Dit is de derde in een vijfdelige serie die een diepe duik neemt in de manier waarop parallelle plannen in de rijmodus van SQL Server worden uitgevoerd. In deel 1 werd uitvoeringscontext nul geïnitialiseerd voor de bovenliggende taak en in deel 2 werd de query-scanstructuur gemaakt. We zijn nu klaar om de query-scan te starten, een vroege fase uit te voeren verwerken en de eerste extra parallelle taken starten.
Opstarten van queryscan
Bedenk dat alleen de bovenliggende taak bestaat op dit moment, en de beurzen (parallelisme-operators) hebben alleen een consumentenkant. Toch is dit voldoende om de uitvoering van de query te laten beginnen, op de werkthread van de bovenliggende taak. De queryprocessor begint met de uitvoering door het queryscanproces te starten via een aanroep van CQueryScan::StartupQuery . Een herinnering aan het plan (klik om te vergroten):
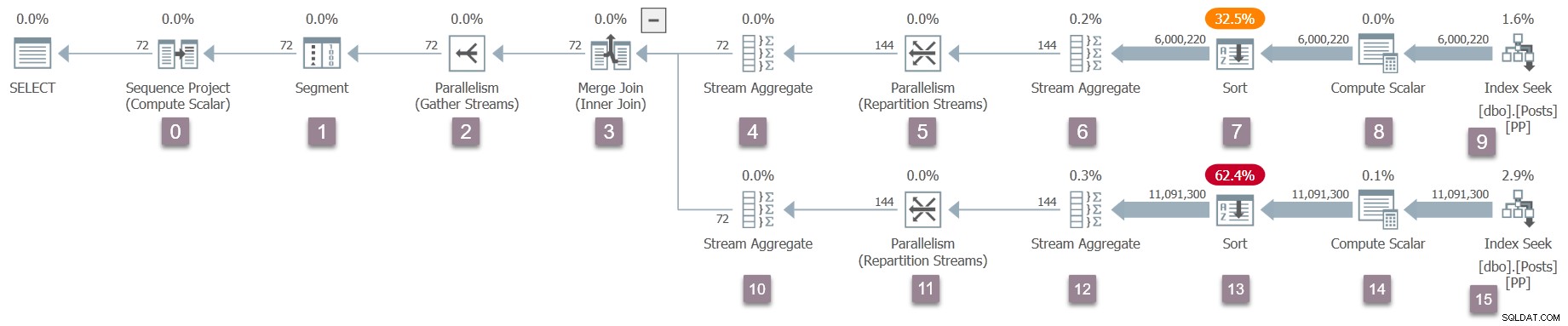
Dit is het eerste punt in het proces tot nu toe dat een uitvoeringsplan tijdens de vlucht is beschikbaar (SQL Server 2016 SP1 en later) in sys.dm_exec_query_statistics_xml . Er is op dit moment niets bijzonders interessants te zien in een dergelijk plan, omdat alle tijdelijke tellers nul zijn, maar het plan is tenminste beschikbaar . Er is geen aanwijzing dat er nog geen parallelle taken zijn gecreëerd, of dat de uitwisselingen geen producentenkant hebben. Het plan ziet er in alle opzichten 'normaal' uit.
