Inleiding
In SQL Server 2012 kon gegroepeerde (vector) aggregatie gebruik maken van parallelle batch-modus uitvoering, maar alleen voor de gedeeltelijke (per-thread) aggregatie. Het bijbehorende globale aggregaat liep altijd in rijmodus, na een Repartition Streams ruilen.
SQL Server 2014 heeft de mogelijkheid toegevoegd om parallelle batch-modus gegroepeerde aggregatie uit te voeren binnen een enkele Hash Match Aggregate exploitant. Dit elimineerde onnodige rijmodusverwerking en maakte een uitwisseling overbodig.
SQL Server 2016 introduceerde seriële batch-modusverwerking en aggregate pushdown . Wanneer pushdown succesvol is, wordt aggregatie uitgevoerd binnen de Columnstore Scan operator zelf, mogelijk direct werkend op gecomprimeerde gegevens, en profiterend van SIMD CPU-instructies.
De prestatieverbeteringen die mogelijk zijn met geaggregeerde pushdown kunnen zeer aanzienlijk zijn. De documentatie somt enkele van de voorwaarden op die nodig zijn om pushdown te bereiken, maar er zijn gevallen waarin het ontbreken van 'lokaal geaggregeerde rijen' niet volledig kan worden verklaard uit die details alleen.
Dit artikel behandelt aanvullende factoren die van invloed zijn op de geaggregeerde pushdown voor GROUP BY alleen zoekopdrachten . Scalaire aggregatie pushdown (aggregatie zonder een GROUP BY clausule), filter pushdown en expressie pushdown kunnen in een toekomstig bericht worden behandeld.
Columnstore-opslag
Het eerste wat je moet zeggen is dat geaggregeerde pushdown alleen van toepassing is op gecomprimeerde gegevens, dus rijen in een delta store komen niet in aanmerking. Verder kan pushdown afhankelijk zijn van het type compressie dat wordt gebruikt. Om dit te begrijpen, is het noodzakelijk om eerst op hoog niveau te bekijken hoe columnstore-opslag werkt:
Een gecomprimeerde rijgroep bevat een kolomsegment voor elke kolom. De onbewerkte kolomwaarden zijn gecodeerd in een geheel getal van 4 bytes of 8 bytes met behulp van waarde of woordenboek codering.
Waardecodering kan het aantal bits dat nodig is voor opslag verminderen door onbewerkte waarden te vertalen met behulp van een basisoffset en magnitude-modifier. De waarden {1100, 1200, 1300} kunnen bijvoorbeeld worden opgeslagen als (0, 1, 2) door eerst te schalen met een factor 0,01 om {11, 12, 13} te geven en vervolgens te herbaseren op 11 om {0, 1, 2}.
Woordenboekcodering wordt gebruikt wanneer er dubbele waarden zijn. Het kan worden gebruikt met niet-numerieke gegevens. Elke unieke waarde wordt opgeslagen in een woordenboek en krijgt een geheel getal-ID toegewezen. De segmentgegevens verwijzen dan naar ID-nummers in het woordenboek in plaats van naar de oorspronkelijke waarden.
Na codering kunnen segmentgegevens verder worden gecomprimeerd met behulp van run-length codering (RLE) en bit-packing:
RLE vervangt herhalende elementen met de gegevens en het aantal herhalingen, bijvoorbeeld {1, 1, 1, 1, 1, 2, 2, 2} kan worden vervangen door {5×1, 3×2}. RLE-ruimtebesparingen nemen toe met de lengte van de herhalende runs. Korte runs kunnen contraproductief zijn.
Bit-packing slaat de binaire vorm van de gegevens op in een zo smal mogelijk gemeenschappelijk venster. De getallen {7, 9, 15} worden bijvoorbeeld opgeslagen in binaire (single-byte voor spatie) gehele getallen als {00000111, 00001001, 00001111}. Het inpakken van deze bits in een vast vier-bits venster geeft de stream {011110011111}. Als u weet dat er een vaste venstergrootte is, is er geen scheidingsteken nodig.
Codering en compressie zijn afzonderlijke stappen, dus RLE en bit-packing worden toegepast op het resultaat van waardecodering of woordenboekcodering van de onbewerkte gegevens. Verder kunnen gegevens binnen hetzelfde kolomsegment een mengsel . hebben van RLE en bit-packing compressie. RLE-gecomprimeerde gegevens worden puur genoemd , en bit-verpakte gecomprimeerde gegevens worden onzuiver . genoemd . Een kolomsegment kan zowel zuivere als onzuivere gegevens bevatten.
