We zijn allemaal verwend geraakt door het vermogen van zoekmachines om dingen als spelfouten, spellingverschillen in namen of andere situaties te omzeilen waarin de zoekterm kan overeenkomen op pagina's waarvan de auteurs er de voorkeur aan geven een andere spelling van een woord te gebruiken. Het toevoegen van dergelijke functies aan onze eigen databasegestuurde applicaties kan onze applicaties op dezelfde manier verrijken en verbeteren, en hoewel het aanbod van commerciële relationele databasebeheersystemen (RDBMS) hun eigen volledig ontwikkelde, op maat gemaakte oplossingen voor dit probleem bieden, kunnen de licentiekosten van deze tools hoger zijn dan verwacht. bereik voor kleinere ontwikkelaars of kleine softwareontwikkelaars.
Je zou kunnen stellen dat dit in plaats daarvan zou kunnen worden gedaan met behulp van een spellingcontrole. Een spellingcontrole heeft echter meestal geen zin bij het matchen van een correcte, maar alternatieve spelling van een naam of ander woord. Matching by sound vult deze functionele leemte op. Dat is het onderwerp van de programmeerhandleiding van vandaag:hoe je geluiden kunt opvragen met Python met behulp van metafoons.
Wat is Soundex?
Soundex werd in het begin van de 20e eeuw ontwikkeld als een middel voor de US Census om namen te matchen op basis van hoe ze klinken. Het werd vervolgens door verschillende telefoonmaatschappijen gebruikt om de namen van klanten te matchen. Het wordt tot op de dag van vandaag gebruikt voor het matchen van fonetische gegevens, ondanks dat het beperkt is tot Amerikaans-Engelse spelling en uitspraak. Het is ook beperkt tot Engelse letters. De meeste RDBMS, zoals SQL Server en Oracle, implementeren samen met MySQL en zijn varianten een Soundex-functie en ondanks zijn beperkingen wordt deze nog steeds gebruikt om veel niet-Engelse woorden te matchen.
Wat is een dubbele metafoon?
De Metafoon algoritme is ontwikkeld in 1990 en overwint enkele van de beperkingen van Soundex. In 2000, een verbeterde opvolger, Double Metaphone , was ontwikkeld. Double Metaphone retourneert een primaire en secundaire waarde die overeenkomt met twee manieren waarop een enkel woord kan worden uitgesproken. Tot op de dag van vandaag is dit algoritme een van de betere open-source fonetische algoritmen. Metaphone 3 werd in 2009 uitgebracht als een verbetering van Double Metaphone, maar dit is een commercieel product.
Helaas implementeren veel van de prominente hierboven genoemde RDBMS geen dubbele metafoon, en de meeste prominente scripttalen bieden geen ondersteunde implementatie van Double Metaphone. Python biedt echter wel een module die Double Metaphone implementeert.
De voorbeelden in deze programmeerhandleiding voor Python gebruiken MariaDB versie 10.5.12 en Python 3.9.2, beide draaiend op Kali/Debian Linux.