Parallel plan-takken
Aangezien dit een parallel plan is, is het handig om het in takken te laten zien. Deze zijn hieronder gearceerd en gelabeld als takken A tot D:
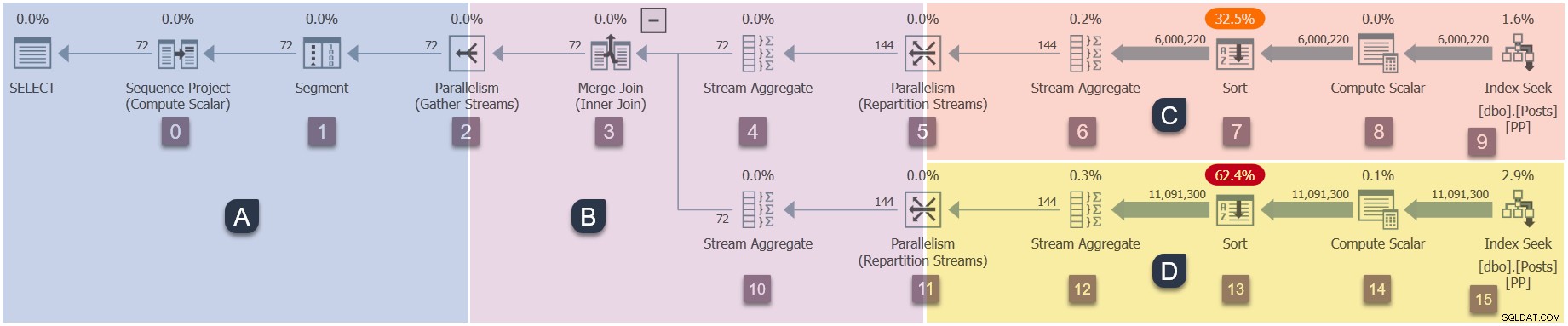
Tak A is gekoppeld aan de bovenliggende taak en wordt uitgevoerd op de werkthread die door de sessie wordt geleverd. Er zullen extra parallelle werkers worden gestart om de extra parallelle taken . uit te voeren vervat in takken B, C en D. Die takken zijn parallel, dus er zullen in elke tak extra DOP-taken en werkers zijn.
Onze voorbeeldquery wordt uitgevoerd op DOP 2, dus branch B krijgt twee extra taken. Hetzelfde geldt voor tak C en tak D, wat een totaal geeft van zes Aanvullende taken. Elke taak wordt uitgevoerd op zijn eigen werkthread in zijn eigen uitvoeringscontext.
Twee planners (S1 en S2 ) zijn toegewezen aan deze query om extra parallelle werkers uit te voeren. Elke extra werknemer wordt uitgevoerd op een van die twee planners. De bovenliggende werknemer kan op een andere planner worden uitgevoerd, dus onze DOP 2-query mag maximaal drie gebruiken processorkernen op elk moment in de tijd.
Om samen te vatten, zal ons plan uiteindelijk het volgende hebben:
- Tak A (ouder)
- Oudertaak.
- Ouderwerker-thread.
- Uitvoeringscontext nul.
- Elke enkele planner die beschikbaar is voor de zoekopdracht.
- Tak B (aanvullend)
- Twee extra taken.
- Een extra werkthread gebonden aan elke nieuwe taak.
- Twee nieuwe uitvoeringscontexten, één voor elke nieuwe taak.
- Eén werkthread wordt uitgevoerd op planner S1 . De andere draait op planner S2 .
- Tak C (aanvullend)
- Twee extra taken.
- Een extra werkthread gebonden aan elke nieuwe taak.
- Twee nieuwe uitvoeringscontexten, één voor elke nieuwe taak.
- Eén werkthread wordt uitgevoerd op planner S1 . De andere draait op planner S2 .
- Tak D (aanvullend)
- Twee extra taken.
- Een extra werkthread gebonden aan elke nieuwe taak.
- Twee nieuwe uitvoeringscontexten, één voor elke nieuwe taak.
- Eén werkthread wordt uitgevoerd op planner S1 . De andere draait op planner S2 .
De vraag is hoe al deze extra taken, werkers en uitvoeringscontexten worden gecreëerd en wanneer ze worden uitgevoerd.
Startvolgorde
De volgorde waarin extra taken begin voor dit specifieke plan uit te voeren is:
- Tak A (bovenliggende taak).
- Branch C (extra parallelle taken).
- Branch D (extra parallelle taken).
- Branch B (extra parallelle taken).
Dat is misschien niet de opstartvolgorde die u verwachtte.
Er kan een aanzienlijke vertraging optreden tussen elk van deze stappen, om redenen die we binnenkort zullen onderzoeken. Het belangrijkste punt in dit stadium is dat de extra taken, werkers en uitvoeringscontexten niet . zijn allemaal tegelijk gemaakt, en dat doen ze niet beginnen allemaal tegelijkertijd met uitvoeren.