De ruimtebesparing die kan worden bereikt door codering en compressie, kan afhankelijk zijn van de bestelling. Alle kolomsegmenten binnen een rijgroep moeten impliciet op dezelfde manier worden gesorteerd, zodat SQL Server op efficiënte wijze volledige rijen uit de kolomsegmenten kan reconstrueren. Wetende dat rij 123 op dezelfde positie (123) in elk kolomsegment is opgeslagen, betekent dat het rijnummer niet hoeft te worden opgeslagen.
Een nadeel van deze regeling is dat een algemene sorteervolgorde moet worden gekozen voor alle kolomsegmenten in een rijgroep. Een bepaalde volgorde past misschien heel goed in de ene kolom, maar mist belangrijke kansen in andere kolommen. Dit is het duidelijkst het geval bij RLE-compressie. SQL Server gebruikt Vertipaq-technologie om een goede manier te bepalen om kolommen in elke rijgroep te sorteren om een goed algemeen compressieresultaat te krijgen.
SQL Server gebruikt momenteel alleen RLE binnen een kolomsegment wanneer er een minimum van 64 . is aaneengesloten herhalende waarden. De overige waarden in het segment zijn bit-packed. Zoals opgemerkt, hangt het af van de volgorde die voor de rijgroep is gekozen of herhalende waarden als aaneengesloten worden weergegeven in een kolomsegment.
SQL Server ondersteunt gespecialiseerde SIMD bit uitpakken voor bitbreedtes van 1 tot en met 10, 12 en 21 bits. SQL Server kan ook standaard gehele grootten gebruiken, b.v. 16, 32 en 64 bits met bit-packing. Deze nummers zijn gekozen omdat ze goed passen in een 64-bits eenheid. Eén eenheid kan bijvoorbeeld drie 21-bits subeenheden bevatten, of 5 12-bits subeenheden. SQL Server niet een 64-bits grens overschrijden bij het inpakken van bits.
SIMD gebruikt 256-bits registers wanneer de processor AVX2-instructies ondersteunt, en 128-bits registers wanneer SSE4.2-instructies beschikbaar zijn. Anders kan uitpakken zonder SIMD worden gebruikt.
Gegroepeerde geaggregeerde pushdown-voorwaarden
De meeste abonnementen met een Hash Match Aggregate operator direct boven een Columnstore Scan de operator komt mogelijk in aanmerking voor gegroepeerde geaggregeerde pushdown, onder voorbehoud van de algemene voorwaarden vermeld in de documentatie.
Extra filters en expressies kunnen soms ook worden toegevoegd zonder gegroepeerde geaggregeerde pushdown te voorkomen. De algemene regel is dat het filter of de expressie ook in staat moet zijn om te pushen (hoewel compatibele expressies nog steeds kunnen verschijnen in een aparte Compute Scalar ). Zoals opgemerkt in de inleiding, kunnen deze aspecten in afzonderlijke artikelen in detail worden behandeld.
Er is momenteel niets in de uitvoeringsplannen dat aangeeft of een bepaald aggregaat als algemeen compatibel werd beschouwd met gegroepeerde aggregaat pushdown of niet. Toch, wanneer het plan in het algemeen in aanmerking komt voor gegroepeerde geaggregeerde pushdown zijn zowel pushdown (snel) als niet-pushdown (langzaam) codepaden beschikbaar.
Elke scanuitvoerbatch (van maximaal 900 rijen) maakt een runtimebeslissing tussen de snelle en langzame codepaden. Door deze flexibiliteit kunnen zoveel mogelijk batches profiteren van pushdown. In het ergste geval zullen geen batches tijdens runtime het snelle pad gebruiken, ondanks een 'algemeen compatibel' plan.
Het uitvoeringsplan toont het resultaat van snelle pushdown-verwerking als 'lokaal geaggregeerde rijen' zonder corresponderende rij-uitvoer van de scan. Slow-path batches verschijnen zoals gewoonlijk als uitvoerrijen van de columnstore-scan, waarbij de aggregatie wordt uitgevoerd door een afzonderlijke operator in plaats van bij de scan.
Een enkele combinatie van gegroepeerd aggregaat en scan kan sommige batches op het snelle pad en andere op het langzame pad sturen, dus het is perfect mogelijk om enkele, maar niet alle, rijen lokaal geaggregeerd te zien. Wanneer de pushdown van gegroepeerd aggregaat succesvol is, bevat elke uitvoerbatch van de scan groeperingssleutels en een gedeeltelijk aggregaat dat de rijen vertegenwoordigt die bijdragen.