Hoe voeg je een dubbele metafoon toe aan Python
Zoals elke Python-module kan de pip-tool worden gebruikt om Double Metaphone te installeren. De syntaxis is afhankelijk van uw Python-installatie. Een typische Double Metaphone-installatie ziet er als volgt uit:
# Typical if you have only Python 3 installed $ pip install doublemetaphone # If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install DoubleMetaphone
Merk op dat het extra hoofdlettergebruik opzettelijk is. De volgende code is een voorbeeld van het gebruik van Double Metaphone in Python:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 1 - Demo script to verify functionality
Het bovenstaande Python-script geeft de volgende uitvoer wanneer het wordt uitgevoerd in uw geïntegreerde ontwikkelomgeving (IDE) of code-editor:
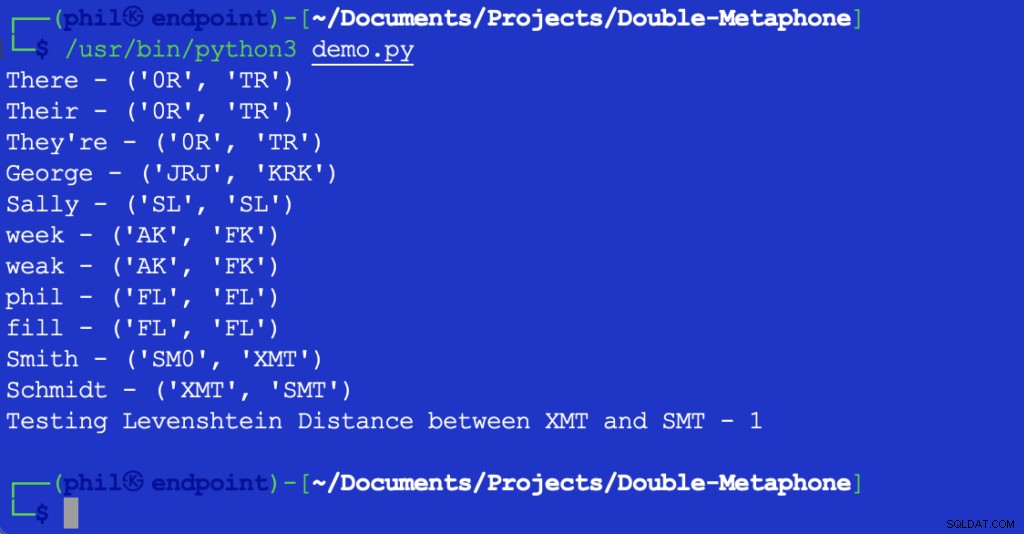
Figuur 1 – Uitvoer van demoscript
Zoals hier te zien is, heeft elk woord zowel een primaire als een secundaire fonetische waarde. Woorden die overeenkomen met zowel primaire als secundaire waarden worden fonetische overeenkomsten genoemd. Woorden die ten minste één fonetische waarde delen, of die de eerste paar karakters in een fonetische waarde delen, zouden fonetisch dicht bij elkaar liggen.
De meeste letters weergegeven komen overeen met hun Engelse uitspraak. X kan overeenkomen met KS , SH , of C . 0 komt overeen met de de geluid in de of daar . Klinkers komen alleen overeen aan het begin van een woord. Vanwege het ontelbare aantal verschillen in regionale accenten, is het niet mogelijk om te zeggen dat woorden objectief exact overeenkomen, zelfs als ze dezelfde fonetische waarden hebben.
Fonetische waarden vergelijken met Python
Er zijn talloze online bronnen die de volledige werking van het Double Metaphone-algoritme kunnen beschrijven; dit is echter niet nodig om het te gebruiken omdat we meer geïnteresseerd zijn in vergelijken de berekende waarden, meer dan dat we geïnteresseerd zijn in het berekenen van de waarden. Zoals eerder vermeld, als er ten minste één waarde gemeenschappelijk is tussen twee woorden, kan worden gezegd dat deze waarden fonetische overeenkomsten zijn , en fonetische waarden die vergelijkbaar . zijn zijn fonetisch dichtbij .
Het vergelijken van absolute waarden is eenvoudig, maar hoe kan worden vastgesteld dat strings vergelijkbaar zijn? Hoewel er geen technische beperkingen zijn die u ervan weerhouden om reeksen van meerdere woorden te vergelijken, zijn deze vergelijkingen meestal onbetrouwbaar. Blijf bij het vergelijken van losse woorden.
Wat zijn Levenshtein-afstanden?
De Levenshtein-afstand tussen twee tekenreeksen is het aantal afzonderlijke tekens dat in één tekenreeks moet worden gewijzigd om het overeen te laten komen met de tweede tekenreeks. Een paar snaren met een lagere Levenshtein-afstand lijken meer op elkaar dan een paar snaren met een hogere Levenshtein-afstand. Levenshtein Distance is vergelijkbaar met Hamming Distance , maar de laatste is beperkt tot snaren van dezelfde lengte, aangezien de fonetische waarden van de dubbele metafoon in lengte kunnen variëren, is het logischer om deze te vergelijken met behulp van de Levenshtein-afstand.
