De namen van IRI-softwareproducten en hoe ze werken, waren soms een bron van mysterie of zelfs verwarring voor niet-ingewijden. Dit artikel beschrijft de onderdelen en verduidelijkt hun wisselwerking, en biedt een snelle inleiding voor potentiële gebruikers, partners en analisten van nieuwe bedrijfstakken st.
Waar het allemaal begon
Het begon met IRI CoSort in 1978, het hulpprogramma voor het sorteren, transformeren en rapporteren van big data voor Unix en Windows dat nog steeds veel wordt gebruikt. Voorafgaand aan CoSort heette dit eerste IRI-product CO-SORT, COSORT en CoSORT, in die volgorde.

In 1992 voegde IRI de Sort Control Language (SortCL) datadefinitiesyntaxis en manipulatieprogramma toe aan de andere hulpprogramma's en API's in het CoSort-pakket. Vandaag de dag is SortCL de meest gebruikte gebruikersinterface met veel functies in het CoSort-pakket.
SortCL-scripts definiëren en het sortcl-programma voert de taken uit die veel algemene gegevensverplaatsing en mappingtaken uitvoeren en combineren die CoSort-gebruikers moeten uitvoeren. SortCL is niet alleen een eenvoudige 4GL om te leren, lezen en wijzigen, maar het wordt ook ondersteund via een API (sortcl_routine genaamd) en grafisch in de gratis IRI Workbench IDE, gebouwd op Eclipse.
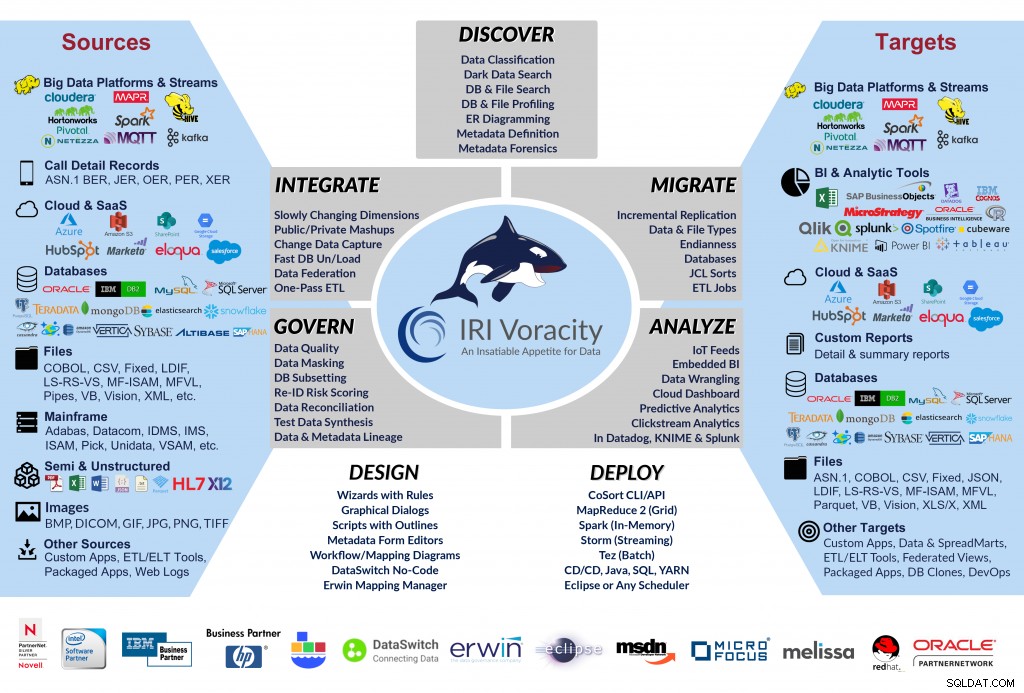
Naarmate de SortCL-functionaliteit uitbreidde, ontgroeide het de traditionele CoSort-markt voor sorteermigraties en BI/DW-versnelling. Tegenwoordig is het uitvoerbare SortCL-bestand niet alleen de motor die de meeste CoSort-taken uitvoert, maar het is het kloppende hart van verschillende spin-offproducten, hier geïllustreerd:

CoSort / SortCL spin-off producten
In het bijzonder verwerken dezelfde SortCL-engine en compatibele jobscripts - meestal ontworpen en vaak beheerd vanuit IRI Workbench, gestructureerde gegevensbronnen in:
- IRI FieldShield en IRI DarkShield voor gegevensmaskering
- IRI RowGen voor synthese van testgegevens en subsetting van databases
- IRI NextForm voor data- en databaseconversie en replicatie en de
- IRI Voracity-gegevensbeheerplatformtaken, waaronder die in CoSort en de hierboven gelinkte producten, plus extra front-end mogelijkheden via de gemeenschappelijke Workbench GUI, zoals:
- Gegevensontdekking (profilering, classificatie en zoeken)
- Datawarehouse ETL, CDC en SDC
- Data Vault 2.0-migratie en prototyping
- Gegevenskwaliteit (validatie, opschoning, homogenisatie)
- Analytics of data-ruzie voor Splunk en KNIME en andere BI-tools via overdracht
Een andere manier om naar de producthiërarchie te kijken is op deze manier:

waar de Workbench IDE is waar alle IRI-producttaken worden ontworpen - inclusief de extra functies die worden ondersteund in Voracity.
Een veelgestelde vraag
Sinds SortCL met CoSort is begonnen en voor al deze producten hetzelfde is, betekent dit dan dat ik CoSort of een ander product hierboven ook kan gebruiken om te doen wat de andere producten doen?
Het antwoord is ja en nee. Ja, u heeft SortCL en kunt in theorie hetzelfde werk doen dat een ander SortCL-compatibel IRI-product moet doen. Maar het zou moeilijker zijn en vormt een productierisico. IRI biedt alleen documentatie en ondersteuning voor de taken die het beste passen bij uw gelicentieerde IRI-product(en).
Daarom is de crossover-capaciteit in de praktijk beperkt. Desalniettemin is combinatorische functionaliteit in veel gevallen gebruikelijk (zoals een gesorteerde DB-subset), en in Voracity zijn multi-task, multi-step use-cases (zoals incrementele mapping, maskering, opschoning en opnieuw formatteren) zeer efficiënt en volledig ondersteund.
 SortCL is de standaardengine in alle IRI Voracity CDC, ETL, CDC, opschoning, afstemming, subsetting ,
SortCL is de standaardengine in alle IRI Voracity CDC, ETL, CDC, opschoning, afstemming, subsetting ,
PII-maskering, synthese van testgegevens, conversie, opnieuw formatteren, ruziemaken, analyses en rapportagetaken.
Runtime-architectuur
Nu u de namen van de producten kent, gaan we kijken hoe ze met elkaar in verband staan en hoe ze worden geïmplementeerd.
IRI-software werkt meestal in een client/server-model, waarbij SortCL-compatibele taken worden gedefinieerd in een front-end bewerkingsomgeving zoals IRI Workbench of een andere teksteditor, of via de IRI API. Die jobs draaien meestal in het SortCL back-end programma op Linux, Unix of Windows (fysieke of virtuele) machines, on-premise of in de cloud:

Sommige taken die in de SortCL-syntaxis zijn gescript, kunnen ook zonder wijziging rechtstreeks worden uitgevoerd in Map Reduce 2, Spark, Spark Stream, Story of Tez voor licentiehouders van de Voracity Grid (VGrid)-editie voor Hadoop.
Merk echter op dat er, in tegenstelling tot veel andere ETL- en gegevensmaskeringprogramma's, geen CoSort-server is waar SortCL centraal moet draaien of beheerd moet worden. Het lichtgewicht uitvoerbare SortCL-bestand kan overal worden uitgevoerd, van een Raspberry Pi tot een z/Linux-mainframe.

Het is daarom gebruikelijk, volgens het bovenstaande diagram, dat sites test- en QA SortCL-instanties hebben geïnstalleerd op ontwikkelaarslaptops met IRI Workbench, evenals op gecentraliseerde bestands- of databaseservers om de prestaties te optimaliseren. Deze veelgestelde vraag behandelt de vraag waar u SortCL moet licentiëren in de context van bijvoorbeeld IRI-gegevensmaskeringsproducten en hoe u de kosten dienovereenkomstig kunt berekenen.
Neem contact op met uw IRI-vertegenwoordiger als u vragen heeft over welk IRI-product u nodig heeft, of hoe u dit het beste kunt implementeren op de hardware die u heeft (of wilt gaan leveren).