Gedetailleerde controles
Er zijn een aantal runtime-controles om te bepalen of pushdown-verwerking kan worden gebruikt. Onder de licht gedocumenteerde controles zijn:
- Er mag geen mogelijkheid zijn tot een geaggregeerde overloop .
- Elke onzuivere (bit-packed) groeperingssleutels moet niet breder zijn dan 10 bits . Pure (RLE-gecodeerde) groeperingssleutels worden behandeld als een onzuivere breedte van nul, dus deze vormen meestal weinig obstakels.
- Pushdown-verwerking moet de moeite waard blijven , met behulp van een 'voordeelmaat' die aan het einde van elke outputbatch wordt bijgewerkt.
De mogelijkheid van geaggregeerde overloop wordt voor elke batch conservatief beoordeeld op basis van het type aggregaat, het type resultaatgegevens, de huidige partiële aggregatiewaarden en informatie over de invoergegevens. SQL Server kent bijvoorbeeld minimum- en maximumwaarden van segmentmetadata zoals weergegeven in de DMV sys.column_store_segments . Als er een risico op overflow bestaat, zal de batch een langzame padverwerking gebruiken. Dit is meestal een risico voor de SUM aggregaat.
De beperking op onzuivere groeperingssleutelbreedte is het benadrukken waard. Het is alleen van toepassing op kolommen in de GROUP BY clausule die daadwerkelijk in het uitvoeringsplan worden gebruikt als basis voor groepering. Deze sets zijn niet altijd precies hetzelfde omdat de optimizer de vrijheid heeft om overbodige groeperingskolommen te verwijderen of om op een andere manier aggregaten te herschrijven, zolang de uiteindelijke queryresultaten maar gegarandeerd overeenkomen met de oorspronkelijke queryspecificatie. Als er een verschil is, zijn het de groeperingskolommen die in het uitvoeringsplan worden weergegeven.
De grotere moeilijkheid is om te weten of een van de groeperingskolommen is opgeslagen met bit-packing, en zo ja, welke breedte is gebruikt. Het zou ook handig zijn om te weten hoeveel waarden zijn gecodeerd met RLE. Deze informatie kan in de column_store_segments . staan DMV, maar dat is vandaag niet het geval. Voor zover ik weet, is er momenteel geen gedocumenteerde manier om bit-packing en RLE-informatie uit metadata te halen. Dat laat ons achter met het zoeken naar ongedocumenteerde alternatieven.
RLE- en bit-packing-informatie zoeken
De ongedocumenteerde DBCC CSINDEX kan ons de informatie geven die we nodig hebben. Traceringsvlag 3604 moet zijn ingeschakeld om deze opdracht uitvoer te laten produceren op het tabblad SSMS-berichten. Gegeven informatie over het kolomsegment waarin we geïnteresseerd zijn, retourneert dit commando:
- Segmentkenmerken (vergelijkbaar met
column_store_segments) - RLE-informatie
- Bladwijzers in RLE-gegevens
- Bitpack-informatie
Omdat ze niet zijn gedocumenteerd, zijn er een paar eigenaardigheden (zoals het toevoegen van een aan kolom-ID's voor geclusterde columnstore, maar niet voor niet-geclusterde columnstore), en zelfs een paar kleine fouten. U mag het nergens op gebruiken, behalve op een persoonlijk testsysteem. Hopelijk zal er op een dag een ondersteunde methode worden geboden om toegang te krijgen tot deze gegevens.
Voorbeelden
De beste manier om DBCC CSINDEX . weer te geven en om de punten die tot nu toe in deze tekst zijn gemaakt te demonstreren, is door enkele voorbeelden te werken. De scripts die volgen gaan ervan uit dat er een tabel is met de naam dbo.Numbers in de huidige database die gehele getallen bevat van 1 tot minimaal 16.384. Hier is een script om mijn standaardversie van deze tabel te maken met tien miljoen gehele getallen:
IF OBJECT_ID(N'dbo.Numbers', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Numbers;
END;
GO
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1
)
SELECT
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten AS T10
CROSS JOIN Ten AS T100
CROSS JOIN Ten AS T1000
CROSS JOIN Ten AS T10000
CROSS JOIN Ten AS T100000
CROSS JOIN Ten AS T1000000
CROSS JOIN Ten AS T10000000
ORDER BY n
OFFSET 0 ROWS
FETCH FIRST 10 * 1000 * 1000 ROWS ONLY
OPTION
(MAXDOP 1);
GO
ALTER TABLE dbo.Numbers
ADD CONSTRAINT [PK dbo.Numbers n]
PRIMARY KEY CLUSTERED (n)
WITH
(
SORT_IN_TEMPDB = ON,
MAXDOP = 1,
FILLFACTOR = 100
);
De voorbeelden gebruiken allemaal dezelfde basistesttabel:De eerste kolom c1 bevat een uniek nummer voor elke rij. De tweede kolom c2 wordt gevuld met een aantal duplicaten voor elk van een klein aantal verschillende waarden.