Python Levenshtein-afstandsbibliotheek
Python kan worden uitgebreid om Levenshtein Distance-berekeningen te ondersteunen via een Python-module:
# If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install python-Levenshtein
Merk op dat, net als bij de installatie van de DoubleMetaphone hierboven, de syntaxis van de aanroep naar pip kan varieren. De python-Levenshtein-module biedt veel meer functionaliteit dan alleen berekeningen van Levenshtein Distance.
De onderstaande code toont een test voor Levenshtein Distance-berekening in Python:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 2 - Demo extended to verify Levenshtein Distance calculation functionality
Het uitvoeren van dit script geeft de volgende output:
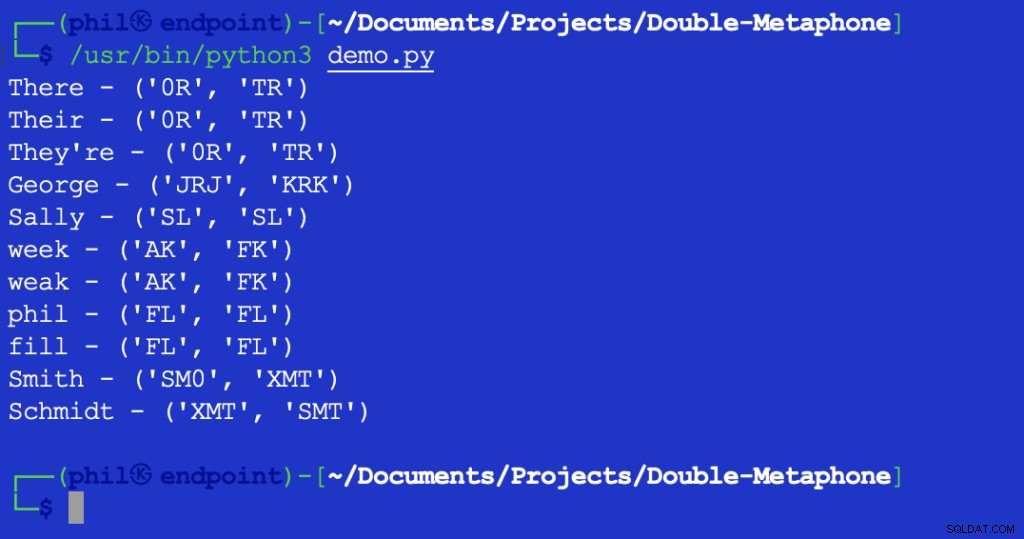
Figuur 2 – Uitvoer van Levenshtein Afstandstest
De geretourneerde waarde van 1 geeft aan dat er één teken staat tussen XMT en SMT dat is anders. In dit geval is dit het eerste teken in beide strings.
Dubbele metafoons vergelijken in Python
Wat volgt is niet alles wat met fonetische vergelijkingen te maken heeft. Het is gewoon een van de vele manieren om een dergelijke vergelijking uit te voeren. Om de fonetische nabijheid van twee gegeven strings effectief te vergelijken, moet elke Double Metaphone fonetische waarde van een string worden vergeleken met de corresponderende Double Metaphone fonetische waarde van een andere string. Aangezien aan beide fonetische waarden van een gegeven string hetzelfde gewicht wordt toegekend, geeft het gemiddelde van deze vergelijkingswaarden een redelijk goede benadering van de fonetische nabijheid:
PN = [ Dist(DM11, DM21,) + Dist(DM12, DM22,) ] / 2.0
Waar:
- DM1(1) :Eerste dubbele metafoonwaarde van string 1,
- DM1(2) :Tweede dubbele metafoonwaarde van string 1
- DM2(1) :Eerste dubbele metafoonwaarde van string 2
- DM2(2) :Tweede dubbele metafoonwaarde van string 2
- PN :Fonetische nabijheid, waarbij lagere waarden dichterbij zijn dan hogere waarden. Een nulwaarde geeft fonetische overeenkomst aan. De hoogste waarde hiervoor is het aantal letters in de kortste string.