SQL Server zou zo kunnen zijn ontworpen dat alle extra parallelle bits in één keer worden gestart. Dat is misschien gemakkelijk te begrijpen, maar over het algemeen zou het niet erg efficiënt zijn. Het zou het aantal extra threads en andere bronnen die door de query worden gebruikt maximaliseren, en resulteren in een groot aantal onnodige parallelle wachttijden.
Met het ontwerp dat wordt gebruikt door SQL Server, zullen parallelle plannen vaak minder totale werkthreads gebruiken dan (DOP vermenigvuldigd met het totale aantal vertakkingen). Dit wordt bereikt door te erkennen dat sommige vertakkingen volledig kunnen worden voltooid voordat een andere vertakking moet beginnen. Dit kan hergebruik van threads binnen dezelfde zoekopdracht mogelijk maken, en over het algemeen wordt het resourceverbruik in het algemeen verminderd.
Laten we nu kijken naar de details van hoe ons parallelle plan van start gaat.
Vertakking A openen
De queryscan wordt uitgevoerd met de bovenliggende taak die Open() . aanroept op de iterator aan de wortel van de boom. Dit is het begin van de uitvoeringsreeks:
- Tak A (oudertaak).
- Branch C (extra parallelle taken).
- Branch D (extra parallelle taken).
- Branch B (extra parallelle taken).
We voeren deze query uit met een 'werkelijk' plan aangevraagd, dus de root-iterator is niet de sequentieprojectoperator op knooppunt 0. Het is eerder de onzichtbare profilerings-iterator die runtime-statistieken registreert in rijmodusplannen.
De onderstaande afbeelding toont de queryscan-iterators in Tak A van het plan, met de positie van onzichtbare profilering-iterators weergegeven door de 'bril'-pictogrammen.
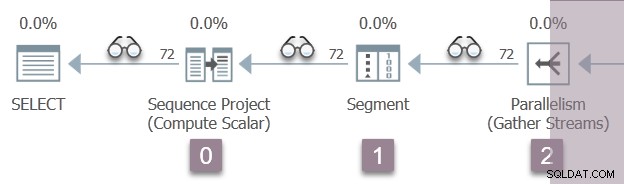
De uitvoering begint met een aanroep om de eerste profiler te openen, CQScanProfileNew::Open . Dit stelt de open tijd in voor de projectoperator van de onderliggende reeks via de Query Performance Counter API van het besturingssysteem.
We kunnen dit nummer zien in sys.dm_exec_query_profiles :
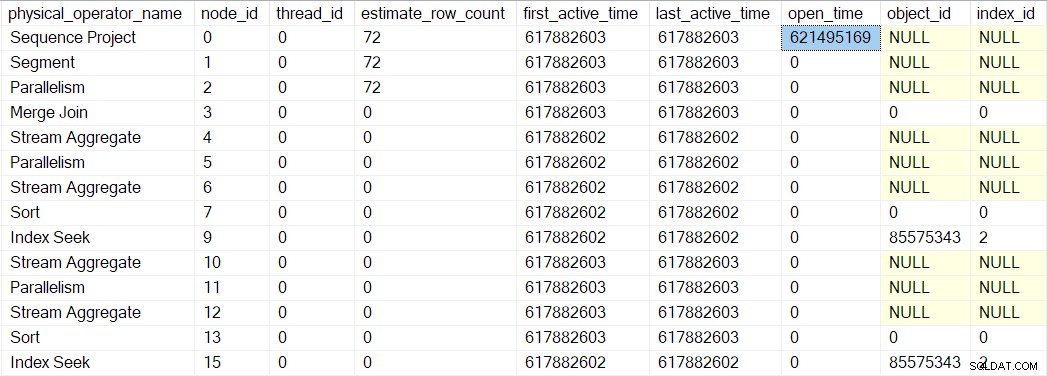
De vermeldingen daar hebben mogelijk de namen van de operators, maar de gegevens komen van de profiler boven de operator, niet de operator zelf.
