe methode met behulp van een dynamische cursor.
De OFFSET-FETCH-methode van 2012
We beginnen met te kijken naar de best presterende implementatie, gemaakt door Peter Larsson. Het gebruikt de SQL Server 2012 OFFSET uitbreiding van de ORDER BY clausule om efficiënt de een of twee middelste rijen te lokaliseren die nodig zijn om de mediaan te berekenen.
OFFSET enkele mediaan
Aarons eerste artikel testte het berekenen van een enkele mediaan over een tabel met tien miljoen rijen:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id);
Peter Larsson's oplossing met behulp van de OFFSET extensie is:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); De bovenstaande code codeert het resultaat van het tellen van de rijen in de tabel. Alle geteste methoden voor het berekenen van de mediaan hebben deze telling nodig om de mediaanrijnummers te berekenen, dus het zijn constante kosten. Door het tellen van rijen buiten de timing te laten, wordt één mogelijke bron van variatie vermeden.
Het uitvoeringsplan voor de OFFSET oplossing wordt hieronder getoond:

De Top-operator slaat snel de onnodige rijen over en geeft alleen de een of twee rijen door die nodig zijn om de mediaan te berekenen naar het stroomaggregaat. Als deze query wordt uitgevoerd met een warme cache en de verzameling van het uitvoeringsplan is uitgeschakeld, wordt deze query uitgevoerd gedurende 910 ms gemiddeld op mijn laptop. Dit is een machine met een Intel i7 740QM-processor die draait op 1,73 GHz met Turbo uitgeschakeld (voor consistentie).
OFFSET gegroepeerde mediaan
Het tweede artikel van Aaron testte de prestaties van het berekenen van een mediaan per groep, met behulp van een verkooptabel met een miljoen rijen met tienduizend vermeldingen voor elk van honderd verkopers:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
Nogmaals, de best presterende oplossing gebruikt OFFSET :
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
SELECT d.SalesPerson, w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK)
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w(Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Het belangrijkste deel van het uitvoeringsplan wordt hieronder weergegeven:

De bovenste rij van het plan betreft het vinden van het aantal groepsrijen voor elke verkoper. De onderste rij gebruikt dezelfde planelementen als voor de mediaanoplossing met één groep om de mediaan voor elke verkoper te berekenen. Wanneer uitgevoerd met een warme cache en uitvoeringsplannen uitgeschakeld, wordt deze query uitgevoerd in 320 ms gemiddeld op mijn laptop.
Een dynamische cursor gebruiken
Het lijkt misschien gek om zelfs maar te denken aan het gebruik van een cursor om de mediaan te berekenen. Transact SQL-cursors hebben de (meestal welverdiende) reputatie traag en inefficiënt te zijn. Er wordt ook vaak gedacht dat dynamische cursors het slechtste type cursor zijn. Deze punten zijn onder bepaalde omstandigheden geldig, maar niet altijd.
Transact SQL-cursors zijn beperkt tot het verwerken van een enkele rij tegelijk, dus ze kunnen inderdaad traag zijn als er veel rijen moeten worden opgehaald en verwerkt. Dat is echter niet het geval voor de mediaanberekening:het enige wat we hoeven te doen is de een of twee middelste waarden efficiënt te lokaliseren en op te halen. . Een dynamische cursor is zeer geschikt voor deze taak, zoals we zullen zien.
Enkele mediaan dynamische cursor
De dynamische cursoroplossing voor een enkele mediaanberekening bestaat uit de volgende stappen:
- Maak een dynamische scrollbare cursor over de geordende lijst met items.
- Bereken de positie van de eerste mediaanrij.
- Verplaats de cursor met
FETCH RELATIVE. - Bepaal of een tweede rij nodig is om de mediaan te berekenen.
- Zo niet, retourneer dan onmiddellijk de enkele mediaanwaarde.
- Haal anders de tweede waarde op met
FETCH NEXT. - Bereken het gemiddelde van de twee waarden en retourneer.