Deze formule wordt onderverdeeld in gevallen zoals Schmidt (XMT, SMT) en Smith (SM0, XMT) waarbij de eerste fonetische waarde van de eerste string overeenkomt met de tweede fonetische waarde van de tweede string. In dergelijke situaties kunnen zowel Schmidt en Smith kan worden beschouwd als fonetisch vergelijkbaar vanwege de gedeelde waarde. De code voor de nabijheidsfunctie moet de bovenstaande formule alleen toepassen als alle vier de fonetische waarden verschillend zijn. De formule heeft ook zwakke punten bij het vergelijken van strings van verschillende lengtes.
Merk op dat er geen enkel effectieve manier is om strings van verschillende lengtes te vergelijken, hoewel het berekenen van de Levenshtein-afstand tussen twee strings rekening houdt met verschillen in stringlengte. Een mogelijke oplossing zou zijn om beide strings te vergelijken tot de lengte van de kortere van de twee strings.
Hieronder vindt u een voorbeeldcodefragment dat de bovenstaande code implementeert, samen met enkele testvoorbeelden:
# demo2.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testwords = ["Philippe", "Phillip", "Sallie", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt", "Harold", "Herald"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
print ("Distance between AK and AK - " + str(distance('AK', 'AK')) + "]")
print ("Comparing week and weak - [" + str(Nearness("week", "weak")) + "]")
print ("Comparing Harold and Herald - [" + str(Nearness("Harold", "Herald")) + "]")
print ("Comparing Smith and Schmidt - [" + str(Nearness("Smith", "Schmidt")) + "]")
print ("Comparing Philippe and Phillip - [" + str(Nearness("Philippe", "Phillip")) + "]")
print ("Comparing Phil and Phillip - [" + str(Nearness("Phil", "Phillip")) + "]")
print ("Comparing Robert and Joseph - [" + str(Nearness("Robert", "Joseph")) + "]")
print ("Comparing Samuel and Elizabeth - [" + str(Nearness("Samuel", "Elizabeth")) + "]")
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 3 - Implementation of the Nearness Algorithm Above
De voorbeeldcode van Python geeft de volgende uitvoer:
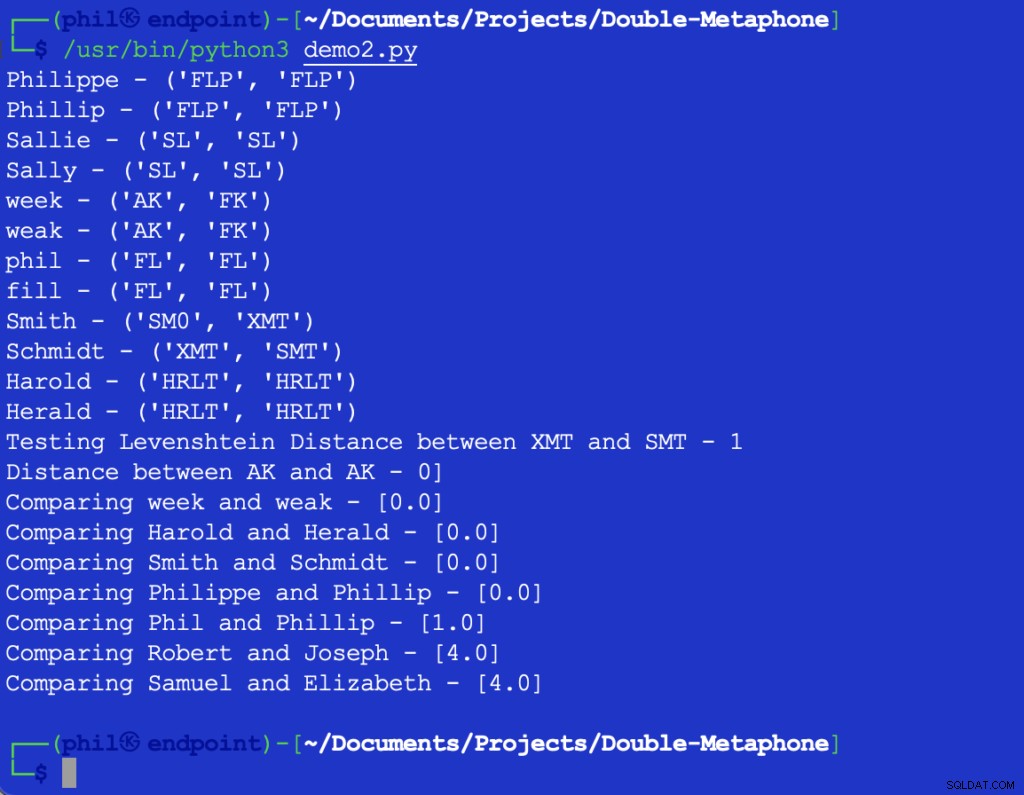
Figuur 3 – Uitvoer van het Nabijheidsalgoritme
De voorbeeldenset bevestigt de algemene trend dat hoe groter de verschillen in woorden, hoe hoger de output van de Nabijheid functie.