Na de gegevenspopulatie wordt een geclusterde columnstore-index gemaakt, zodat alle testgegevens in een enkele gecomprimeerde rijgroep terechtkomen (geen deltastore). Het is gebouwd ter vervanging van een b-tree geclusterde index op kolom c2 om het VertiPaq-algoritme aan te moedigen om in een vroeg stadium na te denken over het nut van sorteren op die kolom. Dit is de basis testopstelling:
USE Sandpit;
GO
DROP TABLE IF EXISTS dbo.Test;
GO
CREATE TABLE dbo.Test
(
c1 integer NOT NULL,
c2 integer NOT NULL
);
GO
DECLARE
@values integer = 512,
@dupes integer = 63;
INSERT dbo.Test
(c1, c2)
SELECT
N.n,
N.n % @values
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND @values * @dupes;
GO
-- Encourage VertiPaq
CREATE CLUSTERED INDEX CCSI ON dbo.Test (c2);
GO
CREATE CLUSTERED COLUMNSTORE INDEX CCSI
ON dbo.Test
WITH (MAXDOP = 1, DROP_EXISTING = ON);
De twee variabelen zijn voor het aantal verschillende waarden dat moet worden ingevoegd in kolom c2 , en het aantal duplicaten voor elk van die waarden.
De testquery is een zeer eenvoudige gegroepeerde COUNT_BIG aggregatie met behulp van kolom c2 als de sleutel:
-- The test query
SELECT
T.c2,
numrows = COUNT_BIG(*)
FROM dbo.Test AS T
GROUP BY
T.c2;
Columnstore-indexinformatie wordt weergegeven met DBCC CSINDEX na elke uitvoering van de testquery:
DECLARE
@dbname sysname = DB_NAME(),
@objectid integer = OBJECT_ID(N'dbo.Test', N'U');
DECLARE
@rowsetid bigint =
(
SELECT
P.hobt_id
FROM sys.partitions AS P
WHERE
P.[object_id] = @objectid
AND P.index_id = 1
AND P.partition_number = 1
),
@rowgroupid integer = 0,
@columnid integer =
COLUMNPROPERTY(@objectid, N'c2', 'ColumnId') + 1;
DBCC CSINDEX
(
@dbname,
@rowsetid,
@columnid,
@rowgroupid,
1, -- show segment data
2, -- print option
0, -- start bitpack unit (inclusive)
2 -- end bitpack unit (exclusive)
); Er zijn tests uitgevoerd op de nieuwste versie van SQL Server die beschikbaar was op het moment van schrijven:Microsoft SQL Server 2017 RTM-CU13-OD build 14.0.3049 Developer Edition (64-bit) op Windows 10 Pro. Het zou ook prima moeten werken met de nieuwste build van SQL Server 2016.
Test 1:Pushdown, 9-bits onzuivere sleutels
Deze test gebruikt het populatiescript voor testgegevens precies zoals hierboven beschreven, en produceert een tabel met 32.256 rijen. Kolom c1 bevat getallen van 1 tot 32.256.
Kolom c2 bevat 512 verschillende waarden van 0 tot en met 511. Elke waarde in c2 is 63 keer gedupliceerd , maar ze verschijnen niet als aaneengesloten blokken wanneer ze worden bekeken in c1 volgorde; ze doorlopen 63 keer de waarden 0 tot 511.
Gezien de voorgaande discussie, verwachten we dat SQL Server de c2 . opslaat kolomgegevens met:
- Woordenboekcodering aangezien er een aanzienlijk aantal dubbele waarden is.
- Geen RLE . Het aantal duplicaten (63) per waarde bereikt niet de drempel van 64 die vereist is voor RLE.
