SQL Server 2012 AlwaysOn-beschikbaarheidsgroepen vereisen een database-mirroring-eindpunt voor elk SQL Server-exemplaar dat als host fungeert voor een replica van een beschikbaarheidsgroep en/of database-mirroringsessie. Dit SQL Server-exemplaar-eindpunt wordt vervolgens gedeeld door een of meer replica's van beschikbaarheidsgroepen en/of database-mirroringsessies en is het mechanisme voor communicatie tussen de primaire replica en de bijbehorende secundaire replica's.
Afhankelijk van de workloads voor het wijzigen van gegevens op de primaire replica, kunnen de vereisten voor de doorvoer van berichten voor de beschikbaarheidsgroep niet-triviaal zijn. Deze activiteit is ook gevoelig voor verkeer van gelijktijdige niet-beschikbare groepsactiviteiten. Als de doorvoer te lijden heeft van verminderde bandbreedte en gelijktijdig verkeer, kunt u overwegen het verkeer van de beschikbaarheidsgroep te isoleren naar zijn eigen speciale netwerkadapter voor elk SQL Server-exemplaar dat als host fungeert voor een beschikbaarheidsreplica. In dit bericht wordt dit proces beschreven en wordt ook kort beschreven wat u zou verwachten in een scenario met een verslechterde doorvoer.
Voor dit artikel gebruik ik een virtuele gast Windows Server Failover Cluster (WSFC) met vijf knooppunten. Elk knooppunt in de WSFC heeft zijn eigen zelfstandige SQL Server-instantie die niet-gedeelde lokale opslag gebruikt. Elk knooppunt heeft ook een afzonderlijke virtuele netwerkadapter voor openbare communicatie, een virtuele netwerkadapter voor WSFC-communicatie en een virtuele netwerkadapter die we zullen wijden aan communicatie met beschikbaarheidsgroepen. Voor de doeleinden van dit bericht zullen we ons concentreren op de informatie die nodig is voor de speciale netwerkadapters van de beschikbaarheidsgroep op elk knooppunt:
| WSFC-knooppuntnaam | Beschikbaarheidsgroep NIC TCP/IPv4-adressen |
|---|---|
| SQL2K12-SVR1 | 192.168.20.31 |
| SQL2K12-SVR2 | 192.168.20.32 |
| SQL2K12-SVR3 | 192.168.20.33 |
| SQL2K12-SVR4 | 192.168.20.34 |
| SQL2K12-SVR5 | 192.168.20.35 |
Het opzetten van een beschikbaarheidsgroep met behulp van een speciale NIC is bijna identiek aan een gedeeld NIC-proces, alleen om de beschikbaarheidsgroep te "binden" aan een specifieke NIC, moet ik eerst de LISTENER_IP aanwijzen argument in het CREATE ENDPOINT commando, met behulp van de bovengenoemde IP-adressen voor mijn speciale NIC's. Hieronder ziet u de creatie van elk eindpunt over de vijf WSFC-knooppunten:
:CONNECT SQL2K12-SVR1
USE [master];
GO
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022, LISTENER_IP = (192.168.20.31))
FOR DATA_MIRRORING (ROLE = ALL, ENCRYPTION = REQUIRED ALGORITHM AES);
GO
IF (SELECT state FROM sys.endpoints WHERE name = N'Hadr_endpoint') <> 0
BEGIN
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
END
GO
USE [master];
GO
GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [SQLSKILLSDEMOS\SQLServiceAcct];
GO
:CONNECT SQL2K12-SVR2
-- ...repeat for other 4 nodes... Na het maken van deze eindpunten die zijn gekoppeld aan de speciale NIC, zijn de rest van mijn stappen bij het instellen van de topologie van de beschikbaarheidsgroep niet anders dan in een gedeeld NIC-scenario.