Database-integratie in Python
De bovenstaande code doorbreekt de functionele kloof tussen een bepaald RDBMS en een Double Metaphone-implementatie. Bovendien, door het implementeren van de Nabijheid functie in Python, wordt het gemakkelijk te vervangen als een ander vergelijkingsalgoritme de voorkeur heeft.
Bekijk de volgende MySQL/MariaDB-tabel:
create table demo_names (record_id int not null auto_increment, lastname varchar(100) not null default '', firstname varchar(100) not null default '', primary key(record_id)); Listing 4 - MySQL/MariaDB CREATE TABLE statement
In de meeste databasegestuurde toepassingen stelt de middleware SQL-statements samen voor het beheren van de gegevens, inclusief het invoegen ervan. De volgende code zal enkele voorbeeldnamen in deze tabel invoegen, maar in de praktijk zou elke code van een web- of desktoptoepassing die dergelijke gegevens verzamelt hetzelfde kunnen doen.
# demo3.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testNames = ["Smith, Jane", "Williams, Tim", "Adams, Richard", "Franks, Gertrude", "Smythe, Kim", "Daniels, Imogen", "Nguyen, Nancy",
"Lopez, Regina", "Garcia, Roger", "Diaz, Catalina"]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
for name in testNames:
nameParts = name.split(',')
# Normally one should do bounds checking here.
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
sql = "insert into demo_names (lastname, firstname) values(%s, %s)"
values = (lastname, firstname)
insertCursor = mydb.cursor()
insertCursor.execute (sql, values)
mydb.commit()
mydb.close()
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Inserting sample data into a database.