- Bitverpakkingsmaat 9 . De 512 verschillende woordenboekitems passen precies in 9 bits (2^9 =512). Elke 64-bits eenheid bevat maximaal zeven 9-bits subeenheden.
Dit wordt allemaal als correct bevestigd met behulp van de DBCC CSINDEX vraag:
De Segmentkenmerken gedeelte van de uitvoer toont woordenboekcodering (type 2; de waarden voor encodingType zijn zoals gedocumenteerd op sys.column_store_segments ).
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =511
NullValue =-1 OnDiskSize =37944 Rijtelling =32256
De RLE-sectie toont geen RLE-gegevens , alleen een aanwijzer naar het bit-verpakte gebied en een lege invoer voor waarde nul:
RLE-koptekst:
Lobtype =3 RLE-arraytelling (in termen van oorspronkelijke eenheden) =2
RLE-arrayinvoergrootte =8
RLE-gegevens:
Index =0 Bitpack Array Index =0 Aantal =32256
Index =1 Waarde =0 Aantal =0
De Bitpack-gegevenskop sectie toont bitpackgrootte 9 en 4.608 bitpack-eenheden gebruikt:
Bitpack-gegevenskoptekst:
Bitpack Entry Size =9 Bitpack Unit Count =4608 Bitpack MinId =3
Bitpack DataSize =36864
De Bitpack-gegevens sectie toont de waarden die zijn opgeslagen in de eerste twee bitpack-eenheden zoals gevraagd door de laatste twee parameters voor de DBCC CSINDEX opdracht. Bedenk dat elke 64-bits eenheid 7 subeenheden kan bevatten (genummerd 0 tot 6) van elk 9 bits (7 x 9 =63 bits). De 4.608 eenheden bevatten in totaal 4.608 * 7 =32.256 rijen:
Unit 0 SubUnit 0 =383
Unit 0 SubUnit 1 =255
Unit 0 SubUnit 2 =127
Unit 0 SubUnit 3 =510
Unit 0 SubUnit 4 =381
Unit 0 SubUnit 5 =253
Unit 0 SubUnit 6 =125
Unit 1 SubUnit 0 =508
Unit 1 SubUnit 1 =379
Unit 1 SubUnit 2 =251
Unit 1 SubUnit 3 =123
Unit 1 SubUnit 4 =506
Unit 1 SubUnit 5 =377
Unit 1 SubUnit 6 =249
Aangezien de groeperingssleutels bit-packing gebruiken met een maat kleiner dan of gelijk aan 10 , we verwachten gegroepeerde geaggregeerde pushdown om hier te werken. Het uitvoeringsplan laat inderdaad zien dat alle rijen lokaal zijn geaggregeerd bij de Columnstore Index Scan operator:

De xml van het abonnement bevat ActualLocallyAggregatedRows="32256" in de runtime-informatie voor de indexscan.
Test 2:geen pushdown, 12-bits onzuivere sleutels
Deze test verandert de @values parameter naar 1025, met behoud van @dupes op 63. Dit geeft een tabel van 64.575 rijen, met 1.025 verschillende waarden in kolom c2 loopt van 0 tot en met 1024. Elke waarde in c2 is 63 keer gedupliceerd .
SQL Server slaat de c2 . op kolomgegevens met:
- Woordenboekcodering aangezien er een aanzienlijk aantal dubbele waarden is.
- Geen RLE . Het aantal duplicaten (63) per waarde bereikt niet de drempel van 64 die vereist is voor RLE.
- Bit-packed met maat 12 . De 1.025 verschillende woordenboekitems passen niet helemaal in 10 bits (2 ^ 10 =1.024). Ze zouden in 11 bits passen, maar SQL Server ondersteunt die bitverpakkingsgrootte niet zoals eerder vermeld. De volgende kleinste grootte is 12 bits. Door 64-bits eenheden met harde randen te gebruiken voor bit-packing, konden er niet meer 11-bits subeenheden in 64 bits passen dan 12-bits subeenheden. Hoe dan ook, er passen 5 subeenheden in een 64-bits eenheid.