Merk op hoe nauw die lijst overeenkomt met de eenvoudige procedure voor het vinden van de mediaan die aan het begin van dit artikel is gegeven. Een volledige Transact SQL-code-implementatie wordt hieronder weergegeven:
-- Dynamic cursor
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE
@RowCount bigint, -- Total row count
@Row bigint, -- Median row number
@Amount1 integer, -- First amount
@Amount2 integer, -- Second amount
@Median float; -- Calculated median
SET @RowCount = 10000000;
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
DECLARE Median CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
O.val
FROM dbo.obj AS O
ORDER BY
O.val;
OPEN Median;
-- Calculate the position of the first median row
SET @Row = (@RowCount + 1) / 2;
-- Move to the row
FETCH RELATIVE @Row
FROM Median
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value we have
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Median
INTO @Amount2;
-- Calculate the median value from the two values
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
SELECT Median = @Median;
SELECT DynamicCur = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
Het uitvoeringsplan voor de FETCH RELATIVE statement toont de dynamische cursor die efficiënt verplaatst naar de eerste rij die nodig is voor de mediaanberekening:
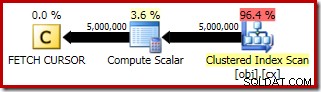
Het plan voor de FETCH NEXT (alleen vereist als er een tweede middelste rij is, zoals in deze tests) is een enkele rij ophalen van de opgeslagen positie van de cursor:
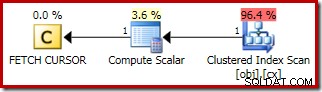
De voordelen van het gebruik van een dynamische cursor hier zijn:
- Het vermijdt het doorlopen van de hele set (het lezen stopt nadat de mediaanrijen zijn gevonden); en
- Er wordt geen tijdelijke kopie van de gegevens gemaakt in tempdb , zoals het zou zijn voor een statische of keyset-cursor.
Merk op dat we geen FAST_FORWARD kunnen specificeren cursor hier (laat de keuze van een statisch of dynamisch-achtig plan over aan de optimizer) omdat de cursor scrollbaar moet zijn om FETCH RELATIVE te ondersteunen . Dynamisch is sowieso de optimale keuze.
Als deze query wordt uitgevoerd met een warme cache en de verzameling van het uitvoeringsplan is uitgeschakeld, duurt deze query 930 ms gemiddeld op mijn testmachine. Dit is iets langzamer dan de 910 ms voor de OFFSET oplossing, maar de dynamische cursor is aanzienlijk sneller dan de andere methoden die Aaron en Rob hebben getest, en er is geen SQL Server 2012 (of hoger) voor nodig.
Ik ga de andere methoden van vóór 2012 hier niet herhalen, maar als voorbeeld van de grootte van de prestatiekloof duurt de volgende oplossing voor rijnummering 1550 ms gemiddeld (70% langzamer):
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK)
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT RowNumber = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());

Gegroepeerde mediane dynamische cursortest
Het is eenvoudig om de oplossing voor dynamische cursor met enkele mediaan uit te breiden om gegroepeerde medianen te berekenen. Omwille van de consistentie ga ik geneste cursors gebruiken (ja, echt):
- Open een statische cursor over de verkopers en het aantal rijen.
- Bereken de mediaan voor elke persoon met elke keer een nieuwe dynamische cursor.
- Sla elk resultaat gaandeweg op in een tabelvariabele.
De code wordt hieronder getoond:
-- Timing
DECLARE @s datetime2 = SYSUTCDATETIME();
-- Holds results
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
-- Variables
DECLARE
@SalesPerson integer, -- Current sales person
@RowCount bigint, -- Current row count
@Row bigint, -- Median row number
@Amount1 float, -- First amount
@Amount2 float, -- Second amount
@Median float; -- Calculated median
-- Row counts per sales person
DECLARE SalesPersonCounts
CURSOR
LOCAL
FORWARD_ONLY
STATIC
READ_ONLY
FOR
SELECT
SalesPerson,
COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
ORDER BY SalesPerson;
OPEN SalesPersonCounts;
-- First person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
WHILE @@FETCH_STATUS = 0
BEGIN
-- Records for the current person
-- Note dynamic cursor
DECLARE Person CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
S.Amount
FROM dbo.Sales AS S
WHERE
S.SalesPerson = @SalesPerson
ORDER BY
S.Amount;
OPEN Person;
-- Calculate median row 1
SET @Row = (@RowCount + 1) / 2;
-- Move to median row 1
FETCH RELATIVE @Row
FROM Person
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Person
INTO @Amount2;
-- Calculate the median value
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
-- Add the result row
INSERT @Result (SalesPerson, Median)
VALUES (@SalesPerson, @Median);
-- Finished with the person cursor
CLOSE Person;
DEALLOCATE Person;
-- Next person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
END;
---- Results
--SELECT
-- R.SalesPerson,
-- R.Median
--FROM @Result AS R;
-- Tidy up
CLOSE SalesPersonCounts;
DEALLOCATE SalesPersonCounts;
-- Show elapsed time
SELECT NestedCur = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); De buitenste cursor is opzettelijk statisch omdat alle rijen in die set worden aangeraakt (ook is een dynamische cursor niet beschikbaar vanwege de groeperingsbewerking in de onderliggende query). Er is deze keer niets nieuws of interessants te zien in de uitvoeringsplannen.