Toevallig een sequentieproject (CQScanSeqProjectNew ) hoeft geen werk te doen wanneer geopend , dus het heeft eigenlijk geen Open() methode. De profiler boven het reeksproject is gebeld, dus een open tijd voor het sequentieproject wordt vastgelegd in de DMV.
De Open . van de profiler methode roept Open niet aan op het sequentieproject (omdat het er geen heeft). In plaats daarvan roept het Open . aan op de profiler voor de volgende iterator in volgorde. Dit is het segment iterator op knooppunt 1. Dat stelt de open tijd voor het segment in, net zoals de vorige profiler deed voor het sequentieproject:
Een segment-iterator doet dingen te doen hebben wanneer ze worden geopend, dus de volgende oproep is om CQScanSegmentNew::Open . Zodra het segment heeft gedaan wat het moet doen, roept het de profiler aan voor de volgende iterator in volgorde:de consument kant van de verzamel streams uitwisseling bij knooppunt 2:
De volgende aanroep van de query-scanboom in het openingsproces is CQScanExchangeNew::Open , en dat is waar dingen interessanter worden.
De collect streams-uitwisseling openen
De consumentenkant van de beurs vragen om te openen:
- Opent een lokale (parallel geneste) transactie (
CXTransLocal::Open). Elk proces heeft een omvattende transactie nodig, en aanvullende parallelle taken zijn geen uitzondering. Ze kunnen de bovenliggende (basis)transactie niet rechtstreeks delen, dus worden geneste transacties gebruikt. Wanneer een parallelle taak toegang moet krijgen tot de basistransactie, wordt deze gesynchroniseerd op een vergrendeling en kanNESTING_TRANSACTION_READONLYworden aangetroffen ofNESTING_TRANSACTION_FULLwacht. - Registreert de huidige werkthread met de uitwisselingspoort (
CXPort::Register). - Synchroniseert met andere threads aan de consumentenkant van de exchange (
sqlmin!CXTransLocal::Synchronize). Er zijn geen andere threads aan de consumentenkant van een verzamelstream, dus dit is in wezen een no-op bij deze gelegenheid.
Verwerking "Vroege fasen"
De bovenliggende taak heeft nu de rand van Tak A bereikt. De volgende stap is bijzonder parallelle plannen in rijmodus:de bovenliggende taak gaat door met de uitvoering door CQScanExchangeNew::EarlyPhases aan te roepen op de verzamelstreams wissel iterator uit op knooppunt 2. Dit is een extra iteratormethode naast de gebruikelijke Open , GetRow , en Close methoden die velen van jullie zullen kennen. EarlyPhases wordt alleen aangeroepen in parallelle plannen in rijmodus.
Ik wil op dit punt duidelijk zijn over iets:de producentkant van de verzamelstreams-uitwisseling op knooppunt 2 heeft niet is nog niet gemaakt, en nee extra parallelle taken zijn gecreëerd. We voeren nog steeds code uit voor de bovenliggende taak, waarbij we de enige thread gebruiken die nu actief is.
Niet alle iterators implementeren EarlyPhases , omdat ze op dit moment niet allemaal iets speciaals te doen hebben in parallelle plannen in rijmodus. Dit is analoog aan het sequentieproject dat de Open . niet implementeert methode omdat het op dat moment niets te maken heeft. De belangrijkste iterators met EarlyPhases methoden zijn:
CQScanConcatNew(aaneenschakeling).CQScanMergeJoinNew(join samenvoegen).CQScanSwitchNew(schakelaar).CQScanExchangeNew(parallelisme).CQScanNew(toegang tot rijen, bijv. scannen en zoeken).CQScanProfileNew(onzichtbare profilers).CQScanLightProfileNew(onzichtbare lichtgewicht profilers).
Tak B vroege fasen
De oudertaak gaat verder door EarlyPhases . te bellen op onderliggende operatoren voorbij de uitwisseling van verzamelstromen op knooppunt 2. Een taak die over een vertakkingsgrens beweegt, lijkt misschien ongebruikelijk, maar onthoud dat uitvoeringscontext nul het hele seriële plan bevat, inclusief uitwisselingen. Verwerking in de vroege fase gaat over het initialiseren van parallellisme, dus het telt niet als uitvoering per se .