De DBCC CSINDEX output bevestigt de bovenstaande analyse:
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1024
NullValue =-1 OnDiskSize =104400 Rijtelling =64575
RLE-koptekst:
Lob-type =3 RLE-arraytelling (in termen van native units) =2
RLE-array-invoergrootte =8
RLE-gegevens:
Index =0 Bitpack Array Index =0 Aantal =64575
Index =1 Waarde =0 Aantal =0
Bitpack-gegevenskoptekst:
Bitpack-invoergrootte =12 Bitpack-eenheidtelling =12915 Bitpack MinId =3
Bitpack-gegevensgrootte =103320
Bitpack-gegevens:
Unit 0 SubUnit 0 =767
Unit 0 SubUnit 1 =510
Unit 0 SubUnit 2 =254
Unit 0 SubUnit 3 =1021
Unit 0 SubUnit 4 =765
Unit 1 SubUnit 0 =507
Unit 1 SubUnit 1 =250
Unit 1 SubUnit 2 =1019
Unit 1 SubUnit 3 =761
Unit 1 SubUnit 4 =505
Sinds de onzuivere groeperingssleutels hebben een grootte groter dan 10 , we verwachten gegroepeerde geaggregeerde pushdown niet werken hier. Dit wordt bevestigd door het uitvoeringsplan met nul rijen lokaal geaggregeerd bij de Columnstore Index Scan operator:
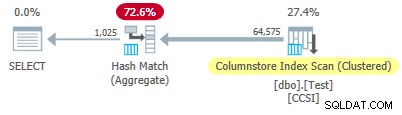
Alle 64.575 rijen worden verzonden (in batches) door de Columnstore Index Scan en geaggregeerd in batchmodus door de Hash Match Aggregate exploitant. De ActualLocallyAggregatedRows kenmerk ontbreekt in de runtime-informatie van het xml-plan voor de indexscan.
Test 3:Pushdown, Pure Keys
Deze test verandert de @dupes parameter van 63 tot 64 om RLE toe te staan. De @values parameter is gewijzigd in 16.384 (het maximum voor het totale aantal rijen om nog steeds in een enkele rijgroep te passen). Het exacte aantal gekozen voor @values is niet belangrijk — het gaat erom 64 duplicaten van elke unieke waarde te genereren, zodat RLE kan worden gebruikt.
SQL Server slaat de c2 . op kolomgegevens met:
- Woordenboekcodering vanwege de dubbele waarden.
- RLE. Gebruikt voor elke afzonderlijke waarde, aangezien elk de drempel van 64 bereikt.
- Geen bit-packed data . Als die er waren, zou het maat 16 gebruiken. Maat 12 is niet groot genoeg (2^12 =4.096 verschillende waarden) en maat 21 zou verspilling zijn. De 16.384 verschillende waarden zouden in 14 bits passen, maar zoals voorheen passen er niet meer van deze in een 64-bits eenheid dan 16-bits subeenheden.
De DBCC CSINDEX output bevestigt het bovenstaande (slechts een paar RLE-items en bladwijzers getoond om ruimteredenen):
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =16383
NullValue =-1 OnDiskSize =131648 Rijtelling =1048576
RLE-koptekst:
Lobtype =3 RLE-arraytelling (in termen van native units) =16385
RLE-arrayinvoergrootte =8
RLE-gegevens:
Index =0 Waarde =3 Telling =64
Index =1 Waarde =1538 Telling =64
Index =2 Waarde =3072 Telling =64
Index =3 Waarde =4608 Telling =64
Index =4 Waarde =6142 Aantal =64
…
Index =16381 Waarde =8954 Aantal =64
Index =16382 Waarde =10489 Aantal =64
Index =16383 Waarde =12025 Aantal =64
Index =16384 Waarde =0 Aantal =0
Bladwijzerkop:
Aantal bladwijzers =65 Bladwijzerafstand =16384 Bladwijzergrootte =520
Bladwijzergegevens:
Positie =0 Index =64
Positie =512 Index =16448
Positie =1024 Index =32832
…
Positie =31744 Index =1015872
Positie =32256 Index =1032256
Positie =32768 Index =1048577
Bitpack-gegevenskoptekst:
Bitpack Entry Size =16 Bitpack Unit Count =0 Bitpack MinId =3
Bitpack DataSize =0
Aangezien de groeperingssleutels puur zijn (RLE wordt gebruikt), gegroepeerde geaggregeerde pushdown wordt hier verwacht. Het uitvoeringsplan bevestigt dit door alle rijen lokaal geaggregeerd weer te geven bij de Columnstore Index Scan operator:
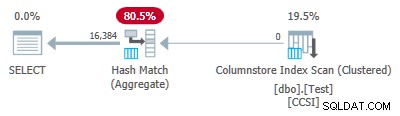
De xml van het abonnement bevat ActualLocallyAggregatedRows="1048576" in de runtime-informatie voor de indexscan.