Het uitvoeren van deze code drukt niets af, maar het vult wel de testtabel in de database voor de volgende lijst die moet worden gebruikt. Als u de tabel rechtstreeks in de MySQL-client opvraagt, kunt u controleren of de bovenstaande code werkte:
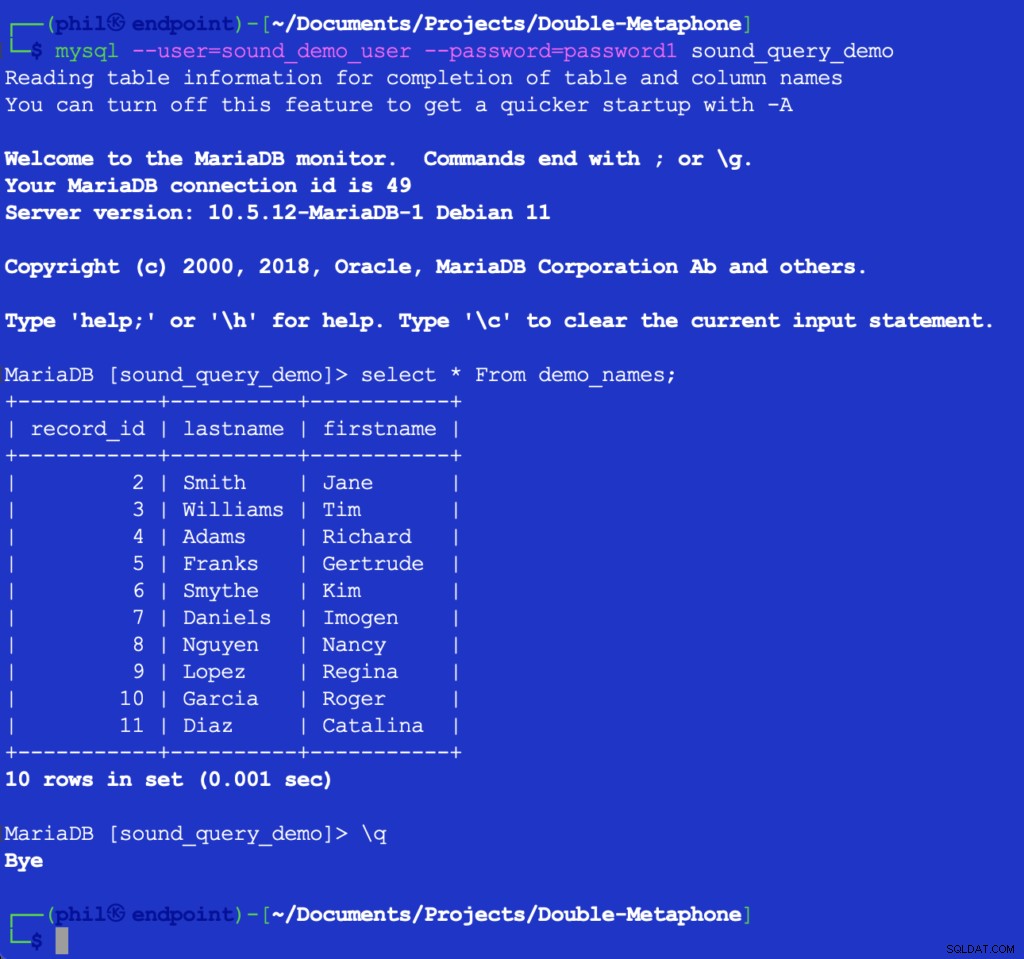
Figuur 4- De ingevoegde tabelgegevens
De onderstaande code zal enkele vergelijkingsgegevens in de bovenstaande tabelgegevens invoeren en er een nabijheidsvergelijking mee uitvoeren:
# demo4.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
comparisonNames = ["Smith, John", "Willard, Tim", "Adamo, Franklin" ]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
sql = "select lastname, firstname from demo_names order by lastname, firstname"
cursor1 = mydb.cursor()
cursor1.execute (sql)
results1 = cursor1.fetchall()
cursor1.close()
mydb.close()
for comparisonName in comparisonNames:
nameParts = comparisonName.split(",")
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
print ("Comparison for " + firstname + " " + lastname + ":")
for result in results1:
firstnameNearness = Nearness (firstname, result[1])
lastnameNearness = Nearness (lastname, result[0])
print ("\t[" + firstname + "] vs [" + result[1] + "] - " + str(firstnameNearness)
+ ", [" + lastname + "] vs [" + result[0] + "] - " + str(lastnameNearness))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Nearness Comparison Demo
Als we deze code uitvoeren, krijgen we de onderstaande output:
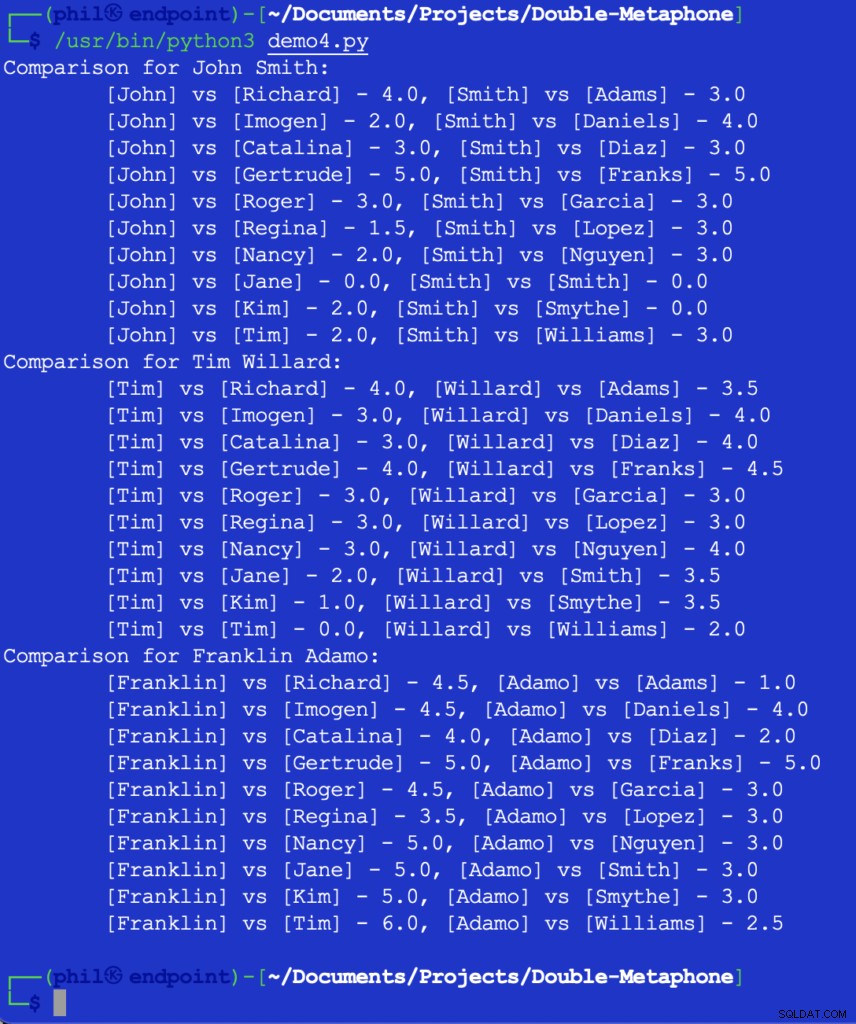
Figuur 5 – Resultaten van de Nabijheidsvergelijking