Om u te helpen het overzicht bij te houden, toont de onderstaande afbeelding de iterators in Tak B van het plan:
Onthoud dat we nog steeds in uitvoeringscontext nul zijn, dus ik noem dit alleen voor het gemak Tak B. We zijn niet begonnen nog geen parallelle uitvoering.
De volgorde van de code-aanroepingen in de vroege fase in Branch B is:
CQScanProfileNew::EarlyPhasesvoor de profiler boven knooppunt 3.CQScanMergeJoinNew::EarlyPhasesop het knooppunt 3 merge join .CQScanProfileNew::EarlyPhasesvoor de profiler boven knooppunt 4. Het knooppunt 4 stroomaggregaat zelf heeft geen methode voor vroege fasen.CQScanProfileNew::EarlyPhasesop de profiler boven knooppunt 5.CQScanExchangeNew::EarlyPhasesvoor de herverdelingsstreams uitwisseling op knooppunt 5.
Merk op dat we in dit stadium alleen de buitenste (bovenste) invoer voor de samenvoegverbinding verwerken. Dit is gewoon de normale iteratieve reeks voor het uitvoeren van rijmodus. Het is niet specifiek voor parallelle plannen.
Tak C vroege fasen
De verwerking in de vroege fase gaat verder met de iterators in Branch C:

De volgorde van oproepen hier is:
CQScanProfileNew::EarlyPhasesvoor de profiler boven knooppunt 6.CQScanProfileNew::EarlyPhasesvoor de profiler boven knooppunt 7.CQScanProfileNew::EarlyPhasesop de profiler boven knooppunt 9.CQScanNew::EarlyPhaseszoek voor de index naar knooppunt 9.
Er is geen EarlyPhases methode op de stream aggregeren of sorteren. Het werk dat wordt uitgevoerd door compute scalar op knooppunt 8 wordt uitgesteld (naar de sortering), dus het verschijnt niet in de query-scanstructuur en heeft geen bijbehorende profiler.
Over profiler-timings
Bovenliggende taak vroege fase verwerking begon bij de uitwisseling van verzamelstromen op knooppunt 2. Het daalde af in de query-scanboom, volgde de buitenste (bovenste) invoer naar de samenvoegverbinding, helemaal naar beneden naar de index, zoek bij knooppunt 9. Onderweg heeft de bovenliggende taak de EarlyPhases methode op elke iterator die het ondersteunt.
Geen van de activiteiten in de vroege fasen is tot nu toe bijgewerkt elk moment in de profilering DMV. In het bijzonder heeft geen van de iterators die zijn geraakt door de verwerking van vroege fasen hun 'open tijd' ingesteld. Dit is logisch, omdat verwerking in de vroege fase slechts het opzetten van parallelle uitvoering is - deze operators worden geopend voor uitvoering later.
De index-zoekopdracht bij knooppunt 9 is een bladknooppunt - het heeft geen kinderen. De bovenliggende taak begint nu terug te keren vanuit de geneste EarlyPhases oproepen, oplopend de query-scanboom terug naar de verzamelstreams-uitwisseling.
Elk van de profilers roept de Query Performance Counter API bij toegang tot hun EarlyPhases methode, en ze noemen het opnieuw op de weg naar buiten. Het verschil tussen de twee getallen staat voor verstreken tijd voor de iterator en al zijn kinderen (aangezien de methodeaanroepen genest zijn).