Test 4:10-bits onzuivere sleutels
Deze test stelt @values in naar 1024 en @dupes tot 63, wat een tabel geeft van 64.512 rijen, met 1024 verschillende waarden in kolom c2 met waarden van 0 tot en met 1.023. Elke waarde in c2 is 63 keer gedupliceerd .
Het belangrijkste , de b-tree geclusterde index wordt nu aangemaakt in kolom c1 in plaats van kolom c2 . De geclusterde columnstore vervangt nog steeds de geclusterde index van b-tree. Dit is het gewijzigde deel van het script:
-- Note column c1 now! CREATE CLUSTERED INDEX CCSI ON dbo.Test (c1); GO CREATE CLUSTERED COLUMNSTORE INDEX CCSI ON dbo.Test WITH (MAXDOP = 1, DROP_EXISTING = ON);
SQL Server slaat de c2 . op kolomgegevens met:
- Woordenboekcodering vanwege de duplicaten.
- Geen RLE . Het aantal duplicaten (63) per waarde bereikt niet de drempel van 64 die vereist is voor RLE.
- Bitverpakking met maat 10 . De 1.024 verschillende woordenboekitems passen precies in 10 bits (2^10 =1.024). In elke 64-bits eenheid kunnen zes subeenheden van elk 10 bits worden opgeslagen.
De DBCC CSINDEX uitvoer is:
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1023
NullValue =-1 OnDiskSize =87096 Rijtelling =64512
RLE-koptekst:
Lob-type =3 RLE-arraytelling (in termen van native units) =2
RLE-array-invoergrootte =8
RLE-gegevens:
Index =0 Bitpack Array Index =0 Aantal =64512
Index =1 Waarde =0 Aantal =0
Bitpack-gegevenskoptekst:
Bitpack-invoergrootte =10 Bitpack-eenheidtelling =10752 Bitpack MinId =3
Bitpack-gegevensgrootte =86016
Bitpack-gegevens:
Unit 0 SubUnit 0 =766
Unit 0 SubUnit 1 =509
Unit 0 SubUnit 2 =254
Unit 0 SubUnit 3 =1020
Unit 0 SubUnit 4 =764
Eenheid 0 SubEenheid 5 =506
Unit 1 SubUnit 0 =250
Unit 1 SubUnit 1 =1018
Unit 1 SubUnit 2 =760
Unit 1 SubUnit 3 =504
Unit 1 SubUnit 4 =247
Eenheid 1 SubEenheid 5 =1014
Sinds de onzuivere groeperingssleutels gebruiken een grootte kleiner dan of gelijk aan 10, we zouden gegroepeerde aggregatie pushdown verwachten om hier te werken. Maar dat is niet wat er gebeurt . Het uitvoeringsplan laat zien dat 54.612 van de 64.512 rijen zijn geaggregeerd op de Hash Match Aggregate operator:
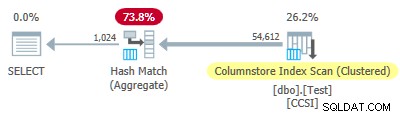
De xml van het abonnement bevat ActualLocallyAggregatedRows="9900" in de runtime-informatie voor de indexscan. Dit betekent gegroepeerde geaggregeerde pushdown werd gebruikt voor 9.900 rijen, maar niet voor de andere 54.612!
Het feedbackmechanisme
SQL Server begon met gegroepeerde geaggregeerde pushdown voor deze uitvoering omdat de onzuivere groeperingssleutels voldeden aan de criteria van 10 bits of minder. Dit duurde in totaal 11 batches (van 900 rijen elk =9.900 rijen totaal). Op dat moment, een feedbackmechanisme dat de effectiviteit meet van gegroepeerde geaggregeerde pushdown besloot dat het niet werkte, en schakelde het uit . De overige batches zijn allemaal verwerkt met pushdown uitgeschakeld.
De feedback vergelijkt in wezen het aantal geaggregeerde rijen met het aantal geproduceerde groepen. Het begint met een waarde van 100 en wordt aangepast aan het einde van elke pushdown-uitvoerbatch. Als de waarde daalt tot 10 of lager, wordt pushdown uitgeschakeld voor de huidige groeperingsbewerking.