Het interessante is de uitvoering. Ondanks de herhaalde creatie en verwijdering van de innerlijke dynamische cursor, presteert deze oplossing erg goed op de testdataset. Met een warme cache en uitvoeringsplannen uitgeschakeld, voltooit het cursorscript in 330 ms gemiddeld op mijn testmachine. Dit is weer een klein beetje langzamer dan de 320 ms opgenomen door de OFFSET gegroepeerde mediaan, maar het verslaat de andere standaardoplossingen die in de artikelen van Aaron en Rob worden vermeld met een ruime marge.
Nogmaals, als voorbeeld van de prestatiekloof met de andere niet-2012-methoden:de volgende oplossing voor rijnummering duurt 485 ms gemiddeld op mijn testopstelling (50% slechter):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median numeric(38, 6) NOT NULL
);
INSERT @Result
SELECT
S.SalesPerson,
CA.Median
FROM
(
SELECT
SalesPerson,
NumRows = COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
) AS S
CROSS APPLY
(
SELECT AVG(1.0 * SQ1.Amount) FROM
(
SELECT
S2.Amount,
rn = ROW_NUMBER() OVER (
ORDER BY S2.Amount)
FROM dbo.Sales AS S2 WITH (PAGLOCK)
WHERE
S2.SalesPerson = S.SalesPerson
) AS SQ1
WHERE
SQ1.rn BETWEEN (S.NumRows + 1)/2 AND (S.NumRows + 2)/2
) AS CA (Median);
SELECT RowNumber = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());

Resultatenoverzicht
In de enkelvoudige mediaantest liep de dynamische cursor 930 ms versus 910 ms voor de OFFSET methode.
In de gegroepeerde mediaantest liep de geneste cursor 330 ms versus 320 ms voor OFFSET .
In beide gevallen was de cursormethode aanzienlijk sneller dan de andere niet-OFFSET methoden. Als u een enkele of gegroepeerde mediaan moet berekenen op een instantie van vóór 2012, kan een dynamische cursor of geneste cursor echt de optimale keuze zijn.
Koude cache-prestaties
Sommigen van jullie vragen zich misschien af wat de prestaties van de koude cache zijn. Voer het volgende uit vóór elke test:
CHECKPOINT; DBCC DROPCLEANBUFFERS;
Dit zijn de resultaten voor de enkelvoudige mediane test:
OFFSET methode:940 ms
Dynamische cursor:955 ms
Voor de gegroepeerde mediaan:
OFFSET methode:380 ms
Geneste cursors:385 ms
Laatste gedachten
De dynamische cursoroplossingen zijn echt aanzienlijk sneller dan de niet-OFFSET methoden voor zowel enkelvoudige als gegroepeerde medianen, althans met deze steekproefgegevenssets. Ik heb er bewust voor gekozen om de testgegevens van Aaron opnieuw te gebruiken, zodat de gegevenssets niet opzettelijk scheef in de richting van de dynamische cursor werden geplaatst. Er misschien andere datadistributies zijn waarvoor de dynamische cursor geen goede optie is. Desalniettemin laat het zien dat er nog steeds momenten zijn waarop een cursor een snelle en efficiënte oplossing kan zijn voor het juiste soort probleem. Zelfs dynamische en geneste cursors.
Lezers met adelaarsogen hebben misschien het PAGLOCK . opgemerkt hint in de OFFSET gegroepeerde mediane test. Dit is vereist voor de beste prestaties, om redenen die ik in mijn volgende artikel zal bespreken. Zonder dit verliest de 2012-oplossing met een behoorlijke marge van de geneste cursor (590ms versus 330ms ).