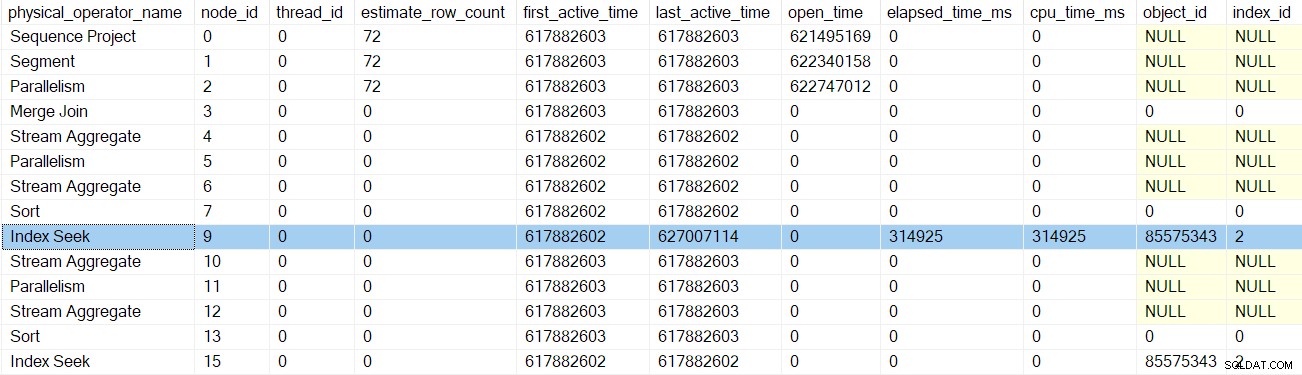
Nadat de profiler voor het zoeken naar de index is teruggekeerd, toont de DMV van de profiler de verstreken en CPU-tijd voor de index zoeken alleen, evenals een bijgewerkte laatst actieve tijd. Merk ook op dat deze informatie wordt vastgelegd voor de bovenliggende taak (de enige optie op dit moment):
Geen van de eerdere iterators die zijn aangeraakt door de vroege fasen van oproepen, hebben verstreken tijden of de laatste actieve tijden bijgewerkt. Deze cijfers worden alleen bijgewerkt wanneer we de boom beklimmen.
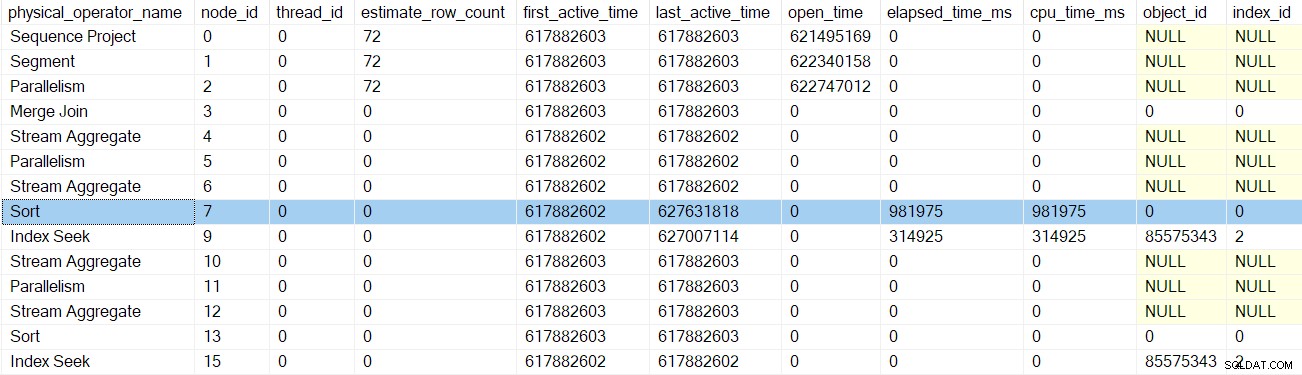
Na de volgende profiler vroege fasen oproepterugkeer, de sorteer tijden zijn bijgewerkt:
De volgende terugkeer brengt ons verder dan de profiler voor het stroomaggregaat bij knooppunt 6:
Terugkerend van deze profiler brengt ons terug naar de EarlyPhases bel de herpartitie streams uitwisseling op knooppunt 5 . Onthoud dat dit niet is waar de reeks oproepen in de vroege fasen begon - dat was de uitwisseling van verzamelstromen op knooppunt 2.