Op dit punt zou het aan de ontwikkelaar zijn om te beslissen wat de drempel zou zijn voor wat een bruikbare vergelijking zou zijn. Sommige van de bovenstaande cijfers lijken misschien onverwacht of verrassend, maar een mogelijke toevoeging aan de code kan een IF zijn statement om elke vergelijkingswaarde die groter is dan 2 . uit te filteren .
Het is misschien vermeldenswaard dat de fonetische waarden zelf niet in de database worden opgeslagen. Dit komt omdat ze worden berekend als onderdeel van de Python-code en het is niet echt nodig om deze ergens op te slaan, omdat ze worden weggegooid wanneer het programma wordt afgesloten, maar een ontwikkelaar kan er waarde aan hechten deze in de database op te slaan en vervolgens de vergelijking te implementeren functie binnen de database een opgeslagen procedure. Het enige grote nadeel hiervan is echter een verlies van codeportabiliteit.
Laatste gedachten over het opvragen van gegevens op geluid met Python
Het vergelijken van gegevens op geluid lijkt niet de "liefde" of aandacht te krijgen die het vergelijken van gegevens door middel van beeldanalyse kan krijgen, maar als een toepassing te maken heeft met meerdere gelijkaardig klinkende varianten van woorden in meerdere talen, kan het een cruciaal nuttig hulpmiddel zijn. hulpmiddel. Een handige eigenschap van dit type analyse is dat een ontwikkelaar geen taalkundige of fonetische expert hoeft te zijn om van deze tools gebruik te kunnen maken. De ontwikkelaar heeft ook een grote flexibiliteit bij het definiëren hoe dergelijke gegevens kunnen worden vergeleken; de vergelijkingen kunnen worden aangepast op basis van de behoeften van de toepassing of bedrijfslogica.
Hopelijk zal dit vakgebied meer aandacht krijgen in de onderzoekssfeer en zullen er in de toekomst meer capabele en robuuste analysetools zijn.