De 'pushdown-voordeelmaatregel' wordt min of meer verlaagd, afhankelijk van hoe slecht de geduwde aggregatie-inspanning gaat. Als er gemiddeld minder dan 8 rijen per groeperingssleutel in de uitvoerbatch zijn, wordt de huidige voordeelwaarde met 22% verlaagd. Als er meer dan 8 maar minder dan 16 zijn, wordt de statistiek met 11% verlaagd.
Aan de andere kant, als de zaken verbeteren en er vervolgens 16 of meer rijen per groeperingssleutel worden aangetroffen voor een uitvoerbatch, wordt de statistiek opnieuw ingesteld op 100 en blijft deze worden aangepast omdat er door de scan gedeeltelijke geaggregeerde batches worden geproduceerd.
De gegevens in deze test werden gepresenteerd in een bijzonder nutteloze volgorde voor pushdown vanwege de originele b-tree geclusterde index op kolom c1 . Als ze op deze manier worden gepresenteerd, worden de waarden in kolom c2 beginnen bij 0 en verhogen met 1 totdat ze 1.023 bereiken, dan beginnen ze de cyclus opnieuw. De 1.023 verschillende waarden zijn meer dan genoeg om ervoor te zorgen dat elke uitvoerbatch van 900 rijen slechts één gedeeltelijk geaggregeerde rij voor elke sleutel bevat. Dit is geen gelukkige toestand.
Als er 64 duplicaten per waarde waren geweest in plaats van 63, zou SQL Server hebben overwogen om te sorteren op c2 tijdens het bouwen van de columnstore-index, en produceerde zo RLE-compressie. Zoals het is, treedt de straf van 22% in na elke batch. Beginnend bij 100 en met dezelfde afgeronde gehele rekenkunde, luidt de reeks metrische waarden:
-- @metric := FLOOR(@metric * 0.78 + 0.5); -- 100, 78, 61, 48, 37, 29, 23, 18, 14, 11, *9*
De elfde batch verlaagt de statistiek tot 10 of lager en pushdown is uitgeschakeld. De 11 batches van 900 rijen zijn goed voor de 9.900 lokaal geaggregeerde rijen die worden weergegeven in het uitvoeringsplan.
Variatie met 900 verschillende waarden
Hetzelfde gedrag is te zien in test 4 met slechts 901 verschillende waarden, ervan uitgaande dat de rijen toevallig in dezelfde nutteloze volgorde worden gepresenteerd.
Wijzigen van de @values parameter naar 900 terwijl al het andere hetzelfde blijft, heeft een dramatisch effect op het uitvoeringsplan:
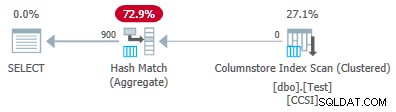
Nu zijn alle 900 groepen geaggregeerd bij de scan! De eigenschappen van het xml-plan tonen ActualLocallyAggregatedRows="56700" . Dit omdat pushdown voor gegroepeerde aggregaties 900 groeperingssleutels en gedeeltelijke aggregaties in één batch onderhoudt. It never encounters a new key value not in the batch, so there is no reason to start a fresh output batch.
Only ever producing one batch means the feedback mechanism never gets chance to reduce the “pushdown benefit measure” to the point where grouped aggregate pushdown is disabled. It never would anyway, since the pushdown is very successful — 56,700 rows for 900 grouping keys is 63 per key, well above the threshold for benefit measure reduction.
Extended Event
There is very little information available in execution plans to help determine why grouped aggregation pushdown was either not tried, or was not successful. There is, however, an Extended Event named query_execution_dynamic_push_down_statistics in the execution category of the Analytic channel.
It provides the following Event Fields:
rows_not_pushed_down_due_to_encoding
Description:Number of rows not pushed to scan because of the the total encoded key length.
This identifies impure data over the 10-bit limit as shown in test 2.
rows_not_pushed_down_due_to_possible_overflow
Description:Number of rows not pushed to scan because of a possible overflow
rows_not_pushed_down_due_to_pushdown_disabled
Description:Number of rows not pushed to scan (only) because dynamic pushdown was disabled
This occurs when the pushdown benefit measure drops below 10 as described in test 4.
rows_pushed_down_in_thread
Description:Number of locally aggregated rows in thread
This corresponds with the value for ‘locally aggregated rows’ shown in execution plans.
Opmerking: No event is recorded if grouped aggregation pushdown is specifically disabled using trace flag 9373. All types of pushdown to a nonclustered columnstore index can be specifically disabled with trace flag 9386. All types of pushdown activity can be disabled with trace flag 9354.