Nadat ik mijn beschikbaarheidsgroep heb gemaakt, kan ik, als ik de belasting van gegevensmodificatie begin tegen de primaire replicabeschikbaarheidsdatabases, snel zien dat het communicatieverkeer van de beschikbaarheidsgroep op de speciale NIC stroomt met behulp van Taakbeheer op het netwerktabblad (de eerste sectie is de doorvoer voor de speciale beschikbaarheidsgroep NIC):
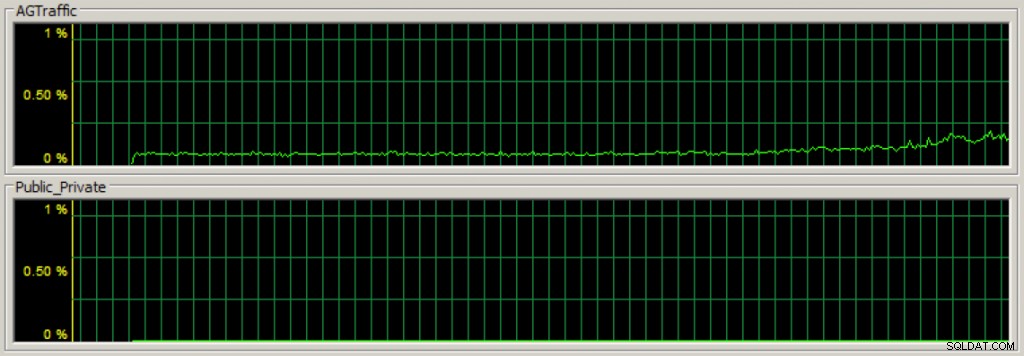
En ik kan de statistieken ook volgen met behulp van verschillende prestatiemeters. In de onderstaande afbeelding is de Inetl[R] PRO_1000 MT-netwerkverbinding _2 mijn speciale beschikbaarheidsgroep-NIC en heeft deze het grootste deel van het NIC-verkeer vergeleken met de twee andere NIC's:

Het hebben van een speciale NIC voor verkeer van beschikbaarheidsgroepen kan een manier zijn om activiteit te isoleren en theoretisch de prestaties te verbeteren, maar als uw speciale NIC onvoldoende bandbreedte heeft, zoals u zou verwachten, zullen de prestaties eronder lijden en de gezondheid van de beschikbaarheidsgroeptopologie verslechteren.
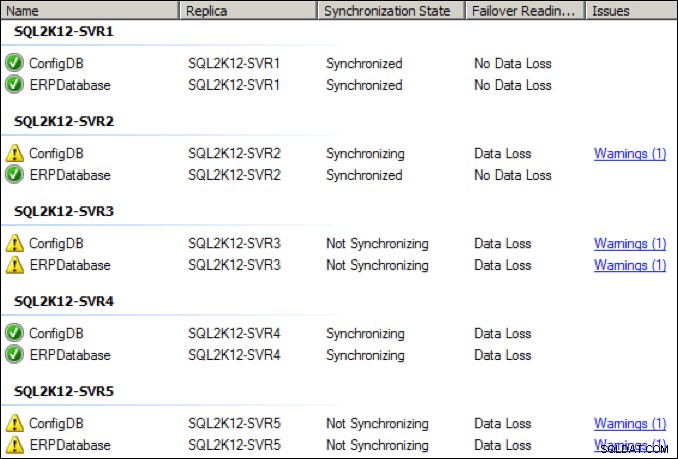
Ik heb bijvoorbeeld de speciale beschikbaarheidsgroep NIC op de primaire replica gewijzigd in een uitgaande overdrachtsbandbreedte van 28,8 Kbps om te zien wat er zou gebeuren. Onnodig te zeggen dat het niet goed was. De doorvoer van de NIC-beschikbaarheidsgroep is aanzienlijk gedaald:

Binnen een paar seconden verslechterde de gezondheid van de verschillende replica's, waarbij een paar replica's naar een "niet-synchroniserende" status gingen:
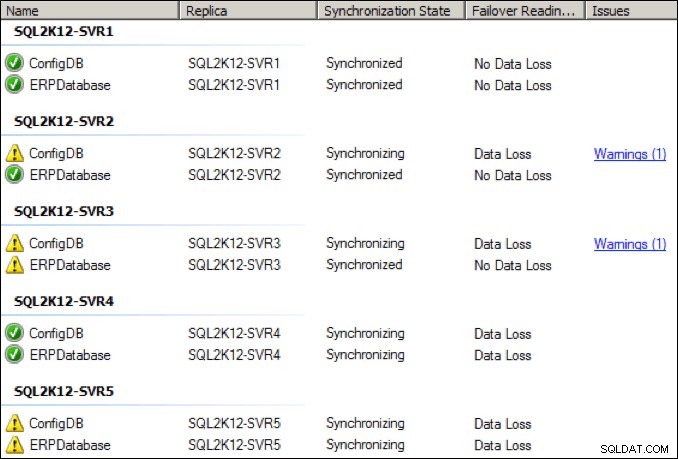
Ik heb de speciale NIC op de primaire replica verhoogd tot 64 Kbps en na een paar seconden was er ook een aanvankelijke inhaalpiek:

Hoewel de zaken verbeterden, was ik getuige van periodieke verbroken verbindingen en gezondheidswaarschuwingen bij deze lagere NIC-doorvoerinstelling:
Hoe zit het met de bijbehorende wachtstatistieken op de primaire replica?