Branch C Parallelle taken in de wachtrij geplaatst
Afgezien van het bijwerken van profileringsgegevens, leken de eerdere vroege fasen-oproepen niet veel te doen. Dat verandert allemaal met de herpartitie streams uitwisseling op knooppunt 5.
Ik ga Branch C behoorlijk gedetailleerd beschrijven om een aantal belangrijke concepten te introduceren, die ook van toepassing zullen zijn op de andere parallelle branches. Door dit onderwerp nu een keer te behandelen, kan een latere bespreking van de branche beknopter zijn.
Nadat de geneste vroege fase-verwerking voor zijn subboom is voltooid (tot aan de indexzoekopdracht op knooppunt 9), kan de uitwisseling zijn eigen vroege fase-werk beginnen. Dit begint hetzelfde als openen de verzamelstromen wisselen op knooppunt 2:
CXTransLocal::Open(het openen van de lokale parallelle subtransactie).CXPort::Register(registreren bij de uitwisselingspoort).
De volgende stappen zijn anders omdat tak C een volledig blokkering . bevat iterator (de sortering op knooppunt 7). De verwerking in de vroege fase bij de knooppunt 5 herpartitiestromen doet het volgende:
- Belt
CQScanExchangeNew::StartAllProducers. Dit is de eerste keer dat we iets tegenkomen dat verwijst naar de producentenkant van de uitwisseling. Knooppunt 5 is de eerste uitwisseling in dit plan om zijn producentenkant te creëren. - Verwerft een mutex dus geen enkele andere thread kan tegelijkertijd taken in de wachtrij plaatsen.
- Start parallelle geneste transacties voor de producententaken (
CXPort::StartNestedTransactionsenReadOnlyXactImp::BeginParallelNestedXact). - Registreert de subtransacties met het bovenliggende query-scanobject (
CQueryScan::AddSubXact). - Maakt producerdescriptors (
CQScanExchangeNew::PxproddescCreate). - Maakt nieuwe uitvoeringscontexten voor producenten (
CExecContext) afgeleid van uitvoeringscontext nul. - Updatet de gekoppelde kaart van plan-iterators.
- Stelt DOP in voor de nieuwe context (
CQueryExecContext::SetDop) zodat alle taken weten wat de algemene DOP-instelling is. - Initialiseert de parametercache (
CQueryExecContext::InitParamCache). - Koppelt de parallelle geneste transacties aan de basistransactie (
CExecContext::SetBaseXact). - Spelt de nieuwe subprocessen in de wachtrij voor uitvoering (
SubprocessMgr::EnqueueMultipleSubprocesses). - Maakt nieuwe parallelle taken taken via
sqldk!SOS_Node::EnqueueMultipleTasksDirect.
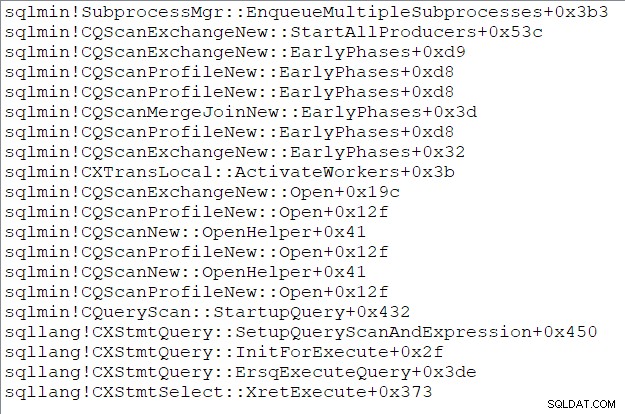
De oproepstapel van de bovenliggende taak (voor degenen onder u die van deze dingen genieten) rond dit tijdstip is:
Einde van deel drie
We hebben nu de producerkant gemaakt van de herverdelingsstromen wisselen op knooppunt 5, extra parallelle taken om Branch C uit te voeren en alles terug te koppelen aan ouder structuren naar behoefte. Tak C is de eerste branch om parallelle taken te starten. Het laatste deel van deze serie zal in detail kijken naar de opening van tak C en de resterende parallelle taken starten.