Toen er voldoende bandbreedte was op de speciale NIC en alle beschikbaarheidsreplica's in goede staat waren, zag ik de volgende verdeling tijdens het laden van gegevens gedurende een periode van 2 minuten:
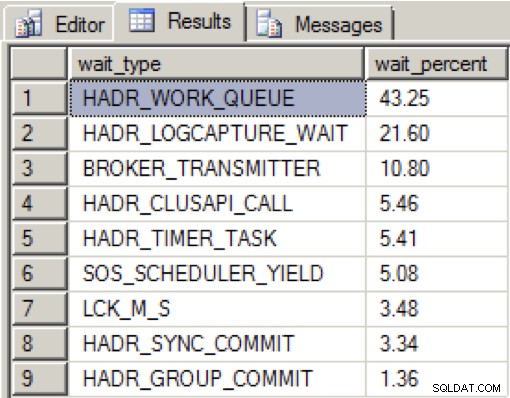
HADR_WORK_QUEUE vertegenwoordigt een verwachte achtergrondwerkthread die wacht op nieuw werk. HADR_LOGCAPTURE_WAIT staat voor een andere verwachte wachttijd tot nieuwe logrecords beschikbaar komen en volgens Books Online wordt dit verwacht als de logscan wordt ingehaald of van schijf wordt gelezen.
Toen ik de doorvoer van de NIC voldoende verminderde om de beschikbaarheidsgroep in een ongezonde staat te krijgen, was de distributie van het wachttype als volgt:
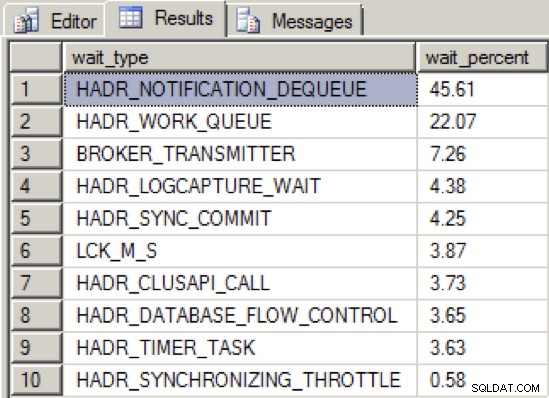
We zien nu een nieuw type topwacht, HADR_NOTIFICATION_DEQUEUE . Dit is een van die wachttypes voor "alleen voor intern gebruik", zoals gedefinieerd door Books Online, die een achtergrondtaak vertegenwoordigt die WSFC-meldingen verwerkt. Wat interessant is, is dat dit type wacht niet direct op een probleem wijst, en toch tonen de tests aan dat dit type wacht naar de top stijgt in combinatie met een verminderde doorvoer van groepsberichten voor beschikbaarheid.
Dus het komt erop neer dat het isoleren van uw beschikbaarheidsgroepsactiviteit naar een speciale NIC nuttig kan zijn als u een netwerkdoorvoer met voldoende bandbreedte biedt. Als u echter geen goede bandbreedte kunt garanderen, zelfs niet met een speciaal netwerk, zal de gezondheid van uw beschikbaarheidsgroeptopologie eronder lijden.